

GLM-4.6 e Minimax-M2 representam dois dos modelos de linguagem de nova geração mais capazes no ecossistema LLM de código aberto. Eles visam confiabilidade, eficiência e usabilidade para desenvolvedores, desde suporte a codificação até execução de tarefas de múltiplas etapas e assistentes prontos para produção. Cada modelo está buscando o “rápido, capaz e acessível” à sua maneira. Então, qual deles realmente se adapta ao seu fluxo de trabalho?
Neste artigo, examinaremos seus pontos fortes principais, contrastes, custo e aplicações do mundo real para ajudá-lo a determinar qual modelo melhor se adapta aos seus objetivos.
GLM-4.6 vs Minimax-M2: Noções Básicas e Benchmark
| Recurso | GLM 4.6 | Minimax M2 |
|---|---|---|
| Parâmetro | 355B com 32B ativados | 230B com 10B ativados |
| Arquitetura | MoE | MoE |
| Janela de Contexto | 200K Tokens | 204K Tokens |
| Código Aberto | Sim | Sim |
| Modo de Pensamento | Raciocínio + Não Raciocínio | Pensar + Não Pensar |
| Benchmark | Categoria | GLM-4.6 | Minimax-M2 |
|---|---|---|---|
| Terminal-Bench Hard | Codificação Agente e Uso de Terminal | 23% | 24% |
| 𝜏²-Bench Telecom | Uso de Ferramentas Agente | 71% | 87% |
| AA-LCR | Raciocínio de Contexto Longo | 54% | 61% |
| Humanity’s Last Exam | Raciocínio e Conhecimento | 13.3% | 12.5% |
| MMLU-Pro | Raciocínio e Conhecimento | 83% | 82% |
| GPQA Diamond | Raciocínio Científico | 78% | 78% |
| LiveCodeBench | Codificação | 70% | 83% |
| SciCode | Codificação | 38% | 36% |
| IFBench | Seguimento de Instruções | 43% | 72% |
| AIME 2025 | Matemática de Competição | 86% | 78% |
1. Raciocínio e Conhecimento
Em cenários de raciocínio e intensivos em conhecimento, o GLM-4.6 demonstra consistência e estrutura ligeiramente mais fortes. Suas respostas tendem a seguir cadeias lógicas de forma mais clara, manter precisão factual e apresentar ideias de maneira bem organizada. Isso o torna especialmente adequado para redação analítica, assistência a pesquisas ou fluxos de trabalho de tomada de decisão complexos. O Minimax M2, embora próximo em capacidade geral de raciocínio, foca mais em agilidade e eficiência — frequentemente produzindo respostas concisas e práticas, em vez de caminhos de raciocínio elaborados.
2. Raciocínio Científico
Ao lidar com perguntas científicas ou técnicas, ambos os modelos mostram um nível de compreensão comparável. Eles podem interpretar fórmulas, contextos teóricos e problemas do tipo experimental com precisão semelhante. No entanto, o GLM-4.6 tende a oferecer um raciocínio mais estável e reproduzível, enquanto o M2 tende a padrões de resolução de problemas mais flexíveis, adaptando-se mais rapidamente a prompts novos ou ambíguos.
3. Codificação e Execução Técnica
O Minimax M2 tem melhor desempenho ao executar instruções práticas de codificação, como editar arquivos, executar scripts ou realizar melhorias iterativas. Ele se comporta mais como um assistente de desenvolvedor que entende a intenção e executa as tarefas de forma eficiente. Em contraste, o GLM-4.6 é mais forte em consistência lógica e correção de algoritmos, tornando-o bem adequado para explicação de código, depuração de lógica ou raciocínio sobre decisões de design de sistema.
4. Uso Agente e Interação com Ferramentas
O Minimax M2 mostra uma vantagem clara no uso do tipo agente. Ele lida com invocação de ferramentas, execução de comandos e planejamento de múltiplas etapas com maior confiabilidade. Isso o torna uma opção mais forte para frameworks de agentes, orquestração de APIs e automação de fluxos de trabalho. O GLM-4.6, embora um pouco menos agressivo no uso de ferramentas, fornece qualidade de saída mais estável ao raciocinar sobre etapas intermediárias, o que beneficia cenários que exigem validação ou saída estruturada.
5. Contexto Longo e Seguimento de Instruções
Em tarefas que exigem contexto estendido ou compreensão detalhada passo a passo, o Minimax-M2 supera ao manter a coerência e seguir instruções complexas de forma mais fiel. Ele gerencia documentos longos ou diálogos de múltiplas turnos com um fluxo suave e semelhante ao humano, tornando-o ideal para resumos, redação de textos longos ou automação de projetos. Em comparação, o GLM-4.6 é mais cauteloso e estruturado, priorizando o alinhamento factual e a clareza mesmo ao lidar com entradas grandes — uma característica que beneficia tarefas de documentação acadêmica, jurídica ou empresarial.
