

開發者在 GLM-4.7 Flash 與 Qwen3-30B-A3B-Thinking-2507 之間選擇時,會面臨明確的取捨:軟體工程專業度與推理深度的差異。兩款都是 30B 級別的混合專家(MoE)模型,每個 token 僅有約 3B 活躍參數,支援長上下文視窗(GLM-4.7 Flash 為 202K,Qwen3 為 262K),且顯存需求相近。兩者的優化方向截然不同:GLM-4.7 Flash 針對代理式編碼工作流程(工具呼叫、網頁瀏覽、程式碼生成)優化,Qwen3-30B-A3B-Thinking-2507 則針對多步驟推理優化,搭載專屬的「思考模式」,可暴露內部推理軌跡。
你應該選擇哪款模型?
| 選擇 GLM-4.7 Flash 如果你需要: | 選擇 Qwen3-30B-A3B-Thinking-2507 如果你需要: |
|---|---|
| • 軟體工程任務(SWE-bench Verified 達 59.2%) • 基於瀏覽器的任務自動化(BrowseComp 達 42.8%,對比 Qwen 的 2.29%) • 代理式工具呼叫(τ²-Bench 達 79.5%,對比 49.0%) • 低延遲的編碼代理 • 需要強大網頁導航與自動化的任務 • 即時程式碼生成與重構 |
• 帶有可視化推理軌跡的多步驟邏輯推理 • 科學研究與學術問題解決 • 指令遵循任務(IFEval 達 88.9%) • 多語言理解與長上下文分析 |
架構對比
兩款都是 30B 級別的混合專家(MoE)模型,每個 token 僅有約 3B 活躍參數,支援長上下文視窗,且顯存需求大體相近。
| 項目 | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| 總參數量 | 30B | 31B |
| 活躍參數量(每 token) | 3B(64 個專家,4 個活躍) | 3.3B(128 個專家,8 個活躍) |
| 上下文長度 | 202,752 tokens | 262,144 tokens |
| 隱藏層數量 | 47 | 48 |
| 注意力頭數量 | 20(標準) | 32 Q / 4 KV(分組查詢注意力,GQA) |
| 精度 | bfloat16 | bfloat16 |
| 多模態支援 | 無(僅文字) | 無(僅文字) |
| 特殊功能 | 瀏覽器自動化、工具呼叫 | 思考模式(推理軌跡) |
