

- DeepSeek V4 Pro vs DeepSeek V4 Flash : comparaison rapide
- Qu'est-ce qui change entre Pro et Flash ?
- Comparaison des prix sur Novita AI
- Repères et signaux de performance
- Comment accéder aux deux API sur Novita AI
- Meilleurs cas d'utilisation : quand choisir chaque modèle
- Notes de migration pour les développeurs
- Recommandation finale
- FAQ
Choisissez DeepSeek V4 Pro lorsque la qualité de sortie sur des tâches complexes de codage agentique, de raisonnement long ou de problèmes multi-étapes difficiles est plus importante que le coût unitaire ; choisissez DeepSeek V4 Flash lorsque vous avez besoin de la même fenêtre de contexte de 1 048 576 tokens, de la même limite de sortie maximale de 393 216 tokens et d’un chemin d’API moins coûteux pour les charges de travail à haut volume ou sensibles à la latence. Les deux modèles sont disponibles via l’API LLM compatible OpenAI de Novita AI, mais leurs prix et leur positionnement indiquent des rôles de production différents.
DeepSeek V4 Pro vs DeepSeek V4 Flash : comparaison rapide
Adéquation du modèle
| Domaine | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Meilleur pour | Workflows agentiques complexes, développement logiciel professionnel, raisonnement difficile | Applications à haute concurrence, charges de travail légères, trafic de production sensible aux coûts |
| Règle de décision | À utiliser lorsque le coût d’échec est élevé | À utiliser lorsque le volume de requêtes ou la latence est plus important |
API et limites
| Domaine | DeepSeek V4 Pro | DeepSeek V4 Flash |
| ID du modèle | deepseek/deepseek-v4-pro |
deepseek/deepseek-v4-flash |
| Disponibilité | Disponible, LLM sans serveur | Disponible, LLM sans serveur |
| Fenêtre de contexte | 1 048 576 tokens | 1 048 576 tokens |
| Tokens de sortie max | 393 216 tokens | 393 216 tokens |
| Modalité entrée / sortie | Texte en entrée, texte en sortie | Texte en entrée, texte en sortie |
| Chemin de requête API | Complétions de chat compatibles OpenAI | Complétions de chat compatibles OpenAI |
Aperçu des prix
| Domaine | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Prix d’entrée | 1,60 $ par million de tokens | 0,14 $ par million de tokens |
| Prix de sortie | 3,20 $ par million de tokens | 0,28 $ par million de tokens |
| Prix de lecture du cache | 0,135 $ par million de tokens | 0,028 $ par million de tokens |
Remarques sur les fonctionnalités
| Domaine | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Fonctionnalités listées | Sans serveur, appel de fonctions, sorties structurées, raisonnement | Sans serveur, appel de fonctions, sorties structurées, raisonnement |
| Remarque pratique | Aiguillez les invites les plus difficiles vers Pro | Utilisez Flash pour le trafic de base scalable |
Qu’est-ce qui change entre Pro et Flash ?
Le changement le plus important ne concerne pas la longueur du contexte ou l’accès de base aux complétions de chat. Sur Novita AI, les deux modèles listent une fenêtre de contexte de 1 048 576 tokens, une sortie maximale de 393 216 tokens, une entrée et une sortie textuelles, une livraison sans serveur, l’appel de fonctions, les sorties structurées et le support du raisonnement.
La différence pratique réside dans le positionnement et le prix. La page du modèle DeepSeek V4 Pro décrit Pro comme l’option phare pour les workflows agentiques complexes, le développement logiciel professionnel, les évaluations lourdes en raisonnement et les tâches de codage exigeantes. La page du modèle DeepSeek V4 Flash positionne Flash comme une option légère pour un service API rapide et économique, une haute concurrence, une faible latence et des charges de travail légères à grande échelle.
Cela donne aux développeurs un modèle de routage clair :
- Utilisez Pro pour les tâches où une seule réponse médiocre peut coûter plus que le prix supplémentaire des tokens : modifications de code autonomes, longues sessions de débogage, analyse à l’échelle du dépôt, planification et raisonnement difficile.
- Utilisez Flash pour les requêtes où le coût et la réactivité façonnent l’expérience produit : assistance par chat, classification de premier passage, résumé, extraction, routage et appels de production répétés.
