

- DeepSeek V4 Pro vs DeepSeek V4 Flash: Kurzvergleich
- Was ändert sich zwischen Pro und Flash?
- Preisvergleich auf Novita AI
- Benchmark- und Leistungssignale
- So greifen Sie auf beide APIs auf Novita AI zu
- Beste Anwendungsfälle: Wann welches Modell wählen
- Migrationshinweise für Entwickler
- Abschließende Empfehlung
- FAQ
Wählen Sie DeepSeek V4 Pro, wenn die Ausgabequalität bei komplexen agentischen Codierungsaufgaben, langem Reasoning oder schwierigen mehrstufigen Aufgaben wichtiger ist als die Stückkosten; wählen Sie DeepSeek V4 Flash, wenn Sie denselben 1.048.576-Token-Kontext, dasselbe maximale Ausgabelimit von 393.216 Token und einen kostengünstigeren API-Pfad für volumenstarke oder latenzempfindliche Workloads benötigen. Beide Modelle sind über die OpenAI-kompatible LLM-API von Novita AI verfügbar, unterscheiden sich jedoch in Preis und Positionierung für verschiedene Produktionsrollen.
DeepSeek V4 Pro vs DeepSeek V4 Flash: Kurzvergleich
Modell-Eignung
| Bereich | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Am besten geeignet für | Komplexe agentische Workflows, professionelle Softwareentwicklung, anspruchsvolles Reasoning | Hochparallele Apps, leichte Workloads, kostenempfindlicher Produktionsverkehr |
| Entscheidungsregel | Verwenden, wenn Fehlerkosten hoch sind | Verwenden, wenn Anfragevolumen oder Latenz wichtiger sind |
API und Limits
| Bereich | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Modell-ID | deepseek/deepseek-v4-pro |
deepseek/deepseek-v4-flash |
| Verfügbarkeit | Verfügbar, serverloses LLM | Verfügbar, serverloses LLM |
| Kontextfenster | 1.048.576 Token | 1.048.576 Token |
| Maximale Ausgabetoken | 393.216 Token | 393.216 Token |
| Eingabe-/Ausgabemodalität | Texteingabe, Textausgabe | Texteingabe, Textausgabe |
| API-Anfragepfad | OpenAI-kompatible Chat-Completions | OpenAI-kompatible Chat-Completions |
Preise im Überblick
| Bereich | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Eingabepreis | 1,60 $ pro 1 M Token | 0,14 $ pro 1 M Token |
| Ausgabepreis | 3,20 $ pro 1 M Token | 0,28 $ pro 1 M Token |
| Cache-Read-Preis | 0,135 $ pro 1 M Token | 0,028 $ pro 1 M Token |
Funktionshinweise
| Bereich | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Gelistete Funktionen | Serverlos, Function Calling, strukturierte Ausgaben, Reasoning | Serverlos, Function Calling, strukturierte Ausgaben, Reasoning |
| Praktischer Hinweis | Leiten Sie die schwierigsten Prompts an Pro weiter | Verwenden Sie Flash für skalierbaren Basisverkehr |
Was ändert sich zwischen Pro und Flash?
Die wichtigste Änderung betrifft nicht die Kontextlänge oder den grundlegenden Zugang zu Chat-Completions. Auf Novita AI haben beide Modelle ein Kontextfenster von 1.048.576 Token, maximal 393.216 Ausgabetoken, Texteingabe, Textausgabe, serverlose Bereitstellung, Function Calling, strukturierte Ausgaben und Reasoning-Unterstützung.
Der praktische Unterschied liegt in der Positionierung und im Preis. Die DeepSeek V4 Pro Modellseite beschreibt Pro als die Flaggschiff-Option für komplexe agentische Workflows, professionelle Softwareentwicklung, reasoning-lastige Evaluierungen und anspruchsvolle Codierungsaufgaben. Die DeepSeek V4 Flash Modellseite positioniert Flash als leichte Option für schnellen, wirtschaftlichen API-Dienst, hohe Parallelität, niedrige Latenz und großvolumige leichte Workloads.
