

Los desarrolladores que eligen entre GLM-4.7 Flash y Qwen3-30B-A3B-Thinking-2507 se enfrentan a un claro intercambio: dominio de la ingeniería de software frente a profundidad de razonamiento. Ambos son modelos MoE de clase 30B con aproximadamente 3B de parámetros activos por token, ventanas de contexto largas (202K para GLM-4.7 Flash, 262K para Qwen3) y requisitos de VRAM similares. La divergencia radica en para qué están optimizados: GLM-4.7 Flash para flujos de trabajo de codificación con agentes (llamada a herramientas, navegación web, generación de código), Qwen3-30B-A3B-Thinking-2507 para razonamiento de múltiples pasos con un “modo de pensamiento” dedicado que expone trazas internas de razonamiento.
¿Qué modelo deberías elegir?
| Elige GLM-4.7 Flash si necesitas: | Elige Qwen3-30B-A3B-Thinking-2507 si necesitas: |
|---|---|
| • Tareas de ingeniería de software (59.2% SWE-bench Verificado) • Automatización de tareas basadas en navegador (42.8% BrowseComp vs 2.29%) • Llamada a herramientas con agentes (79.5% τ²-Bench vs 49.0%) • Agentes de codificación de baja latencia • Tareas que requieren una fuerte navegación web y automatización • Generación y refactorización de código en tiempo real |
• Lógica de múltiples pasos con trazas de razonamiento expuestas • Investigación científica y resolución de problemas académicos • Tareas de seguimiento de instrucciones (88.9% IFEval) • Comprensión multilingüe y análisis de contexto largo |
Comparación de arquitectura
Ambos son modelos MoE de clase 30B con aproximadamente 3B de parámetros activos y ventanas de contexto largas, y tienen requisitos de VRAM en gran medida similares.
| Aspecto | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| Parámetros totales | 30B | 31B |
| Parámetros activos (por token) | 3B (64 expertos, 4 activos) | 3.3B (128 expertos, 8 activos) |
| Longitud de contexto | 202.752 tokens | 262.144 tokens |
| Capas ocultas | 47 | 48 |
| Cabezas de atención | 20 (estándar) | 32 Q / 4 KV (GQA) |
| Precisión | bfloat16 | bfloat16 |
| Soporte multimodal | No (solo texto) | No (solo texto) |
| Características especiales | Automatización de navegador, llamada a herramientas | Modo de pensamiento (trazas de razonamiento) |
Diferencia arquitectónica clave: Qwen3 utiliza Atención de Consulta Agrupada (32 cabezas Q, 4 cabezas KV) para una gestión eficiente del caché KV durante la inferencia de contexto largo, mientras que GLM-4.7 Flash utiliza atención estándar con menos cabezas (20). Qwen activa 8 expertos por token (frente a 4 en GLM-4.7 Flash), proporcionando mayor flexibilidad de enrutamiento a costa de un cálculo ligeramente mayor por paso hacia adelante.
Ambos modelos tienen una eficiencia de parámetros casi idéntica (3B activos). Sin embargo, GLM-4.7 Flash intercambia algo de profundidad de razonamiento por una ejecución más rápida de herramientas, mientras que Qwen3 se enfoca más en el razonamiento profundo de múltiples pasos a través de su arquitectura de modo de pensamiento.
Comparación de benchmarks
La brecha de rendimiento entre estos modelos emerge claramente cuando se agrupan por tipo de tarea. Hemos organizado los benchmarks en tres categorías: codificación/ingeniería, razonamiento/académico y capacidades especializadas.
Benchmarks de codificación e ingeniería de software
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| SWE-bench Verificado | 59.2% 🏆 | 22.0% |
| τ²-Bench (Uso de herramientas) | 79.5% 🏆 | 49.0% |
| BrowseComp | 42.8% 🏆 | 2.29% |
Fuente: Páginas de modelos de Unsloth / Hugging Face. Datos de marzo de 2026.
Benchmarks de razonamiento y académicos
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| GPQA (Preguntas científicas) | 75.2%🏆 | 73.4% |
| AIME 2025 (Matemáticas) | 91.6%🏆 | 85.0% |
Fuente: Páginas de modelos de Unsloth / Hugging Face. Datos de marzo de 2026.
