

- DeepSeek V4 Pro vs DeepSeek V4 Flash: Comparación rápida
- ¿Qué cambia entre Pro y Flash?
- Comparación de precios en Novita AI
- Señales de referencia y rendimiento
- ¿Qué API de DeepSeek V4 deberías usar en Novita AI?
- Mejores casos de uso: Cuándo elegir cada modelo
- Notas de migración para desarrolladores
- Recomendación final
- Artículos recomendados
- Preguntas frecuentes
Elige DeepSeek V4 Pro en Novita AI cuando necesites la opción de mayor calidad para codificación compleja, razonamiento de contexto largo o flujos de trabajo de agente con alto coste de fallo; elige DeepSeek V4 Flash cuando quieras el mismo patrón de API chat/completions, la misma ventana de contexto de 1,048,576 tokens y un precio por token mucho más bajo para el tráfico base. Según lo verificado el 24 de junio de 2026, Pro tiene un precio de $1.60 por millón de tokens de entrada y $3.20 por millón de tokens de salida, mientras que Flash tiene $0.14 por millón de tokens de entrada y $0.28 por millón de tokens de salida.
DeepSeek V4 Pro vs DeepSeek V4 Flash: Comparación rápida
Adecuación del modelo
| Campo | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Mejor para | Flujos de trabajo de agente complejos, desarrollo de software de nivel profesional, razonamiento difícil | Aplicaciones de alta concurrencia, cargas de trabajo ligeras, tráfico de producción sensible al coste |
| Regla de decisión | Úsalo cuando el coste del fallo sea alto | Úsalo cuando el volumen de solicitudes o la latencia importen más |
API y límites
| Campo | DeepSeek V4 Pro | DeepSeek V4 Flash |
| ID de modelo | deepseek/deepseek-v4-pro |
deepseek/deepseek-v4-flash |
| Disponibilidad | Disponible, LLM serverless | Disponible, LLM serverless |
| Ventana de contexto | 1,048,576 tokens | 1,048,576 tokens |
| Máx. tokens de salida | 393,216 tokens | 393,216 tokens |
| Modalidad de entrada/salida | Entrada de texto, salida de texto | Entrada de texto, salida de texto |
| Ruta de solicitud API | Completaciones de chat compatibles con OpenAI | Completaciones de chat compatibles con OpenAI |
Resumen de precios
| Campo | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Precio de entrada | $1.60 por 1M de tokens | $0.14 por 1M de tokens |
| Precio de salida | $3.20 por 1M de tokens | $0.28 por 1M de tokens |
| Precio de lectura de caché | $0.135 por 1M de tokens | $0.028 por 1M de tokens |
Notas de características
| Campo | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Características listadas | Serverless, llamada a funciones, salidas estructuradas, razonamiento | Serverless, llamada a funciones, salidas estructuradas, razonamiento |
| Nota práctica | Enruta los prompts más difíciles a Pro | Usa Flash para tráfico base escalable |
¿Qué cambia entre Pro y Flash?
El cambio más importante no es la longitud del contexto ni el acceso básico a completaciones de chat. En Novita AI, ambos modelos tienen una ventana de contexto de 1,048,576 tokens, máximo de 393,216 tokens de salida, entrada de texto, salida de texto, entrega serverless, llamada a funciones, salidas estructuradas y soporte de razonamiento.
La diferencia práctica es el posicionamiento y el precio. La página del modelo DeepSeek V4 Pro describe a Pro como la opción insignia para flujos de trabajo de agente complejos, desarrollo de software profesional, evaluaciones con mucho razonamiento y tareas de codificación exigentes. La página del modelo DeepSeek V4 Flash posiciona a Flash como una opción ligera para un servicio API rápido y económico, alta concurrencia, baja latencia y cargas de trabajo ligeras a gran escala.
Esto les da a los desarrolladores un patrón de enrutamiento claro:
- Usa Pro para tareas donde una mala respuesta puede costar más que el precio extra del token: cambios de código autónomos, sesiones largas de depuración, análisis a nivel de repositorio, planificación y razonamiento difícil.
- Usa Flash para solicitudes donde el coste y la capacidad de respuesta moldean la experiencia del producto: asistencia en chat, clasificación inicial, resumen, extracción, enrutamiento y llamadas de producción repetidas.
- Usa ambos cuando tu aplicación pueda separar los “prompts difíciles” de los “prompts estándar”. Flash puede manejar la mayor parte del tráfico base, mientras que Pro puede reservarse para escaladas o flujos de trabajo premium.