Das ergibt für Entwickler ein klares Routing-Muster:
- Verwenden Sie Pro für Aufgaben, bei denen eine schlechte Antwort mehr kosten kann als der zusätzliche Token-Preis: autonome Codeänderungen, lange Debugging-Sitzungen, Repositorium-weite Analyse, Planung und schwieriges Reasoning.
- Verwenden Sie Flash für Anfragen, bei denen Kosten und Reaktionsfähigkeit das Produkterlebnis prägen: Chat-Assistenz, Erstklassifizierung, Zusammenfassung, Extraktion, Routing und wiederholte Produktionsaufrufe.
- Verwenden Sie beide, wenn Ihre Anwendung „schwierige Prompts“ von „Standard-Prompts“ trennen kann. Flash kann den meisten Basisverkehr bewältigen, während Pro für Eskalationen oder Premium-Workflows reserviert werden kann.
Wenn Sie bereits den DeepSeek V4 Flash Launch Guide gelesen haben, betrachten Sie diese Seite als Entscheidungsebene: Es geht darum, wann Sie welche API auswählen, nicht darum, das Launch-Setup zu wiederholen.
Preisvergleich auf Novita AI
Die aktuellen Preise auf den Novita AI Modellseiten zeigen eine große Kostenlücke zwischen den beiden Modellen:
DeepSeek V4 Pro Preise
| Bereich | Wert |
| Eingabepreis | 1,60 $ pro 1 M Token |
| Ausgabepreis | 3,20 $ pro 1 M Token |
| Cache-Read-Eingabepreis | 0,135 $ pro 1 M Token |
| Verwendung bei | Komplexem Reasoning, agentischem Coding oder Aufgaben mit hohen Fehlerkosten |
DeepSeek V4 Flash Preise
| Bereich | Wert |
| Eingabepreis | 0,14 $ pro 1 M Token |
| Ausgabepreis | 0,28 $ pro 1 M Token |
| Cache-Read-Eingabepreis | 0,028 $ pro 1 M Token |
| Verwendung bei | Hochvolumigem, latenzempfindlichem oder kostenempfindlichem Produktionsverkehr |
Bei Eingabe- und Ausgabetoken liegt Pro etwa beim 11,4-fachen des angegebenen Flash-Preises. Das bedeutet nicht, dass Flash immer die bessere geschäftliche Wahl ist; es bedeutet, dass Pro dort eingesetzt werden sollte, wo sein erwarteter Qualitätsvorteil die höheren Stückkosten rechtfertigt.
Eine einfache Produktionsrichtlinie funktioniert gut:
- Standardmäßig Flash für hochvolumige Prompts mit klaren Anweisungen, kurzen Bewertungskriterien und niedrigen Fehlerkosten verwenden.
- Auf Pro eskalieren, wenn der Benutzer schwieriges Coding, mehrstufiges Reasoning, Langkontextsynthese oder eine Antwort mit hohem Risiko anfordert.
- Führen Sie einen Schattentest mit einem repräsentativen Prompt-Set durch, bevor Sie das Produktions-Routing ändern. Vergleichen Sie Ausgabequalität, Wiederholungen, Benutzerakzeptanz, Gesamttoken, Latenz und Fehlerfälle, nicht nur den Preis pro Token.
Die Preise können sich ändern. Überprüfen Sie daher die aktuellen Modellseiten, bevor Sie einen preissensiblen Workflow oder ein Angebot veröffentlichen.
Benchmark- und Leistungssignale
Benchmark-Daten von Artificial Analysis zeigen einen klaren Kompromiss zwischen qualitätsorientierter und durchsatzorientierter Nutzung. DeepSeek V4 Pro erzielt den höheren Intelligence-Score, während DeepSeek V4 Flash stärkere Geschwindigkeits- und Kostenmetriken aufweist. Diese Ergebnisse sollten als Entscheidungsfaktoren und nicht als universelle Rangfolgen betrachtet werden.
