

GLM-4.7 FlashとQwen3-30B-A3B-Thinking-2507のどちらを選ぶかは、明確なトレードオフを伴います。ソフトウェアエンジニアリングの熟練度と推論の深さのどちらを優先するかです。両モデルとも30BクラスのMoEモデルで、トークンあたり約3Bのアクティブパラメータ、長いコンテキストウィンドウ(GLM-4.7 Flashは202K、Qwen3は262K)、そして同程度のVRAM要件を備えています。違いは最適化の対象にあります。GLM-4.7 Flashはエージェント型コーディングワークフロー(ツール呼び出し、Webブラウジング、コード生成)向け、Qwen3-30B-A3B-Thinking-2507は専用の「思考モード」により内部の推論過程を可視化しながら多段階推論を行うことに特化しています。
どちらのモデルを選ぶべきですか?
| 以下の場合、GLM-4.7 Flashを選ぶ: | 以下の場合、Qwen3-30B-A3B-Thinking-2507を選ぶ: |
|---|---|
| • ソフトウェアエンジニアリングタスク(SWE-bench Verified 59.2%) • ブラウザベースのタスク自動化(BrowseComp 42.8% vs 2.29%) • エージェント型ツール呼び出し(τ²-Bench 79.5% vs 49.0%) • 低遅延のコーディングエージェント • 強力なWebナビゲーションと自動化を必要とするタスク • リアルタイムのコード生成とリファクタリング |
• 推論過程を可視化した多段階ロジック • 科学研究と学術的問題解決 • 指示追従タスク(IFEval 88.9%) • 多言語理解と長文脈分析 |
アーキテクチャ比較
どちらも30BクラスのMoEモデルで、約3Bのアクティブパラメータと長いコンテキストウィンドウを持ち、VRAM要件もほぼ同じです。
| 項目 | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| 総パラメータ数 | 30B | 31B |
| アクティブパラメータ数(トークンあたり) | 3B(64エキスパート、4アクティブ) | 3.3B(128エキスパート、8アクティブ) |
| コンテキスト長 | 202,752 トークン | 262,144 トークン |
| 隠れ層 | 47 | 48 |
| アテンションヘッド | 20(標準) | 32 Q / 4 KV(GQA) |
| 精度 | bfloat16 | bfloat16 |
| マルチモーダル対応 | なし(テキストのみ) | なし(テキストのみ) |
| 特別な機能 | ブラウザ自動化、ツール呼び出し | 思考モード(推論トレース) |
