

Les modèles GLM-4.6 et Minimax-M2 sont deux des modèles de langage de nouvelle génération les plus performants de l’écosystème LLM open source. Ils visent la fiabilité, l’efficacité et l’ergonomie pour les développeurs, que ce soit pour l’assistance au codage, l’exécution de tâches multi-étapes ou les assistants destinés à la production. Chaque modèle tend vers l’objectif « rapide, performant et abordable » à sa manière. Lequel correspond réellement à votre flux de travail ?
Dans cet article, nous examinerons leurs points forts principaux, leurs différences, leur coût et leurs cas d’usage concrets pour vous aider à déterminer quel modèle correspond le mieux à vos objectifs.
GLM-4.6 vs Minimax-M2 : Bases et benchmarks
| Fonctionnalité | GLM 4.6 | Minimax M2 |
|---|---|---|
| Paramètres | 355 milliards, dont 32 milliards activés | 230 milliards, dont 10 milliards activés |
| Architecture | MoE | MoE |
| Fenêtre de contexte | 200 000 tokens | 204 000 tokens |
| Open source | Oui | Oui |
| Mode de réflexion | Raisonnement + Non-raisonnement | Réflexion + Non-réflexion |
| Benchmark | Catégorie | GLM-4.6 | Minimax-M2 |
|---|---|---|---|
| Terminal-Bench Hard | Codage agent et utilisation du terminal | 23 % | 24 % |
| 𝜏²-Bench Telecom | Utilisation d’outils agent | 71 % | 87 % |
| AA-LCR | Raisonnement sur long contexte | 54 % | 61 % |
| Humanity’s Last Exam | Raisonnement et connaissances | 13,3 % | 12,5 % |
| MMLU-Pro | Raisonnement et connaissances | 83 % | 82 % |
| GPQA Diamond | Raisonnement scientifique | 78 % | 78 % |
| LiveCodeBench | Codage | 70 % | 83 % |
| SciCode | Codage | 38 % | 36 % |
| IFBench | Suivi des instructions | 43 % | 72 % |
| AIME 2025 | Mathématiques de compétition | 86 % | 78 % |
1. Raisonnement et connaissances
Dans des scénarios nécessitant beaucoup de raisonnement et de connaissances, le GLM-4.6 fait preuve d’une cohérence et d’une structure légèrement supérieures. Ses réponses suivent généralement des chaînes logiques plus clairement, maintiennent une précision factuelle et présentent les idées de manière bien organisée. Cela le rend particulièrement adapté à la rédaction analytique, l’assistance à la recherche ou les flux de travail de prise de décision complexes. Le Minimax M2, bien que proche en termes de capacité de raisonnement globale, met davantage l’accent sur l’agilité et l’efficacité : il produit souvent des réponses concises et pratiques plutôt que des chemins de raisonnement élaborés.
2. Raisonnement scientifique
Lorsqu’il s’agit de questions scientifiques ou techniques, les deux modèles affichent un niveau de compréhension comparable. Ils peuvent interpréter des formules, des contextes théoriques et des problèmes de type expérimental avec une précision similaire. Cependant, le GLM-4.6 a tendance à proposer un raisonnement plus stable et reproductible, tandis que le M2 privilégie des schémas de résolution de problèmes plus flexibles, s’adaptant plus rapidement à des prompts nouveaux ou ambigus.
3. Codage et exécution technique
Le Minimax M2 obtient de meilleurs résultats lors de l’exécution d’instructions de codage pratiques, comme la modification de fichiers, l’exécution de scripts ou l’amélioration itérative. Il se comporte davantage comme un assistant développeur qui comprend l’intention et l’exécute efficacement.
À l’inverse, le GLM-4.6 est plus performant en termes de cohérence logique et de justesse des algorithmes, ce qui le rend particulièrement adapté à l’explication de code, au débogage logique ou au raisonnement sur des décisions de conception de systèmes.
