

- DeepSeek V4 Pro против DeepSeek V4 Flash: краткое сравнение
- Что меняется между Pro и Flash?
- Сравнение цен на Novita AI
- Бенчмарки и сигналы производительности
- Как получить доступ к обоим API на Novita AI
- Лучшие сценарии использования: когда выбирать каждую модель
- Заметки по миграции для разработчиков
- Итоговая рекомендация
- Часто задаваемые вопросы
Выбирайте DeepSeek V4 Pro, когда качество вывода при сложных агентных задачах кодинга, длительных рассуждениях или многошаговых задачах важнее стоимости единицы; выбирайте DeepSeek V4 Flash, когда вам нужно то же окно контекста на 1 048 576 токенов, тот же лимит вывода на 393 216 токенов и более дешёвый API-путь для высоконагруженных или чувствительных к задержкам рабочих нагрузок. Обе модели доступны через совместимый с OpenAI LLM API от Novita AI, но их ценообразование и позиционирование указывают на разные роли в производстве.
DeepSeek V4 Pro против DeepSeek V4 Flash: краткое сравнение
Соответствие модели
| Поле | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Лучше всего для | Сложных агентных процессов, профессиональной разработки ПО, трудных рассуждений | Высококонкурентных приложений, лёгких рабочих нагрузок, чувствительного к стоимости продакшн-трафика |
| Правило принятия решения | Используйте, когда цена ошибки высока | Используйте, когда важнее объём запросов или задержка |
API и лимиты
| Поле | DeepSeek V4 Pro | DeepSeek V4 Flash |
| ID модели | deepseek/deepseek-v4-pro |
deepseek/deepseek-v4-flash |
| Доступность | Доступна, serverless LLM | Доступна, serverless LLM |
| Окно контекста | 1 048 576 токенов | 1 048 576 токенов |
| Макс. выводимых токенов | 393 216 токенов | 393 216 токенов |
| Модальность ввода/вывода | Текстовый ввод, текстовый вывод | Текстовый ввод, текстовый вывод |
| Путь запроса API | Совместимые с OpenAI chat completions | Совместимые с OpenAI chat completions |
Краткий обзор цен
| Поле | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Цена ввода | $1.60 за 1M токенов | $0.14 за 1M токенов |
| Цена вывода | $3.20 за 1M токенов | $0.28 за 1M токенов |
| Цена чтения кэша | $0.135 за 1M токенов | $0.028 за 1M токенов |
Особенности
| Поле | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Заявленные возможности | Serverless, вызов функций, структурированные выводы, рассуждения | Serverless, вызов функций, структурированные выводы, рассуждения |
| Практическое замечание | Направляйте самые сложные промпты на Pro | Используйте Flash для масштабируемого базового трафика |
Что меняется между Pro и Flash?
Самое важное изменение — не длина контекста или базовый доступ к chat completions. На Novita AI обе модели указывают окно контекста 1 048 576 токенов, максимум вывода 393 216 токенов, текстовый ввод, текстовый вывод, serverless-доставку, вызов функций, структурированные выводы и поддержку рассуждений.
Практическое различие — в позиционировании и цене. Страница модели DeepSeek V4 Pro описывает Pro как флагманский вариант для сложных агентных процессов, профессиональной разработки ПО, оценочных тестов на рассуждения и требовательных задач кодинга. Страница модели DeepSeek V4 Flash позиционирует Flash как лёгкий вариант для быстрого и экономичного API-сервиса, высокой конкурентности, низкой задержки и крупномасштабных лёгких рабочих нагрузок.
Это даёт разработчикам чёткий паттерн маршрутизации:
- Используйте Pro для задач, где один плохой ответ может обойтись дороже дополнительной цены токена: автономные изменения кода, длительные сессии отладки, анализ на уровне репозитория, планирование и сложные рассуждения.
- Используйте Flash для запросов, где стоимость и скорость отклика формируют пользовательский опыт: чат-ассистенты, первичная классификация, суммаризация, извлечение, маршрутизация и повторяющиеся продакшн-вызовы.