關鍵架構差異: Qwen3 採用分組查詢注意力(32 個 Q 頭、4 個 KV 頭),在長上下文推理時能更高效地管理 KV 快取;而 GLM-4.7 Flash 使用標準注意力機制,頭數量較少(20 個)。Qwen 每個 token 會啟動 8 個專家(GLM-4.7 Flash 為 4 個),雖然每次前向傳播的計算量略高,但提供了更靈活的路由選擇。
兩款模型的參數效率幾乎一致(活躍參數均為 3B)。不過 GLM-4.7 Flash 為了更快的工具執行速度,犧牲了部分推理深度;而 Qwen3 則透過思考模式架構,專注於實現更深層的多步驟推理。
基準測試對比
按任務類型分組時,兩款模型的效能差距會非常明顯。我們將基準測試分為三大類:編碼/軟體工程、推理/學術,以及專項能力。
編碼與軟體工程基準測試
| 基準測試 | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| SWE-bench Verified | 59.2% 🏆 | 22.0% |
| τ²-Bench(工具使用) | 79.5% 🏆 | 49.0% |
| BrowseComp | 42.8% 🏆 | 2.29% |
資料來源:Unsloth / Hugging Face 模型頁面,數據統計至 2026 年 3 月。
推理與學術基準測試
| 基準測試 | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| GPQA(科學問答) | 75.2%🏆 | 73.4% |
| AIME 2025(數學) | 91.6%🏆 | 85.0% |
資料來源:Unsloth / Hugging Face 模型頁面,數據統計至 2026 年 3 月。
專項能力
| 基準測試 | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| HLE(類人評估) | 14.4% 🏆 | 9.8% |
資料來源:Unsloth / Hugging Face 模型頁面,數據統計至 2026 年 3 月。
總體而言,GLM-4.7 Flash 定位為工程與工具導向的模型,而 Qwen3-30B-A3B-Thinking-2507 則針對深度推理與高認知負荷的任務優化。
顯存與 GPU 需求
由於兩款模型的總參數量均為 30B,基礎顯存需求相近,但根據優化方向的不同,量化策略也有所差異。
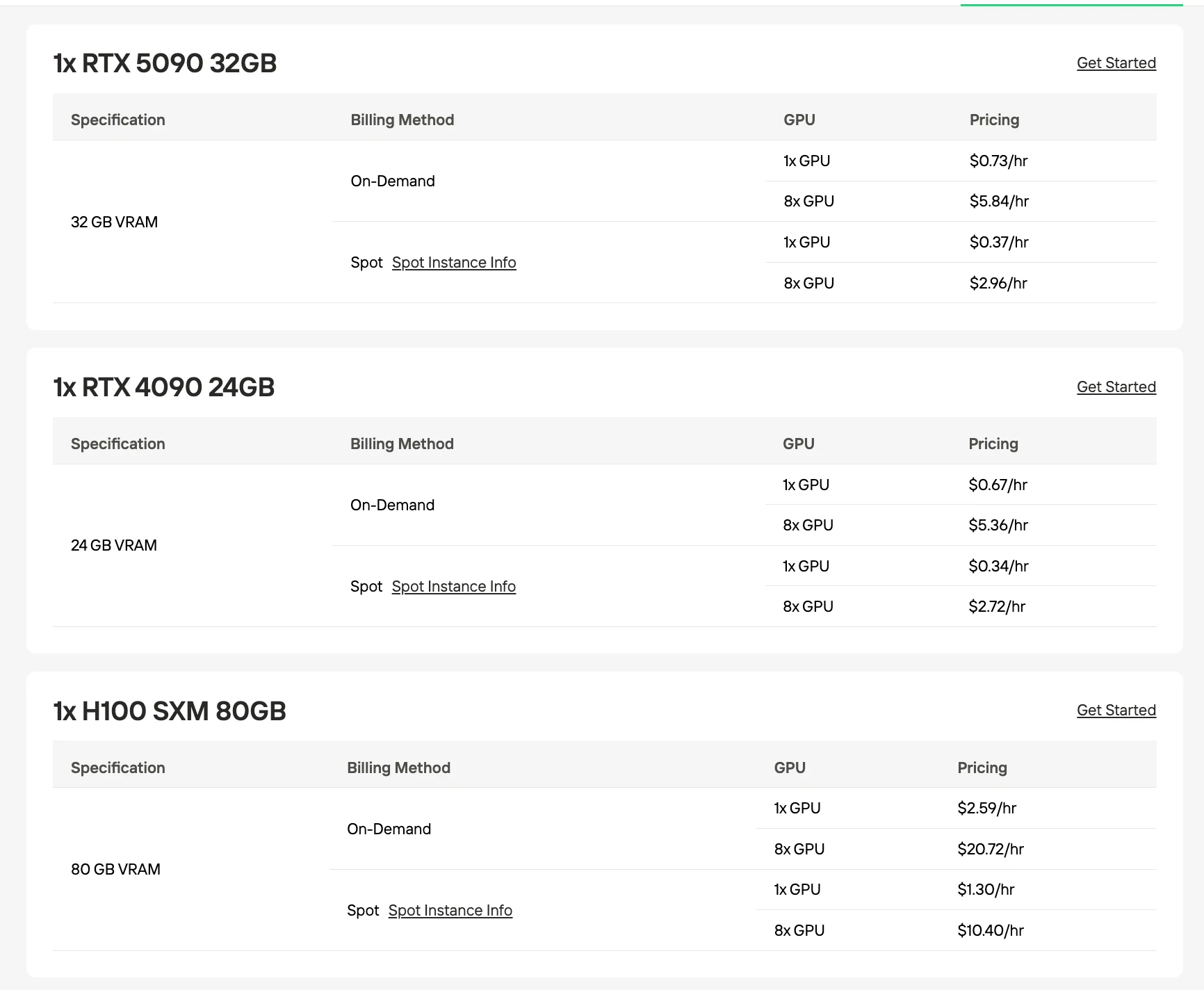
