

Escolha DeepSeek V4 Pro quando a qualidade da saída em tarefas complexas de codificação agêntica, raciocínio longo ou etapas múltiplas difíceis for mais importante que o custo unitário; escolha DeepSeek V4 Flash quando precisar da mesma janela de contexto de 1.048.576 tokens, do mesmo limite máximo de saída de 393.216 tokens e de um caminho de API de menor custo para cargas de trabalho de alto volume ou sensíveis à latência. Ambos os modelos estão disponíveis através da API LLM compatível com OpenAI da Novita AI, mas seus preços e posicionamento apontam para papéis diferentes em produção.
DeepSeek V4 Pro vs DeepSeek V4 Flash: Comparação rápida
Adequação do modelo
| Campo | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Melhor para | Fluxos de trabalho agênticos complexos, desenvolvimento de software profissional, raciocínio difícil | Aplicativos de alta concorrência, cargas de trabalho leves, tráfego de produção sensível a custos |
| Regra de decisão | Use quando o custo da falha for alto | Use quando o volume de requisições ou a latência forem mais importantes |
API e limites
| Campo | DeepSeek V4 Pro | DeepSeek V4 Flash |
| ID do modelo | deepseek/deepseek-v4-pro |
deepseek/deepseek-v4-flash |
| Disponibilidade | Disponível, LLM serverless | Disponível, LLM serverless |
| Janela de contexto | 1.048.576 tokens | 1.048.576 tokens |
| Máx. tokens de saída | 393.216 tokens | 393.216 tokens |
| Modalidade entrada/saída | Entrada de texto, saída de texto | Entrada de texto, saída de texto |
| Caminho da requisição API | Chat completions compatível com OpenAI | Chat completions compatível com OpenAI |
Resumo de preços
| Campo | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Preço de entrada | US$ 1,60 por 1M de tokens | US$ 0,14 por 1M de tokens |
| Preço de saída | US$ 3,20 por 1M de tokens | US$ 0,28 por 1M de tokens |
| Preço de leitura de cache | US$ 0,135 por 1M de tokens | US$ 0,028 por 1M de tokens |
Notas sobre recursos
| Campo | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Recursos listados | Serverless, function calling, saídas estruturadas, raciocínio | Serverless, function calling, saídas estruturadas, raciocínio |
| Observação prática | Direcione os prompts mais difíceis para o Pro | Use Flash para tráfego base escalável |
O que muda entre Pro e Flash?
A mudança mais importante não é o tamanho do contexto ou o acesso básico a chat completions. Na Novita AI, ambos os modelos listam janela de contexto de 1.048.576 tokens, máximo de 393.216 tokens de saída, entrada e saída de texto, entrega serverless, function calling, saídas estruturadas e suporte a raciocínio.
A diferença prática é o posicionamento e o preço. A página do modelo DeepSeek V4 Pro descreve o Pro como a opção principal para fluxos de trabalho agênticos complexos, desenvolvimento profissional de software, avaliações com foco em raciocínio e tarefas de codificação exigentes. A página do modelo DeepSeek V4 Flash posiciona o Flash como uma opção leve para serviço de API rápido e econômico, alta concorrência, baixa latência e cargas de trabalho leves em larga escala.
Isso dá aos desenvolvedores um padrão claro de roteamento:
- Use Pro para tarefas onde uma resposta ruim pode custar mais que o preço extra do token: alterações autônomas de código, longas sessões de depuração, análise em escala de repositório, planejamento e raciocínio difícil.
- Use Flash para requisições onde o custo e a capacidade de resposta moldam a experiência do produto: assistência em chat, classificação inicial, sumarização, extração, roteamento e chamadas repetidas em produção.
- Use ambos quando sua aplicação puder separar “prompts difíceis” de “prompts padrão”. O Flash pode lidar com a maior parte do tráfego base, enquanto o Pro pode ser reservado para escalonamentos ou fluxos de trabalho premium.