4. Utilisation agent et interaction avec les outils
Le Minimax M2 présente un avantage net dans les cas d’usage de type agent. Il gère l’appel d’outils, l’exécution de commandes et la planification multi-étapes avec une plus grande fiabilité. Cela le rend mieux adapté aux frameworks d’agents, à l’orchestration d’API et à l’automatisation des flux de travail.
Le GLM-4.6, bien que légèrement moins performant dans l’utilisation d’outils, offre une qualité de sortie plus stable lors du raisonnement sur les étapes intermédiaires, ce qui est bénéfique pour les scénarios nécessitant une validation ou une sortie structurée.
5. Long contexte et suivi des instructions
Pour les tâches nécessitant un contexte étendu ou une compréhension détaillée étape par étape, le Minimax M2 surpasse en maintenant la cohérence et en suivant les instructions complexes de manière plus fidèle. Il gère les longs documents ou les dialogues multi-tours avec un flux fluide et naturel, ce qui le rend idéal pour la résumé, la rédaction de longs textes ou l’automatisation de projets.
Par comparaison, le GLM-4.6 est plus prudent et structuré, privilégiant l’alignement factuel et la clarté même lors du traitement de grandes entrées : une caractéristique qui bénéficie aux tâches de documentation académique, juridique ou d’entreprise.
6. Tâches mathématiques et symboliques
