

MiniMax M2.5 在 SWE-bench Verified 上以 80.2% 的成绩追平了 GLM 5 的 77.8%,而 API 成本仅为后者的三分之一 via Novita AI。 这两款来自中国的 MoE 模型在 2026 年 2 月前后不到 24 小时内发布,采用了不同的 AI 智能体路线。GLM 5 扩展到 7540 亿参数(激活 400 亿),拥有 20 万词元上下文窗口和 DeepSeek 稀疏注意力,专攻复杂系统工程。MiniMax M2.5 总参数量为 2287 亿,具备规范编写能力,并在超过 20 万个真实世界强化学习环境中训练。选择取决于您是需要 GLM 5 的架构深度来处理多小时的调试会话,还是 M2.5 的低成本来运行高容量智能体流水线。
MiniMax M2.5 与 GLM 5 的模型概览
GLM 5 采用 7540 亿参数的 MoE 架构,每次推理激活 400 亿参数,总规模是 M2.5(2287 亿)的 3.2 倍。这一差距体现了截然不同的设计理念,并贯穿于各个性能维度。
| 架构组件 | GLM 5 | MiniMax M2.5 |
|---|---|---|
| 总参数量 | 7540亿(激活400亿) | 2290亿 |
| 专家架构 | 256个路由专家,Top-8,1个共享专家 | 256个本地专家,Top-8 选择 |
| 注意力机制 | DeepSeek 稀疏注意力(DSA) | 标准注意力 |
| 隐藏层 | 78层,隐藏大小6144 | 62层,隐藏大小3072 |
| 上下文窗口 | 202,752 词元(约20万) | 196,608 词元(约19.7万) |
| 训练数据 | 28.5T 词元 | 未公开 |
| 强化学习框架 | Slime(异步强化学习) | Forge(智能体原生强化学习,20万+环境) |
DeepSeek 稀疏注意力是 GLM 5 的关键架构特性。它能在保持长上下文高性能的同时降低部署成本。202K 与 197K 的上下文差距在纸面上看似不大,但 GLM 5 的 DSA 能在整个窗口内保持连贯性,且无二次方内存扩展问题。MiniMax M2.5 则通过任务分解效率而非原始上下文容量来弥补不足。
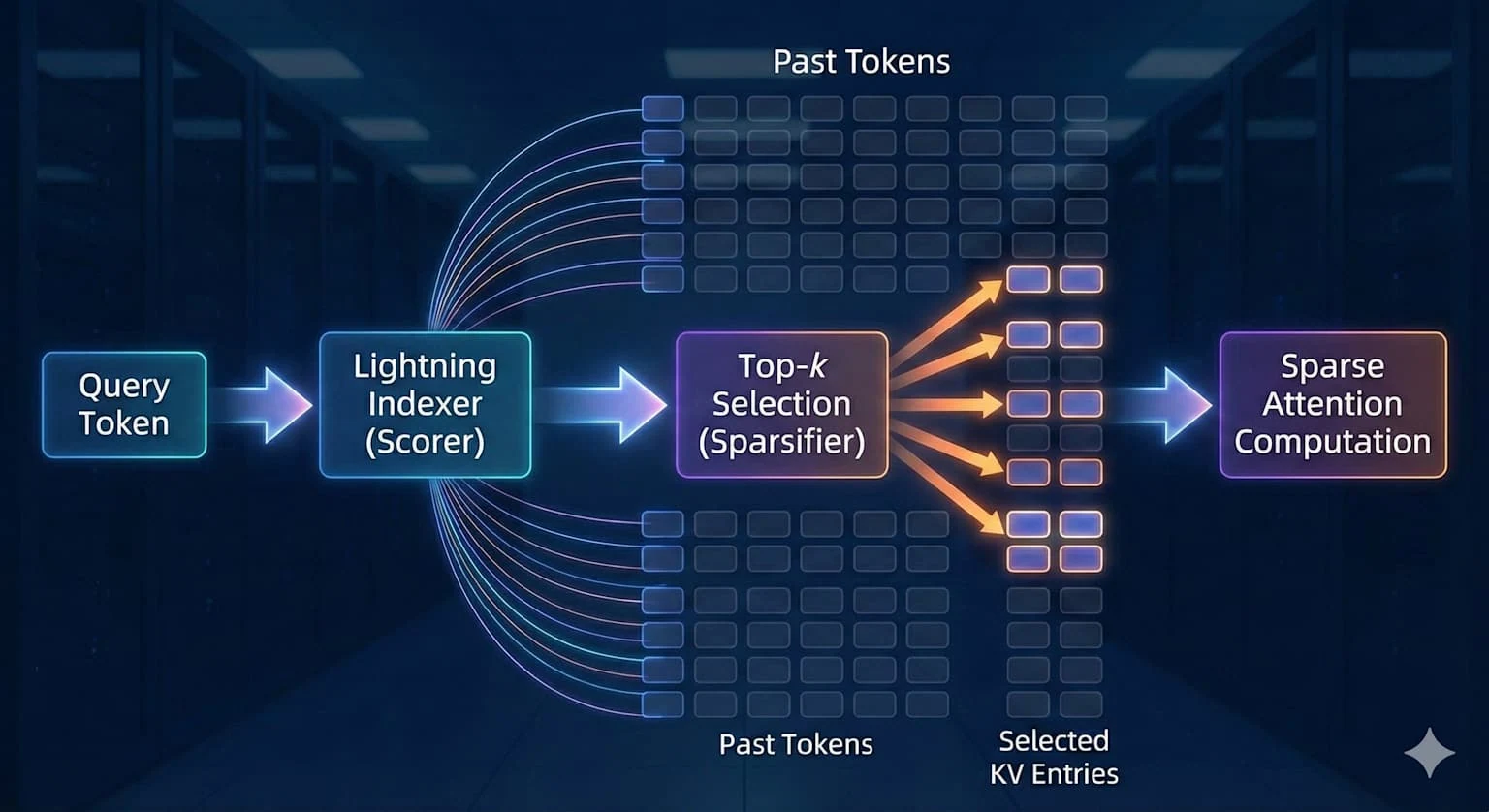
强化学习训练的差距揭示了更深层的差异。GLM 5 的 Slime 框架实现了前所未有规模的异步强化学习,同时推动了预训练和后训练的边界。MiniMax 的 Forge 框架则将训练引擎与智能体完全解耦,优化目标是在各种脚手架(scaffold)上实现泛化,而非单一任务的精通。您需要在“一个模型能应对任何场景”(GLM 5)与“在您的智能体将面对的实际环境中训练”(M2.5 的 20 万+真实训练场景)之间做出选择。
MiniMax M2.5 与 GLM 5 编码能力正面对决
M2.5 在 SWE-bench Verified 上获得 80.2%,略高于 GLM 5 的 77.8%,两者均逼近 Claude Opus 4.6 的 80.9%。
| 编码基准 | GLM 5 | MiniMax M2.5 | 测试内容 |
|---|---|---|---|
| SWE-bench Verified | 77.8% | 80.2% | 真实 GitHub PR 解决能力 |
| SWE-bench Multilingual | 73.3% | 74.1% | 跨语言 Bug 修复 |
| Terminal-Bench 2.0 | 56.2% | 51.7% | CLI 环境操作能力 |
差距体现在它们如何实现相近的分数。Kilo AI 的受控测试揭示了模式:GLM 5 擅长智能体式工程——迭代式调试循环,模型会自动反思编译器错误并重构代码直至测试通过。在“根据规范编写 API”任务中,它通过编写 94 个测试用例、创建可复用中间件和使用标准数据库模式获得满分 35/35,三次自主运行均无 Bug。
M2.5 则在规范编写——即架构师方法——上更胜一筹。在触及代码之前,它会将特性分解为结构、UI 设计和系统界限。在排错任务中,M2.5 记录了每次修复的内联注释并保留了所有原始 API 契约,获得 28/30,高于 GLM 5 的 24.5/30。但代价是:M2.5 在 21 分钟内完成所有测试(GLM 5 需 44 分钟),但在附件端点引入了一个关键授权错误,而 GLM 5 的全面测试原本可以捕获该问题。