Se você já leu o guia de lançamento do DeepSeek V4 Flash, trate esta página como a camada de decisão: trata-se de quando selecionar cada API, não de como repetir a configuração de lançamento.
Comparação de preços na Novita AI
Os preços atuais nas páginas dos modelos da Novita AI mostram uma grande diferença de custo entre os dois modelos:
Preços do DeepSeek V4 Pro
| Campo | Valor |
| Preço de entrada | US$ 1,60 por 1M de tokens |
| Preço de saída | US$ 3,20 por 1M de tokens |
| Preço de leitura de cache | US$ 0,135 por 1M de tokens |
| Use quando | Tarefas de raciocínio complexo, codificação agêntica ou alto custo de falha |
Preços do DeepSeek V4 Flash
| Campo | Valor |
| Preço de entrada | US$ 0,14 por 1M de tokens |
| Preço de saída | US$ 0,28 por 1M de tokens |
| Preço de leitura de cache | US$ 0,028 por 1M de tokens |
| Use quando | Tráfego de produção de alto volume, sensível à latência ou a custos |
Para tokens de entrada e saída, o Pro custa cerca de 11,4x o preço listado do Flash. Isso não significa que o Flash seja sempre a melhor escolha de negócios; significa que o Pro deve ser usado onde sua vantagem de qualidade esperada justifique o custo unitário mais alto.
Uma política de produção simples funciona bem:
- Padrão: Flash para prompts de alto volume com instruções claras, critérios de avaliação curtos e baixo custo de falha.
- Escalonamento: Pro quando o usuário pedir codificação difícil, raciocínio de várias etapas, síntese de contexto longo ou respostas de alto risco.
- Teste sombra: execute um conjunto representativo de prompts antes de mudar o roteamento de produção. Compare qualidade da saída, repetições, aceitação do usuário, total de tokens, latência e casos de falha, não apenas o preço por token.
Os preços podem mudar, então verifique as páginas atuais dos modelos antes de publicar um fluxo de trabalho ou cotação sensível a preços.
Benchmarks e sinais de desempenho
