

يواجه المطورون الذين يختارون بين GLM-4.7 Flash و Qwen3-30B-A3B-Thinking-2507 مفاضلة واضحة: إتقان هندسة البرمجيات مقابل عمق الاستدلال المنطقي. كلا النموذجين من فئة 30B من نماذج MoE مع حوالي 3B معاملات نشطة لكل رمز، ونوافذ سياق طويلة (202K لـ GLM-4.7 Flash، 262K لـ Qwen3)، ومتطلبات متشابهة لذاكرة VRAM. يكمن الاختلاف بينهما في ما تم تحسينهما من أجله: GLM-4.7 Flash لسير عمل البرمجة المعتمدة على الوكلاء (استدعاء الأدوات، تصفح الويب، توليد الأكواد)، و Qwen3-30B-A3B-Thinking-2507 للاستدلال متعدد الخطوات مع وضع “تفكير” مخصص يكشف عن مسارات الاستدلال الداخلية.
أي نموذج يجب أن تختار؟
| اختر GLM-4.7 Flash إذا كنت بحاجة إلى: | اختر Qwen3-30B-A3B-Thinking-2507 إذا كنت بحاجة إلى: |
|---|---|
| • مهام هندسة البرمجيات (59.2% في اختبار SWE-bench المعتمد) • أتمتة المهام المستندة إلى المتصفح (42.8% في BrowseComp مقابل 2.29%) • استدعاء أدوات الوكلاء (79.5% في τ²-Bench مقابل 49.0%) • وكلاء برمجة ذات زمن استجابة منخفض • مهام تتطلب تنقل وتشغيل آلي قوي على الويب • توليد الأكواد وإعادة هيكلتها في الوقت الفعلي |
• منطق متعدد الخطوات مع مسارات استدلال ظاهرة • أبحاث علمية وحل مشاكل أكاديمية • مهام متابعة التعليمات (88.9% في IFEval) • فهم متعدد اللغات وتحليل سياق طويل |
مقارنة البنية المعمارية
كلا النموذجين من فئة 30B من نماذج MoE مع حوالي 3B معاملات نشطة ونوافذ سياق طويلة، ولهما متطلبات متشابهة إلى حد كبير لذاكرة VRAM.
| الجانب | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| إجمالي المعاملات | 30B | 31B |
| المعاملات النشطة (لكل رمز) | 3B (64 خبير، 4 نشطين) | 3.3B (128 خبير، 8 نشطين) |
| طول السياق | 202,752 رمز | 262,144 رمز |
| الطبقات المخفية | 47 | 48 |
| رؤوس الانتباه | 20 (قياسي) | 32 استعلام / 4 مفتاح-قيمة (GQA) |
| الدقة | bfloat16 | bfloat16 |
| دعم متعدد الوسائط | لا (نص فقط) | لا (نص فقط) |
| الميزات الخاصة | أتمتة المتصفح، استدعاء الأدوات | وضع التفكير (مسارات الاستدلال) |
الاختلاف المعماري الرئيسي: يستخدم Qwen3 آلية انتباه الاستعلامات المجمعة (32 رأس استعلام، 4 رؤوس مفتاح/قيمة) لإدارة فعالة لذاكرة التخزين المؤقت KV أثناء الاستدلال طويل السياق، بينما يستخدم GLM-4.7 Flash انتباهًا قياسيًا بعدد أقل من الرؤوس (20). يقوم Qwen بتنشيط 8 خبراء لكل رمز (مقابل 4 في GLM-4.7 Flash)، مما يوفر مرونة توجيه أكبر على حساب تكلفة حسابية أعلى قليلاً لكل عملية تمرير أمامي.
كلا النموذجين لهما كفاءة معاملات متطابقة تقريبًا (3B نشطة). ومع ذلك، يضحي GLM-4.7 Flash ببعض عمق الاستدلال من أجل تنفيذ أسرع للأدوات، بينما يركز Qwen3 بشكل أكبر على استدلال متعدد الخطوات أعمق من خلال بنيته المعمارية لوضع التفكير.
