

Desenvolvedores que escolhem entre o GLM-4.7 Flash e o Qwen3-30B-A3B-Thinking-2507 enfrentam uma troca clara: domínio de engenharia de software versus profundidade de raciocínio. Ambos são modelos MoE de classe 30B com cerca de 3B de parâmetros ativos por token, janelas de contexto longo (202K para o GLM-4.7 Flash, 262K para o Qwen3) e requisitos de VRAM semelhantes. A divergência está no que eles são otimizados: o GLM-4.7 Flash para fluxos de trabalho de codificação agentiva (chamada de ferramentas, navegação web, geração de código), e o Qwen3-30B-A3B-Thinking-2507 para raciocínio multi-etapas com um “modo de pensamento” dedicado que expõe os traços de raciocínio interno.
Qual Modelo Você Deve Escolher?
| Escolha o GLM-4.7 Flash se você precisar de: | Escolha o Qwen3-30B-A3B-Thinking-2507 se você precisar de: |
|---|---|
| • Tarefas de engenharia de software (59,2% no SWE-bench Verified) • Automação de tarefas baseada em navegador (42,8% no BrowseComp vs 2,29%) • Chamada de ferramentas agentiva (79,5% no τ²-Bench vs 49,0%) • Agentes de codificação com menor latência • Tarefas que exigem navegação web e automação robustas • Geração e refatoração de código em tempo real |
• Lógica multi-etapas com traços de raciocínio expostos • Pesquisa científica e resolução de problemas acadêmicos • Tarefas de seguimento de instruções (88,9% no IFEval) • Compreensão multilíngue e análise de contexto longo |
Experimente o GLM 4.7 Flash Agora!
Comparação de Arquitetura
Ambos são modelos MoE de classe 30B com cerca de 3B de parâmetros ativos e janelas de contexto longo, e têm requisitos de VRAM amplamente semelhantes.
| Aspecto | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| Parâmetros Totais | 30B | 31B |
| Parâmetros Ativos (por token) | 3B (64 especialistas, 4 ativos) | 3,3B (128 especialistas, 8 ativos) |
| Comprimento do Contexto | 202.752 tokens | 262.144 tokens |
| Camadas Ocultas | 47 | 48 |
| Cabeças de Atenção | 20 (padrão) | 32 Q / 4 KV (GQA) |
| Precisão | bfloat16 | bfloat16 |
| Suporte Multimodal | Não (apenas texto) | Não (apenas texto) |
| Recursos Especiais | Automação de navegador, chamada de ferramentas | Modo de pensamento (traços de raciocínio) |
Diferença arquitetônica principal: O Qwen3 usa Atenção de Consulta Agrupada (Grouped Query Attention, 32 cabeças Q, 4 cabeças KV) para gerenciamento eficiente do cache KV durante a inferência de contexto longo, enquanto o GLM-4.7 Flash usa atenção padrão com menos cabeças (20). O Qwen ativa 8 especialistas por token (vs. 4 no GLM-4.7 Flash), oferecendo mais flexibilidade de roteamento ao custo de um cálculo ligeiramente maior por passagem forward.
Ambos os modelos têm eficiência de parâmetros quase idêntica (3B ativos). No entanto, o GLM-4.7 Flash troca um pouco de profundidade de raciocínio por execução de ferramentas mais rápida, enquanto o Qwen3 foca mais em raciocínio multi-etapas mais profundo por meio de sua arquitetura de modo de pensamento.
Experimente o GLM 4.7 Flash Agora!
Comparação de Benchmarks
A lacuna de desempenho entre esses modelos emerge claramente quando agrupados por tipo de tarefa. Organizamos os benchmarks em três categorias: codificação/engenharia, raciocínio/acadêmico e recursos especializados.
Benchmarks de Codificação e Engenharia de Software
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| SWE-bench Verified | 59,2% 🏆 | 22,0% |
| τ²-Bench (Uso de Ferramentas) | 79,5% 🏆 | 49,0% |
| BrowseComp | 42,8% 🏆 | 2,29% |
Fonte: Páginas de modelo do Unsloth / Hugging Face. Dados de março de 2026.
Benchmarks de Raciocínio e Acadêmicos
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| GPQA (Perguntas e Respostas de Ciências) | 75,2%🏆 | 73,4% |
| AIME 2025 (Matemática) | 91,6%🏆 | 85,0% |
Fonte: Páginas de modelo do Unsloth / Hugging Face. Dados de março de 2026.
Recursos Especializados
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| HLE (Avaliação Semelhante a Humana) | 14,4% 🏆 | 9,8% |
Fonte: Páginas de modelo do Unsloth / Hugging Face. Dados de março de 2026.