Lorsqu’il s’agit de raisonnement mathématique ou de logique symbolique, le GLM-4.6 se distingue par une plus grande précision et une meilleure interprétabilité. Il gère la décomposition de problèmes, la manipulation symbolique et le raisonnement sur des formules avec une cohérence interne plus forte. Cela lui donne un avantage pour la recherche quantitative, la résolution de problèmes de compétition ou les cas d’usage d’ingénierie très analytiques où la précision prime sur la vitesse d’exécution.
Points clés
- GLM-4.6 excelle dans le raisonnement soutenu, le codage précis et la communication affinée. Il se comporte comme un résolveur de problèmes délibéré et conscient du contexte, idéal pour la recherche, la rédaction technique et les frameworks d’agents nécessitant une clarté de raisonnement et une fiabilité des outils.
- Minimax-M2 est un modèle natif pour les agents, conçu pour la vitesse d’exécution, la robustesse et l’adaptabilité concrète. Il se comporte comme un assistant développeur qui agit plutôt que qui discute : idéal pour les pipelines de production, l’orchestration de code et les agents à long contexte qui valorisent le débit et la réactivité.
GLM-4.6 vs Minimax-M2 : Vitesse et latence
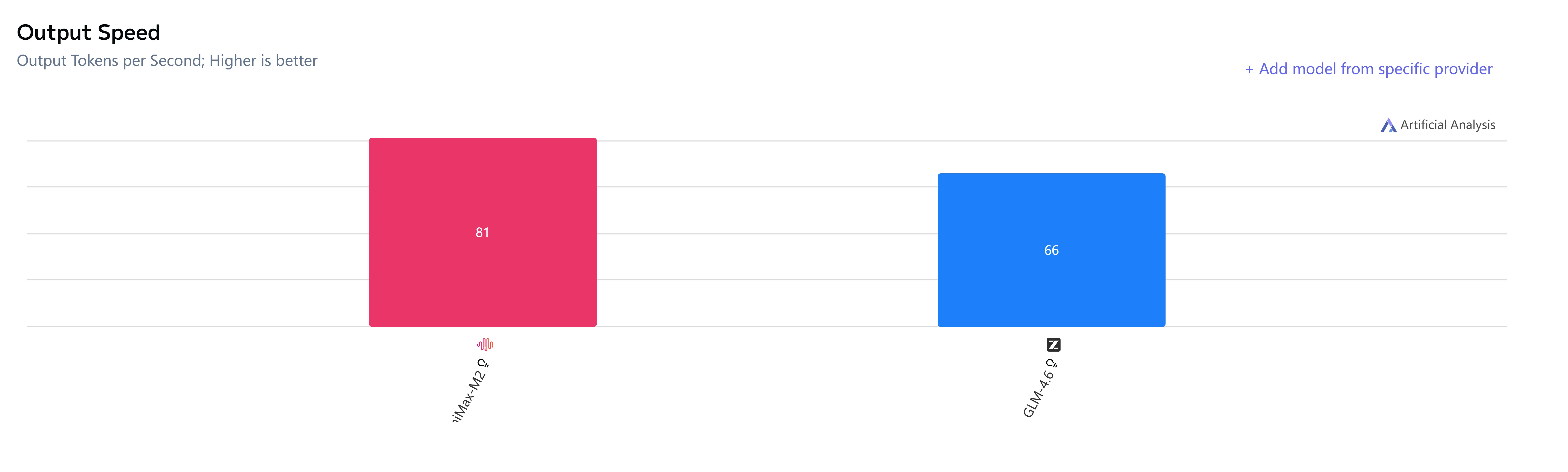
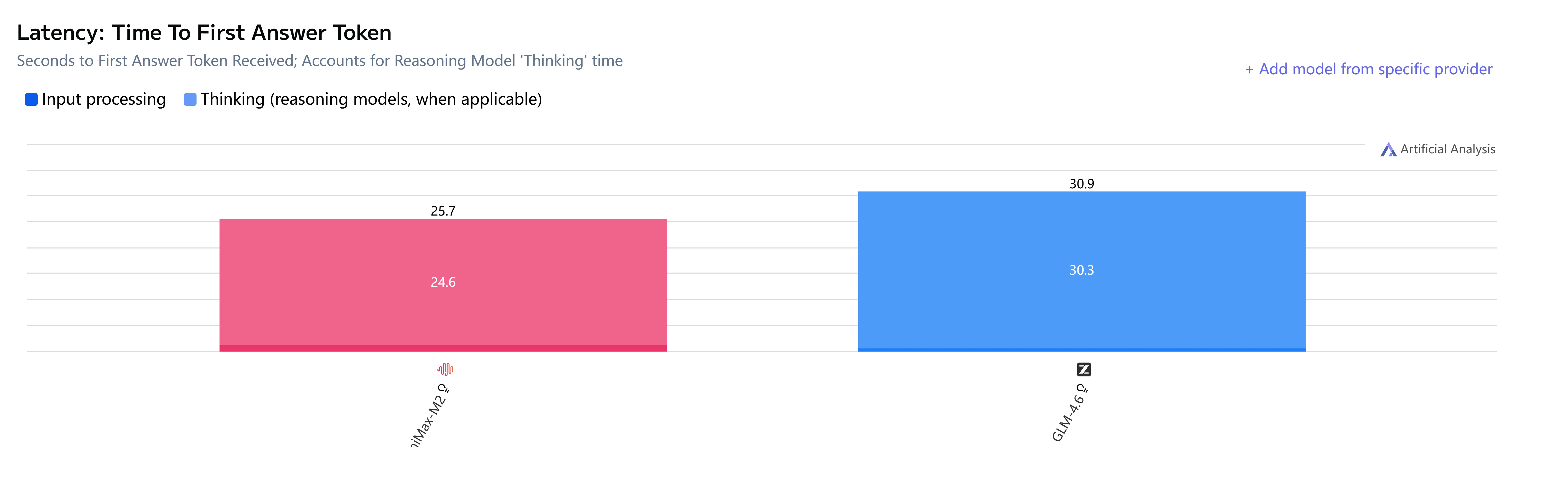
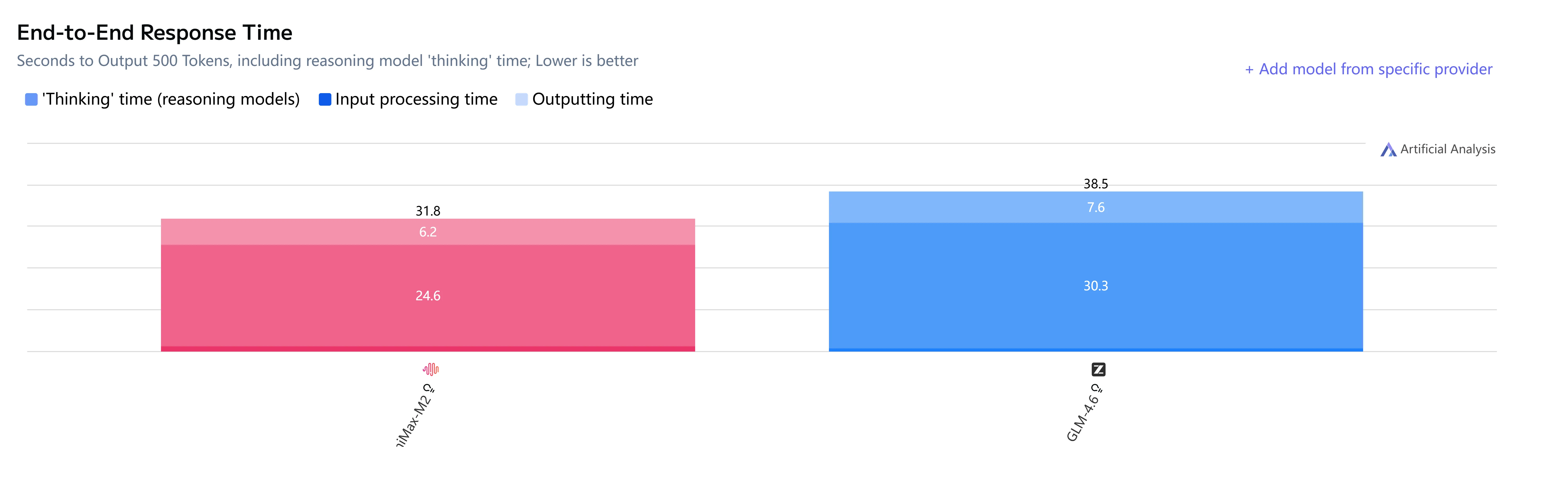
GLM-4.6 vs Minimax-M2 : Cas d’usage
Les deux modèles offrent des performances impressionnantes mais reflètent des philosophies de conception différentes : le GLM-4.6 est le penseur structuré, tandis que le Minimax-M2 est l’exécuteur adaptatif.
