

MiniMax M2.5 以 80.2% 的 SWE-bench Verified 分數匹敵 GLM 5 的 77.8%——並且在 Novita AI 上 API 成本僅為後者的三分之一。 這兩個中國 MoE 模型在 2026 年 2 月接連 24 小時內釋出,但對 AI 代理採取了截然不同的路線。GLM 5 規模達 754B 參數,活躍參數 40B,配備 200K 上下文的 DeepSeek 稀疏注意力機制,專攻複雜系統工程。MiniMax M2.5 則維持 228.7B 總參數,具備規格寫作能力,並在 20 萬個真實 RL 環境中訓練。選擇的關鍵在於:你需要 GLM 5 的架構深度來進行數小時的除錯任務,還是 M2.5 的低成本來運行高吞吐量的代理管線。
MiniMax M2.5 與 GLM 5 模型概覽
GLM 5 擁有 754B 參數的 MoE 架構,每次推論僅啟動 40B 參數,總體量是 M2.5(228.7B)的 3.2 倍。這個差距揭示了截然不同的設計哲學,並影響所有效能面向。
| 架構組件 | GLM 5 | MiniMax M2.5 |
|---|---|---|
| 總參數數 | 754B(40B 活躍) | 229B |
| 專家架構 | 256 路由專家,Top-8,1 共享專家 | 256 本機專家,Top-8 選擇 |
| 注意力機制 | DeepSeek 稀疏注意力 (DSA) | 標準注意力 |
| 隱藏層 | 78 層,6144 隱藏大小 | 62 層,3072 隱藏大小 |
| 上下文視窗 | 202,752 tokens(200K) | 196,608 tokens(197K) |
| 訓練資料 | 28.5T tokens | 未公開 |
| RL 框架 | Slime(非同步 RL) | Forge(代理原生 RL,20 萬以上環境) |
DeepSeek 稀疏注意力是 GLM 5 的關鍵架構特徵。它在保持長上下文高效能的同時,降低了部署成本。202K 與 197K 的上下文差異在紙面上看起來不大,但 GLM 5 的 DSA 能在整個視窗中維持連貫性,且無需二次記憶體擴展。MiniMax M2.5 則透過任務分解效率而非原始上下文容量來補償。
DSA 介紹 – 來源:kaitchup
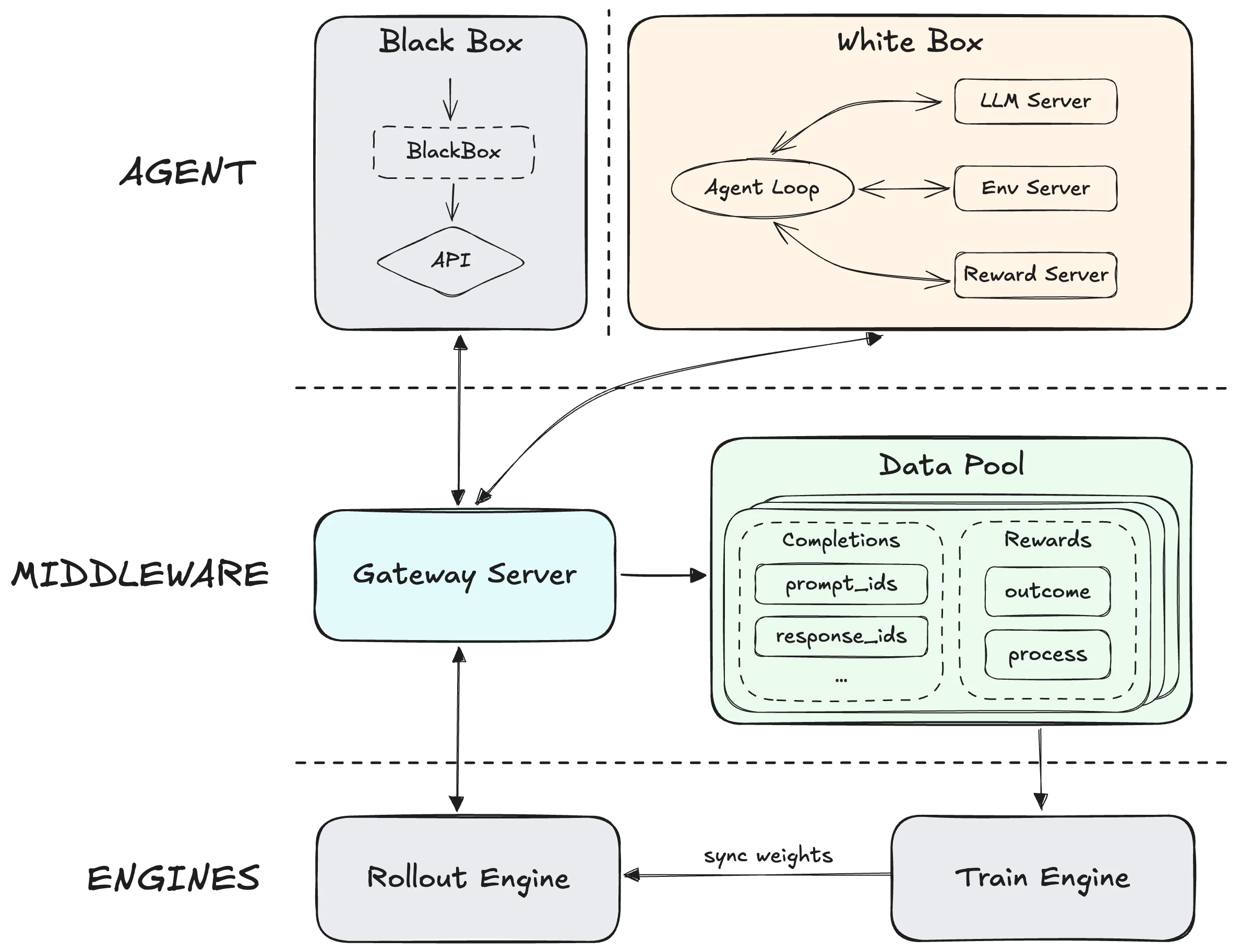
Forge 介紹 – 來源:MiniMax
RL 訓練的差距說明了更深層的故事。GLM 5 的 Slime 框架實現了前所未有的非同步 RL 規模,同時推動了預訓練和後訓練的邊界。MiniMax 的 Forge 框架則完全將訓練引擎與代理解耦,最佳化跨 scaffold 的泛化能力,而非單一任務的專精。你選擇的是一個能處理任何突發狀況的模型(GLM 5),還是一個在代理將面對的實際環境中訓練的模型(M2.5 的 20 萬以上真實訓練情境)。
MiniMax M2.5 與 GLM 5 的正面編碼對決
M2.5 在 SWE-bench Verified 上以 80.2% 的成績略勝 GLM 5 的 77.8%,兩者都逼近 Claude Opus 4.6 的 80.9%。
| 編碼基準 | GLM 5 | MiniMax M2.5 | 測試內容 |
|---|---|---|---|
