

복잡한 에이전트 코딩, 긴 추론, 또는 어려운 다단계 작업에서 출력 품질이 단가보다 중요하다면 DeepSeek V4 Pro를 선택하세요. 동일한 1,048,576 토큰 컨텍스트 윈도우, 동일한 393,216 토큰 최대 출력 제한이 필요하고 대규모 트래픽이나 지연 시간에 민감한 워크로드를 위한 저렴한 API 경로가 필요하다면 DeepSeek V4 Flash를 선택하세요. 두 모델 모두 Novita AI의 OpenAI 호환 LLM API를 통해 사용할 수 있지만, 가격과 포지셔닝은 서로 다른 프로덕션 역할을 가리킵니다.
DeepSeek V4 Pro vs DeepSeek V4 Flash: 빠른 비교
모델 적합성
| 필드 | DeepSeek V4 Pro | DeepSeek V4 Flash |
|---|---|---|
| 최적 용도 | 복잡한 에이전트 워크플로, 전문가 수준 소프트웨어 개발, 어려운 추론 | 높은 동시성 앱, 가벼운 워크로드, 비용에 민감한 프로덕션 트래픽 |
| 결정 규칙 | 실패 비용이 높은 경우 사용 | 요청 볼륨이나 지연 시간이 더 중요한 경우 사용 |
API 및 제한 사항
| 필드 | DeepSeek V4 Pro | DeepSeek V4 Flash |
|---|---|---|
| 모델 ID | deepseek/deepseek-v4-pro |
deepseek/deepseek-v4-flash |
| 가용성 | 사용 가능, 서버리스 LLM | 사용 가능, 서버리스 LLM |
| 컨텍스트 윈도우 | 1,048,576 토큰 | 1,048,576 토큰 |
| 최대 출력 토큰 | 393,216 토큰 | 393,216 토큰 |
| 입력/출력 모달리티 | 텍스트 입력, 텍스트 출력 | 텍스트 입력, 텍스트 출력 |
| API 요청 경로 | OpenAI 호환 채팅 완성 | OpenAI 호환 채팅 완성 |
가격 요약
| 필드 | DeepSeek V4 Pro | DeepSeek V4 Flash |
|---|---|---|
| 입력 가격 | 100만 토큰당 $1.60 | 100만 토큰당 $0.14 |
| 출력 가격 | 100만 토큰당 $3.20 | 100만 토큰당 $0.28 |
| 캐시 읽기 가격 | 100만 토큰당 $0.135 | 100만 토큰당 $0.028 |
기능 참고 사항
| 필드 | DeepSeek V4 Pro | DeepSeek V4 Flash |
|---|---|---|
| 나열된 기능 | 서버리스, 함수 호출, 구조화된 출력, 추론 | 서버리스, 함수 호출, 구조화된 출력, 추론 |
| 실용적 참고 | 가장 어려운 프롬프트는 Pro로 보내세요 | 확장 가능한 기본 트래픽에는 Flash를 사용하세요 |
Pro와 Flash 사이의 변화는 무엇인가요?
가장 중요한 변화는 컨텍스트 길이나 기본 채팅 완성 접근이 아닙니다. Novita AI에서 두 모델 모두 1,048,576 토큰 컨텍스트 윈도우, 393,216 최대 출력 토큰, 텍스트 입력, 텍스트 출력, 서버리스 제공, 함수 호출, 구조화된 출력, 추론 지원을 제공합니다.
실용적인 차이는 포지셔닝과 가격입니다. DeepSeek V4 Pro 모델 페이지는 Pro를 복잡한 에이전트 워크플로, 전문가 수준 소프트웨어 개발, 추론 중심 평가, 까다로운 코딩 작업을 위한 플래그십 옵션으로 설명합니다. DeepSeek V4 Flash 모델 페이지는 Flash를 빠르고 경제적인 API 서비스, 높은 동시성, 낮은 지연 시간, 대규모 가벼운 워크로드를 위한 경량 옵션으로 자리매김합니다.
이는 개발자에게 명확한 라우팅 패턴을 제공합니다:
- 잘못된 답변 하나가 추가 토큰 비용보다 더 큰 비용을 초래할 수 있는 작업(자율 코드 변경, 긴 디버깅 세션, 리포지토리 수준 분석, 계획, 어려운 추론)에는 Pro를 사용하세요.
- 비용과 응답성이 제품 경험을 결정하는 요청(채팅 지원, 1차 분류, 요약, 추출, 라우팅, 반복적인 프로덕션 호출)에는 Flash를 사용하세요.