Capacidades especializadas
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| HLE (Evaluación similar a humana) | 14.4% 🏆 | 9.8% |
Fuente: Páginas de modelos de Unsloth / Hugging Face. Datos de marzo de 2026.
En general, GLM-4.7 Flash está posicionado como un modelo orientado a la ingeniería y las herramientas, mientras que Qwen3-30B-A3B-Thinking-2507 está optimizado para el razonamiento profundo y tareas cognitivas intensivas.
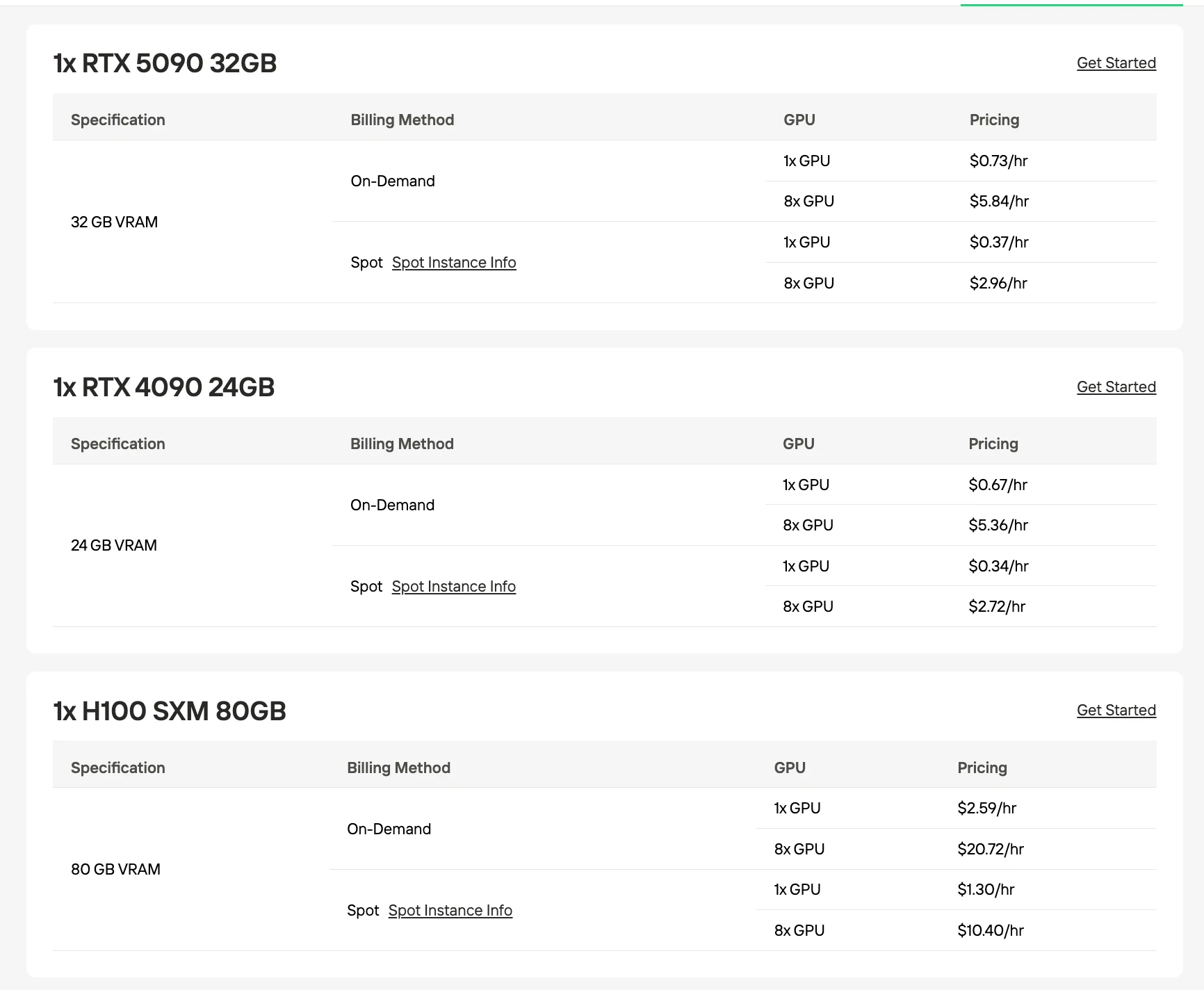
Requisitos de VRAM y GPU
Ambos modelos requieren una VRAM base similar debido a su recuento compartido de 30B parámetros, pero las estrategias de cuantización difieren según el enfoque de optimización.
