

Разработчики, выбирающие между GLM-4.7 Flash и Qwen3-30B-A3B-Thinking-2507, сталкиваются с очевидным компромиссом: мастерство в программной инженерии против глубины рассуждений. Обе являются моделями класса 30B с архитектурой MoE с примерно 3 млрд активных параметров на токен, длинными контекстными окнами (202K у GLM-4.7 Flash, 262K у Qwen3) и схожими требованиями к VRAM. Разница заключается в том, для чего они оптимизированы: GLM-4.7 Flash — для агентных рабочих процессов кодинга (вызов инструментов, веб-браузинг, генерация кода), Qwen3-30B-A3B-Thinking-2507 — для многошаговых рассуждений с выделенным «режимом мышления», который отображает внутренние следы рассуждений.
Какую модель стоит выбрать?
| Выбирайте GLM-4.7 Flash, если вам нужно: | Выбирайте Qwen3-30B-A3B-Thinking-2507, если вам нужно: |
|---|---|
| • Задачи программной инженерии (59.2% по бенчмарку SWE-bench Verified) • Автоматизация задач в браузере (42.8% по BrowseComp против 2.29%) • Агентный вызов инструментов (79.5% по τ²-Bench против 49.0%) • Кодинговые агенты с меньшей задержкой • Задачи, требующие качественной навигации по вебу и автоматизации • Генерация и рефакторинг кода в реальном времени |
• Многошаговая логика с отображением следов рассуждений • Научные исследования и решение академических задач • Задачи на следование инструкциям (88.9% по IFEval) • Многоязычное понимание и анализ длинного контекста |
Попробуйте GLM 4.7 Flash сейчас!
Сравнение архитектуры
Обе являются моделями класса 30B с архитектурой MoE с примерно 3 млрд активных параметров и длинными контекстными окнами, а также имеют в целом схожие требования к VRAM.
| Параметр | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| Общее количество параметров | 30B | 31B |
| Активные параметры (на токен) | 3 млрд (64 эксперта, 4 активных) | 3.3 млрд (128 экспертов, 8 активных) |
| Длина контекста | 202 752 токена | 262 144 токена |
| Скрытые слои | 47 | 48 |
| Головы внимания | 20 (стандартные) | 32 Q / 4 KV (GQA) |
| Точность | bfloat16 | bfloat16 |
| Поддержка мультимодальности | Нет (только текст) | Нет (только текст) |
| Особые функции | Автоматизация браузера, вызов инструментов | Режим мышления (следы рассуждений) |
Ключевое архитектурное отличие: Qwen3 использует группированное внимание запросов (Grouped Query Attention, 32 головы запросов, 4 головы ключей/значений) для эффективного управления кэшем KV при длинноконтекстном выводе, в то время как GLM-4.7 Flash использует стандартное внимание с меньшим количеством голов (20). Qwen активирует 8 экспертов на токен (против 4 у GLM-4.7 Flash), что обеспечивает большую гибкость маршрутизации ценой немного более высоких вычислений на один проход вперед.
Обе модели имеют практически одинаковую эффективность параметров (3 млрд активных). Однако GLM-4.7 Flash жертвует некоторой глубиной рассуждений в пользу более быстрого выполнения инструментов, в то время как Qwen3 делает больший акцент на более глубоких многошаговых рассуждениях за счет своей архитектуры с режимом мышления.
Попробуйте GLM 4.7 Flash сейчас!
Сравнение бенчмарков
Разрыв в производительности между этими моделями четко проявляется при группировке по типу задач. Мы разделили бенчмарки на три категории: кодинг/программная инженерия, рассуждения/академические задачи и специализированные возможности.
Бенчмарки кодинга и программной инженерии
| Бенчмарк | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| SWE-bench Verified | 59.2% 🏆 | 22.0% |
| τ²-Bench (использование инструментов) | 79.5% 🏆 | 49.0% |
| BrowseComp | 42.8% 🏆 | 2.29% |
Источник: страницы моделей Unsloth / Hugging Face. Данные на март 2026 года.
Бенчмарки рассуждений и академических задач
| Бенчмарк | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| GPQA (вопросы по науке) | 75.2%🏆 | 73.4% |
| AIME 2025 (математика) | 91.6%🏆 | 85.0% |
Источник: страницы моделей Unsloth / Hugging Face. Данные на март 2026 года.
Специализированные возможности
| Бенчмарк | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| HLE (оценка, похожая на человеческую) | 14.4% 🏆 | 9.8% |
Источник: страницы моделей Unsloth / Hugging Face. Данные на март 2026 года.
