

选择 GLM-4.7 Flash 与 Qwen3-30B-A3B-Thinking-2507 的开发者面临一个明显的权衡:软件工程能力 vs 推理深度。两者都是 30B 级别的 MoE 模型,每个 token 约有 3B 活跃参数,长上下文窗口(GLM-4.7 Flash 为 202K,Qwen3 为 262K),VRAM 需求相似。区别在于它们的优化方向:GLM-4.7 Flash 面向代理式编码工作流(工具调用、网页浏览、代码生成),而 Qwen3-30B-A3B-Thinking-2507 则面向多步骤推理,配备专门的“思考模式”以暴露内部推理轨迹。
应该选择哪个模型?
| 如需以下功能,请选择 GLM-4.7 Flash: | 如需以下功能,请选择 Qwen3-30B-A3B-Thinking-2507: |
|---|---|
| • 软件工程任务(SWE-bench Verified 59.2%) • 基于浏览器的任务自动化(BrowseComp 42.8% vs 2.29%) • 代理式工具调用(τ²-Bench 79.5% vs 49.0%) • 低延迟编码代理 • 需要强大网页导航和自动化的任务 • 实时代码生成与重构 |
• 多步骤逻辑推理(带有显式推理痕迹) • 科学研究与学术问题求解 • 指令遵循任务(IFEval 88.9%) • 多语言理解与长上下文分析 |
架构对比
两者都是 30B 级别的 MoE 模型,每个 token 约有 3B 活跃参数,上下文窗口较长,VRAM 需求大致相同。
| 方面 | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| 总参数量 | 30B | 31B |
| 活跃参数(每 token) | 3B(64 专家,4 个活跃) | 3.3B(128 专家,8 个活跃) |
| 上下文长度 | 202,752 tokens | 262,144 tokens |
| 隐藏层数 | 47 | 48 |
| 注意力头数 | 20(标准注意力) | 32 Q / 4 KV(GQA) |
| 精度 | bfloat16 | bfloat16 |
| 多模态支持 | 否(仅文本) | 否(仅文本) |
| 特殊功能 | 浏览器自动化、工具调用 | 思考模式(推理痕迹) |
关键架构差异: Qwen3 使用分组查询注意力(32个Q头,4个KV头),以在长上下文推理中高效管理KV缓存;GLM-4.7 Flash 则使用标准注意力机制(20个头)。Qwen3 每个 token 激活 8 个专家(而 GLM-4.7 Flash 激活 4 个),提供了更高的路由灵活性,但每次前向计算的算力消耗也略高。
两个模型的参数效率几乎相同(3B 活跃参数)。不过,GLM-4.7 Flash 牺牲了一定的推理深度以换取更快的工具执行速度,而 Qwen3 则通过其思考模式架构更侧重于更深层次的多步骤推理。
基准测试对比
按任务类型分组后,两个模型之间的性能差距清晰可见。我们将基准测试分为三类:编码/工程、推理/学术以及专项能力。
编码与软件工程基准测试
