

Entwickler, die sich zwischen GLM-4.7 Flash und Qwen3-30B-A3B-Thinking-2507 entscheiden, stehen vor einer klaren Abwägung: Meisterschaft in der Softwareentwicklung versus Tiefe im logischen Denken. Beide sind MoE-Modelle der 30B-Klasse mit etwa 3B aktiven Parametern pro Token, langen Kontextfenstern (202K für GLM-4.7 Flash, 262K für Qwen3) und ähnlichen VRAM-Anforderungen. Der Unterschied liegt in der Optimierung: GLM-4.7 Flash ist für agentische Programmierworkflows (Tool-Aufrufe, Webbrowsing, Codegenerierung) ausgelegt, Qwen3-30B-A3B-Thinking-2507 für mehrstufige logische Denkaufgaben mit einem dedizierten „Denkmodus“, der interne Denkspuren offenlegt.
Welches Modell solltest du wählen?
| Wähle GLM-4.7 Flash, wenn du Folgendes benötigst: | Wähle Qwen3-30B-A3B-Thinking-2507, wenn du Folgendes benötigst: |
|---|---|
| • Softwareentwicklungsaufgaben (59,2 % SWE-bench Verified) • Browserbasierte Aufgabenautomatisierung (42,8 % BrowseComp vs 2,29 %) • Agentische Tool-Aufrufe (79,5 % τ²-Bench vs 49,0 %) • Codierungsagenten mit niedriger Latenz • Aufgaben, die starke Webnavigation und Automatisierung erfordern • Echtzeit-Codegenerierung und Refactoring |
• Mehrstufige Logik mit offengelegten Denkspuren • Wissenschaftliche Forschung und akademische Problemlösung • Aufgaben zur Befolgung von Anweisungen (88,9 % IFEval) • Mehrsprachiges Verständnis und Langkontext-Analyse |
Architekturvergleich
Beide sind MoE-Modelle der 30B-Klasse mit etwa 3B aktiven Parametern, langen Kontextfenstern und weitgehend ähnlichen VRAM-Anforderungen.
| Aspekt | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| Gesamtparameter | 30B | 31B |
| Aktive Parameter (pro Token) | 3B (64 Experten, 4 aktiv) | 3,3B (128 Experten, 8 aktiv) |
| Kontextlänge | 202.752 Token | 262.144 Token |
| Versteckte Schichten | 47 | 48 |
| Aufmerksamkeitsköpfe | 20 (standard) | 32 Q / 4 KV (GQA) |
| Präzision | bfloat16 | bfloat16 |
| Multimodale Unterstützung | Nein (nur Text) | Nein (nur Text) |
| Besondere Funktionen | Browserautomatisierung, Tool-Aufrufe | Denkmodus (Denkspuren) |
Wichtiger architektonischer Unterschied: Qwen3 verwendet Grouped Query Attention (32 Q-Köpfe, 4 KV-Köpfe) für ein effizientes KV-Cache-Management während der Langkontext-Inferenz, während GLM-4.7 Flash Standard-Aufmerksamkeit mit weniger Köpfen (20) verwendet. Qwen aktiviert 8 Experten pro Token (im Vergleich zu 4 bei GLM-4.7 Flash), was mehr Routing-Flexibilität bietet, aber einen etwas höheren Rechenaufwand pro Vorwärtsdurchlauf kostet.
Beide Modelle haben eine nahezu identische Parameter-Effizienz (3B aktiv). GLM-4.7 Flash tauscht jedoch etwas Tiefe im logischen Denken gegen schnellere Tool-Ausführung ein, während Qwen3 sich durch seine Denkmodus-Architektur stärker auf tiefere mehrstufige logische Denkaufgaben konzentriert.
Benchmark-Vergleich
Der Leistungsunterschied zwischen diesen Modellen wird deutlich, wenn man sie nach Aufgabenart gruppiert. Wir haben die Benchmarks in drei Kategorien eingeteilt: Programmierung/Softwareentwicklung, logisches Denken/Akademisches und spezielle Fähigkeiten.
Benchmarks für Programmierung und Softwareentwicklung
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| SWE-bench Verified | 59,2 % 🏆 | 22,0 % |
| τ²-Bench (Tool-Nutzung) | 79,5 % 🏆 | 49,0 % |
| BrowseComp | 42,8 % 🏆 | 2,29 % |
Quelle: Unsloth / Hugging Face Modellseiten. Datenstand: März 2026.
Benchmarks für logisches Denken und akademische Aufgaben
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| GPQA (Wissenschaftliche Q&A) | 75,2 % 🏆 | 73,4 % |
| AIME 2025 (Mathematik) | 91,6 % 🏆 | 85,0 % |
Quelle: Unsloth / Hugging Face Modellseiten. Datenstand: März 2026.
Spezielle Fähigkeiten
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| HLE (Human-Like Eval) | 14,4 % 🏆 | 9,8 % |
Quelle: Unsloth / Hugging Face Modellseiten. Datenstand: März 2026.