| SWE-bench Verified | 77.8% | 80.2% | 真實 GitHub PR 解決 |
| SWE-bench Multilingual | 73.3% | 74.1% | 跨語言錯誤修復 |
| Terminal-Bench 2.0 | 56.2% | 51.7% | CLI 環境操作 |
差距體現在它們如何達成相似的分數。Kilo AI 的受控測試揭示了模式:GLM 5 擅長代理工程——反覆除錯循環,模型會對編譯器錯誤進行自我反思並重構,直到測試通過。它在 API 規格實現測試中獲得完美 35/35 分,撰寫了 94 個測試案例、建立可重複使用的中介軟體,並使用標準資料庫模式。三次自主運行中零錯誤。
M2.5 則在規格寫作上勝出——這是架構師的作法。在接觸程式碼之前,它會將功能分解為結構、UI 設計和系統邊界。在錯誤查找任務中,M2.5 用內聯註解記錄每個修復,並保留所有原始 API 合約,得分 28/30,優於 GLM 5 的 24.5/30。但缺點是:M2.5 在 21 分鐘內完成所有測試(GLM 5 需 44 分鐘),卻在附件端點產生了嚴重的授權錯誤,而 GLM 5 的全面測試本可捕捉到這個問題。

測試來源:Kilo Code
關鍵結論: 當你需要從頭開始建構且需要無懈可擊的程式碼時,GLM 5 的自我反思循環表現出色。而 M2.5 的事前規劃則在處理既有程式碼庫時佔優勢,因為此時最小變更和清晰文件比完美架構更重要。實際開發者回報,M2.5 需要更多關注但完成速度更快,而 GLM 5 更貼合意圖但偶爾會遇到速率限制。GLM 5 建構更多、測試更多;MiniMax M2.5 變更更少、完成更快。
https://www.youtube.com/watch?v=t94H-DkFIys
MiniMax M2.5 與 GLM 5 的代理效能
GLM 5 在工具呼叫基準上佔據主導地位。它在 MCP-Atlas(公開集)獲得 67.8%,在 Tool-Decathlon 獲得 38%,在 τ²-Bench 獲得 89.7%。這些並非一般的函數呼叫測試;它們衡量的是代理是否能夠鏈結 5 到 10 個工具調用,以解決真實的研究任務。
M2.5 的優勢則體現在決策效率上。在 BrowseComp、Wide Search 和 RISE 中,M2.5 使用比 M2.1 少 20% 的搜尋輪次就能獲得更好的結果。它學會了用更精確的查詢而非窮舉探索來解決問題。這種效率在生產環境中會產生複合效應:當你的代理每天執行 1,000 個研究任務時,M2.5 的 token 效率在考慮其更低的 API 定價之前,就已經先節省了 20% 的成本。
| 代理基準 | GLM 5 | MiniMax M2.5 | 測試情境 |
|---|---|---|---|
| BrowseComp(含上下文管理) | 75.9% | 75.1%~76.3% | 真實瀏覽,含歷史丟棄策略 |
| RISE(內部) | 未公開 | 50.2% | 專業研究任務 |
| BFCL | 未公開 | 76.8% | |
| τ²-Bench | 89.7% | 未公開 | 工具選擇與排序 |
| MCP-Atlas(公開集) | 67.8% | 未公開 | MCP 伺服器整合任務 |