GLM-4.7 Flash 推薦 GPU
| 量化/格式 | 模型大小 | 顯存需求 | 推薦配置 |
|---|---|---|---|
| UD-Q4_K_XL(推薦) | 17.52 GB | 24 GB | 單張 RTX 4090 |
| Q4_K_M | 18.31 GB | 24 GB | 單張 RTX 4090 |
| Q5_K_M | 21.41 GB | 24 GB | 單張 RTX 4090 |
| Q8_0 | 31.84 GB | 40 GB | 2 張 RTX 4090 或 H100 80GB |
| BF16(全精度) | 60 GB | 80 GB | H100 80GB |
資料來源:Unsloth / Hugging Face。顯存數據為基於量化模型大小的估算值。
Qwen3-30B-A3B-Thinking-2507 推薦 GPU
| 格式 | 檔案大小 | 最低顯存 | 適用場景 |
|---|---|---|---|
| UD-Q4_K_XL(推薦) | 17.72 GB | 24 GB | 單張 RTX 4090 |
| Q4_K_M | 18.56 GB | 24 GB | 單張 RTX 4090 |
| Q5_K_M | 21.73 GB | 24 GB | 單張 RTX 4090 |
| Q8_0 | 32.48 GB | 40 GB | 2 張 RTX 4090 或 H100 80GB |
| BF16(全精度) | 61 GB | 80 GB+ | H100 80GB |
資料來源:Unsloth / Hugging Face。顯存數據為基於量化模型大小的估算值。
如何存取 GLM-4.7 Flash 或 Qwen3-30B-A3B?
兩款模型都支援相容 OpenAI 的 API 存取,對於已經使用 OpenAI SDK 的開發者來說,整合非常簡單。
步驟 1:登入並進入模型庫
登入你的帳號,點擊 模型庫 按鈕。

步驟 2:選擇模型
瀏覽可用的選項,選擇符合你需求的模型。

步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
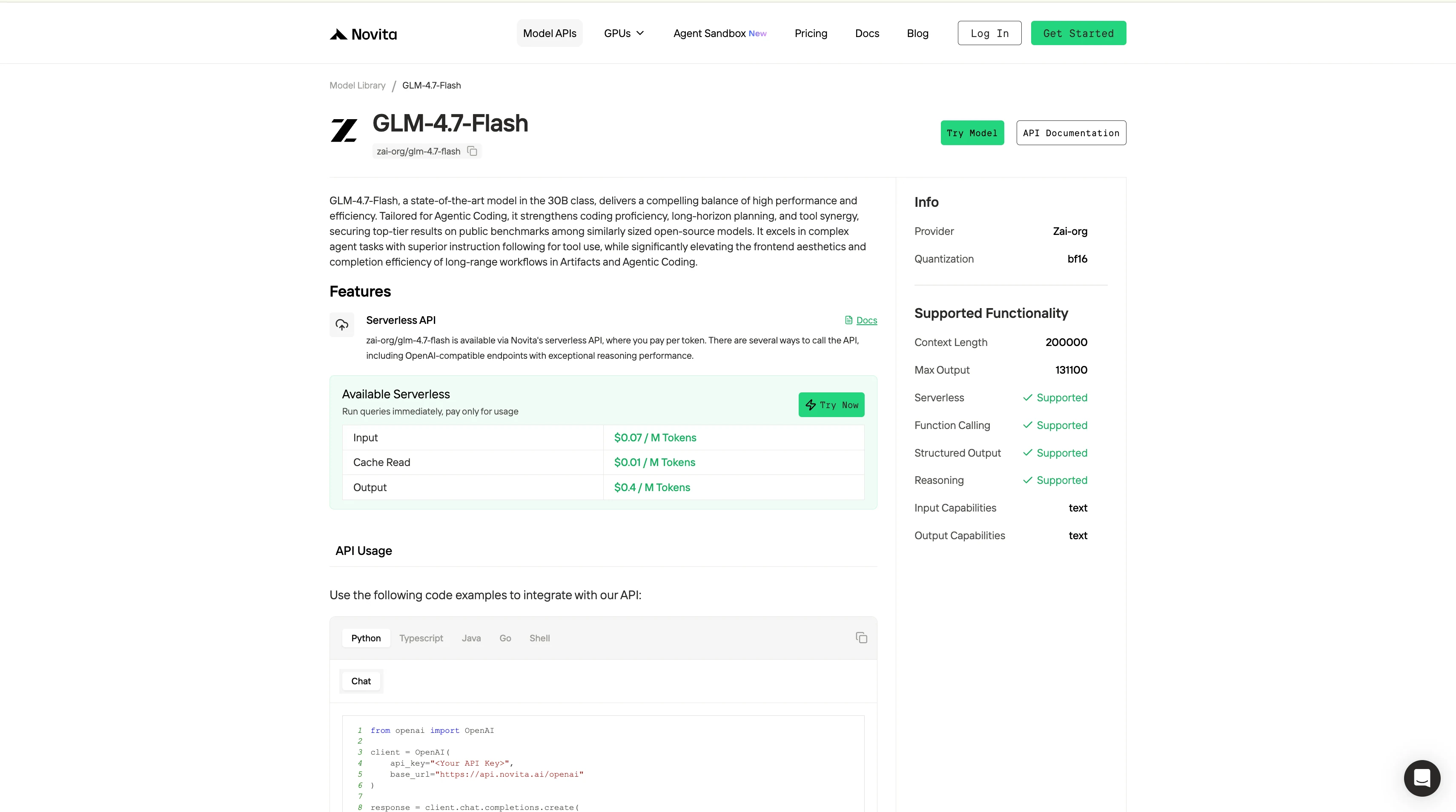
步驟 4:取得 API 金鑰
要進行 API 驗證,我們會為你提供新的 API 金鑰。進入「設定」頁面,即可按照圖片指示複製 API 金鑰。