В целом, GLM-4.7 Flash позиционируется как инженерно-ориентированная модель с упором на инструменты, в то время как Qwen3-30B-A3B-Thinking-2507 оптимизирована для глубоких рассуждений и задач, требующих больших когнитивных затрат.
Попробуйте GLM 4.7 Flash сейчас!
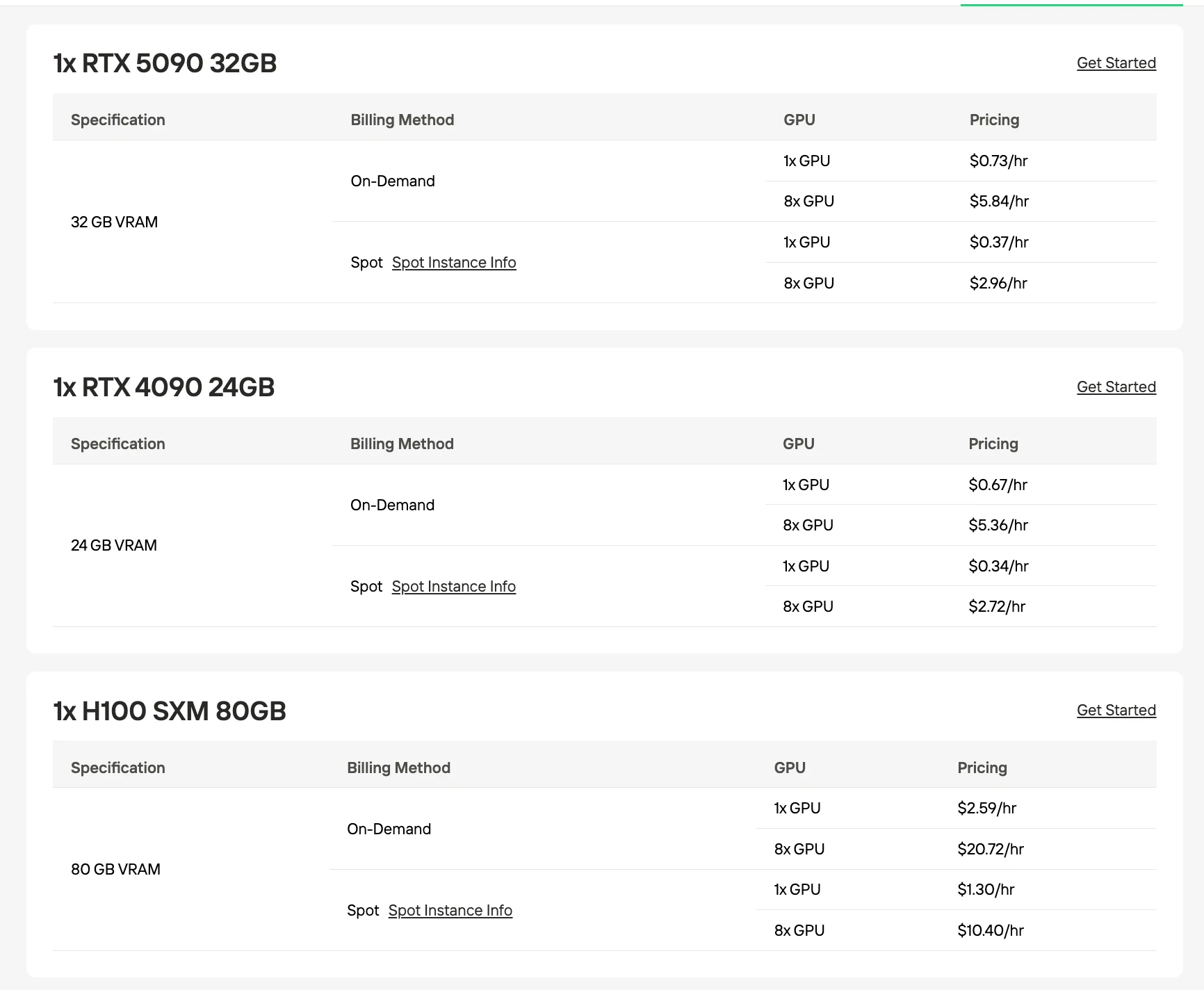
Требования к VRAM и GPU
Обе модели требуют схожего объема базовой VRAM из-за общего количества параметров 30B, но стратегии квантования различаются в зависимости от фокуса оптимизации.