- Utilisez les deux lorsque votre application peut séparer les « invites difficiles » des « invites standard ». Flash peut gérer la majeure partie du trafic de base, tandis que Pro peut être réservé aux escalades ou aux workflows premium.
Si vous avez déjà lu le guide de lancement de DeepSeek V4 Flash, considérez cette page comme la couche de décision : il s’agit de savoir quand sélectionner chaque API, et non de répéter la configuration de lancement.
Comparaison des prix sur Novita AI
Les prix actuels des pages de modèles Novita AI montrent un écart de coût important entre les deux modèles :
Tarifs DeepSeek V4 Pro
| Domaine | Valeur |
| Prix d’entrée | 1,60 $ par million de tokens |
| Prix de sortie | 3,20 $ par million de tokens |
| Prix d’entrée en lecture du cache | 0,135 $ par million de tokens |
| À utiliser quand | Raisonnement complexe, codage agentique ou tâches à coût d’échec élevé |
Tarifs DeepSeek V4 Flash
| Domaine | Valeur |
| Prix d’entrée | 0,14 $ par million de tokens |
| Prix de sortie | 0,28 $ par million de tokens |
| Prix d’entrée en lecture du cache | 0,028 $ par million de tokens |
| À utiliser quand | Trafic de production à haut volume, sensible à la latence ou aux coûts |
Pour les tokens d’entrée et de sortie, Pro coûte environ 11,4 fois le prix indiqué de Flash. Cela ne signifie pas que Flash est toujours le meilleur choix commercial ; cela signifie que Pro doit être utilisé là où son avantage de qualité attendu justifie le coût unitaire plus élevé.
Une politique de production simple fonctionne bien :
- Par défaut, utilisez Flash pour les invites à haut volume avec des instructions claires, des critères d’évaluation courts et un faible coût d’échec.
- Passez à Pro lorsque l’utilisateur demande du codage difficile, un raisonnement multi-étapes, une synthèse de contexte long ou une réponse à enjeux élevés.
- Effectuez un test en parallèle sur un ensemble représentatif d’invites avant de modifier le routage de production. Comparez la qualité de sortie, les nouvelles tentatives, l’acceptation par l’utilisateur, le nombre total de tokens, la latence et les cas d’échec, et pas seulement le prix par token.