- Используйте обе модели, когда ваше приложение может разделять «сложные» и «стандартные» промпты. Flash может обрабатывать большую часть базового трафика, а Pro можно резервировать для эскалаций или премиальных процессов.
Если вы уже читали руководство по запуску DeepSeek V4 Flash, рассматривайте эту страницу как слой принятия решений: она о том, когда выбирать каждый API, а не о повторении настройки запуска.
Сравнение цен на Novita AI
Текущие цены на страницах моделей Novita AI показывают большой разрыв в стоимости между двумя моделями:
Цены DeepSeek V4 Pro
| Поле | Значение |
| Цена ввода | $1.60 за 1M токенов |
| Цена вывода | $3.20 за 1M токенов |
| Цена чтения кэша (ввод) | $0.135 за 1M токенов |
| Использовать когда | Сложные рассуждения, агентный кодинг или задачи с высокой ценой ошибки |
Цены DeepSeek V4 Flash
| Поле | Значение |
| Цена ввода | $0.14 за 1M токенов |
| Цена вывода | $0.28 за 1M токенов |
| Цена чтения кэша (ввод) | $0.028 за 1M токенов |
| Использовать когда | Высоконагруженный, чувствительный к задержкам или стоимости продакшн-трафик |
Для токенов ввода и вывода Pro стоит примерно в 11,4 раза дороже указанной цены Flash. Это не означает, что Flash всегда является лучшим бизнес-выбором; это означает, что Pro следует использовать там, где ожидаемое преимущество в качестве оправдывает более высокую стоимость за единицу.
Простая производственная политика работает хорошо:
- По умолчанию используйте Flash для высоконагруженных промптов с чёткими инструкциями, короткими критериями оценки и низкой ценой ошибки.
- Переключайтесь на Pro, когда пользователь запрашивает сложный кодинг, многошаговые рассуждения, синтез длинного контекста или ответ с высокими ставками.
- Перед изменением производственной маршрутизации проведите теневой тест на репрезентативном наборе промптов. Сравните качество вывода, повторные попытки, принятие пользователем, общее количество токенов, задержку и случаи неудач, а не только цену за токен.