مقارنة معايير الأداء
يظهر الفجوة في الأداء بين هذين النموذجين بوضوح عند تجميعها حسب نوع المهمة. لقد قمنا بتنظيم معايير الأداء في ثلاث فئات: البرمجة/هندسة البرمجيات، الاستدلال/الأكاديمي، والقدرات المتخصصة.
معايير أداء البرمجة وهندسة البرمجيات
| معيار الأداء | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| اختبار SWE-bench المعتمد | 59.2% 🏆 | 22.0% |
| τ²-Bench (استخدام الأدوات) | 79.5% 🏆 | 49.0% |
| BrowseComp | 42.8% 🏆 | 2.29% |
المصدر: صفحات نماذج Unsloth / Hugging Face. البيانات اعتبارًا من مارس 2026.
معايير الاستدلال والأكاديمي
| معيار الأداء | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| GPQA (أسئلة العلوم) | 75.2%🏆 | 73.4% |
| AIME 2025 (الرياضيات) | 91.6%🏆 | 85.0% |
المصدر: صفحات نماذج Unsloth / Hugging Face. البيانات اعتبارًا من مارس 2026.
القدرات المتخصصة
| معيار الأداء | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| HLE (تقييم شبيه بالبشر) | 14.4% 🏆 | 9.8% |
المصدر: صفحات نماذج Unsloth / Hugging Face. البيانات اعتبارًا من مارس 2026.
بشكل عام، يُصنف GLM-4.7 Flash كنموذج موجه لهندسة البرمجيات والأدوات، بينما تم تحسين Qwen3-30B-A3B-Thinking-2507 للاستدلال العميق والمهام التي تتطلب جهدًا معرفيًا كبيرًا.
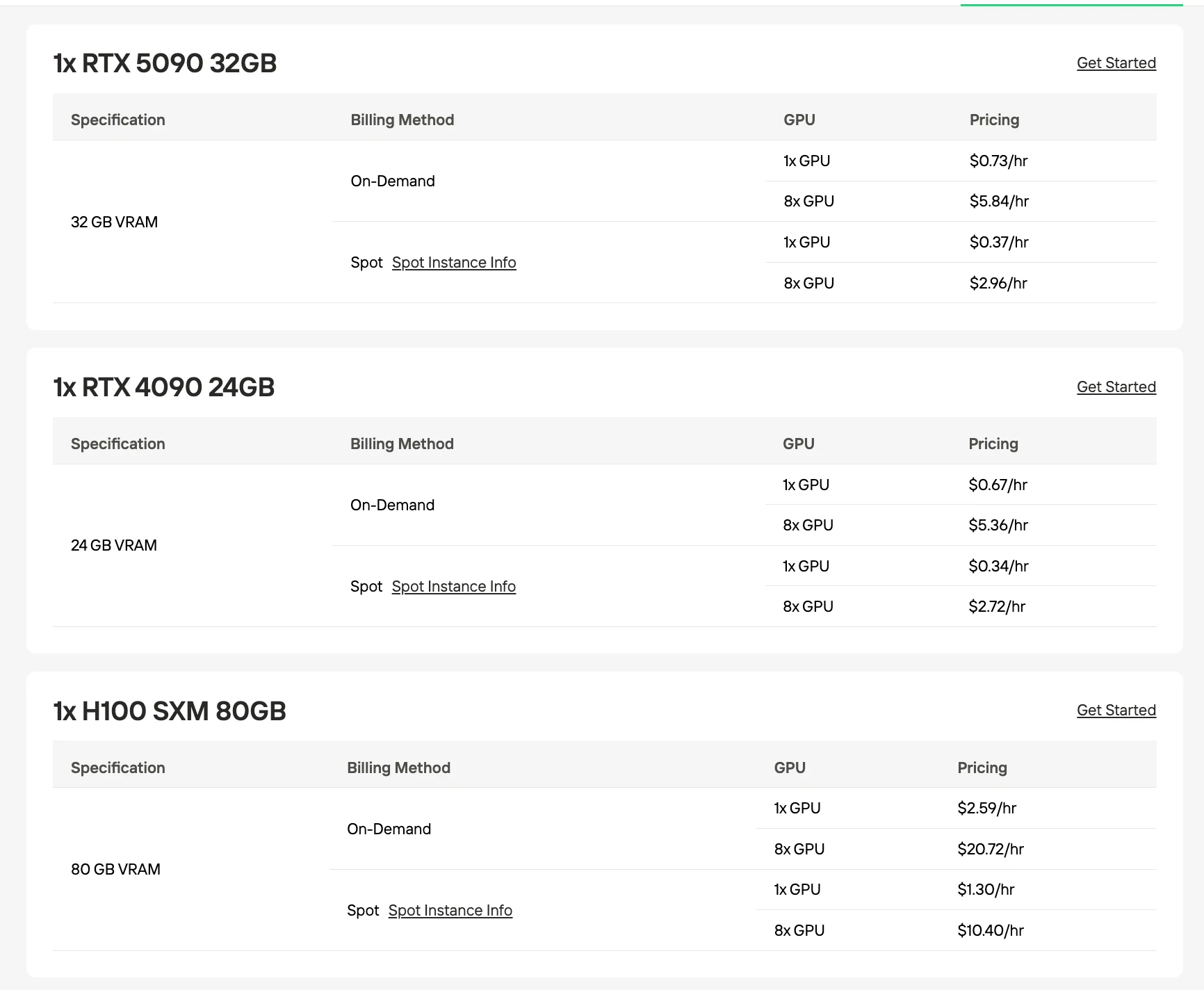
متطلبات ذاكرة VRAM ووحدات معالجة الرسومات (GPU)