主なアーキテクチャの違い: Qwen3はGrouped Query Attention(Qヘッド32、KVヘッド4)を採用し、長文脈推論時のKVキャッシュ管理を効率化しています。一方、GLM-4.7 Flashは標準アテンション(20ヘッド)を採用。Qwenはトークンあたり8エキスパートを活性化(GLM-4.7 Flashは4エキスパート)し、より柔軟なルーティングを実現する代わりに、フォワードパスあたりの計算量が若干増加します。
両モデルのパラメータ効率はほぼ同じ(アクティブ3B)ですが、GLM-4.7 Flashは推論の深さを犠牲にしてツール実行の高速化を図り、Qwen3は思考モードのアーキテクチャを通じてより深い多段階推論に重点を置いています。
ベンチマーク比較
これらのモデルの性能差は、タスクタイプ別にグループ化すると明確に現れます。ベンチマークをコーディング/エンジニアリング、推論/学術、専門能力の3つのカテゴリに分類しました。
コーディング&ソフトウェアエンジニアリングベンチマーク
| ベンチマーク | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| SWE-bench Verified | 59.2% 🏆 | 22.0% |
| τ²-Bench (Tool Use) | 79.5% 🏆 | 49.0% |
| BrowseComp | 42.8% 🏆 | 2.29% |
出典: Unsloth / Hugging Faceモデルページ。2026年3月時点のデータ。
推論&学術ベンチマーク
| ベンチマーク | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| GPQA (Science QA) | 75.2%🏆 | 73.4% |
| AIME 2025 (Math) | 91.6%🏆 | 85.0% |
出典: Unsloth / Hugging Faceモデルページ。2026年3月時点のデータ。
専門能力
| ベンチマーク | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| HLE (Human-Like Eval) | 14.4% 🏆 | 9.8% |
出典: Unsloth / Hugging Faceモデルページ。2026年3月時点のデータ。
全体的に、GLM-4.7 Flashはエンジニアリングおよびツール志向のモデルとして位置づけられ、Qwen3-30B-A3B-Thinking-2507は深い推論と認知負荷の高いタスク向けに最適化されています。
VRAMとGPU要件
両モデルは共通の30Bパラメータ数により同程度の基本VRAMを必要としますが、量子化戦略は最適化の焦点に応じて異なります。
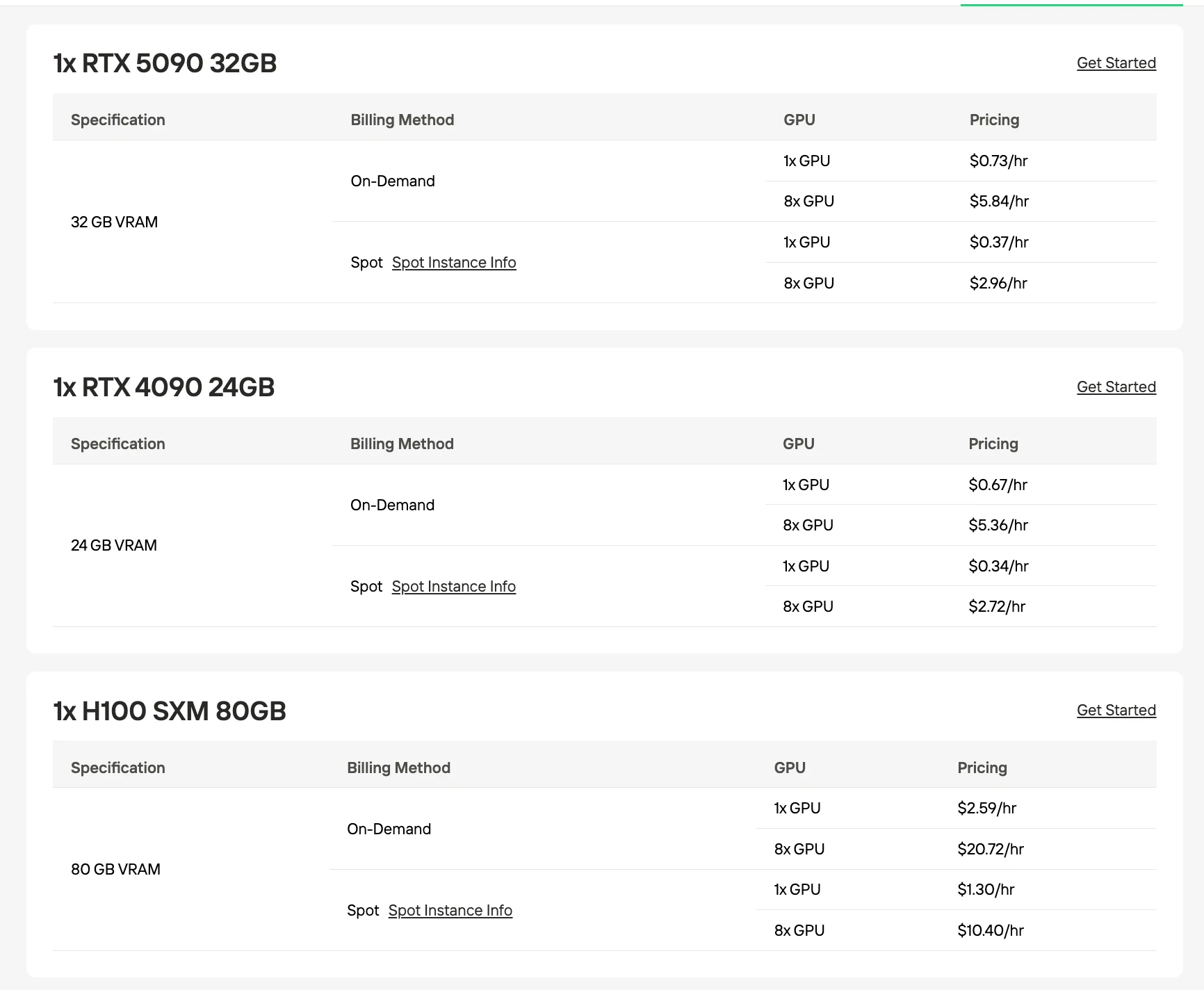
GLM-4.7 FlashにおすすめのGPU
| 量子化/フォーマット | モデルサイズ | VRAM要件 | 推奨セットアップ |