6. Tarefas Matemáticas e Simbólicas
Ao lidar com raciocínio matemático ou lógica simbólica, o GLM-4.6 se destaca com maior precisão e interpretabilidade. Ele lida com decomposição de problemas, manipulação simbólica e raciocínio de fórmulas com consistência interna mais forte. Isso lhe dá uma vantagem para pesquisa quantitativa, resolução de problemas competitivos ou casos de uso de engenharia pesados em análise, onde a precisão importa mais do que a velocidade de execução.
Conclusão
- GLM-4.6: se destaca em raciocínio sustentado, codificação precisa e comunicação refinada. Ele se comporta como um solucionador de problemas deliberado e consciente do contexto, ideal para pesquisa, redação técnica e frameworks de agentes que exigem clareza de raciocínio e confiabilidade de ferramentas.
- Minimax-M2: é um modelo nativo para agentes, projetado para velocidade de execução, robustez e adaptabilidade no mundo real. Ele se parece com um assistente de desenvolvedor que age em vez de discutir — ideal para pipelines de produção, orquestração de código e agentes de contexto longo que valorizam throughput e responsividade.
GLM-4.6 vs Minimax-M2: Velocidade e Latência
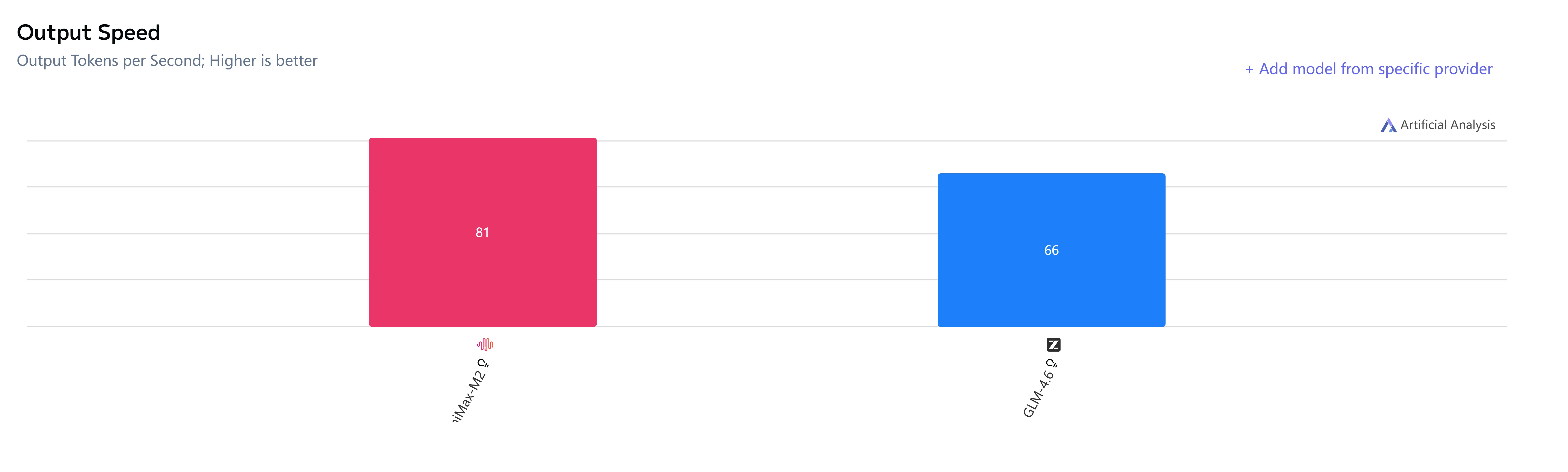
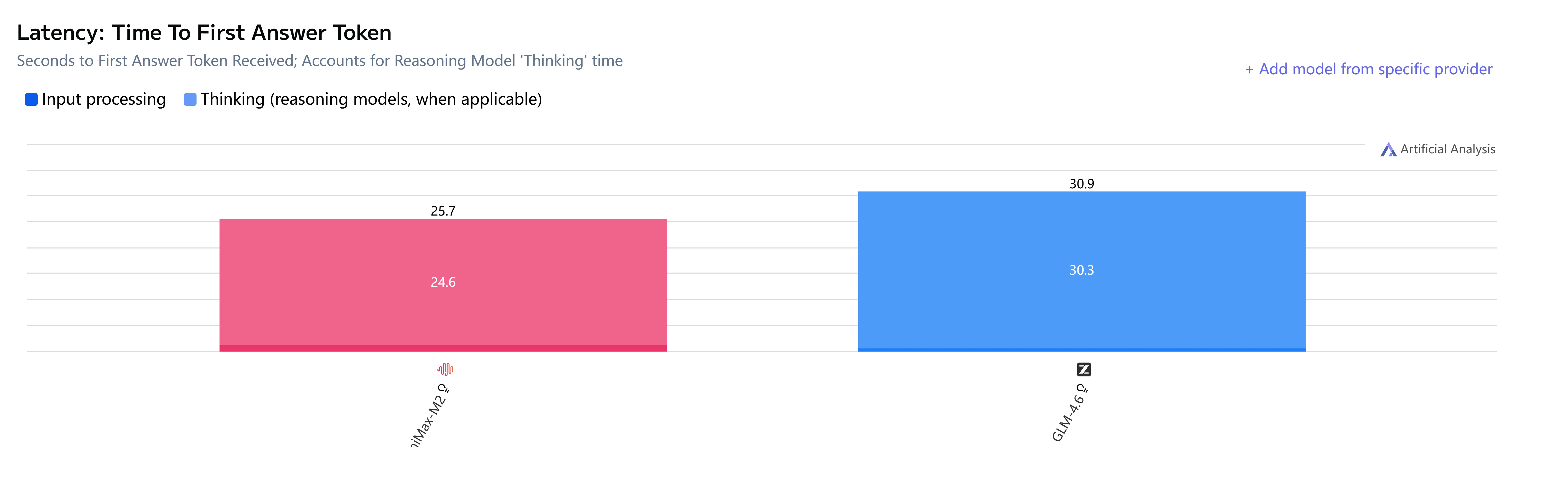
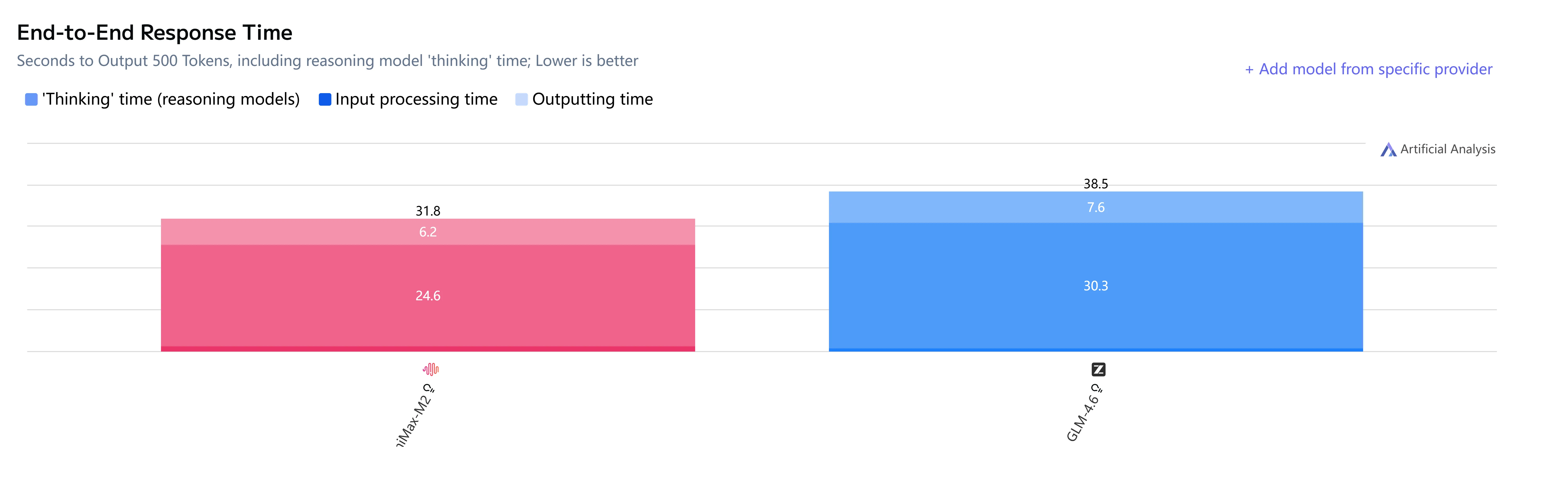
GLM-4.6 vs Minimax-M2: Casos de Uso
Ambos os modelos têm desempenho impressionante, mas refletem filosofias de design diferentes — o GLM-4.6 é o pensador estruturado, enquanto o Minimax-M2 é o executor adaptativo. Seus pontos fortes se manifestam em cenários do mundo real distintos:
GLM-4.6: Raciocínio Estruturado e Inteligência de Textos Longos
O GLM-4.6 brilha onde precisão, clareza de raciocínio e estabilidade contextual definem o valor. Sua janela de 200K tokens e alinhamento de linguagem refinado o tornam ideal para tarefas que exigem pensamento sustentado e interpretabilidade.
