

Les développeurs qui hésitent entre GLM-4.7 Flash et Qwen3-30B-A3B-Thinking-2507 se heurtent à un compromis clair : maîtrise de l’ingénierie logicielle contre profondeur de raisonnement. Les deux sont des modèles MoE de classe 30B avec environ 3 milliards de paramètres actifs par jeton, des fenêtres de contexte long (202K pour GLM-4.7 Flash, 262K pour Qwen3) et des exigences VRAM similaires. La divergence réside dans leur optimisation : GLM-4.7 Flash est conçu pour les flux de travail de codage agentique (appel d’outils, navigation web, génération de code), tandis que Qwen3-30B-A3B-Thinking-2507 est optimisé pour le raisonnement multi-étapes avec un « mode de réflexion » dédié qui expose les traces de raisonnement interne.
Quel modèle devez-vous choisir ?
| Choisissez GLM-4.7 Flash si vous avez besoin de : | Choisissez Qwen3-30B-A3B-Thinking-2507 si vous avez besoin de : |
|---|---|
| • Tâches d’ingénierie logicielle (59,2 % sur SWE-bench Verified) • Automatisation de tâches basée sur un navigateur (42,8 % sur BrowseComp contre 2,29 %) • Appel d’outils agentique (79,5 % sur τ²-Bench contre 49,0 %) • Agents de codage à faible latence • Tâches nécessitant une navigation web et une automatisation performantes • Génération et refactorisation de code en temps réel |
• Logique multi-étapes avec traces de raisonnement exposées • Recherche scientifique et résolution de problèmes académiques • Tâches de suivi d’instructions (88,9 % sur IFEval) • Compréhension multilingue et analyse de contexte long |
Essayez GLM 4.7 Flash dès maintenant !
Comparaison des architectures
Les deux sont des modèles MoE de classe 30B avec environ 3 milliards de paramètres actifs et des fenêtres de contexte long, et leurs exigences VRAM sont globalement similaires.
| Aspect | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| Paramètres totaux | 30B | 31B |
| Paramètres actifs (par jeton) | 3B (64 experts, 4 actifs) | 3,3B (128 experts, 8 actifs) |
| Longueur de contexte | 202 752 jetons | 262 144 jetons |
| Couches cachées | 47 | 48 |
| Têtes d’attention | 20 (standard) | 32 Q / 4 KV (GQA) |
| Précision | bfloat16 | bfloat16 |
| Prise en charge multimodale | Non (texte uniquement) | Non (texte uniquement) |
| Fonctionnalités spéciales | Automatisation de navigateur, appel d’outils | Mode de réflexion (traces de raisonnement) |
Différence architecturale clé : Qwen3 utilise l’attention groupée par requête (32 têtes Q, 4 têtes KV) pour une gestion efficace du cache KV lors de l’inférence en contexte long, tandis que GLM-4.7 Flash utilise une attention standard avec moins de têtes (20). Qwen active 8 experts par jeton (contre 4 pour GLM-4.7 Flash), offrant une plus grande flexibilité de routage au prix d’une charge de calcul légèrement plus élevée par passage avant.
Les deux modèles ont une efficacité paramétrique quasi identique (3 milliards de paramètres actifs). Cependant, GLM-4.7 Flash sacrifie une partie de la profondeur de raisonnement pour une exécution d’outils plus rapide, tandis que Qwen3 se concentre davantage sur un raisonnement multi-étapes plus approfondi grâce à son architecture de mode de réflexion.
Essayez GLM 4.7 Flash dès maintenant !
Comparaison des benchmarks
L’écart de performance entre ces modèles apparaît clairement lorsqu’on les regroupe par type de tâche. Nous avons organisé les benchmarks en trois catégories : codage/ingénierie, raisonnement/académique et capacités spécialisées.
Benchmarks de codage et d’ingénierie logicielle
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| SWE-bench Verified | 59,2 % 🏆 | 22,0 % |
| τ²-Bench (Utilisation d’outils) | 79,5 % 🏆 | 49,0 % |
| BrowseComp | 42,8 % 🏆 | 2,29 % |
Source : pages de modèles Unsloth / Hugging Face. Données de mars 2026.
Benchmarks de raisonnement et académiques
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| GPQA (Questions-réponses scientifiques) | 75,2 % 🏆 | 73,4 % |
| AIME 2025 (Mathématiques) | 91,6 % 🏆 | 85,0 % |
Source : pages de modèles Unsloth / Hugging Face. Données de mars 2026.
Capacités spécialisées
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| HLE (Évaluation de type humain) | 14,4 % 🏆 | 9,8 % |
Source : pages de modèles Unsloth / Hugging Face. Données de mars 2026.