يتطلب كلا النموذجين كمية متشابهة من ذاكرة VRAM الأساسية بسبب عدد المعاملات المشترك البالغ 30B، ولكن استراتيجيات التكميم تختلف بناءً على نقطة التحسين.
وحدة معالجة الرسومات الموصى بها لـ GLM-4.7 Flash
| التكميم / التنسيق | حجم النموذج | متطلبات ذاكرة VRAM | الإعداد الموصى به |
|---|---|---|---|
| UD-Q4_K_XL (موصى به) | 17.52 جيجابايت | 24 جيجابايت | وحدة RTX 4090 واحدة |
| Q4_K_M | 18.31 جيجابايت | 24 جيجابايت | وحدة RTX 4090 واحدة |
| Q5_K_M | 21.41 جيجابايت | 24 جيجابايت | وحدة RTX 4090 واحدة |
| Q8_0 | 31.84 جيجابايت | 40 جيجابايت | وحدتان من RTX 4090 أو H100 سعة 80 جيجابايت |
| BF16 (كامل) | 60 جيجابايت | 80 جيجابايت | H100 سعة 80 جيجابايت |
المصدر: Unsloth / Hugging Face. أرقام ذاكرة VRAM هي تقديرات مبنية على أحجام النماذج المكممة.
وحدة معالجة الرسومات الموصى بها لـ Qwen3-30B-A3B-Thinking-2507
| التنسيق | حجم الملف | الحد الأدنى من ذاكرة VRAM | الأفضل لـ |
|---|---|---|---|
| UD-Q4_K_XL (موصى به) | 17.72 جيجابايت | 24 جيجابايت | وحدة RTX 4090 واحدة |
| Q4_K_M | 18.56 جيجابايت | 24 جيجابايت | وحدة RTX 4090 واحدة |
| Q5_K_M | 21.73 جيجابايت | 24 جيجابايت | وحدة RTX 4090 واحدة |
| Q8_0 | 32.48 جيجابايت | 40 جيجابايت | وحدتان من RTX 4090 أو H100 سعة 80 جيجابايت |
| BF16 (كامل) | 61 جيجابايت | 80 جيجابايت أو أكثر | H100 سعة 80 جيجابايت |
المصدر: Unsloth / Hugging Face. أرقام ذاكرة VRAM هي تقديرات مبنية على أحجام النماذج المكممة.