Dados de benchmark do Artificial Analysis indicam uma troca clara entre uso orientado à qualidade e orientado à taxa de transferência. O DeepSeek V4 Pro relata a pontuação de inteligência mais alta, enquanto o DeepSeek V4 Flash relata métricas de velocidade e custo mais fortes. Esses resultados devem ser tratados como insumos para decisão, não como classificações universais.
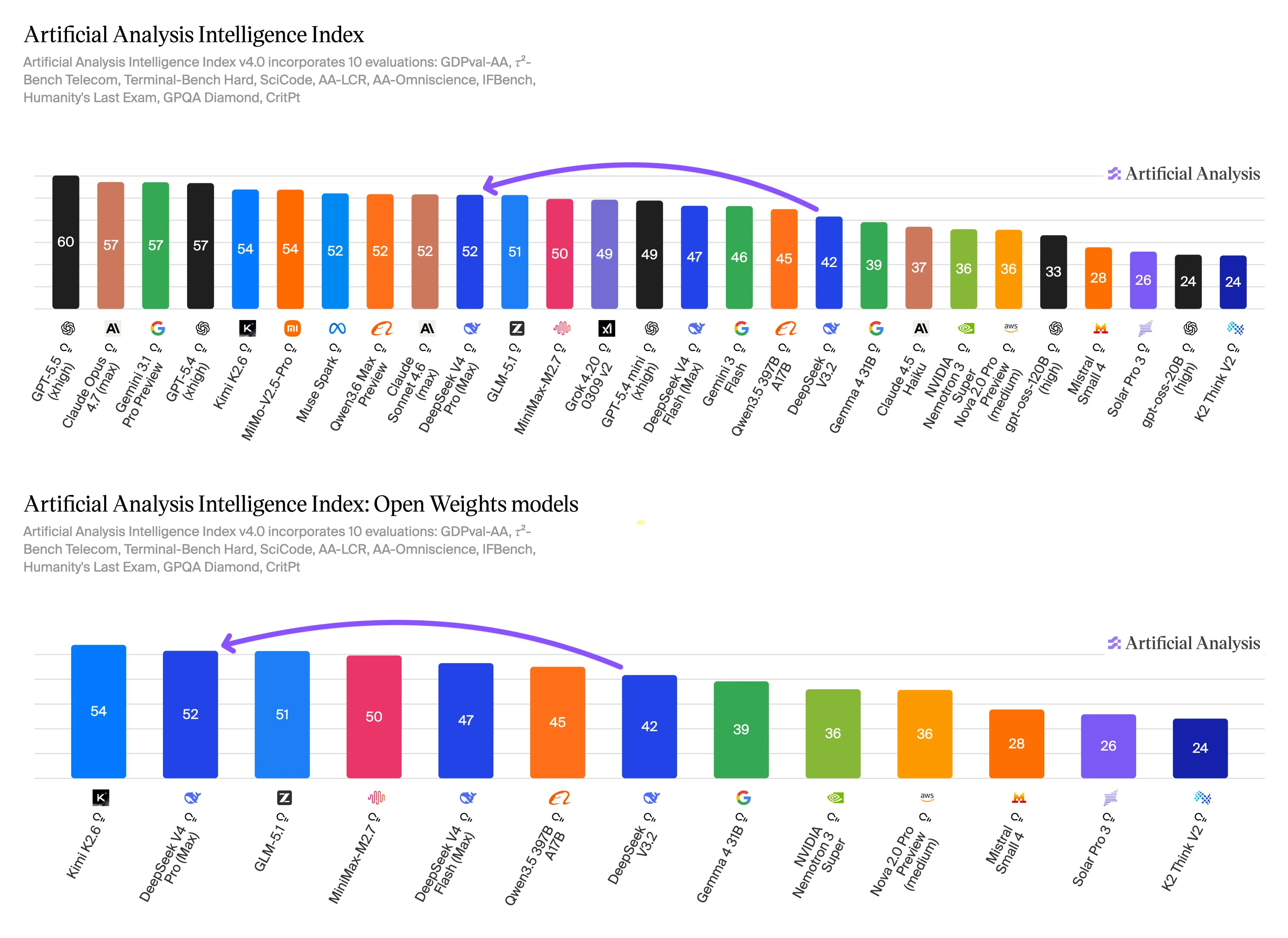
O Intelligence Index v4.0 cobre avaliações para trabalho agêntico, tarefas de terminal e codificação, raciocínio de contexto longo, conhecimento, seguimento de instruções, raciocínio científico e testes de qualidade relacionados. Esse escopo de avaliação é relevante aqui porque essas categorias se sobrepõem ao principal motivo para escolher o Pro: trabalhos mais difíceis em várias etapas, onde uma resposta de maior qualidade pode justificar um custo unitário mais alto.
O Flash ainda apresenta desempenho competitivo na mesma escala de benchmark, e seu perfil de velocidade e preço o torna uma opção prática para caminhos de produção que executam muitos prompts semelhantes. Use Flash para sumarização inicial, classificação, extração, assistência ao suporte ou roteamento. Escalone para Pro quando o prompt for ambíguo, exigir raciocínio mais profundo, envolver uma base de código grande ou tiver um alto custo de falha.
Antes de substituir um modelo pelo outro, execute seu próprio conjunto de prompts em ambas as APIs. Acompanhe respostas aceitas, taxa de repetição, latência, custo total de tokens, confiabilidade da saída estruturada e comportamento de chamadas de ferramentas. O benchmark sugere por onde começar, mas o roteamento de produção deve seguir sua carga de trabalho real.
Como acessar ambas as APIs na Novita AI
Ambos os modelos usam a API LLM compatível com OpenAI da Novita AI. O ID do modelo é o campo que você altera ao alternar entre Pro e Flash.
