

複雑なエージェント型コーディング、長い推論、困難なマルチステップタスクにおいて、出力品質が単価よりも重要である場合はDeepSeek V4 Proを選択してください。同じ1,048,576トークンのコンテキストウィンドウ、同じ393,216トークンの最大出力制限を必要とし、大量リクエストやレイテンシーが重要なワークロードに対して、より低コストなAPIパスが必要な場合はDeepSeek V4 Flashを選択してください。両モデルはNovita AIのOpenAI互換LLM APIを通じて利用可能ですが、その価格設定とポジショニングは異なるプロダクションの役割を示しています。
DeepSeek V4 Pro vs DeepSeek V4 Flash: 簡単比較
モデルの適合性
| 項目 | DeepSeek V4 Pro | DeepSeek V4 Flash |
| 最適な用途 | 複雑なエージェントワークフロー、プロフェッショナル向けソフトウェア開発、高度な推論 | 高同時実行アプリ、軽量ワークロード、コスト重視のプロダクショントラフィック |
| 判断基準 | 失敗コストが高い場合に使用 | リクエスト量やレイテンシーが重要な場合に使用 |
APIと制限
| 項目 | DeepSeek V4 Pro | DeepSeek V4 Flash |
| モデルID | deepseek/deepseek-v4-pro |
deepseek/deepseek-v4-flash |
| 提供状況 | 利用可能、サーバーレスLLM | 利用可能、サーバーレスLLM |
| コンテキストウィンドウ | 1,048,576トークン | 1,048,576トークン |
| 最大出力トークン | 393,216トークン | 393,216トークン |
| 入出力モダリティ | テキスト入力、テキスト出力 | テキスト入力、テキスト出力 |
| APIリクエストパス | OpenAI互換のチャット完結 | OpenAI互換のチャット完結 |
価格の概要
| 項目 | DeepSeek V4 Pro | DeepSeek V4 Flash |
| 入力価格 | 100万トークンあたり$1.60 | 100万トークンあたり$0.14 |
| 出力価格 | 100万トークンあたり$3.20 | 100万トークンあたり$0.28 |
| キャッシュ読み取り価格 | 100万トークンあたり$0.135 | 100万トークンあたり$0.028 |
機能メモ
| 項目 | DeepSeek V4 Pro | DeepSeek V4 Flash |
| 掲載機能 | サーバーレス、関数呼び出し、構造化出力、推論 | サーバーレス、関数呼び出し、構造化出力、推論 |
| 実用的な注意 | 最も難しいプロンプトはProにルーティング | スケーラブルなベーストラフィックにはFlashを使用 |
ProとFlashの違いは何か?
最も重要な違いは、コンテキスト長や基本的なチャット完結アクセスではありません。Novita AIでは、両モデルとも1,048,576トークンのコンテキストウィンドウ、393,216の最大出力トークン、テキスト入力、テキスト出力、サーバーレス配信、関数呼び出し、構造化出力、推論サポートをリストしています。
実用的な違いは、ポジショニングと価格です。DeepSeek V4 Proモデルページでは、Proを複雑なエージェントワークフロー、プロフェッショナル向けソフトウェア開発、推論重視の評価、要求の厳しいコーディングタスク向けのフラッグシップオプションとして説明しています。DeepSeek V4 Flashモデルページでは、Flashを高速で経済的なAPIサービス、高同時実行、低レイテンシー、大規模な軽量ワークロード向けの軽量オプションとして位置付けています。