Цены могут меняться, поэтому перед публикацией рабочего процесса или цитаты, чувствительной к цене, проверяйте актуальные страницы моделей.
Бенчмарки и сигналы производительности
Данные бенчмарков от Artificial Analysis указывают на чёткий компромисс между ориентированным на качество и на пропускную способность использованием. DeepSeek V4 Pro показывает более высокий показатель интеллекта, а DeepSeek V4 Flash демонстрирует более сильные показатели скорости и стоимости. Эти результаты следует рассматривать как входные данные для принятия решений, а не как универсальные рейтинги.
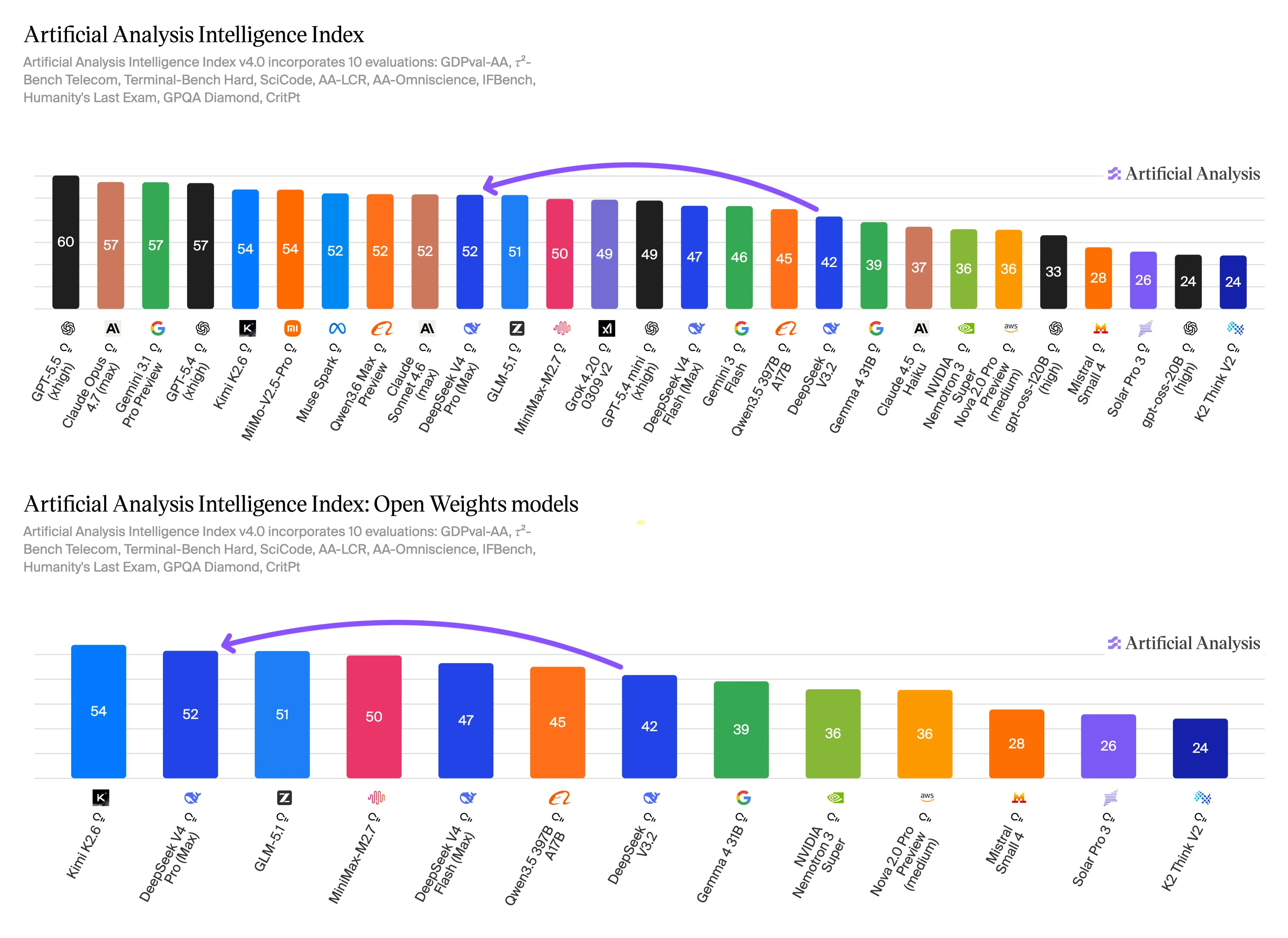
Индекс интеллекта v4.0 охватывает оценки для агентной работы, терминальных и кодовых задач, рассуждений с длинным контекстом, знаний, следования инструкциям, научных рассуждений и связанных тестов качества. Эта область оценки актуальна здесь, потому что эти категории пересекаются с основной причиной выбора Pro: более сложные многошаговые задачи, где ответ более высокого качества может оправдать более высокую стоимость за единицу.
Flash по-прежнему конкурентоспособен по той же шкале бенчмарков, а его профиль скорости и цены делает его практичным вариантом для производственных путей, которые выполняют множество похожих промптов. Используйте Flash для первичной суммаризации, классификации, извлечения, поддержки или маршрутизации. Переключайтесь на Pro, когда промпт неоднозначен, требует более глубоких рассуждений, затрагивает большую кодовую базу или имеет высокую цену ошибки.
Прежде чем заменять одну модель другой, выполните свой набор промптов на обоих API. Отслеживайте принятые ответы, частоту повторных попыток, задержку, общую стоимость токенов, надёжность структурированного вывода и поведение вызова инструментов. Бенчмарк подсказывает, с чего начать, но производственная маршрутизация должна следовать вашей фактической рабочей нагрузке.
Как получить доступ к обоим API на Novita AI
Обе модели используют совместимый с OpenAI LLM API от Novita AI. ID модели — это поле, которое вы меняете при переключении между Pro и Flash.