测试来源:Kilo Code
核心要点: GLM 5 的自我反思循环在从零开始构建并需要无懈可击的代码时表现出色。M2.5 的前期规划在遗留代码库维护中占优——此时最小化修改和清晰的文档比完美架构更重要。实际开发人员反馈,M2.5 需要更多人工监督但完成更快,而 GLM 5 更符合开发意图,但偶尔会遇到速率限制。GLM 5 构建和测试更多,MiniMax M2.5 改动更少且完成更快。
https://www.youtube.com/watch?v=t94H-DkFIys
MiniMax M2.5 与 GLM 5 的智能体性能
GLM 5 在工具调用基准上占据主导地位:MCP-Atlas(公开集)67.8%、Tool-Decathlon 38%、τ²-Bench 89.7%。这些并非通用函数调用测试;它们衡量智能体能否串联 5-10 次工具调用来解决真实的研究任务。
M2.5 的优势体现在决策效率上。在 BrowseComp、Wide Search 和 RISE 上,M2.5 使用比 M2.1 少 20% 的搜索轮次就获得了更优结果。它学会了通过更精确的查询而非穷举探索来解决问题。这种效率在生产环境中会放大:当您的智能体每天运行 1000 项研究任务时,M2.5 的 token 效率在计入其更低 API 定价之前就已降低了 20% 的成本。
| 智能体基准 | GLM 5 | MiniMax M2.5 | 测试场景 |
|---|---|---|---|
| BrowseComp(带上下文管理) | 75.9% | 75.1%~76.3% | 带历史丢弃策略的真实浏览 |
| RISE(内部) | 未公开 | 50.2% | 专业研究任务 |
| BFCL | 未公开 | 76.8% | |
| τ²-Bench | 89.7% | 未公开 | 工具选择与排序 |
| MCP-Atlas(公开集) | 67.8% | 未公开 | MCP 服务器集成任务 |
MiniMax M2.5 与 GLM 5 的成本分析
M2.5 的定价为每百万 token 输入 0.30 美元 / 输出 1.20 美元,比 GLM 5 预估的 1.00 美元 / 3.20 美元低了 70%(输入)和 62.5%(输出)。持续运行 M2.5 每小时花费约 1 美元(每年 8760 美元),而 GLM 5 持续运行约 2.80 美元/小时(每年 24,528 美元)——在相近可用性下费用高出 2.8 倍。
| 成本场景 | GLM 5 | MiniMax M2.5 | MiniMax M2.5 高速版 |
|---|---|---|---|
| API 定价(每百万 token) | 1.00 美元输入 / 3.20 美元输出 | 0.30 美元输入 / 1.20 美元输出 | 0.60 美元输入 / 2.40 美元输出 |
| 缓存读取 | 0.2 美元/Mt | 0.03 美元/Mt | 0.03 美元/Mt |
| OpenClaw 日均使用(50万输入 / 10万输出) | 0.82 美元/天 | 0.27 美元/天 | 0.54 美元/天 |
缓存读取是指读取之前存储在提示缓存中的 token 的成本。当同一提示内容在多个请求之间复用时,模型直接从缓存中检索这些 token,而非从头处理,从而降低推理延迟和成本。
MiniMax M2.5 与 GLM 5 的使用场景建议
选择 MiniMax M2.5:当速度和成本优势比架构灵活性更重要时。面向客户的智能体需要大规模亚秒级响应——处理每天 10,000+ 对话的聊天机器人、开发者团队的代码补全、自动文档生成等,M2.5 的高吞吐量和 3 倍更低的 API 成本都带来显著优势。
选择 GLM 5:当架构深度和定制需求比成本约束更重要时。需要完整代码库上下文的研究环境、多小时的调试会话,或需要与自定义工具栈集成,这些场景受益于 GLM 5 的 20 万词元上下文窗口及其在 MCP-Atlas/Tool-Decathlon 上的主导地位。7540 亿参数规模配合 DeepSeek 稀疏注意力,在 M2.5 可能因上下文丢失而中断的复杂系统工程任务中保持连贯性。
| 使用场景类别 | GLM 5 | MiniMax M2.5 | 决策因素 |
|---|---|---|---|
| 面向客户的智能体 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | API 价格低廉 |
| 复杂系统工程 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 20万上下文 + DSA 支持多会话 |
| 高容量自动化(每日 10,000+ 任务) | ⭐⭐ | ⭐⭐⭐⭐⭐ | API 费用低 3 倍 = 每美元处理 3 倍任务 |
| 探索性开发 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Kilo 测试中 M2.5 耗时 21 分钟 vs GLM 5 耗时 44 分钟 |
| 自定义工具栈集成 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | MCP-Atlas 67.8%、τ²-Bench 89.7% |
| 多语言代码库维护 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | SWE-bench Multilingual:73.3% vs 51.3% |
| 办公生产力(Word/Excel/PPT) | ⭐⭐ | ⭐⭐⭐⭐⭐ | GDPval-MM 主流模型胜率达 59% |
如何通过 Novita AI 访问这两个模型?
第 1 步:登录并进入模型库
登录您的账户,点击 模型库 按钮。