これにより、開発者は明確なルーティングパターンを得られます:
- Proは、不十分な回答がトークン価格の追加コストを上回る可能性があるタスクに使用します:自律的なコード変更、長時間のデバッグセッション、リポジトリ規模の分析、計画、困難な推論。
- Flashは、コストと応答性が製品体験を形作るリクエストに使用します:チャット支援、一次分類、要約、抽出、ルーティング、繰り返しのプロダクションコール。
- アプリケーションが「難しいプロンプト」と「標準的なプロンプト」を分離できる場合は、両方を使用します。Flashはほとんどのベーストラフィックを処理し、Proはエスカレーションやプレミアムワークフロー用に確保できます。
すでにDeepSeek V4 Flash導入ガイドを読んでいる場合は、このページを決定レイヤーとして扱ってください。ここでは、導入設定の繰り返しではなく、各APIをいつ選択するかについて説明します。
Novita AIでの価格比較
現在のNovita AIモデルページの価格は、2つのモデル間に大きなコスト差を示しています。
DeepSeek V4 Proの価格
| 項目 | 値 |
| 入力価格 | 100万トークンあたり$1.60 |
| 出力価格 | 100万トークンあたり$3.20 |
| キャッシュ読み取り入力価格 | 100万トークンあたり$0.135 |
| 使用する場面 | 複雑な推論、エージェント型コーディング、または失敗コストが高いタスク |
DeepSeek V4 Flashの価格
| 項目 | 値 |
| 入力価格 | 100万トークンあたり$0.14 |
| 出力価格 | 100万トークンあたり$0.28 |
| キャッシュ読み取り入力価格 | 100万トークンあたり$0.028 |
| 使用する場面 | 大量リクエスト、レイテンシー重視、またはコスト重視のプロダクショントラフィック |
入出力トークンにおいて、ProはFlashの約11.4倍の価格です。これは常にFlashの方がビジネス的に優れていることを意味するわけではありません。Proは、期待される品質の優位性が高い単価を正当化する場面で使用すべきです。
シンプルなプロダクションポリシーがうまく機能します:
- 明確な指示、短い評価基準、低い失敗コストを持つ大量のプロンプトにはデフォルトでFlashを使用します。
- ユーザーが難しいコーディング、マルチステップ推論、長いコンテキストの合成、または高リスクの回答を求めた場合はProにエスカレーションします。
- プロダクションルーティングを変更する前に、代表的なプロンプトセットでシャドウテストを実施します。トークン単価だけでなく、出力品質、リトライ、ユーザー受容性、総トークン数、レイテンシー、障害ケースを比較します。
価格は変更される可能性があるため、価格に敏感なワークフローや見積もりを公開する前に、現在のモデルページを確認してください。
ベンチマークとパフォーマンスシグナル
Artificial Analysisのベンチマークデータは、品質重視とスループット重視の使用法の間の明確なトレードオフを示しています。DeepSeek V4 Proは高いインテリジェンススコアを報告している一方、DeepSeek V4 Flashは優れた速度とコスト指標を報告しています。これらの結果は、普遍的なランキングではなく、意思決定のインプットとして扱うべきです。
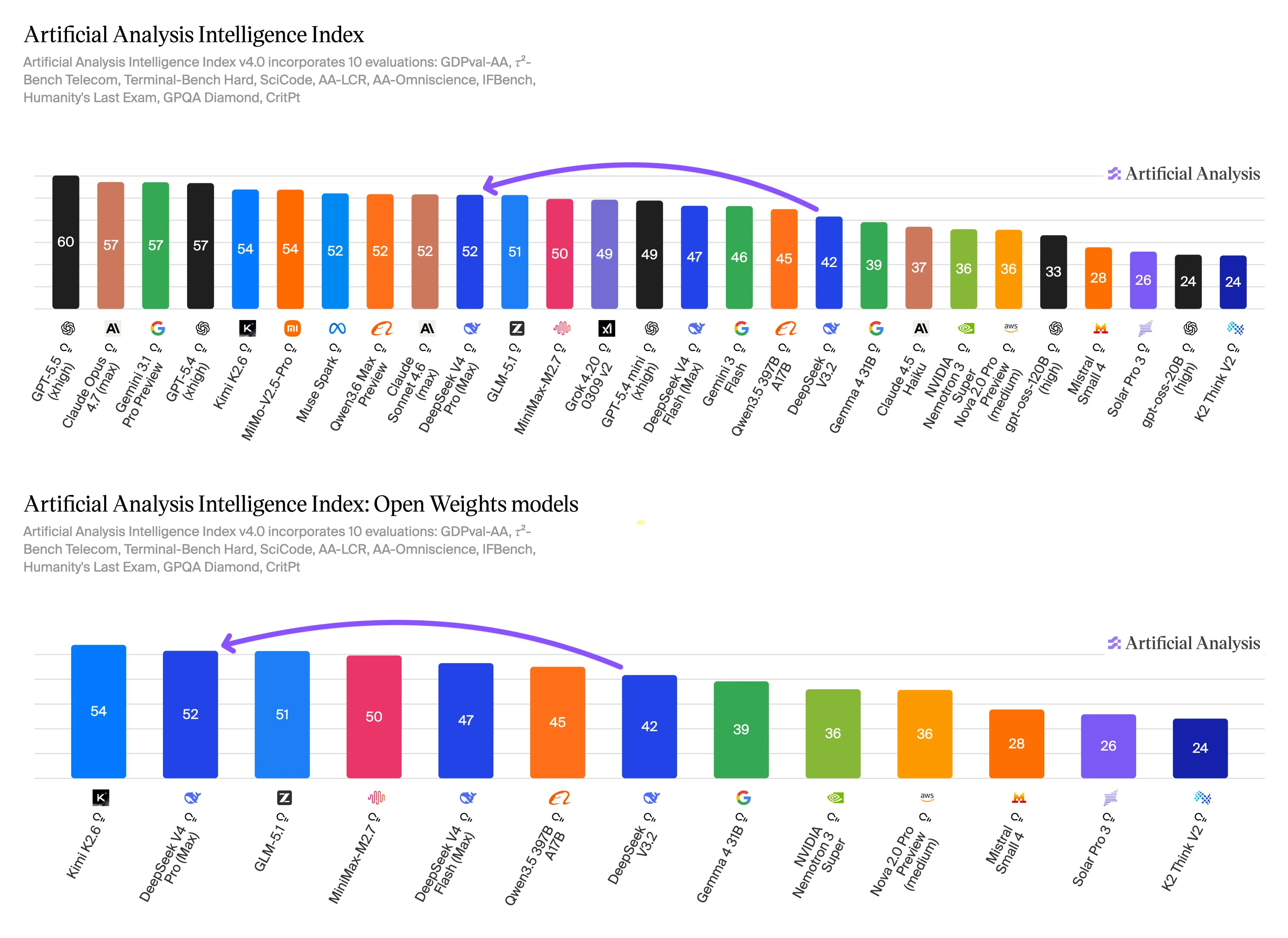