Insgesamt ist GLM-4.7 Flash als ingenieur- und tool-orientiertes Modell positioniert, während Qwen3-30B-A3B-Thinking-2507 für tiefe logische Denkaufgaben und kognitiv anspruchsvolle Aufgaben optimiert ist.
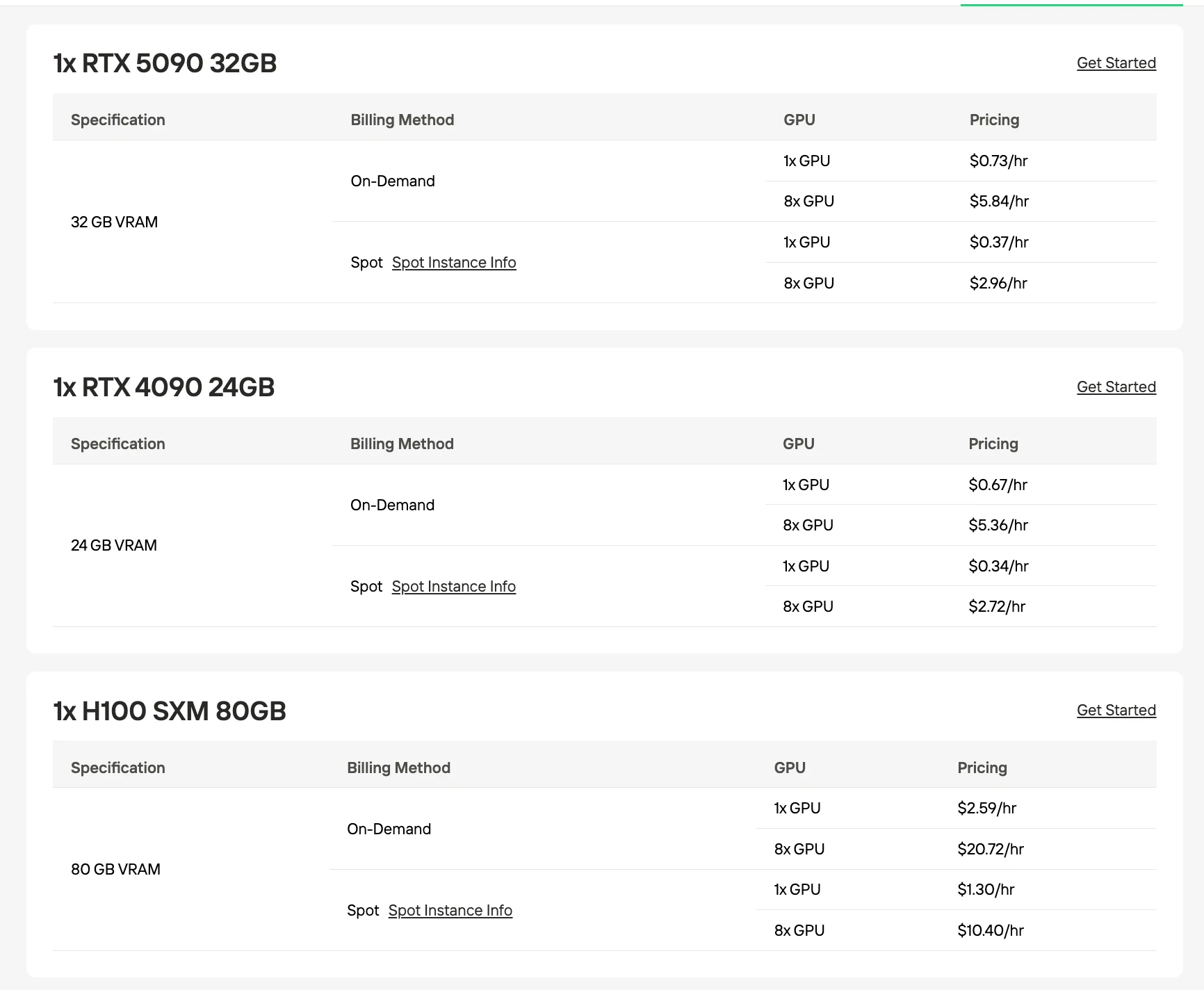
VRAM- und GPU-Anforderungen
Beide Modelle erfordern aufgrund ihrer gemeinsamen 30B-Parameteranzahl ähnliche Basis-VRAM, aber die Quantisierungsstrategien unterscheiden sich je nach Optimierungsschwerpunkt.
Empfohlene GPU für GLM-4.7 Flash
| Quantisierung / Format | Modellgröße | VRAM-Anforderung | Empfohlene Konfiguration |
|---|---|---|---|
| UD-Q4_K_XL (empfohlen) | 17,52 GB | 24 GB | Einzelne RTX 4090 |
| Q4_K_M | 18,31 GB | 24 GB | Einzelne RTX 4090 |
| Q5_K_M | 21,41 GB | 24 GB | Einzelne RTX 4090 |
| Q8_0 | 31,84 GB | 40 GB | 2× RTX 4090 oder H100 80GB |
| BF16 (voll) | 60 GB | 80 GB | H100 80GB |
Quelle: Unsloth / Hugging Face. Die VRAM-Werte sind Schätzungen basierend auf den Größen quantisierter Modelle.