- 애플리케이션이 "어려운 프롬프트"와 "일반 프롬프트"를 분리할 수 있다면 둘 다 사용하세요. Flash는 대부분의 기본 트래픽을 처리하고, Pro는 에스컬레이션이나 프리미엄 워크플로를 위해 예약할 수 있습니다.
이미 DeepSeek V4 Flash 출시 가이드를 읽었다면, 이 페이지를 결정 레이어로 취급하세요. 즉, 설정을 반복하는 방법이 아니라 각 API를 언제 선택해야 하는지에 대한 내용입니다.
Novita AI 가격 비교
현재 Novita AI 모델 페이지 가격은 두 모델 간 큰 비용 차이를 보여줍니다.
DeepSeek V4 Pro 가격
| 필드 | 값 |
|---|---|
| 입력 가격 | 100만 토큰당 $1.60 |
| 출력 가격 | 100만 토큰당 $3.20 |
| 캐시 읽기 입력 가격 | 100만 토큰당 $0.135 |
| 사용 시기 | 복잡한 추론, 에이전트 코딩, 또는 실패 비용이 높은 작업 |
DeepSeek V4 Flash 가격
| 필드 | 값 |
|---|---|
| 입력 가격 | 100만 토큰당 $0.14 |
| 출력 가격 | 100만 토큰당 $0.28 |
| 캐시 읽기 입력 가격 | 100만 토큰당 $0.028 |
| 사용 시기 | 대규모, 지연 시간 민감, 또는 비용 민감 프로덕션 트래픽 |
입력 및 출력 토큰의 경우 Pro는 Flash 가격의 약 11.4배입니다. 이것이 Flash가 항상 더 나은 비즈니스 선택임을 의미하지는 않습니다. Pro는 예상되는 품질 우위가 더 높은 단가를 정당화할 수 있는 곳에 사용해야 합니다.
간단한 프로덕션 정책이 잘 작동합니다:
- 명확한 지침, 짧은 평가 기준, 낮은 실패 비용이 있는 대규모 프롬프트에는 기본적으로 Flash를 사용하세요.
- 사용자가 어려운 코딩, 다단계 추론, 긴 컨텍스트 합성, 또는 높은 위험도의 답변을 요청할 때 Pro로 에스컬레이션하세요.
- 프로덕션 라우팅을 변경하기 전에 대표적인 프롬프트 세트로 섀도 테스트를 실행하세요. 토큰당 가격뿐만 아니라 출력 품질, 재시도, 사용자 수용도, 총 토큰, 지연 시간, 실패 사례를 비교하세요.
가격은 변경될 수 있으므로, 비용에 민감한 워크플로나 견적을 게시하기 전에 현재 모델 페이지를 확인하세요.
벤치마크 및 성능 신호