Рекомендуемые GPU для GLM-4.7 Flash
| Квантование / Формат | Размер модели | Требуемый объем VRAM | Рекомендуемая конфигурация |
|---|---|---|---|
| UD-Q4_K_XL (рекомендуется) | 17.52 ГБ | 24 ГБ | Одна RTX 4090 |
| Q4_K_M | 18.31 ГБ | 24 ГБ | Одна RTX 4090 |
| Q5_K_M | 21.41 ГБ | 24 ГБ | Одна RTX 4090 |
| Q8_0 | 31.84 ГБ | 40 ГБ | 2× RTX 4090 или H100 80GB |
| BF16 (полный) | 60 ГБ | 80 ГБ | H100 80GB |
Источник: Unsloth / Hugging Face. Значения VRAM являются оценками на основе размеров квантованных моделей.
Рекомендуемые GPU для Qwen3-30B-A3B-Thinking-2507
| Формат | Размер файла | Минимальный объем VRAM | Лучше всего подходит для |
|---|---|---|---|
| UD-Q4_K_XL (рекомендуется) | 17.72 ГБ | 24 ГБ | Одна RTX 4090 |
| Q4_K_M | 18.56 ГБ | 24 ГБ | Одна RTX 4090 |
| Q5_K_M | 21.73 ГБ | 24 ГБ | Одна RTX 4090 |
| Q8_0 | 32.48 ГБ | 40 ГБ | 2× RTX 4090 или H100 80GB |
| BF16 (полный) | 61 ГБ | 80 ГБ и более | H100 80GB |
Источник: Unsloth / Hugging Face. Значения VRAM являются оценками на основе размеров квантованных моделей.
Попробуйте экономичные GPU сейчас!
Как получить доступ к GLM-4.7 Flash или Qwen3-30B-A3B?
Обе модели поддерживают доступ через API, совместимый с OpenAI, что делает интеграцию простой для разработчиков, уже использующих SDK OpenAI.
Шаг 1: Войдите в аккаунт и перейдите в библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.

Шаг 2: Выберите нужную модель
Просмотрите доступные варианты и выберите модель, которая подходит для ваших задач.

Попробуйте GLM 4.7 Flash сейчас!
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 4: Получите API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
Выбор между GLM-4.7 Flash и Qwen3-30B-A3B-Thinking-2507 сводится к четкой специализации: GLM-4.7 Flash однозначно побеждает для агентов программной инженерии (59.2% по SWE-bench, 79.5% по τ²-Bench, 42.8% по BrowseComp) при непревзойденной стоимости $0.47 за 1M токенов через Novita AI. Для разработчиков, создающих интеграции с Claude Code, терминальной автоматизации или браузерных агентов, GLM-4.7 Flash является очевидным выбором — его преимущество в 2.7 раза по SWE-bench над Qwen3 (59.2% против 22.0%) и минимальные цены делают его идеальным для рабочих процессов кодинга в продакшене.
Заключение
Обе GLM-4.7 Flash и Qwen3-30B-A3B-Thinking-2507 являются мощными моделями класса 30B с архитектурой MoE с практически идентичными требованиями к VRAM, но они предназначены для разных сценариев использования. GLM-4.7 Flash является очевидным выбором для агентов программной инженерии, автоматизации браузера и рабочих процессов с большим количеством инструментов. Qwen3-30B-A3B-Thinking-2507 проявляет себя лучше всего, когда вам нужны прозрачные многошаговые рассуждения с явными следами мышления для исследовательских и аналитических задач.
Ключевой вывод: Если вы создаете кодинговый агент или конвейер автоматизации, выбирайте GLM-4.7 Flash. Если вам нужны структурированные глубокие рассуждения, выбирайте Qwen3-30B-A3B-Thinking-2507. Обе модели доступны на Novita AI — попробуйте GLM-4.7 Flash или изучите полный каталог моделей уже сегодня.
Какая модель лучше подходит для кодинговых агентов: GLM-4.7 Flash или Qwen3-30B-A3B-Thinking-2507?
GLM-4.7 Flash лидирует с результатом 59.2% по бенчмарку SWE-bench Verified (против 22.0% у Qwen) и 79.5% по использованию инструментов в τ²-Bench (против 49.0%).
Какую модель проще развернуть локально?
Обе требуют ~18 ГБ VRAM при квантовании INT4 на одной RTX 4090.
Можно ли запустить GLM-4.7 Flash в Claude Code или Trae?
Да, оба инструмента поддерживают интеграцию пользовательских моделей через API.
Рекомендуемые материалы для чтения
- Использование GLM-4.5 в Trae для создания более умных кодинговых агентов
- Использование MiniMax M2.1 в OpenCode
- DeepSeek против Qwen: определите, какая экосистема подходит для продакшена
Novita AI — это облачная платформа для ИИ и агентов, которая помогает разработчикам и стартапам создавать, развертывать и масштабировать модели и агентные приложения с высокой производительностью, надежностью и экономической эффективностью.