|---|---|---|---|
| UD-Q4_K_XL(推奨) | 17.52 GB | 24 GB | 単一 RTX 4090 |
| Q4_K_M | 18.31 GB | 24 GB | 単一 RTX 4090 |
| Q5_K_M | 21.41 GB | 24 GB | 単一 RTX 4090 |
| Q8_0 | 31.84 GB | 40 GB | 2× RTX 4090 または H100 80GB |
| BF16(フル) | 60 GB | 80 GB | H100 80GB |
出典: Unsloth / Hugging Face。VRAM数値は量子化モデルサイズに基づく推定値です。
Qwen3-30B-A3B-Thinking-2507におすすめのGPU
| フォーマット | ファイルサイズ | 最小VRAM | 最適用途 |
|---|---|---|---|
| UD-Q4_K_XL(推奨) | 17.72 GB | 24 GB | 単一 RTX 4090 |
| Q4_K_M | 18.56 GB | 24 GB | 単一 RTX 4090 |
| Q5_K_M | 21.73 GB | 24 GB | 単一 RTX 4090 |
| Q8_0 | 32.48 GB | 40 GB | 2× RTX 4090 または H100 80GB |
| BF16(フル) | 61 GB | 80 GB+ | H100 80GB |
出典: Unsloth / Hugging Face。VRAM数値は量子化モデルサイズに基づく推定値です。
GLM-4.7 FlashまたはQwen3-30B-A3Bにアクセスする方法?
両モデルはOpenAI互換のAPIアクセスをサポートしており、OpenAI SDKを既に使用している開発者は容易に統合できます。
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、Model Library ボタンをクリックします。

ステップ 2: モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。

ステップ 3: 無料トライアルを開始
選択したモデルの機能を探索するために無料トライアルを開始します。
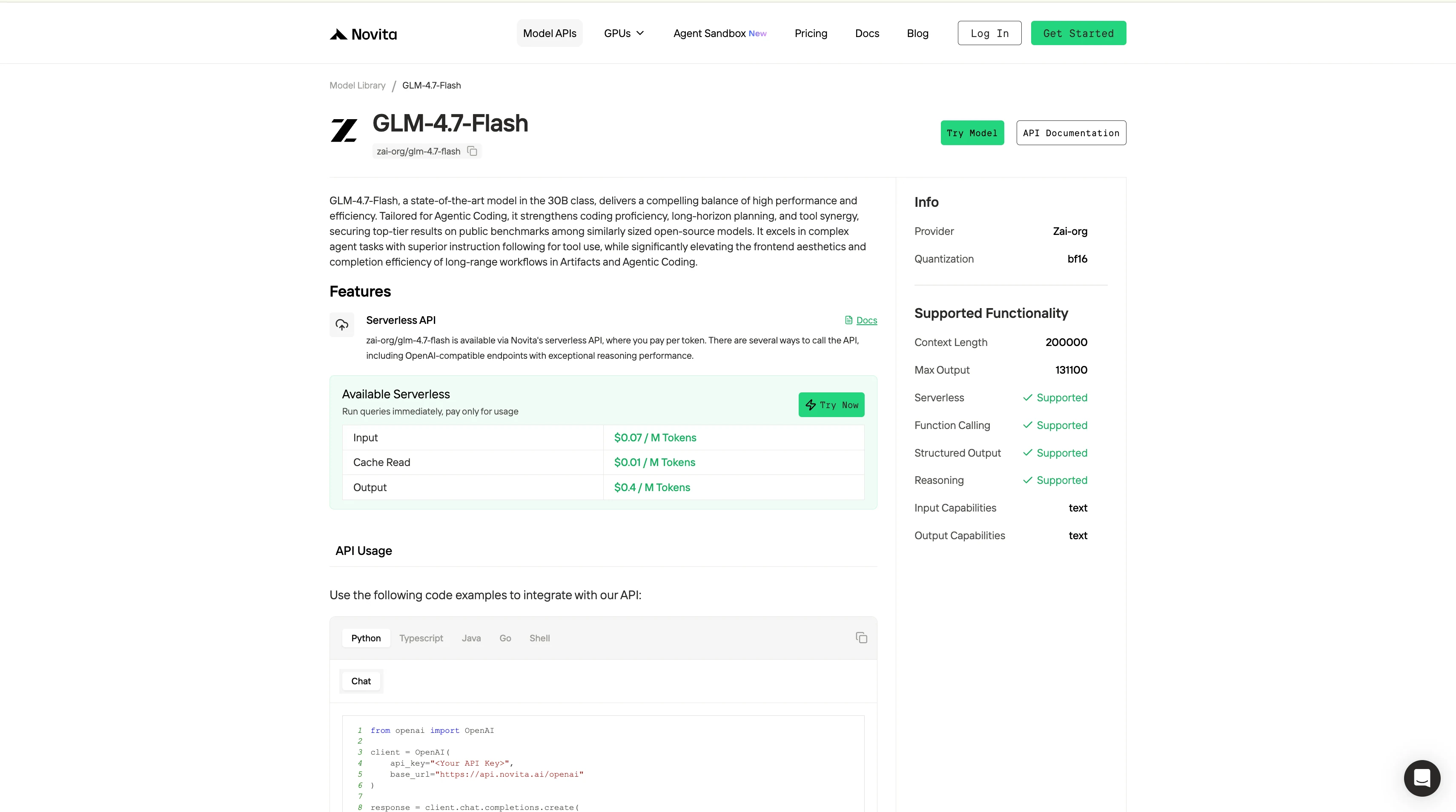
ステップ 4: APIキーを取得
APIで認証するために、新しいAPIキーを発行します。「Settings」ページにアクセスし、画像に示されているようにAPIキーをコピーできます。

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