جرب وحدات معالجة الرسومات ذات التكلفة الفعالة الآن!
كيفية الوصول إلى GLM-4.7 Flash أو Qwen3-30B-A3B؟
يدعم كلا النموذجين الوصول عبر واجهة برمجة تطبيقات (API) متوافقة مع OpenAI، مما يجعل التكامل بسيطًا للمطورين الذين يستخدمون بالفعل حزمة تطوير البرامج (SDK) الخاصة بـ OpenAI.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع واجهة برمجة التطبيقات، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “الإعدادات“، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
يأتي الخيار بين GLM-4.7 Flash و Qwen3-30B-A3B-Thinking-2507 إلى تخصص واضح: يفوز GLM-4.7 Flash بشكل حاسم لوكلاء هندسة البرمجيات (59.2% في SWE-bench، 79.5% في τ²-Bench، 42.8% في BrowseComp) بتكلفة ممزوجة لا تُضاهى تبلغ 0.47 دولار لكل 1M عبر Novita AI. بالنسبة للمطورين الذين يبنون تكاملات مع Claude Code، أو أتمتة الأطراف الطرفية، أو وكلاء مستندين إلى المتصفح، فإن GLM-4.7 Flash هو الخيار الواضح — حيث إن ميزته البالغة 2.7 ضعف في اختبار SWE-bench مقارنة بـ Qwen3 (59.2% مقابل 22.0%) وأسعاره المنخفضة جدًا تجعله مثاليًا لسير عمل البرمجة الإنتاجية.
الخلاصة
كلا من GLM-4.7 Flash و Qwen3-30B-A3B-Thinking-2507 هما نموذجان قويان من فئة 30B من نماذج MoE بمتطلبات متشابهة جدًا لذاكرة VRAM، ولكنهما يخدمان حالات استخدام مختلفة. GLM-4.7 Flash هو الخيار الواضح لوكلاء هندسة البرمجيات، وأتمتة المتصفح، وسير العمل التي تعتمد heavily على الأدوات. يتفوق Qwen3-30B-A3B-Thinking-2507 عندما تحتاج إلى استدلال متعدد الخطوات شفاف مع مسارات تفكير صريحة لمهام البحث والتحليل.
النقطة الرئيسية: إذا كنت تبني وكيل برمجة أو خط أنابيب أتمتة، فاختر GLM-4.7 Flash. إذا كنت بحاجة إلى استدلال عميق منظم، فاختر Qwen3-30B-A3B-Thinking-2507. كلا النموذجين متاحان على Novita AI — جرب GLM-4.7 Flash أو استكشف كتالوج النماذج الكامل اليوم.
أي منهما أفضل لوكلاء البرمجة: GLM-4.7 Flash أم Qwen3-30B-A3B-Thinking-2507؟
يهيمن GLM-4.7 Flash بنتيجة 59.2% في اختبار SWE-bench المعتمد (مقابل 22.0% لـ Qwen) و 79.5% في استخدام أدوات τ²-Bench (مقابل 49.0%).
أي منهما أسهل في النشر محليًا؟
كلاهما يتطلب ~18 جيجابايت من ذاكرة VRAM مع تكميم INT4 على وحدة RTX 4090 واحدة.
هل يمكنني تشغيل GLM-4.7 Flash على Claude Code أو Trae؟
نعم، كلا الأداة تدعمان تكامل النماذج المخصصة عبر واجهة برمجة التطبيقات.
قراءات موصى بها
- استخدام GLM-4.5 في Trae لفتح وكلاء برمجة أكثر ذكاءً
- استخدام MiniMax M2.1 في OpenCode
- DeepSeek مقابل Qwen: حدد أي نظام بيئي يناسب احتياجات الإنتاج
Novita AI هي منصة سحابية للذكاء الاصطناعي والوكلاء تساعد المطورين والشركات الناشئة على بناء ونشر وتوسيع نطاق النماذج والتطبيقات المعتمدة على الوكلاء بأداء عالٍ وموثوقية وكفاءة في التكلفة.