Intelligence Index v4.0は、エージェント作業、ターミナルおよびコーディングタスク、長文脈推論、知識、指示追従、科学的推論、および関連する品質テストの評価をカバーしています。この評価範囲は、Proを選ぶ主な理由である「より困難なマルチステップ作業で、高品質な回答が高い単価を正当化できる」という点と重なるため、ここに関連があります。
Flashは同じベンチマークスケールで競争力のあるパフォーマンスを示しており、その速度と価格プロファイルは、多数の類似プロンプトを実行するプロダクションパスの実用的な選択肢となります。Flashは一次要約、分類、抽出、サポート支援、ルーティングに使用します。プロンプトが曖昧で、より深い推論が必要で、大規模なコードベースに触れる場合、または失敗コストが高い場合はProにエスカレーションします。
一方のモデルを他方に置き換える前に、両方のAPIで独自のプロンプトセットを実行してください。受け入れられた回答、リトライ率、レイテンシー、総トークンコスト、構造化出力の信頼性、ツール呼び出しの動作を追跡します。ベンチマークは出発点を示しますが、プロダクションルーティングは実際のワークロードに従うべきです。
Novita AIで両方のAPIにアクセスする方法
両モデルともNovita AIのOpenAI互換LLM APIを使用します。モデルIDは、ProとFlashを切り替える際に変更するフィールドです。
ステップ1: モデルIDと利用可能性を確認
デプロイ前に現在のモデルページを使用してください:
- DeepSeek V4 Pro APIとプレイグラウンド:
deepseek/deepseek-v4-pro - DeepSeek V4 Flash APIとプレイグラウンド:
deepseek/deepseek-v4-flash
Novita AIのモデル一覧エンドポイントを使用して、利用可能なモデルオブジェクトやフィールド(モデルID、価格フィールド、タイトル、説明、コンテキストサイズなど)を確認することもできます。
ステップ2: OpenAI互換のベースURLを使用
Novita AIのAPIリファレンスには、以下のOpenAI互換エンドポイントがリストされています:
https://api.novita.ai/openai
チャット完結の場合、エンドポイントは:
https://api.novita.ai/openai/v1/chat/completions
リクエストにはAuthorizationヘッダーにBearerトークンが必要です。
ステップ3: 同じプロンプトを両モデルに対して実行
実際のトラフィックを代表する小さな評価セットから始めます:簡単なプロンプト、長文脈プロンプト、コーディングプロンプト、ツール形式のプロンプト、抽出プロンプト、失敗しやすいプロンプト。
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-flash",
"messages": [
{
"role": "user",
"content": "LLMチャットAPIにおけるバッチ処理とストリーミングのトレードオフを要約してください。"
}
],
"max_tokens": 500,
"temperature": 0.2
}'
次に、モデルIDのみを切り替えます:
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-pro",
"messages": [
{
"role": "user",