GLM-4.7 FlashとQwen3-30B-A3B-Thinking-2507の選択は、明確な専門性に帰着します。GLM-4.7 Flashはソフトウェアエンジニアリングエージェントにおいて決定的に優れており(SWE-bench 59.2%、τ²-Bench 79.5%、BrowseComp 42.8%)、Novita AIを通じて破格の$0.47/100万トークン(混合)というコストを実現しています。Claude Codeの統合、ターミナル自動化、ブラウザベースエージェントを構築する開発者にとって、GLM-4.7 Flashは明白な選択です。Qwen3に対する2.7倍のSWE-benchアドバンテージ(59.2% vs 22.0%)と非常に低い価格設定により、本番コーディングワークフローに最適です。
まとめ
GLM-4.7 FlashとQwen3-30B-A3B-Thinking-2507は、ほぼ同一のVRAM要件を持つ優れた30BクラスのMoEモデルですが、それぞれ異なるユースケースを想定しています。GLM-4.7 Flashはソフトウェアエンジニアリングエージェント、ブラウザ自動化、ツール中心のワークフローに最適な選択です。Qwen3-30B-A3B-Thinking-2507は、研究や分析タスクにおいて明示的な思考トレースを伴う透過的な多段階推論が必要な場合に優れた性能を発揮します。
重要なポイント: コーディングエージェントや自動化パイプラインを構築しているなら、GLM-4.7 Flashを選びましょう。構造化された深い推論が必要なら、Qwen3-30B-A3B-Thinking-2507を選びましょう。どちらもNovita AIで利用可能です。GLM-4.7 Flashをお試しください、または本日フルモデルカタログをご覧ください。
コーディングエージェントにはどちらが優れていますか:GLM-4.7 Flash or Qwen3-30B-A3B-Thinking-2507?
GLM-4.7 FlashがSWE-bench Verifiedで59.2%(Qwenの22.0%に対し)と、τ²-Benchツール使用で79.5%(Qwenの49.0%に対し)と圧倒的なスコアを記録しています。
ローカルでのデプロイはどちらが簡単ですか?
どちらも1× RTX 4090でINT4量子化により約18GBのVRAMが必要です。
Claude CodeやTraeでGLM-4.7 Flashを実行できますか?
はい、どちらのツールもAPI経由でカスタムモデル統合をサポートしています。
おすすめの記事
- TraeでGLM-4.5を使用してスマートなコーディングエージェントを解放する
- OpenCodeでMiniMax M2.1を使用する
- DeepSeek vs Qwen: 本番ニーズに合うエコシステムを見極める
Novita AIは、AIとエージェントのクラウドプラットフォームであり、開発者やスタートアップが高性能、信頼性、コスト効率に優れたモデルやエージェントアプリケーションを構築、デプロイ、スケールするのを支援します。