Empfohlene GPU für Qwen3-30B-A3B-Thinking-2507
| Format | Dateigröße | Mindestens erforderlicher VRAM | Am besten geeignet für |
|---|---|---|---|
| UD-Q4_K_XL (empfohlen) | 17,72 GB | 24 GB | Einzelne RTX 4090 |
| Q4_K_M | 18,56 GB | 24 GB | Einzelne RTX 4090 |
| Q5_K_M | 21,73 GB | 24 GB | Einzelne RTX 4090 |
| Q8_0 | 32,48 GB | 40 GB | 2× RTX 4090 oder H100 80GB |
| BF16 (voll) | 61 GB | 80 GB+ | H100 80GB |
Quelle: Unsloth / Hugging Face. Die VRAM-Werte sind Schätzungen basierend auf den Größen quantisierter Modelle.
Teste jetzt kostengünstige GPUs!
Wie greifst du auf GLM-4.7 Flash oder Qwen3-30B-A3B zu?
Beide Modelle unterstützen OpenAI-kompatiblen API-Zugriff, was die Integration für Entwickler, die bereits das OpenAI SDK verwenden, unkompliziert macht.
Schritt 1: Einloggen und Zugriff auf die Modellbibliothek
Logge dich in deinem Konto ein und klicke auf die Schaltfläche Modellbibliothek.

Schritt 2: Wähle dein Modell
Durchstöbere die verfügbaren Optionen und wähle das Modell, das deinen Anforderungen entspricht.

Schritt 3: Starte deine kostenlose Testversion
Starte deine kostenlose Testversion, um die Funktionen des ausgewählten Modells kennenzulernen.
Schritt 4: Hole deinen API-Schlüssel
Zur Authentifizierung bei der API stellen wir dir einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ kannst du den API-Schlüssel wie in der Abbildung gezeigt kopieren.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
Die Wahl zwischen GLM-4.7 Flash und Qwen3-30B-A3B-Thinking-2507 hängt von einer klaren Spezialisierung ab: GLM-4.7 Flash gewinnt deutlich für Softwareentwicklungsagenten (59,2 % SWE-bench, 79,5 % τ²-Bench, 42,8 % BrowseComp) zu einem unschlagbaren kombinierten Preis von 0,47 $/1M über Novita AI. Für Entwickler, die Claude Code-Integrationen, Terminalautomatisierung oder browserbasierte Agenten erstellen, ist GLM-4.7 Flash die offensichtliche Wahl – sein 2,7-facher SWE-bench-Vorteil gegenüber Qwen3 (59,2 % vs. 22,0 %) und die extrem niedrigen Preise machen es ideal für produktive Programmierworkflows.
Fazit
Sowohl GLM-4.7 Flash als auch Qwen3-30B-A3B-Thinking-2507 sind leistungsstarke MoE-Modelle der 30B-Klasse mit nahezu identischen VRAM-Anforderungen, aber sie dienen unterschiedlichen Anwendungsfällen. GLM-4.7 Flash ist die klare Wahl für Softwareentwicklungsagenten, Browserautomatisierung und tool-intensive Workflows. Qwen3-30B-A3B-Thinking-2507 glänzt, wenn du transparente mehrstufige logische Denkaufgaben mit expliziten Denkspuren für Forschungs- und Analyseaufgaben benötigst.
Hauptvorteil: Wenn du einen Programmieragenten oder eine Automatisierungspipeline erstellst, wähle GLM-4.7 Flash. Wenn du strukturiertes tiefes logisches Denken benötigst, wähle Qwen3-30B-A3B-Thinking-2507. Beide sind auf Novita AI verfügbar — teste GLM-4.7 Flash oder erkunde noch heute den gesamten Modellkatalog.
Welches Modell ist besser für Programmieragenten: GLM-4.7 Flash oder Qwen3-30B-A3B-Thinking-2507?
GLM-4.7 Flash dominiert mit 59,2 % bei SWE-bench Verified (gegenüber 22,0 % bei Qwen) und 79,5 % bei der Tool-Nutzung im τ²-Bench (gegenüber 49,0 %).
Welches Modell ist einfacher lokal bereitzustellen?
Beide benötigen ~18 GB VRAM bei INT4-Quantisierung auf 1× RTX 4090.
Kann ich GLM-4.7 Flash in Claude Code oder Trae ausführen?
Ja, beide Tools unterstützen die Integration benutzerdefinierter Modelle über die API.
Empfohlene Lektüre
- Nutze GLM-4.5 in Trae, um intelligentere Programmieragenten freizuschalten
- Nutze MiniMax M2.1 in OpenCode
- DeepSeek vs Qwen: Finde heraus, welches Ökosystem für Produktionsanforderungen geeignet ist
Novita AI ist eine KI- & Agenten-Cloud-Plattform, die Entwicklern und Startups hilft, Modelle und agentische Anwendungen mit hoher Leistung, Zuverlässigkeit und Kosteneffizienz zu erstellen, bereitzustellen und zu skalieren.