Si ya leíste la guía de lanzamiento de DeepSeek V4 Flash, trata esta página como la capa de decisión: se trata de cuándo seleccionar cada API, no de repetir la configuración de lanzamiento.
Comparación de precios en Novita AI
Los precios actuales de las páginas de modelo de Novita AI muestran una gran diferencia de coste entre los dos modelos:
Precios de DeepSeek V4 Pro
| Campo | Valor |
| Precio de entrada | $1.60 por 1M de tokens |
| Precio de salida | $3.20 por 1M de tokens |
| Precio de entrada de lectura de caché | $0.135 por 1M de tokens |
| Usar cuando | Razonamiento complejo, codificación de agente o tareas con alto coste de fallo |
Precios de DeepSeek V4 Flash
| Campo | Valor |
| Precio de entrada | $0.14 por 1M de tokens |
| Precio de salida | $0.28 por 1M de tokens |
| Precio de entrada de lectura de caché | $0.028 por 1M de tokens |
| Usar cuando | Tráfico de producción de alto volumen, sensible a la latencia o al coste |
Para tokens de entrada y salida, Pro es aproximadamente 11.4 veces el precio listado de Flash. Eso no significa que Flash sea siempre la mejor opción de negocio; significa que Pro debe usarse donde su ventaja de calidad esperada justifique el mayor coste unitario.
Una política de producción simple funciona bien:
- Usa Flash por defecto para prompts de alto volumen que tengan instrucciones claras, criterios de evaluación cortos y bajo coste de fallo.
- Escala a Pro cuando el usuario solicite codificación difícil, razonamiento de varios pasos, síntesis de contexto largo o una respuesta de alto riesgo.
- Realiza una prueba en paralelo con un conjunto de prompts representativo antes de cambiar el enrutamiento de producción. Compara calidad de salida, reintentos, aceptación del usuario, tokens totales, latencia y casos de fallo, no solo el precio por token.
Los precios pueden cambiar, así que verifica las páginas de modelo actuales antes de publicar un flujo de trabajo o cotización sensible al precio. Si tu intención de búsqueda es “precios de DeepSeek V4 Pro vs Flash”, esta brecha de precios es la razón principal por la que la mayoría de los equipos comienzan con Flash para el tráfico general y mantienen a Pro como un nivel de escalada.
Señales de referencia y rendimiento
Los datos de referencia de Artificial Analysis indican un claro equilibrio entre el uso orientado a la calidad y el orientado al rendimiento. DeepSeek V4 Pro reporta la puntuación de inteligencia más alta, mientras que DeepSeek V4 Flash reporta métricas de velocidad y coste más sólidas. Estos resultados deben tratarse como insumos de decisión, no como clasificaciones universales.