- Fluxos de trabalho de pesquisa analítica: sintetizando insights de relatórios longos, conjuntos de dados de múltiplos PDFs ou documentos jurídicos/financeiros com lógica de referência cruzada.
- Redação técnica e documentação: gerando relatórios estruturados, visões gerais de arquitetura ou manuais de usuário que exigem consistência de tom e precisão factual.
- Raciocínio complexo de código: explicando algoritmos, refatorando projetos grandes ou otimizando decisões de design de sistema enquanto mantém uma rationale coerente.
- Assistentes conscientes do contexto: alimentando sistemas de diálogo ou bots educacionais que devem permanecer logicamente consistentes ao longo de centenas de turnos.
Minimax-M2: Execução, Agilidade e Desempenho Agente
O Minimax-M2 prospera em ambientes onde velocidade, autonomia e adaptabilidade são prioridades. Sua arquitetura nativa para agentes permite o uso contínuo de ferramentas, tornando-o ideal para fluxos de trabalho dinâmicos de múltiplas etapas.
- Automação para desenvolvedores: realizando edições de múltiplos arquivos, correções de dependências ou depuração de CI/CD em contextos de terminal ou IDE com baixa latência.
- Tarefas de recuperação agente: executando pipelines de navegação e síntese que localizam fontes, extraem dados e verificam resultados de forma autônoma.
- Orquestração de fluxos de trabalho: coordenando ações encadeadas em shell, navegador e executores de código para automação de negócios ou dados.
- Implantação escalável: servindo como um motor de alto throughput e eficiente em custos para agentes de nível de produção ou plataformas de codificação colaborativa.
GLM-4.6 vs Minimax-M2: Preços
| Modelo | Preço de Entrada (/1M Tokens) | Preço de Saída (/1M Tokens) |
| GLM-4.6 (via Novita AI) | $0.6 | $2.2 |
| Minimax-M2 (via Novita AI) | $0.3 | $1.2 |
A Novita AI oferece suporte tanto ao GLM-4.6 quanto ao Minimax-M2 por meio de sua API REST, oferecendo raciocínio avançado, contexto estendido e alta eficiência de codificação.
Como Acessar o GLM-4.6 ou o Minimax-M2 na Novita AI
Opção 1: Usando a API
Passo 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.
Passo 4: Instale a API (GLM 4.6 como Exemplo)
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.6",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Opção 2: Fluxos de Trabalho Multi-Agente com OpenAI Agents SDK
Construa sistemas multi-agente sofisticados aproveitando as capacidades de modo duplo do DeepSeek-V3.1:
- Integração Plug-and-Play: Use o DeepSeek V3.1 em qualquer fluxo de trabalho do OpenAI Agents
- Capacidades Avançadas de Agente: Suporte para transferências, roteamento e integração de ferramentas
- Arquitetura Escalável: Projete agentes que aproveitem as capacidades do DeepSeek V3.1
Opção 3: Conecte-se com Outras Plataformas de Terceiros
Ferramentas de Desenvolvimento: Integre-se perfeitamente com IDEs e ambientes de desenvolvimento populares como Cursor, Trae, Qwen Code e Cline por meio da API da Novita AI, que é totalmente compatível com a OpenAI. Além disso, o GLM-4.6 fornecido pela Novita AI também é compatível com a Anthropic, permitindo a integração direta dentro do Claude Code.
Frameworks de Orquestração: Conecte-se com LangChain, Dify, CrewAI, Langflow e outras plataformas de orquestração de IA usando conectores oficiais.
Integração com Hugging Face: A Novita AI atua como um provedor de inferência oficial do Hugging Face, garantindo ampla compatibilidade com o ecossistema.
Perguntas Frequentes
Qual é a principal diferença entre o GLM-4.6 e o Minimax-M2? O GLM-4.6 foca em raciocínio avançado e desempenho em contexto longo, enquanto o Minimax-M2 enfatiza eficiência prática e estabilidade conversacional.
O GLM-4.6 é adequado para codificação e engenharia de software? Sim. O GLM-4.6 lida com projetos complexos de múltiplos arquivos e depuração estruturada melhor do que a maioria dos modelos de peso aberto, tornando-o uma escolha sólida para desenvolvedores.
O que torna o Minimax-M2 ideal para aplicações rápidas? O Minimax-M2 usa um design de Mixture-of-Experts (MoE) que ativa apenas 10B de parâmetros por consulta, permitindo respostas quase em tempo real com latência mínima para chatbots e tarefas de automação.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