Les prix peuvent changer, alors vérifiez les pages de modèles actuelles avant de publier un workflow ou un devis sensible aux prix.
Repères et signaux de performance
Les données de référence d’Artificial Analysis indiquent un compromis clair entre une utilisation axée sur la qualité et une utilisation axée sur le débit. DeepSeek V4 Pro rapporte le score d’intelligence le plus élevé, tandis que DeepSeek V4 Flash rapporte de meilleures mesures de vitesse et de coût. Ces résultats doivent être traités comme des intrants décisionnels plutôt que comme des classements universels.
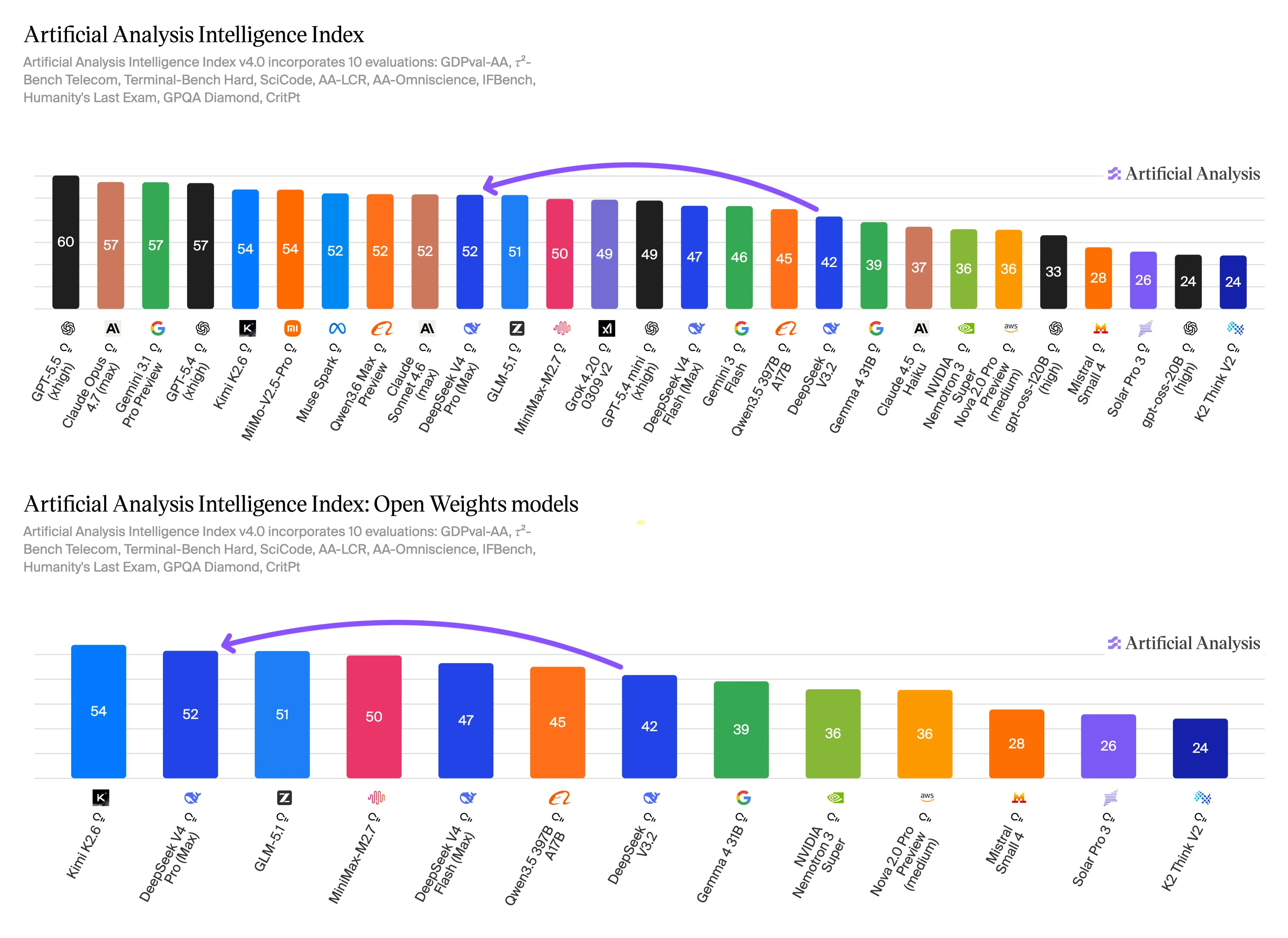
L’Indice d’Intelligence v4.0 couvre les évaluations pour le travail agentique, les tâches de terminal et de codage, le raisonnement en contexte long, les connaissances, le suivi d’instructions, le raisonnement scientifique et les tests de qualité connexes. Ce périmètre d’évaluation est pertinent ici car ces catégories recoupent la principale raison de choisir Pro : un travail multi-étapes plus difficile où une réponse de meilleure qualité peut justifier un coût unitaire plus élevé.
Flash reste compétitif sur la même échelle de référence, et son profil de vitesse et de prix en fait une option pratique pour les chemins de production qui exécutent de nombreuses invites similaires. Utilisez Flash pour le résumé de premier passage, la classification, l’extraction, l’assistance ou le routage. Passez à Pro lorsque l’invite est ambiguë, nécessite un raisonnement plus approfondi, touche une grande base de code ou a un coût d’échec élevé.
Avant de remplacer un modèle par un autre, exécutez votre propre ensemble d’invites sur les deux API. Suivez les réponses acceptées, le taux de nouvelles tentatives, la latence, le coût total des tokens, la fiabilité des sorties structurées et le comportement des appels d’outils. Les repères suggèrent par où commencer, mais le routage de production doit suivre votre charge de travail réelle.
Comment accéder aux deux API sur Novita AI
Les deux modèles utilisent l’API LLM compatible OpenAI de Novita AI. L’ID du modèle est le champ que vous modifiez pour basculer entre Pro et Flash.