Шаг 1: Подтвердите ID моделей и доступность
Перед развёртыванием используйте актуальные страницы моделей:
- API и плейграунд DeepSeek V4 Pro:
deepseek/deepseek-v4-pro - API и плейграунд DeepSeek V4 Flash:
deepseek/deepseek-v4-flash
Эндпоинт списка моделей Novita AI также можно использовать для проверки доступных объектов моделей и полей, таких как ID модели, поля ценообразования, заголовок, описание и размер контекста.
Шаг 2: Используйте совместимый с OpenAI базовый URL
Справочник API Novita AI перечисляет совместимые с OpenAI эндпоинты по адресу:
https://api.novita.ai/openai
Для chat completions эндпоинт:
https://api.novita.ai/openai/v1/chat/completions
Запросы требуют bearer-токен в заголовке Authorization.
Шаг 3: Запустите один и тот же промпт на обеих моделях
Начните с небольшого оценочного набора, который представляет реальный трафик: лёгкие промпты, промпты с длинным контекстом, промпты кодинга, промпты в стиле инструментов, промпты извлечения и промпты, склонные к сбоям.
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-flash",
"messages": [
{
"role": "user",
"content": "Обобщите компромиссы между пакетной обработкой и потоковой передачей для LLM чат API."
}
],
"max_tokens": 500,
"temperature": 0.2
}'
Затем измените только ID модели:
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-pro",
"messages": [
{
"role": "user",
"content": "Обобщите компромиссы между пакетной обработкой и потоковой передачей для LLM чат API."
}
],
"max_tokens": 500,
"temperature": 0.2
}'
Шаг 4: Сравните производственные сигналы
Для каждого класса промптов запишите:
- качество и правильность завершения
- надёжность формата вывода
- поведение инструментов или вызова функций, если ваше приложение от них зависит
- общее количество токенов ввода и вывода
- задержку при ожидаемой конкурентности
- частоту повторных попыток и частоту отката
- пользовательскую видимую частоту принятия или редактирования
Это особенно важно, если вы планируете маршрутизировать стандартные запросы на Flash, а эскалации — на Pro.
Лучшие сценарии использования: когда выбирать каждую модель
Выбирайте DeepSeek V4 Pro для сложной работы
Используйте Pro, когда задача требует более глубоких рассуждений или более сильного агентного поведения:
- анализ кодовой базы, ревью кода и планы рефакторинга
- автономные агенты кодинга, которым нужно рассуждать на нескольких файлах
- отладка или анализ инцидентов с длинным контекстом
- многошаговое планирование с высокой ценой ошибки
- математические, научные или соревновательные рассуждения в стиле программирования
- премиальные пользовательские процессы, где качество ответа важнее стоимости единицы
Руководство по длинному контексту DeepSeek V4 Pro — лучшее внутреннее продолжение, когда читатель хочет больше деталей об использовании Pro для задач с длинным контекстом.
Выбирайте DeepSeek V4 Flash для масштабируемого продакшн-трафика
Используйте Flash, когда рабочая нагрузка выигрывает от более низкой цены за единицу и более лёгкого обслуживания:
- высоконагруженные чаты и функции ассистента
- классификация, маршрутизация, извлечение и суммаризация
- задачи первичного объяснения кода или документации
- рабочие процессы поддержки с множеством похожих промптов
- фоновая обработка, где доступен откат к Pro
- приложения, где задержка и стоимость являются ключевыми ограничениями пользовательского опыта
Руководство по DeepSeek V4 Flash на Novita AI — естественный компаньон по настройке для разработчиков, которые выбирают Flash в качестве модели по умолчанию.
Избегайте слепого переключения
Не переключайтесь только потому, что две модели имеют одинаковую длину контекста и доступ к эндпоинту. Перед миграцией убедитесь, что новая модель сохраняет:
- поведение промпта на ваших производственных примерах
- форму структурированного JSON или вывода
- аргументы вызова инструментов и поведение при сбоях
- задержку при ожидаемой конкурентности
- общую стоимость с учётом повторных попыток и более длинных выводов
- защитные меры, поведение отказа и обработку крайних случаев
Для многих систем лучший ответ — не Pro или Flash. Это политика маршрутизации, использующая обе модели.