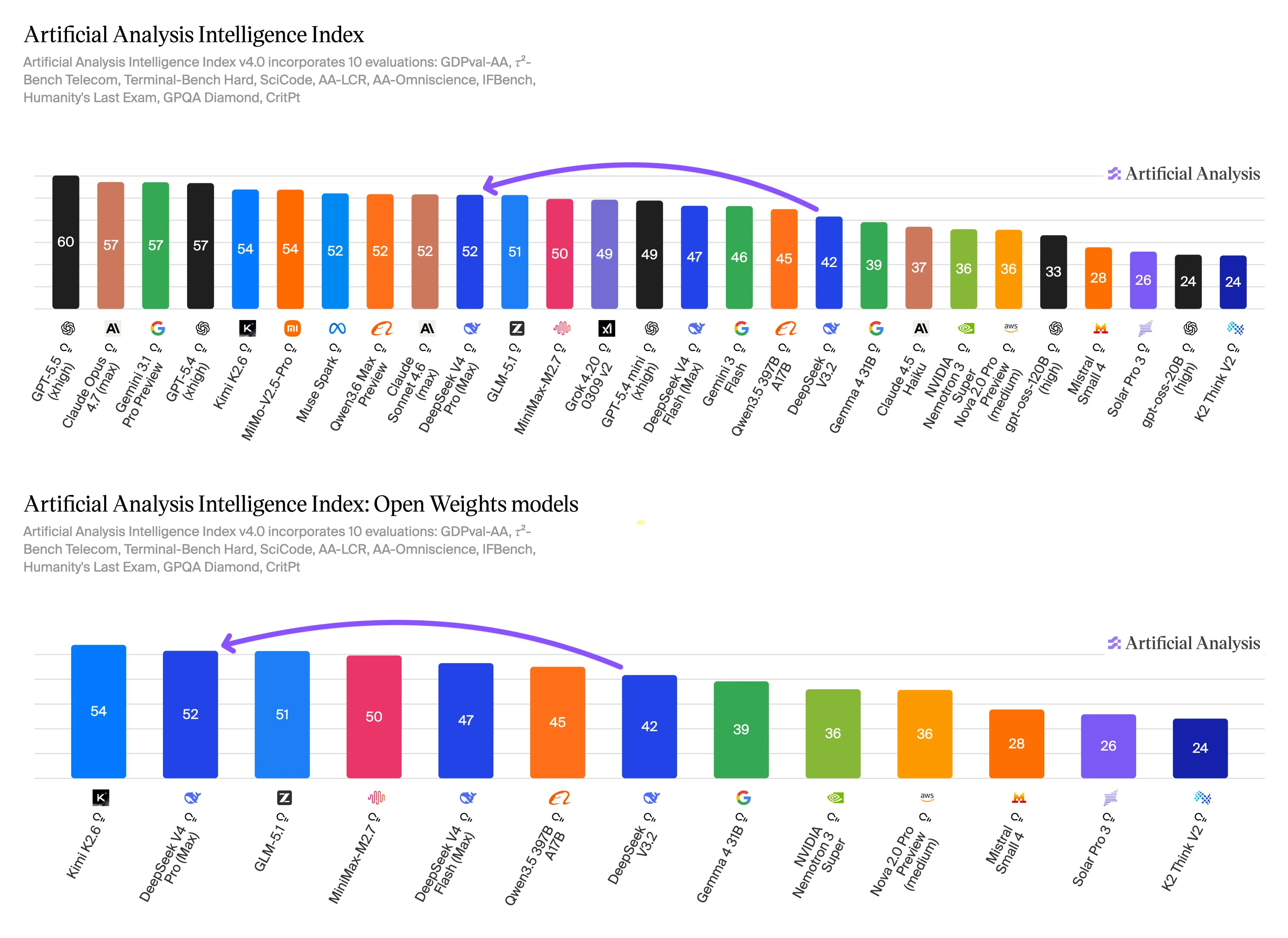
Der Intelligence Index v4.0 umfasst Evaluierungen für agentische Arbeit, Terminal- und Codierungsaufgaben, Langkontext-Reasoning, Wissen, Instruktionsbefolgung, wissenschaftliches Reasoning und verwandte Qualitätstests. Dieser Bewertungsumfang ist hier relevant, da diese Kategorien mit dem Hauptgrund überlappen, Pro zu wählen: schwierigere mehrstufige Arbeiten, bei denen eine qualitativ hochwertigere Antwort höhere Stückkosten rechtfertigen kann.