GPU recomendada para GLM-4.7 Flash
| Cuantización / Formato | Tamaño del modelo | Requisito de VRAM | Configuración recomendada |
|---|---|---|---|
| UD-Q4_K_XL (recomendado) | 17.52 GB | 24 GB | Una sola RTX 4090 |
| Q4_K_M | 18.31 GB | 24 GB | Una sola RTX 4090 |
| Q5_K_M | 21.41 GB | 24 GB | Una sola RTX 4090 |
| Q8_0 | 31.84 GB | 40 GB | 2× RTX 4090 o H100 80GB |
| BF16 (completo) | 60 GB | 80 GB | H100 80GB |
Fuente: Unsloth / Hugging Face. Las cifras de VRAM son estimaciones basadas en tamaños de modelos cuantizados.
GPU recomendada para Qwen3-30B-A3B-Thinking-2507
| Formato | Tamaño de archivo | VRAM mínima | Mejor para |
|---|---|---|---|
| UD-Q4_K_XL (recomendado) | 17.72 GB | 24 GB | Una sola RTX 4090 |
| Q4_K_M | 18.56 GB | 24 GB | Una sola RTX 4090 |
| Q5_K_M | 21.73 GB | 24 GB | Una sola RTX 4090 |
| Q8_0 | 32.48 GB | 40 GB | 2× RTX 4090 o H100 80GB |
| BF16 (completo) | 61 GB | 80 GB+ | H100 80GB |
Fuente: Unsloth / Hugging Face. Las cifras de VRAM son estimaciones basadas en tamaños de modelos cuantizados.
¿Cómo acceder a GLM-4.7 Flash o Qwen3-30B-A3B?
Ambos modelos admiten acceso a API compatible con OpenAI, lo que facilita la integración para desarrolladores que ya utilizan el SDK de OpenAI.
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comienza tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
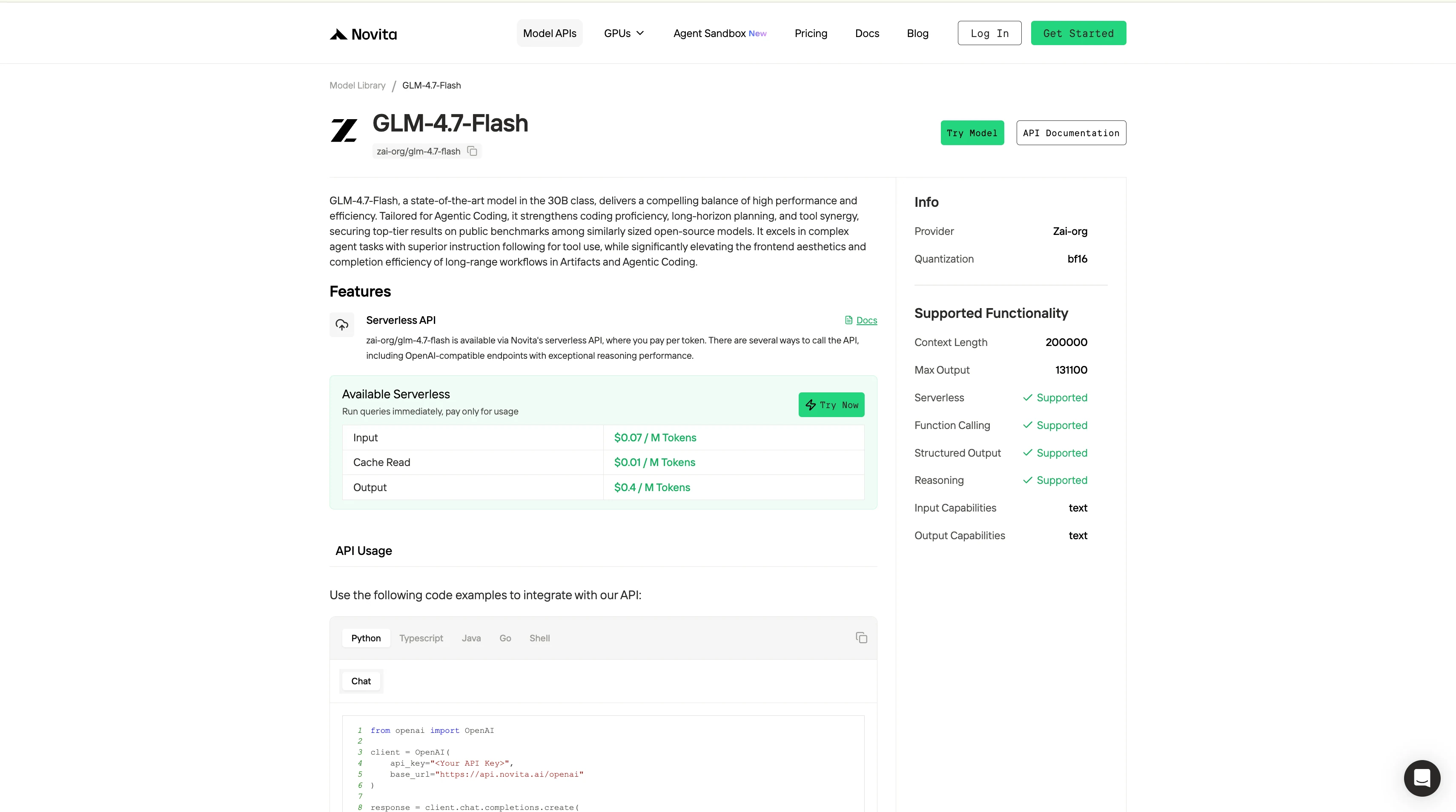
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresando a la página “Settings“, puedes copiar la clave API como se indica en la imagen.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
La elección entre GLM-4.7 Flash y Qwen3-30B-A3B-Thinking-2507 se reduce a una especialización clara: GLM-4.7 Flash gana de manera decisiva para agentes de ingeniería de software (59.2% SWE-bench, 79.5% τ²-Bench, 42.8% BrowseComp) a un costo combinado imbatible de $0.47/1M a través de Novita AI. Para desarrolladores que construyen integraciones con Claude Code, automatización de terminal o agentes basados en navegador, GLM-4.7 Flash es la elección obvia: su ventaja de 2.7× en SWE-bench sobre Qwen3 (59.2% vs 22.0%) y su precio extremadamente bajo lo hacen ideal para flujos de trabajo de codificación en producción.