No geral, o GLM-4.7 Flash é posicionado como um modelo orientado a engenharia e ferramentas, enquanto o Qwen3-30B-A3B-Thinking-2507 é otimizado para raciocínio profundo e tarefas com alta carga cognitiva.
Experimente o GLM 4.7 Flash Agora!
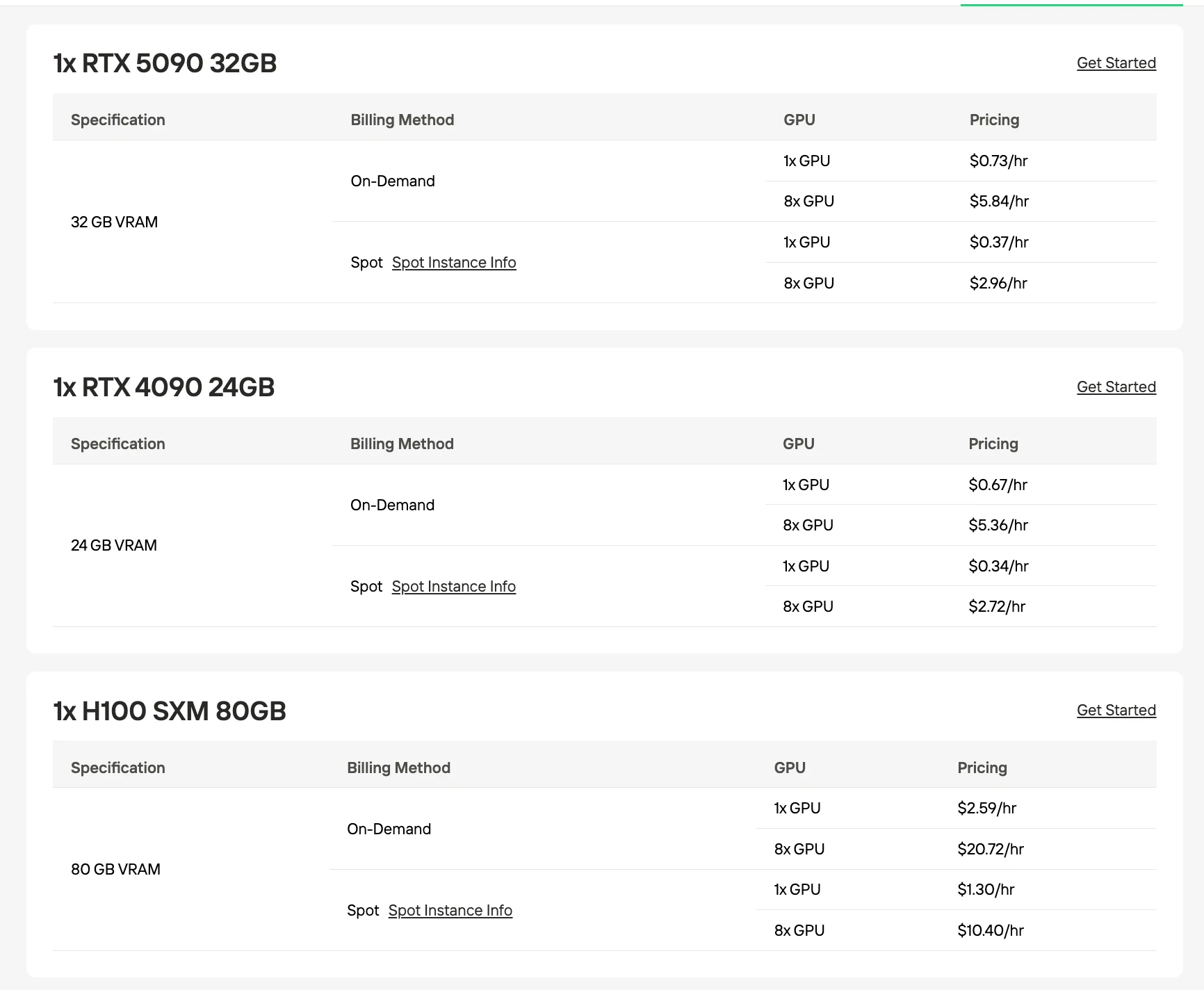
Requisitos de VRAM e GPU
Ambos os modelos exigem VRAM base semelhante devido à sua contagem compartilhada de 30B de parâmetros, mas as estratégias de quantização diferem com base no foco de otimização.