Flash schneidet auf derselben Benchmark-Skala immer noch wettbewerbsfähig ab, und sein Geschwindigkeits- und Preisprofil macht es zu einer praktischen Option für Produktionspfade, die viele ähnliche Prompts ausführen. Verwenden Sie Flash für Erstzusammenfassung, Klassifizierung, Extraktion, Support-Assistenz oder Routing. Eskalieren Sie auf Pro, wenn der Prompt mehrdeutig ist, tiefergehendes Reasoning erfordert, eine große Codebasis betrifft oder hohe Fehlerkosten verursacht.
Bevor Sie ein Modell durch das andere ersetzen, führen Sie Ihr eigenes Prompt-Set auf beiden APIs aus. Verfolgen Sie akzeptierte Antworten, Wiederholungsrate, Latenz, Gesamttokenkosten, Zuverlässigkeit strukturierter Ausgaben und Tool-Call-Verhalten. Der Benchmark gibt einen Anhaltspunkt, aber das Produktions-Routing sollte Ihrem tatsächlichen Workload folgen.
So greifen Sie auf beide APIs auf Novita AI zu
Beide Modelle verwenden die OpenAI-kompatible LLM-API von Novita AI. Die Modell-ID ist das Feld, das Sie ändern, wenn Sie zwischen Pro und Flash wechseln.
Schritt 1: Überprüfen Sie Modell-IDs und Verfügbarkeit
Verwenden Sie vor der Bereitstellung die aktuellen Modellseiten:
- DeepSeek V4 Pro API und Playground:
deepseek/deepseek-v4-pro - DeepSeek V4 Flash API und Playground:
deepseek/deepseek-v4-flash
Der Novita AI Endpunkt zum Auflisten von Modellen kann auch verwendet werden, um verfügbare Modellobjekte und Felder wie Modell-ID, Preisfelder, Titel, Beschreibung und Kontextgröße zu überprüfen.
Schritt 2: Verwenden Sie die OpenAI-kompatible Basis-URL
Die API-Referenz von Novita AI listet OpenAI-kompatible Endpunkte unter:
https://api.novita.ai/openai
Für Chat-Completions lautet der Endpunkt:
https://api.novita.ai/openai/v1/chat/completions
Anfragen erfordern ein Bearer-Token im Authorization-Header.
Schritt 3: Führen Sie denselben Prompt gegen beide Modelle aus
Beginnen Sie mit einem kleinen Evaluierungsset, das den realen Verkehr repräsentiert: einfache Prompts, Langkontext-Prompts, Codierungs-Prompts, Tool-artige Prompts, Extraktions-Prompts und fehleranfällige Prompts.
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-flash",
"messages": [
{
"role": "user",
"content": "Fassen Sie die Kompromisse zwischen Batching und Streaming für eine LLM-Chat-API zusammen."
}
],
"max_tokens": 500,
"temperature": 0.2
}'
Dann nur die Modell-ID ändern:
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-pro",
"messages": [
{
"role": "user",
"content": "Fassen Sie die Kompromisse zwischen Batching und Streaming für eine LLM-Chat-API zusammen."