Artificial Analysis의 벤치마크 데이터는 품질 중심 사용과 처리량 중심 사용 사이의 명확한 트레이드오프를 나타냅니다. DeepSeek V4 Pro는 더 높은 지능 점수를 보고하는 반면, DeepSeek V4 Flash는 더 강력한 속도 및 비용 지표를 보고합니다. 이러한 결과는 보편적인 순위보다는 결정 입력으로 취급해야 합니다.
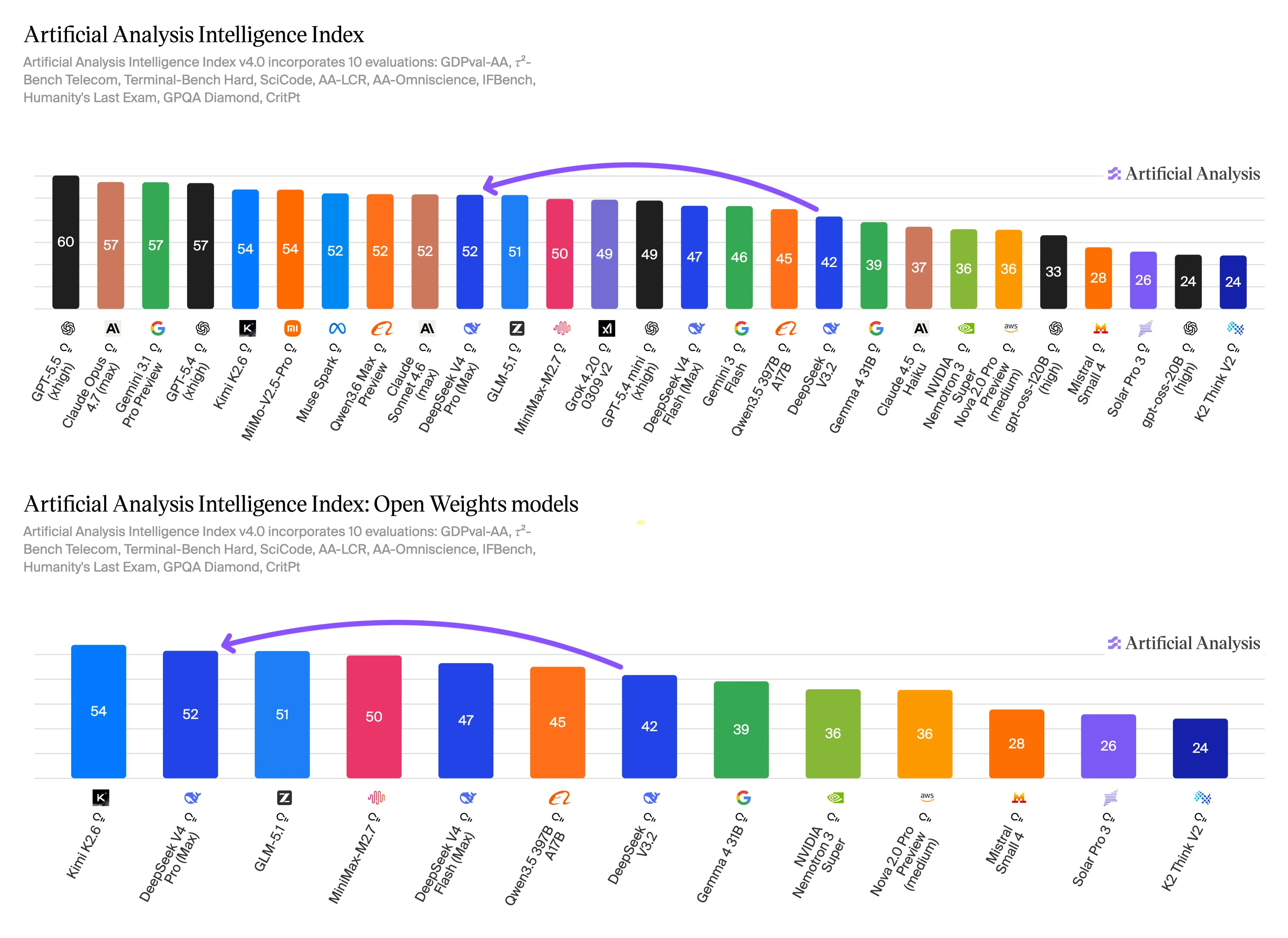
Intelligence Index v4.0은 에이전트 작업, 터미널 및 코딩 작업, 긴 컨텍스트 추론, 지식, 지시 따르기, 과학적 추론 및 관련 품질 테스트에 대한 평가를 포함합니다. 이 평가 범위는 더 높은 품질의 답변이 더 높은 단가를 정당화할 수 있는 더 어려운 다단계 작업을 Pro를 선택하는 주된 이유와 겹치기 때문에 여기서 관련이 있습니다.
Flash는 동일한 벤치마크 척도에서 여전히 경쟁력 있는 성능을 보여주며, 속도와 가격 프로필은 많은 유사한 프롬프트를 실행하는 프로덕션 경로에 실용적인 옵션입니다. 1차 요약, 분류, 추출, 지원 지원 또는 라우팅에는 Flash를 사용하세요. 프롬프트가 모호하거나, 더 깊은 추론이 필요하거나, 큰 코드베이스를 다루거나, 실패 비용이 높은 경우 Pro로 에스컬레이션하세요.
한 모델을 다른 모델로 교체하기 전에 두 API에 대해 자체 프롬프트 세트를 실행하세요. 수락된 답변, 재시도율, 지연 시간, 총 토큰 비용, 구조화된 출력 신뢰성, 도구 호출 동작을 추적하세요. 벤치마크는 시작점을 제시하지만, 프로덕션 라우팅은 실제 워크로드를 따라야 합니다.
Novita AI에서 두 API에 접근하는 방법
두 모델 모두 Novita AI의 OpenAI 호환 LLM API를 사용합니다. 모델 ID는 Pro와 Flash 사이를 전환할 때 변경하는 필드입니다.
1단계: 모델 ID 및 가용성 확인
배포 전에 현재 모델 페이지를 사용하세요:
- DeepSeek V4 Pro API 및 플레이그라운드:
deepseek/deepseek-v4-pro - DeepSeek V4 Flash API 및 플레이그라운드:
deepseek/deepseek-v4-flash
Novita AI 모델 목록 엔드포인트를 사용하여 사용 가능한 모델 객체와 모델 ID, 가격 필드, 제목, 설명, 컨텍스트 크기와 같은 필드를 확인할 수도 있습니다.