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
GLM-4.7 Flash 與 Qwen3-30B-A3B-Thinking-2507 的選擇取決於明確的專業方向:GLM-4.7 Flash 在軟體工程代理任務上(SWE-bench 59.2%、τ²-Bench 79.5%、BrowseComp 42.8%)表現壓倒性領先,在 Novita AI 上的混合定價更是低至每百萬 token 0.47 美元,性價比無敵。對於要開發 Claude Code 整合、終端自動化或瀏覽器代理的開發者來說,GLM-4.7 Flash 是顯而易見的選擇——它對 Qwen3 有 2.7 倍的 SWE-bench 優勢(59.2% 對比 22.0%),加上極低的定價,非常適合生產環境的編碼工作流程。
結論
GLM-4.7 Flash 與 Qwen3-30B-A3B-Thinking-2507 都是強勁的 30B 級別混合專家模型,顯存需求幾乎一致,但適用的場景截然不同。GLM-4.7 Flash 是軟體工程代理、瀏覽器自動化、工具密集型工作流程的首選;Qwen3-30B-A3B-Thinking-2507 則在需要可視化多步驟推理、帶有明確思考軌跡的研究與分析任務上表現更優。
關鍵結論: 如果你要開發編碼代理或自動化流程,選擇 GLM-4.7 Flash;如果需要結構化的深度推理,選擇 Qwen3-30B-A3B-Thinking-2507。兩款模型都可以在 Novita AI 上使用——立即試用 GLM-4.7 Flash 或立即探索完整模型目錄。
哪款模型更適合編碼代理:GLM-4.7 Flash 還是 Qwen3-30B-A3B-Thinking-2507?
GLM-4.7 Flash 在 SWE-bench Verified 上取得 59.2% 的領先成績(對比 Qwen 的 22.0%),工具使用測試 τ²-Bench 也達到 79.5%(對比 49.0%),表現壓倒性領先。
哪款模型更適合本地部署?
兩款模型在 INT4 量化後,僅需約 18GB 顯存,即可在單張 RTX 4090 上運行。
我可以在 Claude Code 或 Trae 中運行 GLM-4.7 Flash 嗎?
可以,這兩款工具都支援透過 API 整合自訂模型。
推薦閱讀
Novita AI 是 AI 與代理雲端平台,協助開發者與新創公司高效能、高可靠、低成本地建構、部署與擴展模型與代理式應用程式。