MiniMax M2.5 與 GLM 5 的成本分析
M2.5 每百萬 token 輸入 $0.30 / 輸出 $1.20 的價格,比 GLM 5 預估的輸入 $1.00 / 輸出 $3.20 便宜了 70% 的輸入和 62.5% 的輸出。連續運行 M2.5 每小時成本 $1 美元(每年 $8,760 美元)。GLM 5 的定價則使連續運行成本約為每小時 $2.80 美元(每年 $24,528 美元)——在相近的正常運行時間下,成本高出 2.8 倍。
| 成本情境 | GLM 5 | MiniMax M2.5 | MiniMax M2.5 高速模式 |
|---|---|---|---|
| API 定價(每百萬 token) | ** 輸入 $1.00 / 輸出 $3.20** | ** 輸入 $0.30 / 輸出 $1.20** | ** 輸入 $0.60 / 輸出 $2.40** |
| 快取讀取 | $0.2 /Mt | $0.03 /Mt | $0.03 /Mt |
| OpenClaw 每日用量(500K 輸入 / 100K 輸出) | $0.82/天 | $0.27/天 | $0.54/天 |
快取讀取 指的是讀取先前儲存在提示快取中的 token 的成本。當多個請求重複使用相同的提示內容時,模型會直接從快取中檢索這些 token,而不是從頭開始重新處理。這降低了推論延遲和成本。
MiniMax M2.5 與 GLM 5 的使用案例建議
選擇 MiniMax M2.5 當速度與成本的主導地位比架構靈活性更重要時。需要次秒級回應並大規模運作的客戶面向代理——處理每天超過 10,000 次對話的聊天機器人、跨開發團隊的程式碼補全、自動化文件生成——都能從 M2.5 的高吞吐量和 3 倍更低的 API 成本中受益。
選擇 GLM 5 當架構深度和自訂需求超過成本考量時。需要完整程式碼庫上下文的研究環境、長達數小時的除錯任務,或與自訂工具堆疊整合的工作,都偏好 GLM 5 的 200K 上下文視窗以及其在 MCP-Atlas / Tool-Decathlon 上的優勢。754B 參數規模搭配 DeepSeek 稀疏注意力,能夠在複雜的系統工程任務中維持連貫性,而 M2.5 可能在任務中途失去上下文。
| 使用案例類別 | GLM 5 | MiniMax M2.5 | 決定因素 |
|---|---|---|---|
| **客戶面向代理 ** | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 低廉的 API 價格 |
| **複雜系統工程 ** | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 200K 上下文 + DSA,適合長時段任務 |
| 高吞吐量自動化(每天 10K+ 任務) | ⭐⭐ | ⭐⭐⭐⭐⭐ | 3 倍便宜 API = 每美元 3 倍任務 |
| **探索性開發 ** | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Kilo 測試中 M2.5 21 分鐘 vs GLM 5 44 分鐘 |