GPU Recomendada para o GLM-4.7 Flash
| Quantização / Formato | Tamanho do Modelo | Requisito de VRAM | Configuração Recomendada |
|---|---|---|---|
| UD-Q4_K_XL (recomendado) | 17,52 GB | 24 GB | Única RTX 4090 |
| Q4_K_M | 18,31 GB | 24 GB | Única RTX 4090 |
| Q5_K_M | 21,41 GB | 24 GB | Única RTX 4090 |
| Q8_0 | 31,84 GB | 40 GB | 2× RTX 4090 ou H100 80GB |
| BF16 (completo) | 60 GB | 80 GB | H100 80GB |
Fonte: Unsloth / Hugging Face. Os valores de VRAM são estimativas baseadas nos tamanhos de modelos quantizados.
GPU Recomendada para o Qwen3-30B-A3B-Thinking-2507
| Formato | Tamanho do Arquivo | VRAM Mínima | Melhor Para |
|---|---|---|---|
| UD-Q4_K_XL (recomendado) | 17,72 GB | 24 GB | Única RTX 4090 |
| Q4_K_M | 18,56 GB | 24 GB | Única RTX 4090 |
| Q5_K_M | 21,73 GB | 24 GB | Única RTX 4090 |
| Q8_0 | 32,48 GB | 40 GB | 2× RTX 4090 ou H100 80GB |
| BF16 (completo) | 61 GB | 80 GB+ | H100 80GB |
Fonte: Unsloth / Hugging Face. Os valores de VRAM são estimativas baseadas nos tamanhos de modelos quantizados.
Experimente GPUs Econômicas Agora!
Como Acessar o GLM-4.7 Flash ou o Qwen3-30B-A3B?
Ambos os modelos suportam acesso a API compatível com a OpenAI, tornando a integração direta para desenvolvedores que já usam o SDK da OpenAI.
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Experimente o GLM 4.7 Flash Agora!
Passo 3: Inicie Seu Teste Gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API para você. Acessando a página de “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
A escolha entre o GLM-4.7 Flash e o Qwen3-30B-A3B-Thinking-2507 se resume a uma especialização clara: o GLM-4.7 Flash vence de forma decisiva para agentes de engenharia de software (59,2% no SWE-bench, 79,5% no τ²-Bench, 42,8% no BrowseComp) com um custo combinado imbatível de $0,47/1M via Novita AI. Para desenvolvedores que criam integrações com o Claude Code, automação de terminal ou agentes baseados em navegador, o GLM-4.7 Flash é a escolha óbvia — sua vantagem de 2,7× no SWE-bench em relação ao Qwen3 (59,2% vs 22,0%) e seus preços extremamente baixos o tornam ideal para fluxos de trabalho de codificação em produção.
Conclusão
Tanto o GLM-4.7 Flash quanto o Qwen3-30B-A3B-Thinking-2507 são modelos MoE de classe 30B robustos com requisitos de VRAM quase idênticos, mas atendem a casos de uso distintos. O GLM-4.7 Flash é a escolha clara para agentes de engenharia de software, automação de navegador e fluxos de trabalho com muitas ferramentas. O Qwen3-30B-A3B-Thinking-2507 se destaca quando você precisa de raciocínio multi-etapas transparente com traços de pensamento explícitos para tarefas de pesquisa e análise.
Conclusão Principal: Se você está construindo um agente de codificação ou pipeline de automação, opte pelo GLM-4.7 Flash. Se você precisa de raciocínio profundo estruturado, escolha o Qwen3-30B-A3B-Thinking-2507. Ambos estão disponíveis na Novita AI — experimente o GLM-4.7 Flash ou explore o catálogo completo de modelos hoje.
Qual é melhor para agentes de codificação: GLM-4.7 Flash ou Qwen3-30B-A3B-Thinking-2507?
O GLM-4.7 Flash domina com 59,2% no SWE-bench Verified (vs 22,0% do Qwen) e 79,5% no uso de ferramentas do τ²-Bench (vs 49,0%).
Qual é mais fácil de implantar localmente?
Ambos exigem ~18GB de VRAM com quantização INT4 em 1× RTX 4090.
Posso executar o GLM-4.7 Flash no Claude Code ou Trae?
Sim, ambas as ferramentas suportam integração de modelos personalizados via API.
Leituras Recomendadas
- Use o GLM-4.5 no Trae para Desbloquear Agentes de Codificação Mais Inteligentes
- Use o MiniMax M2.1 no OpenCode
- DeepSeek vs Qwen: Identifique Qual Ecossistema Atende às Necessidades de Produção
Novita AI é uma plataforma de nuvem de IA e agentes que ajuda desenvolvedores e startups a construir, implantar e escalar modelos e aplicações agentivas com alta performance, confiabilidade e eficiência de custos.