"content": "LLMチャットAPIにおけるバッチ処理とストリーミングのトレードオフを要約してください。"
}
],
"max_tokens": 500,
"temperature": 0.2
}'
ステップ4: プロダクションシグナルを比較
プロンプトのクラスごとに以下を記録します:
- 完結品質と正確性
- 出力形式の信頼性
- アプリが依存するツールや関数呼び出しの動作
- 総入力トークンと出力トークン
- 予想される同時実行下でのレイテンシー
- リトライ率とフォールバック率
- ユーザーから見える受入率や編集率
これは、標準リクエストをFlashに、エスカレーションをProにルーティングする予定がある場合に特に重要です。
最適なユースケース: 各モデルを選択するタイミング
複雑な作業にはDeepSeek V4 Proを選択
Proは、より深い推論や強力なエージェント動作が必要なタスクに使用します:
- コードベース分析、コードレビュー、リファクタリング計画
- 複数ファイルにわたって推論する必要がある自律型コーディングエージェント
- 長文脈のデバッグやインシデント分析
- 失敗コストが高いマルチステップ計画
- 数学、STEM、競技プログラミング形式の推論
- 回答品質が単価よりも重要なプレミアムユーザーワークフロー
DeepSeek V4 Pro長文脈ガイドは、読者がProを長文脈ワークロードに使用する詳細を知りたい場合の優れたフォローアップ資料です。
スケーラブルなプロダクショントラフィックにはDeepSeek V4 Flashを選択
Flashは、低単価と軽量なサービスがメリットとなるワークロードに使用します:
- 大量のチャットおよびアシスタント機能
- 分類、ルーティング、抽出、要約
- 一次的なコード説明やドキュメント作成タスク
- 多くの類似プロンプトを含むサポートワークフロー
- Proへのフォールバックが可能なバックグラウンド処理
- レイテンシーとコストが中核的なユーザー体験の制約となるアプリケーション
Novita AI上のDeepSeek V4 Flashガイドは、デフォルトモデルとしてFlashを選択する開発者にとって自然なセットアップの伴走資料です。
盲目的に切り替えない
2つのモデルがコンテキスト長とエンドポイントアクセスを共有しているからといって、純粋に切り替えないでください。移行前に、新しいモデルが以下を維持していることを確認します:
- プロダクション例でのプロンプト動作
- JSONまたは構造化出力の形状
- ツール呼び出しの引数と失敗動作
- 予想される同時実行下でのレイテンシー
- リトライや長い出力後の総コスト
- ガードレール、拒否動作、エッジケースの処理
多くのシステムでは、最良の答えはProまたはFlashのどちらかではありません。両方を使用するルーティングポリシーです。
開発者向け移行ノート
2つのモデル間で移行する場合、最初に更新するフィールドはモデルIDです:
| 方向 | 変更内容 |
| Flash → Pro | 難しいプロンプトに対してdeepseek/deepseek-v4-flashをdeepseek/deepseek-v4-proに置き換えます。 |
| Pro → Flash | コスト重視のベースラインプロンプトに対してdeepseek/deepseek-v4-proをdeepseek/deepseek-v4-flashに置き換えます。 |
| 混合ルーティング | 両方のIDを保持し、タスクの難易度、アカウント階層、評価スコアでルーティングします。 |
移行チェックリスト:
- Novita AIモデルページで現在のモデル利用可能性を確認します。