| 基准测试 | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| SWE-bench Verified | 59.2% 🏆 | 22.0% |
| τ²-Bench(工具使用) | 79.5% 🏆 | 49.0% |
| BrowseComp | 42.8% 🏆 | 2.29% |
来源:Unsloth / Hugging Face 模型页面。数据截至 2026 年 3 月。
推理与学术基准测试
| 基准测试 | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| GPQA(科学问答) | 75.2%🏆 | 73.4% |
| AIME 2025(数学) | 91.6%🏆 | 85.0% |
来源:Unsloth / Hugging Face 模型页面。数据截至 2026 年 3 月。
专项能力
| 基准测试 | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| HLE(类人评估) | 14.4% 🏆 | 9.8% |
来源:Unsloth / Hugging Face 模型页面。数据截至 2026 年 3 月。
总体而言,GLM-4.7 Flash 定位为工程和工具导向型模型,而 Qwen3-30B-A3B-Thinking-2507 则针对深度推理和认知密集型任务进行了优化。
VRAM 与 GPU 需求
由于两个模型均为 30B 参数量,基础 VRAM 需求相似,但量化策略因优化侧重点不同而略有差异。
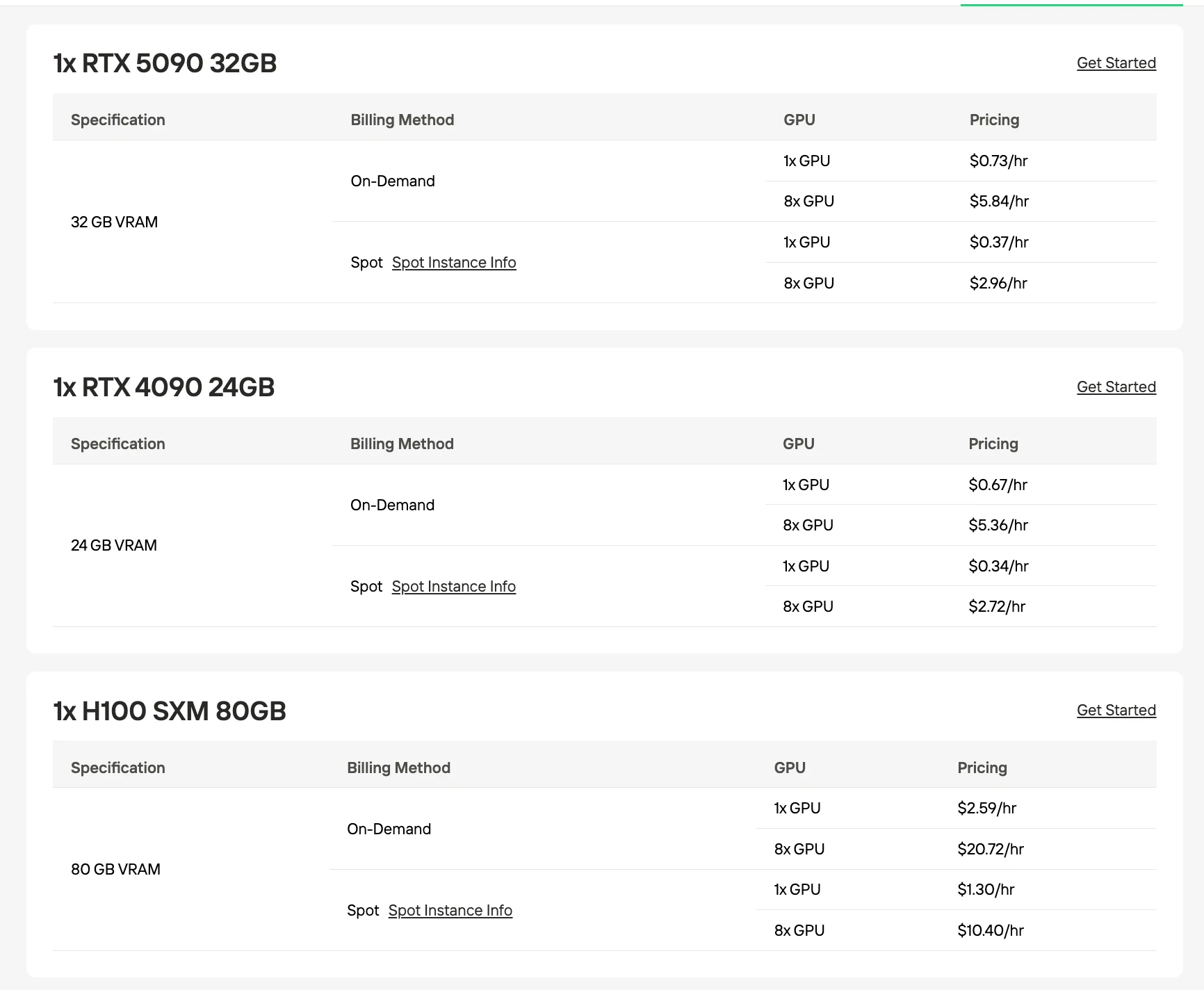
GLM-4.7 Flash 推荐 GPU
| 量化/格式 | 模型大小 | VRAM 需求 | 推荐配置 |
|---|---|---|---|
| UD-Q4_K_XL(推荐) | 17.52 GB | 24 GB | 单张 RTX 4090 |
| Q4_K_M | 18.31 GB | 24 GB | 单张 RTX 4090 |
| Q5_K_M | 21.41 GB | 24 GB | 单张 RTX 4090 |
| Q8_0 | 31.84 GB | 40 GB | 2× RTX 4090 或 H100 80GB |
| BF16(完整) | 60 GB | 80 GB | H100 80GB |
来源:Unsloth / Hugging Face。VRAM 数据基于量化模型大小估算。
Qwen3-30B-A3B-Thinking-2507 推荐 GPU
| 格式 | 文件大小 | 最低 VRAM | 最佳用途 |
|---|---|---|---|
| UD-Q4_K_XL(推荐) | 17.72 GB | 24 GB | 单张 RTX 4090 |
| Q4_K_M | 18.56 GB | 24 GB | 单张 RTX 4090 |
| Q5_K_M | 21.73 GB | 24 GB | 单张 RTX 4090 |
| Q8_0 | 32.48 GB | 40 GB | 2× RTX 4090 或 H100 80GB |
| BF16(完整) | 61 GB | 80 GB+ | H100 80GB |