}
],
"max_tokens": 500,
"temperature": 0.2
}'
Schritt 4: Vergleichen Sie Produktionssignale
Notieren Sie für jede Prompt-Klasse:
- Fertigstellungsqualität und Korrektheit
- Zuverlässigkeit des Ausgabeformats
- Tool- oder Function-Call-Verhalten, falls Ihre App davon abhängt
- Gesamteingabe- und Ausgabetoken
- Latenz unter erwarteter Parallelität
- Wiederholungsrate und Fallback-Rate
- benutzersichtbare Akzeptanz- oder Bearbeitungsrate
Dies ist besonders wichtig, wenn Sie planen, Standardanfragen an Flash und Eskalationen an Pro zu routen.
Beste Anwendungsfälle: Wann welches Modell wählen
Wählen Sie DeepSeek V4 Pro für komplexe Arbeiten
Verwenden Sie Pro, wenn die Aufgabe tieferes Reasoning oder stärkeres agentisches Verhalten erfordert:
- Codebasis-Analyse, Code-Review und Refactoring-Pläne
- autonome Codierungsagenten, die über mehrere Dateien hinweg argumentieren müssen
- Langkontext-Debugging oder Incident-Analyse
- mehrstufige Planung mit hohen Fehlerkosten
- mathematisches, MINT- oder wettbewerbsorientiertes Programmier-Reasoning
- Premium-Benutzer-Workflows, bei denen Antwortqualität wichtiger ist als Stückkosten
Der DeepSeek V4 Pro Long-Context Guide ist der bessere interne Folgeartikel, wenn der Leser mehr Details zur Verwendung von Pro für Langkontext-Workloads wünscht.
Wählen Sie DeepSeek V4 Flash für skalierbaren Produktionsverkehr
Verwenden Sie Flash, wenn der Workload von einem niedrigeren Stückpreis und einer leichteren Bereitstellung profitiert:
- hochvolumige Chat- und Assistenzfunktionen
- Klassifizierung, Routing, Extraktion und Zusammenfassung
- erste Erklärungen von Code oder Dokumentationsaufgaben
- Support-Workflows mit vielen ähnlichen Prompts
- Hintergrundverarbeitung, bei der ein Fallback zu Pro verfügbar ist
- Anwendungen, bei denen Latenz und Kosten zentrale Benutzererfahrungsbeschränkungen sind
Der DeepSeek V4 Flash auf Novita AI Guide ist der natürliche Setup-Begleiter für Entwickler, die Flash als Standardmodell wählen.
Vermeiden Sie blindes Wechseln
Wechseln Sie nicht rein aufgrund der gemeinsamen Kontextlänge und Endpunktzugänglichkeit. Stellen Sie vor der Migration sicher, dass das neue Modell Folgendes beibehält:
- Prompt-Verhalten auf Ihren Produktionsbeispielen
- JSON- oder strukturierte Ausgabeform
- Tool-Call-Argumente und Fehlerverhalten
- Latenz unter erwarteter Parallelität
- Gesamtkosten nach Wiederholungen und längeren Ausgaben
- Schutzmechanismen, Verweigerungsverhalten und Umgang mit Randfällen
Für viele Systeme ist die beste Antwort weder Pro noch Flash. Es ist eine Routing-Richtlinie, die beide verwendet.
Migrationshinweise für Entwickler
Wenn Sie zwischen den beiden Modellen migrieren, ist die Modell-ID das erste Feld, das aktualisiert werden muss:
| Richtung | Änderung |
| Flash zu Pro | Ersetzen Sie deepseek/deepseek-v4-flash durch deepseek/deepseek-v4-pro für schwierigere Prompts. |
| Pro zu Flash | Ersetzen Sie deepseek/deepseek-v4-pro durch deepseek/deepseek-v4-flash für kostenempfindliche Basis-Prompts. |
| Gemischtes Routing | Behalten Sie beide IDs und routen Sie nach Aufgabenkomplexität, Kontostufe oder Evaluierungsergebnis. |
Migrations-Checkliste:
- Überprüfen Sie die aktuelle Modellverfügbarkeit auf den Novita AI Modellseiten.
- Überprüfen Sie die aktuellen Preise, bevor Sie Kostenannahmen ändern.