Étape 1 : Confirmer les ID des modèles et la disponibilité
Utilisez les pages de modèles actuelles avant le déploiement :
- API et terrain de jeu DeepSeek V4 Pro :
deepseek/deepseek-v4-pro - API et terrain de jeu DeepSeek V4 Flash :
deepseek/deepseek-v4-flash
Le point de terminaison de liste de modèles Novita AI peut également être utilisé pour vérifier les objets et champs de modèle disponibles tels que l’ID du modèle, les champs de prix, le titre, la description et la taille du contexte.
Étape 2 : Utiliser l’URL de base compatible OpenAI
La référence API de Novita AI liste les points de terminaison compatibles OpenAI sous :
https://api.novita.ai/openai
Pour les complétions de chat, le point de terminaison est :
https://api.novita.ai/openai/v1/chat/completions
Les requêtes nécessitent un jeton porteur dans l’en-tête Authorization.
Étape 3 : Exécuter la même invite sur les deux modèles
Commencez par un petit ensemble d’évaluation représentatif du trafic réel : invites faciles, invites à contexte long, invites de codage, invites de style outil, invites d’extraction et invites sujettes aux échecs.
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-flash",
"messages": [
{
"role": "user",
"content": "Résumez les compromis entre le traitement par lots et le streaming pour une API de chat LLM."
}
],
"max_tokens": 500,
"temperature": 0.2
}'
Ensuite, changez uniquement l’ID du modèle :
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-pro",
"messages": [
{
"role": "user",
"content": "Résumez les compromis entre le traitement par lots et le streaming pour une API de chat LLM."
}
],
"max_tokens": 500,
"temperature": 0.2
}'
Étape 4 : Comparer les signaux de production
Pour chaque classe d’invite, enregistrez :
- la qualité et l’exactitude de la complétion
- la fiabilité du format de sortie
- le comportement de l’outil ou de l’appel de fonction si votre application en dépend
- le nombre total de tokens d’entrée et de sortie
- la latence sous la concurrence attendue
- le taux de nouvelles tentatives et le taux de repli
- le taux d’acceptation ou de modification visible par l’utilisateur
Ceci est particulièrement important si vous prévoyez d’acheminer les requêtes standard vers Flash et les escalades vers Pro.
Meilleurs cas d’utilisation : quand choisir chaque modèle
Choisissez DeepSeek V4 Pro pour les travaux complexes
Utilisez Pro lorsque la tâche nécessite un raisonnement plus approfondi ou un comportement agentique plus fort :
- analyse de codebase, revue de code et plans de refactoring
- agents de codage autonomes qui doivent raisonner sur plusieurs fichiers
- débogage en contexte long ou analyse d’incidents
- planification multi-étapes avec un coût d’échec élevé
- raisonnement mathématique, STEM ou de type programmation compétitive
- workflows utilisateur premium où la qualité de la réponse prime sur le coût unitaire
Le guide du contexte long de DeepSeek V4 Pro est le meilleur suivi interne lorsque le lecteur souhaite plus de détails sur l’utilisation de Pro pour les charges de travail à contexte long.
Choisissez DeepSeek V4 Flash pour le trafic produit scalable
Utilisez Flash lorsque la charge de travail bénéficie d’un prix unitaire inférieur et d’un service plus léger :
- fonctionnalités de chat et d’assistance à haut volume
- classification, routage, extraction et résumé
- explication de code de premier passage ou tâches de documentation
- workflows de support avec de nombreuses invites similaires
- traitement en arrière-plan où un repli vers Pro est disponible
- applications où la latence et le coût sont des contraintes fondamentales de l’expérience utilisateur
Le guide DeepSeek V4 Flash sur Novita AI est le compagnon de configuration naturel pour les développeurs qui choisissent Flash comme modèle par défaut.
Évitez de basculer aveuglément
Ne basculez pas simplement parce que deux modèles partagent la longueur de contexte et l’accès au point de terminaison. Avant la migration, vérifiez que le nouveau modèle préserve :
- le comportement de l’invite sur vos exemples de production
- la forme JSON ou des sorties structurées
- les arguments des appels d’outils et le comportement en cas d’échec
- la latence sous la concurrence attendue
- le coût total après les nouvelles tentatives et les sorties plus longues
- les garde-fous, le comportement de refus et la gestion des cas limites
Pour de nombreux systèmes, la meilleure réponse n’est ni Pro ni Flash. C’est une politique de routage qui utilise les deux.