第 2 步:选择模型
浏览可用选项并选择适合您需求的模型。

第 3 步:开始免费试用
开始免费试用,探索所选模型的能力。
第 4 步:获取 API 密钥
为进行 API 认证,我们将为您提供一个新的 API 密钥。进入“设置”页面,按图示复制 API 密钥。

第 5 步:安装 API
使用适合您编程语言的包管理器安装 API。
安装后,在开发环境中导入必要的库。使用您的 API 密钥初始化 API,以开始与 Novita AI LLM 交互。以下是为 Python 用户使用聊天补全 API 的示例。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5 or minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
一个关键问题: 您需要的是定制化还是性能?如果您的工作流需要微调、自托管或与专有工具栈集成 → GLM 5 的架构灵活性和 MIT 许可证足以证明其溢价合理。如果您正在构建需要扩展到数百万次调用且无预算限制的智能体 → M2.5 的低成本智力将成为您的护城河。中国的开源模型格局刚刚迫使所有竞争对手重新评估 2026 年“可负担 AI”的含义。
常见问题解答
在编码任务方面,MiniMax M2.5 和 GLM 5 哪个更好?
MiniMax M2.5 在编码任务上表现更好,SWE-bench Verified 得分 80.2%,略高于 GLM 5。
在智能体工作流方面,MiniMax M2.5 和 GLM 5 哪个更好?
GLM 5 在复杂智能体工作流中表现更好,在带有工具的 HLE 和 Terminal-Bench 上取得了比 MiniMax M2.5 更强的结果。
MiniMax M2.5 和 GLM 5 能在消费级 GPU 上运行吗?
MiniMax M2.5 和 GLM 5 都需要大量 VRAM,通常通过 API 访问,而非在消费级 GPU 上本地运行。
Novita AI 是一个 AI 与智能体云平台,帮助开发者和初创公司以高性能、高可靠性和高成本效益的方式构建、部署和扩展模型与智能体应用。
推荐阅读