Dans l’ensemble, GLM-4.7 Flash est positionné comme un modèle orienté ingénierie et outils, tandis que Qwen3-30B-A3B-Thinking-2507 est optimisé pour le raisonnement approfondi et les tâches nécessitant beaucoup de cognition.
Essayez GLM 4.7 Flash dès maintenant !
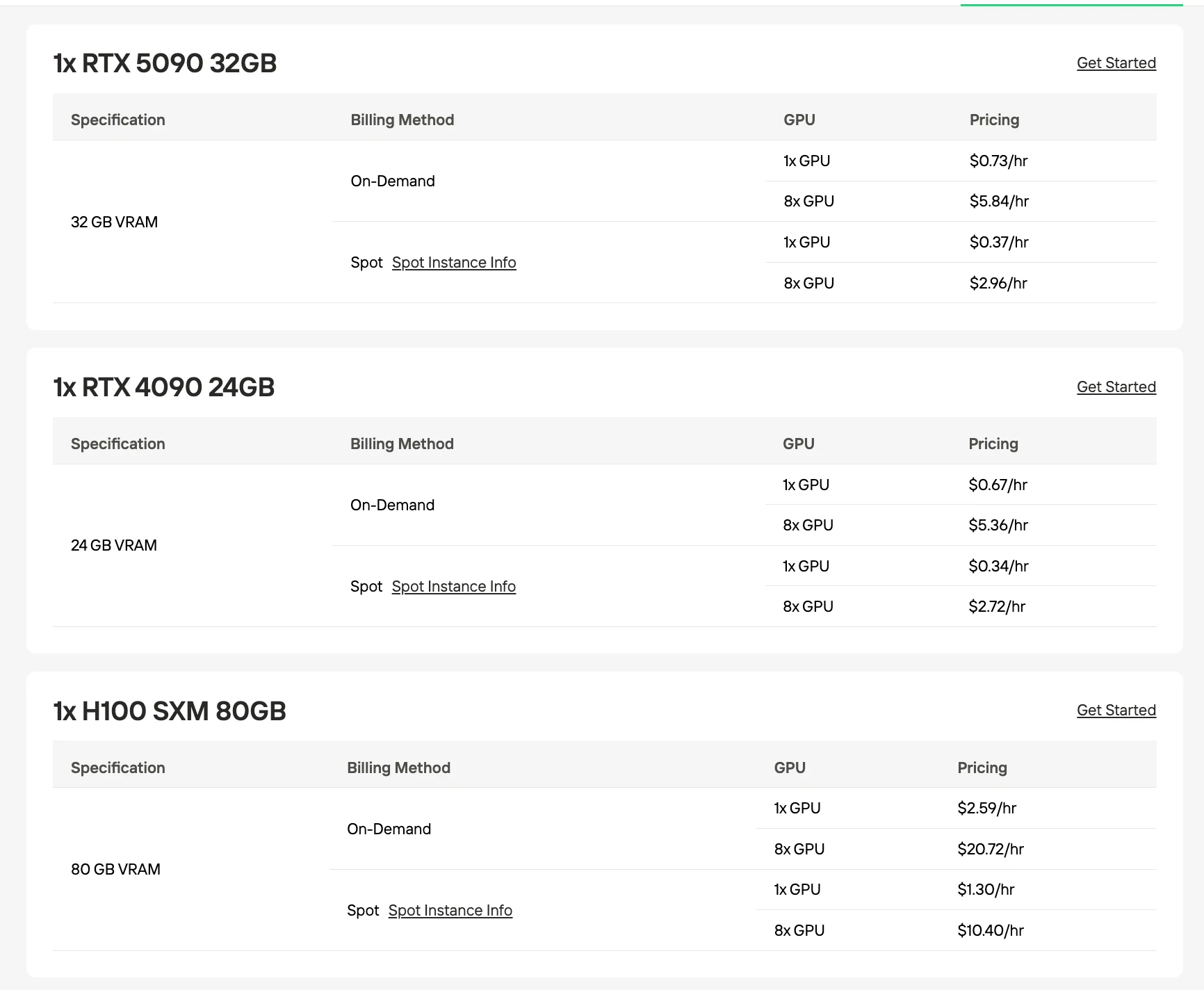
Exigences en VRAM et GPU
Les deux modèles nécessitent une VRAM de base similaire en raison de leur nombre de paramètres commun de 30B, mais les stratégies de quantification diffèrent en fonction de l’orientation de l’optimisation.