- コスト前提を変更する前に現在の価格を確認します。
- このガイドの例では、同じベースURLとチャット完結エンドポイントを維持します。
- 代表的なプロンプト回帰セットを実行します。
- 出力品質をタスクタイプ別に比較し、総合勝率だけで判断しない。
- トークン使用量、レイテンシー、リトライ、フォールバック率を追跡します。
- トラフィックを以前のモデルIDに戻せるロールバック計画を維持します。
最終推奨
ほとんどのチームにとって、DeepSeek V4 Flashは大量プロダクショントラフィックで最初にテストすべきモデルです。なぜなら、Novita AI上でProと同じ可視のコンテキストおよび最大出力制限を維持しながら、はるかに低い入力、出力、キャッシュ読み取り価格をリストしているからです。
DeepSeek V4 Proは、品質、推論の深さ、またはエージェント型コーディングの信頼性が、より高いトークン価格よりもビジネス価値が高いタスクに予約すべきです。製品に日常的なプロンプトと難しいプロンプトの両方が含まれる場合は、日常的なリクエストをFlashにルーティングし、評価で分割が確認された後により難しいリクエストをProにエスカレーションします。
FAQ
DeepSeek V4 ProとDeepSeek V4 Flashの主な違いは何ですか?
Novita AI上では、このガイドで使用されている可視のコンテキスト制限、最大出力制限、モダリティ、チャット完結リクエストパスは同じです。主な違いはポジショニングと価格です。Proは複雑な推論とエージェント型コーディング向けの品質重視オプションであり、Flashは大量リクエストとレイテンシー重視の使用向けの低コストオプションです。
両モデルともNovita AIで利用可能ですか?
はい。Novita AIにはdeepseek/deepseek-v4-proおよびdeepseek/deepseek-v4-flashのモデルページがあり、両方ともサーバーレスLLMモデルとしてリストされています。
DeepSeek V4 FlashはDeepSeek V4 Proより安いですか?
2026年6月9日現在のNovita AIモデルページでは、Flashが100万入力トークンあたり$0.14、100万出力トークンあたり$0.28、Proが100万入力トークンあたり$1.60、100万出力トークンあたり$3.20とリストされています。
FlashからProにアップグレードすべきですか?
Flashが複雑なコーディング、長文脈推論、または高い失敗コストが伴うタスクで品質目標を満たさない場合に、特定のワークロードをProにアップグレードします。実際のプロンプト、総コスト、レイテンシー、障害ケースを比較するまで、すべてのトラフィックをアップグレードしないでください。
両モデルとも同じチャット完結エンドポイントを使用できますか?
はい。Novita AIのモデルページでは、両モデルともchat/completionsをリストしており、APIリファレンスはOpenAI互換のチャット完結エンドポイントを/openai/v1/chat/completionsとして文書化しています。
ベンチマークはProが常にFlashより優れていることを証明していますか?
いいえ。報告されているベンチマークデータでは、Proが高いインテリジェンス指標スコアを示し、Flashが高い出力速度、低い最初のトークン遅延、低いリスト価格を示しています。難しい推論やコーディングタスクにはProを使用し、大量のプロダクショントラフィックにはFlashをテストしてください。