Passo 1: Confirmar IDs dos modelos e disponibilidade
Use as páginas atuais dos modelos antes da implantação:
- DeepSeek V4 Pro API e playground:
deepseek/deepseek-v4-pro - DeepSeek V4 Flash API e playground:
deepseek/deepseek-v4-flash
O endpoint de listagem de modelos da Novita AI também pode ser usado para verificar objetos de modelo disponíveis e campos como ID do modelo, campos de preço, título, descrição e tamanho do contexto.
Passo 2: Usar a URL base compatível com OpenAI
A referência da API da Novita AI lista endpoints compatíveis com OpenAI em:
https://api.novita.ai/openai
Para chat completions, o endpoint é:
https://api.novita.ai/openai/v1/chat/completions
As requisições exigem um token bearer no cabeçalho Authorization.
Passo 3: Executar o mesmo prompt em ambos os modelos
Comece com um pequeno conjunto de avaliação que represente o tráfego real: prompts fáceis, prompts de contexto longo, prompts de codificação, prompts no estilo ferramenta, prompts de extração e prompts propensos a falhas.
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-flash",
"messages": [
{
"role": "user",
"content": "Resuma as compensações entre batching e streaming para uma API de chat LLM."
}
],
"max_tokens": 500,
"temperature": 0.2
}'
Depois, altere apenas o ID do modelo:
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-pro",
"messages": [
{
"role": "user",
"content": "Resuma as compensações entre batching e streaming para uma API de chat LLM."
}
],
"max_tokens": 500,
"temperature": 0.2
}'
Passo 4: Comparar sinais de produção
Para cada classe de prompt, registre:
- qualidade e correção da resposta
- confiabilidade do formato de saída
- comportamento de chamada de ferramenta ou função, se seu aplicativo depender disso
- total de tokens de entrada e saída
- latência sob concorrência esperada
- taxa de repetição e taxa de fallback
- taxa de aceitação ou edição visível ao usuário
Isso é especialmente importante se você planeja rotear requisições padrão para Flash e escalonamentos para Pro.
Melhores casos de uso: quando escolher cada modelo
Escolha DeepSeek V4 Pro para trabalhos complexos
Use Pro quando a tarefa exigir raciocínio mais profundo ou comportamento agêntico mais forte:
- análise de base de código, revisão de código e planos de refatoração
- agentes de codificação autônomos que precisam raciocinar em vários arquivos
- depuração de contexto longo ou análise de incidentes
- planejamento de várias etapas com alto custo de falha
- raciocínio matemático, STEM ou estilo programação competitiva
- fluxos de trabalho de usuários premium onde a qualidade da resposta importa mais que o custo unitário
O guia de contexto longo do DeepSeek V4 Pro é o melhor complemento interno quando o leitor quiser mais detalhes sobre o uso do Pro para cargas de trabalho de contexto longo.
Escolha DeepSeek V4 Flash para tráfego de produto escalável
Use Flash quando a carga de trabalho se beneficiar de um preço unitário mais baixo e de um serviço mais leve:
- recursos de chat e assistente de alto volume
- classificação, roteamento, extração e sumarização
- tarefas de explicação de código ou documentação de primeira passagem
- fluxos de trabalho de suporte com muitos prompts semelhantes
- processamento em segundo plano onde um fallback para Pro está disponível
- aplicativos onde latência e custo são restrições centrais da experiência do usuário
O guia DeepSeek V4 Flash na Novita AI é o companheiro de configuração natural para desenvolvedores que escolhem Flash como modelo padrão.
Evite mudanças cegas
Não mude apenas porque dois modelos compartilham tamanho de contexto e acesso a endpoint. Antes da migração, verifique se o novo modelo preserva:
- comportamento do prompt em seus exemplos de produção
- formato de saída JSON ou estruturado
- argumentos de chamada de ferramenta e comportamento de falha
- latência sob concorrência esperada
- custo total após repetições e saídas mais longas
- guardrails, comportamento de recusa e tratamento de casos extremos
Para muitos sistemas, a melhor resposta não é Pro ou Flash. É uma política de roteamento que usa ambos.