| **自訂工具堆疊整合 ** | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 67.8% MCP-Atlas,89.7% τ²-Bench |
| **多語言程式碼庫維護 ** | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | SWE-bench Multilingual 73.3% vs 51.3% |
| 辦公室生產力(Word/Excel/PPT) | ⭐⭐ | ⭐⭐⭐⭐⭐ | 在主流模型上勝率 59%(GDPval-MM) |
如何透過 Novita AI 存取兩個模型?
步驟 1:登入並存取模型庫
登入您的帳戶,然後點擊 模型庫 按鈕。

步驟 2:選擇您的模型
瀏覽可用選項,並選擇符合您需求的模型。

步驟 3:開始免費試用
開始免費試用,探索所選模型的功能。
步驟 4:取得 API 金鑰
為了驗證 API,我們會提供您一組新的 API 金鑰。進入「設定」頁面,您可以依照圖片指示複製 API 金鑰。

步驟 5:安裝 API
使用您程式語言專屬的套件管理器安裝 API。
安裝完成後,將必要的函式庫匯入您的開發環境。使用您的 API 金鑰初始化 API,即可開始與 Novita AI LLM 互動。以下是 Python 使用者使用聊天完成 API 的範例。
from openai import OpenAI
client = OpenAI(
api_key="<您的 API 金鑰>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5 or minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "您是位樂於助人的助手。"},
{"role": "user", "content": "你好,最近好嗎?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
一個問題決定一切: 您需要的是自訂性還是單純的效能?如果您的工作流程需要微調、自行託管,或與專有工具堆疊整合 → GLM 5 的架構靈活性和 MIT 授權足以證明其溢價合理。如果您正在開發需要擴展到數百萬次呼叫而不受預算限制的代理 → M2.5 的低成本智慧將成為您的護城河。中國開源模型生態已經迫使每個競爭者重新校準 2026 年「平價 AI」的定義。
常見問題
對於編碼任務,MiniMax M2.5 還是 GLM 5 比較好?
MiniMax M2.5 在 SWE-bench Verified 上以 80.2% 的成績表現稍優於 GLM 5,適合編碼任務。
對於代理工作流程,MiniMax M2.5 還是 GLM 5 比較好?
GLM 5 在複雜代理工作流程中表現更佳,在 HLE with tools 和 Terminal-Bench 上均取得比 MiniMax M2.5 更強的結果。
MiniMax M2.5 和 GLM 5 可以在消費級 GPU 上運行嗎?
這兩個模型都需要大量 VRAM,通常透過 API 而非消費級 GPU 來存取。
Novita AI 是一個 AI 與代理雲端平台,幫助開發者和新創企業以高效能、高可靠性和高成本效益來建構、部署和擴展模型及代理應用程式。
推薦閱讀