Leurs points forts se manifestent dans des scénarios concrets distincts :
GLM-4.6 : Raisonnement structuré et intelligence sur longs textes
Le GLM-4.6 excelle là où la précision, la clarté de raisonnement et la stabilité contextuelle constituent la valeur ajoutée.
Sa fenêtre de contexte de 200 000 tokens et son alignement linguistique affiné le rendent idéal pour les tâches nécessitant une réflexion soutenue et une interprétabilité.
- Flux de travail de recherche analytique : synthétiser des informations provenant de longs rapports, de jeux de données multi-PDF ou de documents juridiques/financiers avec une logique de références croisées.
- Rédaction technique et documentation : générer des rapports structurés, des présentations d’architecture ou des manuels utilisateurs nécessitant une cohérence de ton et une précision factuelle.
- Raisonnement sur du code complexe : expliquer des algorithmes, refactoriser de grands projets ou optimiser la conception de systèmes tout en maintenant une justification cohérente.
- Assistants conscients du contexte : alimenter des systèmes de dialogue ou des bots éducatifs qui doivent rester logiquement cohérents sur des centaines de tours de parole.
Minimax-M2 : Exécution, agilité et performance agent
Le Minimax-M2 excelle dans les environnements où la vitesse, l’autonomie et l’adaptabilité sont prioritaires.