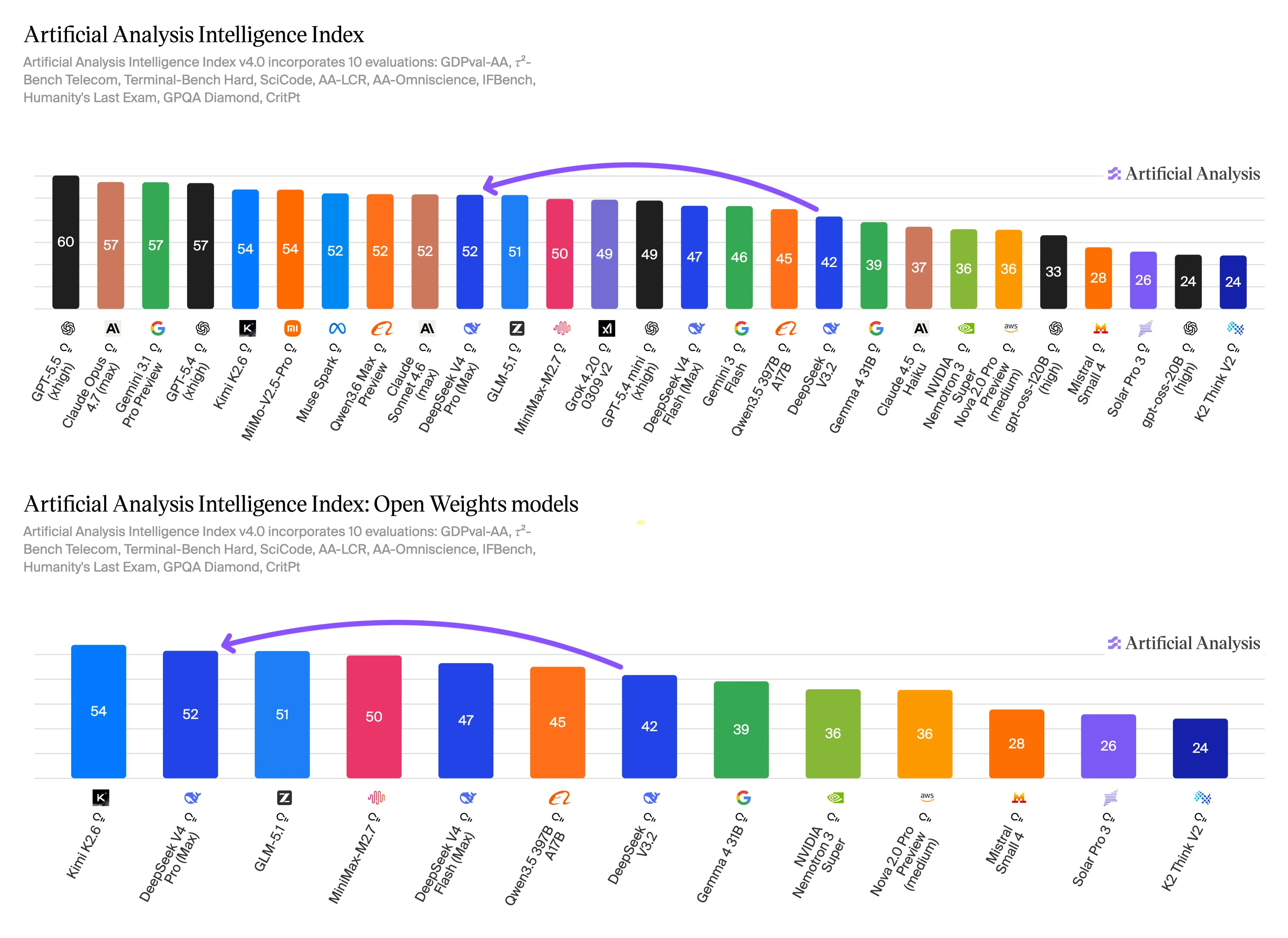
El Intelligence Index v4.0 cubre evaluaciones para trabajo de agente, tareas de terminal y codificación, razonamiento de contexto largo, conocimiento, seguimiento de instrucciones, razonamiento científico y pruebas de calidad relacionadas. Este alcance de evaluación es relevante aquí porque esas categorías se superponen con la razón principal para elegir Pro: trabajo más difícil de varios pasos donde una respuesta de mayor calidad puede justificar un mayor coste unitario.
Flash aún se desempeña de manera competitiva en la misma escala de referencia, y su perfil de velocidad y precio lo convierten en una opción práctica para rutas de producción que ejecutan muchos prompts similares. Usa Flash para resúmenes de primera pasada, clasificación, extracción, asistencia de soporte o enrutamiento. Escala a Pro cuando el prompt sea ambiguo, requiera un razonamiento más profundo, toque una base de código grande o tenga un alto coste de fallo.
Antes de reemplazar un modelo por el otro, ejecuta tu propio conjunto de prompts en ambas APIs. Realiza un seguimiento de las respuestas aceptadas, la tasa de reintentos, la latencia, el coste total de tokens, la fiabilidad de las salidas estructuradas y el comportamiento de las llamadas a herramientas. El benchmark sugiere por dónde empezar, pero el enrutamiento de producción debe seguir tu carga de trabajo real.
¿Qué API de DeepSeek V4 deberías usar en Novita AI?
Ambos modelos usan la API LLM compatible con OpenAI de Novita AI. El ID del modelo es el campo que cambias al alternar entre Pro y Flash, por lo que la decisión de la API es principalmente una decisión de enrutamiento: envía los prompts sensibles a la calidad a deepseek/deepseek-v4-pro y los prompts base de alto volumen a deepseek/deepseek-v4-flash.
Si buscaste el ID de modelo exacto, la ruta de documentación de la API o qué endpoint cambia entre los dos modelos, la respuesta breve es que el endpoint no cambia. Mantienes la misma URL base de Novita y la ruta POST /openai/v1/chat/completions, y luego cambias solo el valor de model y tu política de enrutamiento.
Si necesitas los detalles de implementación antes de ejecutar una evaluación, abre la guía de contexto largo de DeepSeek V4 Pro para la planificación de solicitudes de Pro y la guía de configuración de DeepSeek V4 Flash para la ruta predeterminada de menor coste.