Conclusión
Tanto GLM-4.7 Flash como Qwen3-30B-A3B-Thinking-2507 son modelos MoE de clase 30B con requisitos de VRAM casi idénticos, pero sirven para casos de uso distintos. GLM-4.7 Flash es la elección clara para agentes de ingeniería de software, automatización de navegador y flujos de trabajo intensivos en herramientas. Qwen3-30B-A3B-Thinking-2507 sobresale cuando necesitas razonamiento transparente de múltiples pasos con trazas de pensamiento explícitas para tareas de investigación y análisis.
Conclusión clave: Si estás construyendo un agente de codificación o un pipeline de automatización, opta por GLM-4.7 Flash. Si necesitas razonamiento profundo estructurado, elige Qwen3-30B-A3B-Thinking-2507. Ambos están disponibles en Novita AI — prueba GLM-4.7 Flash o explora el catálogo completo de modelos hoy.
¿Cuál es mejor para agentes de codificación: GLM-4.7 Flash o Qwen3-30B-A3B-Thinking-2507?
GLM-4.7 Flash domina con 59.2% en SWE-bench Verificado (frente al 22.0% de Qwen) y 79.5% en uso de herramientas τ²-Bench (frente al 49.0%).
¿Cuál es más fácil de implementar localmente?
Ambos requieren ~18GB de VRAM con cuantización INT4 en 1× RTX 4090.
¿Puedo ejecutar GLM-4.7 Flash en Claude Code o Trae?
Sí, ambas herramientas admiten integración de modelos personalizados a través de API.
Lectura recomendada
- Usa GLM-4.5 en Trae para desbloquear agentes de codificación más inteligentes
- Usa MiniMax M2.1 en OpenCode
- DeepSeek vs Qwen: identifica qué ecosistema se adapta a las necesidades de producción
Novita AI es una plataforma de nube de IA y agentes que ayuda a desarrolladores y startups a construir, implementar y escalar modelos y aplicaciones de agentes con alto rendimiento, fiabilidad y eficiencia de costos.