Son architecture native pour les agents permet une utilisation transparente des outils, ce qui le rend idéal pour les flux de travail dynamiques et multi-étapes.
- Automatisation pour les développeurs : effectuer des modifications sur plusieurs fichiers, des corrections de dépendances ou du débogage CI/CD dans des environnements de terminal ou d’IDE avec une faible latence.
- Tâches de récupération agent : exécuter des pipelines de navigation et de synthèse qui localisent des sources, extraient des données et vérifient les résultats de manière autonome.
- Orchestration de flux de travail : coordonner des actions enchaînées entre shell, navigateur et exécuteurs de code pour l’automatisation métier ou de données.
- Déploiement scalable : servir de moteur à haut débit et rentable pour des agents de niveau production ou des plateformes de codage collaboratif.
GLM-4.6 vs Minimax-M2 : Tarification
| Modèle | Prix d’entrée (/1 million de tokens) | Prix de sortie (/1 million de tokens) |
|---|---|---|
| GLM-4.6 (via Novita AI) | 0,6 $ | 2,2 $ |
| Minimax-M2 (via Novita AI) | 0,3 $ | 1,2 $ |
Novita AI prend en charge les modèles GLM-4.6 et MiniMax-M2 via son API REST, offrant un raisonnement avancé, un contexte étendu et une efficacité de codage élevée.
Comment accéder aux modèles GLM-4.6 ou Minimax-M2 sur Novita AI
Option 1 : Utiliser l’API
Étape 1 : Se connecter et accéder à la bibliothèque de modèles Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisir votre modèle Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Obtenir votre clé API Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En vous rendant sur la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.
Étape 4 : Installer l’API (exemple avec GLM 4.6) Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec les LLM de Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python :
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.6",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2 : Flux de travail multi-agents avec le SDK OpenAI Agents
Construisez des systèmes multi-agents sophistiqués en exploitant les capacités duales de DeepSeek-V3.1 :
- Intégration plug-and-play : utilisez DeepSeek V3.1 dans tout flux de travail OpenAI Agents
- Capacités agent avancées : prise en charge des transferts, du routage et de l’intégration d’outils
- Architecture scalable : concevez des agents qui exploitent les capacités de DeepSeek V3.1
Option 3 : Se connecter à d’autres plateformes tierces
Outils de développement : intégrez-vous de manière transparente aux IDE et environnements de développement populaires comme Cursor, Trae, Qwen Code et Cline via l’API de Novita AI, qui est entièrement compatible avec OpenAI. De plus, le GLM-4.6 proposé par Novita AI est également compatible avec Anthropic, ce qui permet de l’intégrer directement dans Claude Code.
Frameworks d’orchestration : connectez-vous à LangChain, Dify, CrewAI, Langflow et à d’autres plateformes d’orchestration IA à l’aide de connecteurs officiels.
Intégration Hugging Face : Novita AI est un fournisseur d’inférence officiel de Hugging Face, garantissant une compatibilité large avec l’écosystème.
Questions fréquemment posées
Quelle est la principale différence entre le GLM-4.6 et le Minimax-M2 ? Le GLM-4.6 met l’accent sur le raisonnement avancé et les performances sur long contexte, tandis que le Minimax-M2 privilégie l’efficacité pratique et la stabilité des conversations.
Le GLM-4.6 est-il adapté au codage et à l’ingénierie logicielle ? Oui. Le GLM-4.6 gère les projets complexes multi-fichiers et le débogage structuré mieux que la plupart des modèles à poids ouverts, ce qui en fait un choix solide pour les développeurs.
Qu’est-ce qui rend le Minimax-M2 idéal pour les applications rapides ? Le Minimax-M2 utilise une conception de type Mélange d’experts (MoE) qui n’active que 10 milliards de paramètres par requête, permettant des réponses quasi en temps réel avec une latence minimale pour les chatbots et les tâches d’automatisation.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle vos projets.