Paso 1: Confirma los IDs de modelo y la disponibilidad
Usa las páginas de modelo actuales antes de la implementación:
- Precios y playground de la API de DeepSeek V4 Pro:
deepseek/deepseek-v4-pro - Precios y playground de la API de DeepSeek V4 Flash:
deepseek/deepseek-v4-flash
También se puede usar el endpoint de listado de modelos de Novita AI para verificar los objetos de modelo disponibles y campos como ID de modelo, campos de precio, título, descripción y tamaño de contexto.
Paso 2: Usa la URL base compatible con OpenAI
La referencia de la API de Novita AI enumera endpoints compatibles con OpenAI bajo:
https://api.novita.ai/openai
Para completaciones de chat, el endpoint es:
https://api.novita.ai/openai/v1/chat/completions
Las solicitudes requieren un token Bearer en el encabezado Authorization.
Paso 3: Ejecuta el mismo prompt contra ambos modelos
Comienza con un pequeño conjunto de evaluación que represente el tráfico real: prompts fáciles, prompts de contexto largo, prompts de codificación, prompts de estilo herramienta, prompts de extracción y prompts propensos a fallos.
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-flash",
"messages": [
{
"role": "user",
"content": "Resume las ventajas y desventajas entre el procesamiento por lotes y el streaming para una API de chat LLM."
}
],
"max_tokens": 500,
"temperature": 0.2
}'
Luego cambia solo el ID del modelo:
curl --request POST \
--url https://api.novita.ai/openai/v1/chat/completions \
--header "Authorization: Bearer $NOVITA_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "deepseek/deepseek-v4-pro",
"messages": [
{
"role": "user",
"content": "Resume las ventajas y desventajas entre el procesamiento por lotes y el streaming para una API de chat LLM."
}
],
"max_tokens": 500,
"temperature": 0.2
}'
Paso 4: Compara las señales de producción
Para cada clase de prompt, registra:
- calidad y corrección de la finalización
- fiabilidad del formato de salida
- comportamiento de herramientas o llamadas a funciones si tu aplicación depende de ello
- tokens totales de entrada y salida
- latencia bajo la concurrencia esperada
- tasa de reintentos y tasa de fallback
- tasa de aceptación o edición visible para el usuario
Esto es especialmente importante si planeas enrutar solicitudes estándar a Flash y escaladas a Pro.
Mejores casos de uso: Cuándo elegir cada modelo
Elige DeepSeek V4 Pro para trabajos complejos
Usa Pro cuando la tarea necesite un razonamiento más profundo o un comportamiento de agente más fuerte:
- análisis de base de código, revisión de código y planes de refactorización
- agentes de codificación autónomos que necesitan razonar a través de múltiples archivos
- depuración de contexto largo o análisis de incidentes
- planificación de varios pasos con alto coste de fallo
- razonamiento matemático, STEM o estilo programación competitiva
- flujos de trabajo de usuarios premium donde la calidad de la respuesta importa más que el coste unitario
La guía de contexto largo de DeepSeek V4 Pro es el mejor seguimiento interno cuando el lector quiere más detalles sobre el uso de Pro para cargas de trabajo de contexto largo.
Elige DeepSeek V4 Flash para tráfico de producto escalable
Usa Flash cuando la carga de trabajo se beneficie de un precio unitario más bajo y un servicio más ligero:
- funciones de chat y asistente de alto volumen
- clasificación, enrutamiento, extracción y resumen
- explicación de código de primera pasada o tareas de documentación
- flujos de trabajo de soporte con muchos prompts similares
- procesamiento en segundo plano donde haya disponible un fallback a Pro
- aplicaciones donde la latencia y el coste son restricciones centrales de la experiencia del usuario
La guía de DeepSeek V4 Flash en Novita AI es el complemento de configuración natural para los desarrolladores que eligen Flash como modelo predeterminado.
Evita cambiar ciegamente
No cambies solo porque dos modelos compartan la longitud de contexto y el acceso al endpoint. Antes de la migración, verifica que el nuevo modelo preserve:
- el comportamiento del prompt en tus ejemplos de producción
- la forma de la salida JSON o estructurada
- los argumentos de llamada a herramientas y el comportamiento ante fallos
- la latencia bajo la concurrencia esperada
- el coste total después de reintentos y salidas más largas
- las barreras de seguridad, el comportamiento de rechazo y el manejo de casos límite
Para muchos sistemas, la mejor respuesta no es Pro o Flash. Es una política de enrutamiento que usa ambos.