Заметки по миграции для разработчиков
Если вы мигрируете между двумя моделями, ID модели — первое поле для обновления:
| Направление | Изменение |
| Flash -> Pro | Замените deepseek/deepseek-v4-flash на deepseek/deepseek-v4-pro для более сложных промптов. |
| Pro -> Flash | Замените deepseek/deepseek-v4-pro на deepseek/deepseek-v4-flash для чувствительных к стоимости базовых промптов. |
| Смешанная маршрутизация | Держите оба ID и маршрутизируйте по сложности задачи, уровню аккаунта или оценочному баллу. |
Чек-лист миграции:
- Подтвердите текущую доступность модели на страницах моделей Novita AI.
- Подтвердите текущие цены перед изменением предположений о стоимости.
- Сохраните тот же базовый URL и эндпоинт chat completions для примеров в этом руководстве.
- Запустите репрезентативный регрессионный набор промптов.
- Сравните качество вывода по типу задачи, а не только по общему проценту побед.
- Отслеживайте использование токенов, задержку, повторные попытки и частоту отказов.
- Держите план отката, который может переключить трафик обратно на предыдущий ID модели.
Итоговая рекомендация
Для большинства команд DeepSeek V4 Flash должен быть первой моделью для тестирования высоконагруженного продакшн-трафика, поскольку он имеет гораздо более низкие цены на ввод, вывод и чтение кэша, сохраняя те же видимые лимиты контекста и максимального вывода, что и Pro на Novita AI.
DeepSeek V4 Pro следует резервировать для задач, где качество, глубина рассуждений или надёжность агентного кодинга имеют большую бизнес-ценность, чем более высокая цена токена. Если ваш продукт включает как рутинные, так и сложные промпты, маршрутизируйте рутинные запросы на Flash, а более сложные — на Pro после того, как ваша оценка подтвердит разделение.
Часто задаваемые вопросы
В чём основное различие между DeepSeek V4 Pro и DeepSeek V4 Flash?
На Novita AI видимый лимит контекста, максимальный лимит вывода, модальности и путь запроса chat completions, используемые в этом руководстве, одинаковы. Основное различие в позиционировании и цене: Pro — это ориентированный на качество вариант для сложных рассуждений и агентного кодинга, а Flash — более дешёвый вариант для высоконагруженного и чувствительного к задержкам использования.
Обе модели доступны на Novita AI?
Да. Novita AI имеет страницы моделей как для deepseek/deepseek-v4-pro, так и для deepseek/deepseek-v4-flash, и обе указаны как serverless LLM модели.
DeepSeek V4 Flash дешевле, чем DeepSeek V4 Pro?
По состоянию на 9 июня 2026 года текущие страницы моделей Novita AI указывают Flash по цене $0.14 за 1M токенов ввода и $0.28 за 1M токенов вывода, тогда как Pro указан по цене $1.60 за 1M токенов ввода и $3.20 за 1M токенов вывода.
Стоит ли мне обновляться с Flash до Pro?
Обновляйте конкретные рабочие нагрузки до Pro, когда Flash не соответствует вашему целевому качеству для сложного кодинга, рассуждений с длинным контекстом или задач с высокой ценой ошибки. Не обновляйте весь трафик, пока не сравните реальные промпты, общую стоимость, задержку и случаи неудач.
Могут ли обе модели использовать один и тот же эндпоинт chat completions?
Да. Страницы моделей Novita AI указывают chat/completions для обеих моделей, а справочник API документирует совместимый с OpenAI эндпоинт chat completions по адресу /openai/v1/chat/completions.
Доказывают ли бенчмарки, что Pro всегда лучше Flash?
Нет. Сообщённые данные бенчмарков дают Pro более высокий показатель индекса интеллекта, в то время как Flash показывает более высокую скорость вывода, меньшую задержку первого токена и более низкие указанные цены токенов. Используйте Pro для более сложных рассуждений или задач кодинга и тестируйте Flash для высоконагруженного продакшн-трафика.