2단계: OpenAI 호환 기본 URL 사용
Novita AI의 API 참조는 OpenAI 호환 엔드포인트를 다음과 같이 나열합니다:
https://api.novita.ai/openai
채팅 완성의 경우 엔드포인트는 다음과 같습니다:
https://api.novita.ai/openai/v1/chat/completions
요청에는 Authorization 헤더에 Bearer 토큰이 필요합니다.
3단계: 두 모델에 대해 동일한 프롬프트 실행
실제 트래픽을 대표하는 작은 평가 세트로 시작하세요: 쉬운 프롬프트, 긴 컨텍스트 프롬프트, 코딩 프롬프트, 도구 스타일 프롬프트, 추출 프롬프트, 실패하기 쉬운 프롬프트.
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-flash",
"messages": [
{
"role": "user",
"content": "Summarize the tradeoffs between batching and streaming for an LLM chat API."
}
],
"max_tokens": 500,
"temperature": 0.2
}'
그런 다음 모델 ID만 변경합니다:
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-pro",
"messages": [
{
"role": "user",
"content": "Summarize the tradeoffs between batching and streaming for an LLM chat API."
}
],
"max_tokens": 500,
"temperature": 0.2
}'
4단계: 프로덕션 신호 비교
각 프롬프트 클래스에 대해 다음을 기록하세요:
- 완성 품질 및 정확성
- 출력 형식 신뢰성
- 앱이 의존하는 경우 도구 또는 함수 호출 동작
- 총 입력 및 출력 토큰
- 예상 동시성 하의 지연 시간
- 재시도율 및 폴백율
- 사용자에게 보이는 수락 또는 편집율
이는 표준 요청을 Flash로, 에스컬레이션을 Pro로 라우팅할 계획이라면 특히 중요합니다.
최적 사용 사례: 각 모델을 선택해야 하는 경우
복잡한 작업에는 DeepSeek V4 Pro를 선택하세요
더 깊은 추론이나 더 강력한 에이전트 동작이 필요한 작업에 Pro를 사용하세요:
- 코드베이스 분석, 코드 리뷰, 리팩토링 계획
- 여러 파일에 걸쳐 추론해야 하는 자율 코딩 에이전트
- 긴 컨텍스트 디버깅 또는 인시던트 분석
- 실패 비용이 높은 다단계 계획
- 수학, STEM, 또는 경쟁 프로그래밍 스타일 추론
- 답변 품질이 단가보다 중요한 프리미엄 사용자 워크플로
DeepSeek V4 Pro 긴 컨텍스트 가이드는 긴 컨텍스트 워크로드에 Pro를 사용하는 방법에 대한 자세한 내용을 원할 때 더 나은 내부 후속 자료입니다.
확장 가능한 제품 트래픽에는 DeepSeek V4 Flash를 선택하세요
더 낮은 단가와 더 가벼운 서빙의 이점을 누리는 워크로드에는 Flash를 사용하세요:
- 대규모 채팅 및 어시스턴트 기능
- 분류, 라우팅, 추출, 요약
- 1차 코드 설명 또는 문서화 작업
- 많은 유사한 프롬프트가 있는 지원 워크플로
- Pro로의 폴백이 가능한 백그라운드 처리
- 지연 시간과 비용이 핵심 사용자 경험 제약 조건인 애플리케이션
Novita AI의 DeepSeek V4 Flash 가이드는 Flash를 기본 모델로 선택하는 개발자를 위한 자연스러운 설정 동반 자료입니다.
맹목적으로 전환하지 마세요
두 모델이 컨텍스트 길이와 엔드포인트 접근을 공유한다고 해서 순수하게 전환하지 마세요. 마이그레이션 전에 새 모델이 다음을 유지하는지 확인하세요:
- 프로덕션 예제에 대한 프롬프트 동작
- JSON 또는 구조화된 출력 형태
- 도구 호출 인수 및 실패 동작
- 예상 동시성 하의 지연 시간
- 재시도 및 더 긴 출력 후 총 비용
- 가드레일, 거부 동작, 엣지 케이스 처리
많은 시스템에서 최고의 답변은 Pro 또는 Flash가 아닙니다. 둘 다 사용하는 라우팅 정책입니다.