- Behalten Sie dieselbe Basis-URL und denselben Chat-Completions-Endpunkt für die Beispiele in diesem Leitfaden bei.
- Führen Sie eine repräsentative Prompt-Regression durch.
- Vergleichen Sie die Ausgabequalität nach Aufgabentyp, nicht nur nach aggregierter Gewinnrate.
- Verfolgen Sie Token-Nutzung, Latenz, Wiederholungen und Fallback-Rate.
- Halten Sie einen Rollback-Plan bereit, der den Datenverkehr zurück zur vorherigen Modell-ID umschalten kann.
Abschließende Empfehlung
Für die meisten Teams sollte DeepSeek V4 Flash das erste zu testende Modell für hochvolumigen Produktionsverkehr sein, da es viel niedrigere Preise für Eingabe, Ausgabe und Cache-Lesevorgänge bietet, während es auf Novita AI dieselben sichtbaren Kontext- und Maximalausgabelimits wie Pro beibehält.
DeepSeek V4 Pro sollte Aufgaben vorbehalten sein, bei denen Qualität, Reasoning-Tiefe oder Zuverlässigkeit beim agentischen Codieren einen höheren geschäftlichen Wert haben als der höhere Token-Preis. Wenn Ihr Produkt sowohl routinemäßige als auch schwierige Prompts umfasst, routen Sie routinemäßige Anfragen an Flash und eskalieren Sie schwierigere Anfragen an Pro, nachdem Ihre Evaluierung die Trennung bestätigt hat.
FAQ
Was ist der Hauptunterschied zwischen DeepSeek V4 Pro und DeepSeek V4 Flash?
Auf Novita AI sind das sichtbare Kontextlimit, das maximale Ausgabelimit, die Modalitäten und der in diesem Leitfaden verwendete Chat-Completions-Anfragepfad gleich. Der Hauptunterschied liegt in der Positionierung und im Preis: Pro ist die qualitätsorientierte Option für komplexes Reasoning und agentisches Codieren, während Flash die kostengünstigere Option für hochvolumige und latenzempfindliche Nutzung ist.
Sind beide Modelle auf Novita AI verfügbar?
Ja. Novita AI hat Modellseiten für sowohl deepseek/deepseek-v4-pro als auch deepseek/deepseek-v4-flash, und beide sind als serverlose LLM-Modelle gelistet.
Ist DeepSeek V4 Flash günstiger als DeepSeek V4 Pro?
Stand 9. Juni 2026 listen die aktuellen Novita AI Modellseiten Flash mit 0,14 $ pro 1 M Eingabetoken und 0,28 $ pro 1 M Ausgabetoken, während Pro mit 1,60 $ pro 1 M Eingabetoken und 3,20 $ pro 1 M Ausgabetoken gelistet ist.
Sollte ich von Flash auf Pro upgraden?
Upgraden Sie bestimmte Workloads auf Pro, wenn Flash Ihr Qualitätsziel bei komplexem Codieren, Langkontext-Reasoning oder Aufgaben mit hohen Fehlerkosten nicht erfüllt. Upgraden Sie nicht den gesamten Datenverkehr, bevor Sie echte Prompts, Gesamtkosten, Latenz und Fehlerfälle verglichen haben.
Können beide Modelle denselben Chat-Completions-Endpunkt verwenden?
Ja. Die Novita AI Modellseiten listen chat/completions für beide Modelle, und die API-Referenz dokumentiert den OpenAI-kompatiblen Chat-Completions-Endpunkt unter /openai/v1/chat/completions.
Beweisen Benchmarks, dass Pro immer besser ist als Flash?
Nein. Die gemeldeten Benchmark-Daten geben Pro einen höheren Intelligence Index Score, während Flash eine höhere Ausgabegeschwindigkeit, niedrigere First-Token-Latenz und niedrigere gelistete Token-Preise zeigt. Verwenden Sie Pro für schwierigeres Reasoning oder Codierungsaufgaben und testen Sie Flash für hochvolumigen Produktionsverkehr.