Notas de migração para desenvolvedores
Se você está migrando entre os dois modelos, o ID do modelo é o primeiro campo a ser atualizado:
| Direção | Mudança |
| Flash para Pro | Substitua deepseek/deepseek-v4-flash por deepseek/deepseek-v4-pro para prompts mais difíceis. |
| Pro para Flash | Substitua deepseek/deepseek-v4-pro por deepseek/deepseek-v4-flash para prompts base sensíveis a custos. |
| Roteamento misto | Mantenha ambos os IDs e roteie por dificuldade da tarefa, nível de conta ou pontuação de avaliação. |
Lista de verificação de migração:
- Confirme a disponibilidade atual do modelo nas páginas de modelo da Novita AI.
- Confirme os preços atuais antes de alterar as suposições de custo.
- Mantenha a mesma URL base e endpoint de chat completions para os exemplos neste guia.
- Execute um conjunto de regressão de prompts representativo.
- Compare a qualidade da saída por tipo de tarefa, não apenas pela taxa de vitória agregada.
- Acompanhe uso de tokens, latência, repetições e taxa de fallback.
- Mantenha um plano de reversão que possa redirecionar o tráfego de volta para o ID do modelo anterior.
Recomendação final
Para a maioria das equipes, o DeepSeek V4 Flash deve ser o primeiro modelo a testar para tráfego de produção de alto volume, pois lista preços de entrada, saída e leitura de cache muito mais baixos, mantendo os mesmos limites visíveis de contexto e saída máxima que o Pro na Novita AI.
O DeepSeek V4 Pro deve ser reservado para tarefas onde a qualidade, profundidade de raciocínio ou confiabilidade na codificação agêntica tenham mais valor de negócio que o preço mais alto do token. Se seu produto inclui prompts rotineiros e difíceis, roteie solicitações rotineiras para Flash e escale solicitações mais difíceis para Pro após sua avaliação confirmar a divisão.
FAQ
Qual é a principal diferença entre DeepSeek V4 Pro e DeepSeek V4 Flash?
Na Novita AI, o limite de contexto visível, o limite máximo de saída, as modalidades e o caminho de requisição de chat completions usados neste guia são os mesmos. A principal diferença é o posicionamento e o preço: Pro é a opção focada em qualidade para raciocínio complexo e codificação agêntica, enquanto Flash é a opção de menor custo para uso de alto volume e sensível à latência.
Ambos os modelos estão disponíveis na Novita AI?
Sim. A Novita AI possui páginas de modelo para deepseek/deepseek-v4-pro e deepseek/deepseek-v4-flash, e ambos são listados como modelos LLM serverless.
O DeepSeek V4 Flash é mais barato que o DeepSeek V4 Pro?
A partir de 9 de junho de 2026, as páginas atuais dos modelos da Novita AI listam Flash a US$ 0,14 por 1M de tokens de entrada e US$ 0,28 por 1M de tokens de saída, enquanto Pro é listado a US$ 1,60 por 1M de tokens de entrada e US$ 3,20 por 1M de tokens de saída.
Devo atualizar do Flash para o Pro?
Atualize cargas de trabalho específicas para o Pro quando o Flash não atender ao seu objetivo de qualidade em codificação complexa, raciocínio de contexto longo ou tarefas de alto custo de falha. Não atualize todo o tráfego até comparar prompts reais, custo total, latência e casos de falha.
Ambos os modelos podem usar o mesmo endpoint de chat completions?
Sim. As páginas de modelo da Novita AI listam chat/completions para ambos os modelos, e a referência da API documenta o endpoint de chat completions compatível com OpenAI em /openai/v1/chat/completions.
Os benchmarks provam que o Pro é sempre melhor que o Flash?
Não. Os dados de benchmark relatados dão ao Pro uma pontuação de Intelligence Index mais alta, enquanto o Flash mostra maior velocidade de saída, menor latência do primeiro token e preços de token listados mais baixos. Use Pro para tarefas de raciocínio ou codificação mais difíceis e teste Flash para tráfego de produto de alto volume.