개발자를 위한 마이그레이션 참고 사항
두 모델 간에 마이그레이션하는 경우 모델 ID가 가장 먼저 업데이트해야 할 필드입니다:
| 방향 | 변경 |
|---|---|
| Flash -> Pro | 더 어려운 프롬프트에 대해 deepseek/deepseek-v4-flash를 deepseek/deepseek-v4-pro로 교체 |
| Pro -> Flash | 비용 민감 기본 프롬프트에 대해 deepseek/deepseek-v4-pro를 deepseek/deepseek-v4-flash로 교체 |
| 혼합 라우팅 | 두 ID를 모두 유지하고 작업 난이도, 계정 등급 또는 평가 점수에 따라 라우팅 |
마이그레이션 체크리스트:
- Novita AI 모델 페이지에서 현재 모델 가용성 확인
- 비용 가정을 변경하기 전에 현재 가격 확인
- 이 가이드의 예제에 대해 동일한 기본 URL 및 채팅 완성 엔드포인트 유지
- 대표적인 프롬프트 회귀 세트 실행
- 집계 승률뿐만 아니라 작업 유형별로 출력 품질 비교
- 토큰 사용량, 지연 시간, 재시도, 폴백율 추적
- 트래픽을 이전 모델 ID로 다시 전환할 수 있는 롤백 계획 유지
최종 권장 사항
대부분의 팀의 경우, DeepSeek V4 Flash는 대규모 프로덕션 트래픽에 대해 가장 먼저 테스트해야 할 모델입니다. Pro와 동일한 가시적인 컨텍스트 및 최대 출력 제한을 유지하면서 Novita AI에서 훨씬 낮은 입력, 출력 및 캐시 읽기 가격을 나열하기 때문입니다.
DeepSeek V4 Pro는 품질, 추론 깊이 또는 에이전트 코딩 신뢰성이 더 높은 토큰 가격보다 더 많은 비즈니스 가치를 지닌 작업을 위해 예약해야 합니다. 제품에 일상적인 프롬프트와 어려운 프롬프트가 모두 포함되어 있다면, 평가를 통해 분할을 확인한 후 일상적인 요청을 Flash로 라우팅하고 더 어려운 요청을 Pro로 에스컬레이션하세요.
자주 묻는 질문
DeepSeek V4 Pro와 DeepSeek V4 Flash의 주요 차이점은 무엇인가요?
Novita AI에서 이 가이드에 사용된 가시적인 컨텍스트 제한, 최대 출력 제한, 모달리티 및 채팅 완성 요청 경로는 동일합니다. 주요 차이점은 포지셔닝과 가격입니다. Pro는 복잡한 추론 및 에이전트 코딩을 위한 품질 우선 옵션이고, Flash는 대규모 및 지연 시간에 민감한 사용을 위한 저비용 옵션입니다.
두 모델 모두 Novita AI에서 사용할 수 있나요?
예. Novita AI에는 deepseek/deepseek-v4-pro와 deepseek/deepseek-v4-flash 모두에 대한 모델 페이지가 있으며, 둘 다 서버리스 LLM 모델로 나열되어 있습니다.
DeepSeek V4 Flash가 DeepSeek V4 Pro보다 저렴한가요?
2026년 6월 9일 기준, 현재 Novita AI 모델 페이지는 Flash를 입력 토큰 100만 개당 $0.14, 출력 토큰 100만 개당 $0.28로 나열하고, Pro는 입력 토큰 100만 개당 $1.60, 출력 토큰 100만 개당 $3.20으로 나열합니다.
Flash에서 Pro로 업그레이드해야 하나요?
복잡한 코딩, 긴 컨텍스트 추론 또는 실패 비용이 높은 작업에서 Flash가 품질 목표를 충족하지 못할 경우 특정 워크로드를 Pro로 업그레이드하세요. 실제 프롬프트, 총 비용, 지연 시간 및 실패 사례를 비교할 때까지 모든 트래픽을 업그레이드하지 마세요.
두 모델 모두 동일한 채팅 완성 엔드포인트를 사용할 수 있나요?
예. Novita AI의 모델 페이지는 두 모델 모두에 대해 chat/completions를 나열하며, API 참조는 OpenAI 호환 채팅 완성 엔드포인트를 /openai/v1/chat/completions로 문서화합니다.
벤치마크가 Pro가 항상 Flash보다 낫다는 것을 증명하나요?
아니요. 보고된 벤치마크 데이터는 Pro에게 더 높은 Intelligence Index 점수를 주고, Flash는 더 높은 출력 속도, 더 낮은 첫 토큰 지연 시간, 더 낮은 나열된 토큰 가격을 보여줍니다. 더 어려운 추론 또는 코딩 작업에는 Pro를 사용하고, 대규모 제품 트래픽에는 Flash를 테스트하세요.