Notes de migration pour les développeurs
Si vous migrez entre les deux modèles, l’ID du modèle est le premier champ à mettre à jour :
| Direction | Changement |
| Flash vers Pro | Remplacez deepseek/deepseek-v4-flash par deepseek/deepseek-v4-pro pour les invites plus difficiles. |
| Pro vers Flash | Remplacez deepseek/deepseek-v4-pro par deepseek/deepseek-v4-flash pour les invites de base sensibles aux coûts. |
| Routage mixte | Conservez les deux ID et acheminez selon la difficulté de la tâche, le niveau du compte ou le score d’évaluation. |
Liste de contrôle de migration :
- Confirmez la disponibilité actuelle du modèle sur les pages de modèles Novita AI.
- Confirmez les prix actuels avant de modifier les hypothèses de coût.
- Conservez la même URL de base et le même point de terminaison de complétions de chat pour les exemples de ce guide.
- Exécutez un ensemble de régression d’invites représentatif.
- Comparez la qualité de sortie par type de tâche, pas seulement le taux de victoire global.
- Suivez l’utilisation des tokens, la latence, les nouvelles tentatives et le taux de repli.
- Gardez un plan de retour qui peut rediriger le trafic vers l’ID du modèle précédent.
Recommandation finale
Pour la plupart des équipes, DeepSeek V4 Flash devrait être le premier modèle à tester pour le trafic de production à haut volume, car il liste des prix d’entrée, de sortie et de lecture du cache beaucoup plus bas tout en conservant les mêmes limites visibles de contexte et de sortie maximale que Pro sur Novita AI.
DeepSeek V4 Pro doit être réservé aux tâches où la qualité, la profondeur de raisonnement ou la fiabilité du codage agentique ont plus de valeur commerciale que le prix plus élevé des tokens. Si votre produit comprend à la fois des invites de routine et des invites difficiles, acheminez les requêtes de routine vers Flash et escaladez les requêtes plus difficiles vers Pro après que votre évaluation a confirmé la séparation.
FAQ
Quelle est la principale différence entre DeepSeek V4 Pro et DeepSeek V4 Flash ?
Sur Novita AI, la limite de contexte visible, la limite de sortie maximale, les modalités et le chemin de requête des complétions de chat utilisés dans ce guide sont les mêmes. La principale différence réside dans le positionnement et le prix : Pro est l’option priorisant la qualité pour le raisonnement complexe et le codage agentique, tandis que Flash est l’option à moindre coût pour les usages à haut volume et sensibles à la latence.
Les deux modèles sont-ils disponibles sur Novita AI ?
Oui. Novita AI propose des pages de modèles pour deepseek/deepseek-v4-pro et deepseek/deepseek-v4-flash, et les deux sont listés comme modèles LLM sans serveur.
DeepSeek V4 Flash est-il moins cher que DeepSeek V4 Pro ?
Au 9 juin 2026, les pages de modèles Novita AI actuelles listent Flash à 0,14 $ par million de tokens d’entrée et 0,28 $ par million de tokens de sortie, tandis que Pro est listé à 1,60 $ par million de tokens d’entrée et 3,20 $ par million de tokens de sortie.
Dois-je passer de Flash à Pro ?
Passez des charges de travail spécifiques à Pro lorsque Flash n’atteint pas votre objectif de qualité sur le codage complexe, le raisonnement en contexte long ou les tâches à coût d’échec élevé. Ne passez pas tout le trafic avant d’avoir comparé les vraies invites, le coût total, la latence et les cas d’échec.
Les deux modèles peuvent-ils utiliser le même point de terminaison de complétions de chat ?
Oui. Les pages de modèles Novita AI listent chat/completions pour les deux modèles, et la référence API documente le point de terminaison de complétions de chat compatible OpenAI à /openai/v1/chat/completions.
Les repères prouvent-ils que Pro est toujours meilleur que Flash ?
Non. Les données de référence rapportées donnent à Pro un score d’indice d’intelligence plus élevé, tandis que Flash montre une vitesse de sortie plus élevée, une latence de premier token plus faible et des prix de tokens listés plus bas. Utilisez Pro pour les tâches de raisonnement ou de codage plus difficiles, et testez Flash pour le trafic produit à haut volume.