来源:Unsloth / Hugging Face。VRAM 数据基于量化模型大小估算。
如何访问 GLM-4.7 Flash 或 Qwen3-30B-A3B?
两个模型均支持 OpenAI 兼容的 API 接口,使已经使用 OpenAI SDK 的开发者能够轻松集成。
步骤 1:登录并访问模型库
登录您的账户,然后点击模型库按钮。

步骤 2:选择模型
浏览可用选项,选择符合您需求的模型。

步骤 3:开始免费试用
开始免费试用,探索所选模型的能力。
步骤 4:获取您的 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新 API 密钥。进入“设置”页面,您可以按照图片中的指示复制 API 密钥。

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
选择 GLM-4.7 Flash 还是 Qwen3-30B-A3B-Thinking-2507,归根结底是明确的分工:GLM-4.7 Flash 在软件工程代理方面具有决定性优势(SWE-bench 59.2%,τ²-Bench 79.5%,BrowseComp 42.8%),且通过 Novita AI 提供的混合成本仅为 $0.47/1M,极具竞争力。对于正在构建 Claude Code 集成、终端自动化或基于浏览器的代理的开发者来说,GLM-4.7 Flash 是显而易见的选择——它在 SWE-bench 上领先 Qwen3 2.7 倍(59.2% vs 22.0%),加上极高的性价比,非常适合生产级编码工作流。
结论
GLM-4.7 Flash 和 Qwen3-30B-A3B-Thinking-2507 都是优秀的 30B 级 MoE 模型,VRAM 需求几乎相同,但适用于不同的使用场景。GLM-4.7 Flash 是软件工程代理、浏览器自动化和繁重工具工作流的明确选择。Qwen3-30B-A3B-Thinking-2507 在需要透明的多步骤推理并带有显式思考痕迹的研究和分析任务中表现出色。
关键要点: 如果您正在构建编码代理或自动化管道,请选择 GLM-4.7 Flash。如果您需要结构化的深度推理,请选择 Qwen3-30B-A3B-Thinking-2507。两者均可通过 Novita AI 获取——立即试用 GLM-4.7 Flash 或浏览完整的模型目录。
对于编码代理,GLM-4.7 Flash 和 Qwen3-30B-A3B-Thinking-2507 哪个更好?
GLM-4.7 Flash 遥遥领先,SWE-bench Verified 得分 59.2%(Qwen3 为 22.0%),τ²-Bench 工具使用得分 79.5%(Qwen3 为 49.0%)。
哪个模型更容易本地部署?
两者在 INT4 量化下均需约 18GB VRAM,可在 1× RTX 4090 上运行。
我可以在 Claude Code 或 Trae 中运行 GLM-4.7 Flash 吗?
可以,这两个工具都支持通过 API 自定义模型集成。
推荐阅读
Novita AI 是一个 AI 与代理云平台,帮助开发者和初创企业构建、部署和扩展模型及代理应用程序,提供高性能、高可靠性和高成本效益。