GPU recommandé pour GLM-4.7 Flash
| Quantification / Format | Taille du modèle | Exigence VRAM | Configuration recommandée |
|---|---|---|---|
| UD-Q4_K_XL (recommandé) | 17,52 Go | 24 Go | Carte RTX 4090 unique |
| Q4_K_M | 18,31 Go | 24 Go | Carte RTX 4090 unique |
| Q5_K_M | 21,41 Go | 24 Go | Carte RTX 4090 unique |
| Q8_0 | 31,84 Go | 40 Go | 2× RTX 4090 ou H100 80Go |
| BF16 (complet) | 60 Go | 80 Go | H100 80Go |
Source : Unsloth / Hugging Face. Les chiffres de VRAM sont des estimations basées sur les tailles des modèles quantifiés.
GPU recommandé pour Qwen3-30B-A3B-Thinking-2507
| Format | Taille du fichier | VRAM minimale | Idéal pour |
|---|---|---|---|
| UD-Q4_K_XL (recommandé) | 17,72 Go | 24 Go | Carte RTX 4090 unique |
| Q4_K_M | 18,56 Go | 24 Go | Carte RTX 4090 unique |
| Q5_K_M | 21,73 Go | 24 Go | Carte RTX 4090 unique |
| Q8_0 | 32,48 Go | 40 Go | 2× RTX 4090 ou H100 80Go |
| BF16 (complet) | 61 Go | 80 Go+ | H100 80Go |
Source : Unsloth / Hugging Face. Les chiffres de VRAM sont des estimations basées sur les tailles des modèles quantifiés.
Essayez des GPU rentables dès maintenant !
Comment accéder à GLM-4.7 Flash ou Qwen3-30B-A3B ?
Les deux modèles prennent en charge l’accès API compatible OpenAI, ce qui rend l’intégration simple pour les développeurs utilisant déjà le SDK OpenAI.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Essayez GLM 4.7 Flash dès maintenant !
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En vous rendant sur la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
Le choix entre GLM-4.7 Flash et Qwen3-30B-A3B-Thinking-2507 se résume à une spécialisation claire : GLM-4.7 Flash l’emporte nettement pour les agents d’ingénierie logicielle (59,2 % sur SWE-bench, 79,5 % sur τ²-Bench, 42,8 % sur BrowseComp) à un coût mixte imbattable de 0,47 $ par million de jetons via Novita AI. Pour les développeurs créant des intégrations Claude Code, des automatisations de terminal ou des agents basés sur un navigateur, GLM-4.7 Flash est le choix évident : son avantage de 2,7× sur SWE-bench par rapport à Qwen3 (59,2 % contre 22,0 %) et ses prix extrêmement bas en font un modèle idéal pour les flux de travail de codage en production.
Conclusion
GLM-4.7 Flash et Qwen3-30B-A3B-Thinking-2507 sont tous deux des modèles MoE de classe 30B performants avec des exigences VRAM quasi identiques, mais ils répondent à des cas d’usage distincts. GLM-4.7 Flash est le choix évident pour les agents d’ingénierie logicielle, l’automatisation de navigateur et les flux de travail fortement orientés outils. Qwen3-30B-A3B-Thinking-2507 excelle lorsque vous avez besoin d’un raisonnement multi-étapes transparent avec des traces de réflexion explicites pour des tâches de recherche et d’analyse.
Point clé à retenir : Si vous développez un agent de codage ou un pipeline d’automatisation, optez pour GLM-4.7 Flash. Si vous avez besoin d’un raisonnement approfondi structuré, choisissez Qwen3-30B-A3B-Thinking-2507. Les deux sont disponibles sur Novita AI — essayez GLM-4.7 Flash ou explorez le catalogue complet de modèles dès aujourd’hui.
Quel modèle est le meilleur pour les agents de codage : GLM-4.7 Flash ou Qwen3-30B-A3B-Thinking-2507 ?
GLM-4.7 Flash domine avec 59,2 % sur SWE-bench Verified (contre 22,0 % pour Qwen) et 79,5 % sur l’utilisation d’outils τ²-Bench (contre 49,0 %).
Lequel est le plus facile à déployer localement ?
Les deux nécessitent environ 18 Go de VRAM avec une quantification INT4 sur 1 carte RTX 4090.
Puis-je exécuter GLM-4.7 Flash dans Claude Code ou Trae ?
Oui, les deux outils prennent en charge l’intégration de modèles personnalisés via API.
Lectures recommandées
- Utilisez GLM-4.5 dans Trae pour débloquer des agents de codage plus intelligents
- Utilisez MiniMax M2.1 dans OpenCode
- DeepSeek vs Qwen : Identifiez quel écosystème correspond aux besoins de production
Novita AI est une plateforme cloud IA et d’agents qui aide les développeurs et les startups à créer, déployer et mettre à l’échelle des modèles et des applications agentiques avec des performances élevées, une fiabilité et une efficacité de coûts.