Notas de migración para desarrolladores
Si estás migrando entre los dos modelos, el ID del modelo es el primer campo a actualizar:
| Dirección | Cambio |
| Flash a Pro | Reemplaza deepseek/deepseek-v4-flash con deepseek/deepseek-v4-pro para prompts más difíciles. |
| Pro a Flash | Reemplaza deepseek/deepseek-v4-pro con deepseek/deepseek-v4-flash para prompts base sensibles al coste. |
| Enrutamiento mixto | Mantén ambos IDs y enruta según la dificultad de la tarea, el nivel de cuenta o la puntuación de evaluación. |
Lista de verificación de migración:
- Confirma la disponibilidad actual del modelo en las páginas de modelo de Novita AI.
- Confirma los precios actuales antes de cambiar las suposiciones de coste.
- Mantén la misma URL base y endpoint de completaciones de chat para los ejemplos de esta guía.
- Ejecuta un conjunto de regresión de prompts representativo.
- Compara la calidad de salida por tipo de tarea, no solo por tasa de victorias agregada.
- Realiza un seguimiento del uso de tokens, latencia, reintentos y tasa de fallback.
- Mantén un plan de reversión que pueda cambiar el tráfico de vuelta al ID de modelo anterior.
Recomendación final
Para la mayoría de los equipos, DeepSeek V4 Flash debería ser el primer modelo a probar para tráfico de producción de alto volumen, ya que tiene precios de entrada, salida y lectura de caché mucho más bajos, mientras mantiene el mismo contexto visible y los mismos límites máximos de salida que Pro en Novita AI.
DeepSeek V4 Pro debe reservarse para tareas donde la calidad, la profundidad del razonamiento o la fiabilidad de la codificación de agente tengan más valor comercial que el precio más alto del token. Si tu producto incluye prompts tanto rutinarios como difíciles, enruta las solicitudes rutinarias a Flash y escala las solicitudes más difíciles a Pro después de que tu evaluación confirme la división.
Artículos recomendados
- DeepSeek V4 Flash en Novita AI
- Guía de contexto largo de DeepSeek V4 Pro
- Mejores proveedores de API LLM 2026
Preguntas frecuentes
¿Cuál es la principal diferencia entre DeepSeek V4 Pro y DeepSeek V4 Flash?
En Novita AI, el límite de contexto visible, el límite máximo de salida, las modalidades y la ruta de solicitud de completaciones de chat utilizados en esta guía son los mismos. La principal diferencia es el posicionamiento y el precio: Pro es la opción centrada en la calidad para razonamiento complejo y codificación de agente, mientras que Flash es la opción de menor coste para uso de alto volumen y sensible a la latencia.
¿Ambos modelos están disponibles en Novita AI?
Sí. Novita AI tiene páginas de modelo tanto para deepseek/deepseek-v4-pro como para deepseek/deepseek-v4-flash, y ambos están listados como modelos LLM serverless.
¿DeepSeek V4 Flash es más barato que DeepSeek V4 Pro?
A partir del 9 de junio de 2026, las páginas de modelo actuales de Novita AI listan Flash a $0.14 por 1M de tokens de entrada y $0.28 por 1M de tokens de salida, mientras que Pro está listado a $1.60 por 1M de tokens de entrada y $3.20 por 1M de tokens de salida.
¿Debería actualizar de Flash a Pro?
Actualiza cargas de trabajo específicas a Pro cuando Flash no cumpla con tu objetivo de calidad en codificación compleja, razonamiento de contexto largo o tareas con alto coste de fallo. No actualices todo el tráfico hasta que compares prompts reales, coste total, latencia y casos de fallo.
¿Pueden ambos modelos usar el mismo endpoint de completaciones de chat?
Sí. Las páginas de modelo de Novita AI listan chat/completions para ambos modelos, y la referencia de la API documenta el endpoint de completaciones de chat compatible con OpenAI en /openai/v1/chat/completions.
¿Los benchmarks demuestran que Pro es siempre mejor que Flash?
No. Los datos de referencia reportados le dan a Pro una puntuación más alta en el Intelligence Index, mientras que Flash muestra mayor velocidad de salida, menor latencia del primer token y precios de token listados más bajos. Usa Pro para tareas de razonamiento o codificación más difíciles, y prueba Flash para tráfico de producto de alto volumen.



