

GLM-4.6 und Minimax-M2 gehören zu den leistungsfähigsten Sprachmodellen der neuen Generation im Open-Source-LLM-Ökosystem. Sie zielen auf Zuverlässigkeit, Effizienz und Entwicklerfreundlichkeit ab – von der Code-Unterstützung über die Ausführung mehrstufiger Aufgaben bis hin zu produktionsbereiten Assistenten. Jedes Modell verfolgt auf seine eigene Weise das Ziel, „schnell, leistungsfähig und erschwinglich“ zu sein. Welches passt also tatsächlich zu Ihrem Workflow?
In diesem Artikel untersuchen wir ihre wichtigsten Stärken, Unterschiede, Kosten und praktischen Anwendungsfälle, um Ihnen bei der Entscheidung zu helfen, welches Modell am besten zu Ihren Zielen passt.
GLM-4.6 vs Minimax-M2: Grundlagen und Benchmarks
| Funktion | GLM 4.6 | Minimax M2 |
|---|---|---|
| Parameter | 355B mit 32B aktiviert | 230B mit 10B aktiviert |
| Architektur | MoE | MoE |
| Kontextfenster | 200K Tokens | 204K Tokens |
| Open Source | Ja | Ja |
| Denkmodus | Reasoning + Non-Reasoning | Think + Non-Think |
| Benchmark | Kategorie | GLM-4.6 | Minimax-M2 |
|---|---|---|---|
| Terminal-Bench Hard | Agentische Code- & Terminalnutzung | 23% | 24% |
| 𝜏²-Bench Telecom | Agentische Werkzeugnutzung | 71% | 87% |
| AA-LCR | Langkontext-Reasoning | 54% | 61% |
| Humanity’s Last Exam | Reasoning & Wissen | 13,3 % | 12,5 % |
| MMLU-Pro | Reasoning & Wissen | 83 % | 82 % |
| GPQA Diamond | Wissenschaftliches Reasoning | 78 % | 78 % |
| LiveCodeBench | Codeentwicklung | 70% | 83% |
| SciCode | Codeentwicklung | 38% | 36% |
| IFBench | Anweisungsbefolgung | 43% | 72% |
| AIME 2025 | Wettbewerbsmathematik | 86% | 78% |
1. Reasoning & Wissen
In Szenarien mit hohem Anspruch an Reasoning und Wissen zeigt GLM-4.6 eine leicht stärkere Konsistenz und Struktur. Seine Antworten folgen in der Regel klareren logischen Ketten, bewahren faktische Genauigkeit und präsentieren Ideen auf gut organisierte Weise. Das macht es besonders geeignet für analytische Schreibarbeiten, Forschungsunterstützung oder komplexe Entscheidungsworkflows. Minimax M2 konzentriert sich trotz ähnlicher allgemeiner Reasoning-Fähigkeiten mehr auf Agilität und Effizienz – es liefert oft prägnante, praxisorientierte Antworten statt ausführlicher Reasoning-Pfade.
2. Wissenschaftliches Reasoning
Bei wissenschaftlichen oder technischen Fragen zeigen beide Modelle ein vergleichbares Verständnis. Sie können Formeln, theoretische Kontexte und experimentelle Probleme mit ähnlicher Genauigkeit interpretieren. GLM-4.6 bietet jedoch tendenziell stabilere und reproduzierbare Reasoning-Ergebnisse, während M2 zu flexibleren Problemlösungsmustern neigt und sich schneller an neue oder mehrdeutige Prompts anpasst.
3. Codeentwicklung & Technische Ausführung
Minimax M2 schneidet bei der Ausführung praktischer Code-Anweisungen besser ab, etwa beim Bearbeiten von Dateien, Ausführen von Skripten oder Durchführen iterativer Verbesserungen. Es verhält sich eher wie ein Entwicklerassistent, der Absichten versteht und diese effizient umsetzt.
Im Gegensatz dazu ist GLM-4.6 stärker in Bezug auf logische Konsistenz und Korrektheit von Algorithmen, was es besonders geeignet macht für Code-Erklärungen, Debugging-Logik oder Reasoning zu Systemdesign-Entscheidungen.
4. Agentische Nutzung & Werkzeuginteraktion
Minimax M2 zeigt einen klaren Vorteil bei der agentischen Nutzung. Es bewältigt Werkzeugaufrufe, Befehlsausführung und mehrstufige Planung zuverlässiger. Das macht es besser geeignet für Agent-Frameworks, API-Orchestrierung und Workflow-Automatisierung.
GLM-4.6 liefert zwar eine etwas weniger aggressive Werkzeugnutzung, bietet aber eine stabilere Ausgabequalität beim Reasoning über Zwischenschritte, was Szenarien zugutekommt, die Validierung oder strukturierte Ausgaben erfordern.
5. Langkontext & Anweisungsbefolgung
Bei Aufgaben, die einen erweiterten Kontext oder ein detailliertes schrittweises Verständnis erfordern, schneidet Minimax M2 besser ab, da es Kohärenz bewahrt und komplexe Anweisungen genauer befolgt. Es verarbeitet lange Dokumente oder mehrturnige Dialoge mit einem flüssigen, menschenähnlichen Ablauf, was es ideal macht für Zusammenfassungen, Langform-Texte oder Projektautomatisierung.
Im Vergleich dazu ist GLM-4.6 vorsichtiger und strukturierter und priorisiert faktische Ausrichtung und Klarheit auch bei der Verarbeitung großer Eingaben – eine Eigenschaft, die akademischen, juristischen oder Unternehmensdokumentationsaufgaben zugutekommt.
6. Mathematische & Symbolische Aufgaben
Bei mathematischem Reasoning oder symbolischer Logik sticht GLM-4.6 durch größere Präzision und Interpretierbarkeit hervor. Es bewältigt Problemzerlegung, symbolische Manipulation und Formel-Reasoning mit stärkerer interner Konsistenz. Das gibt ihm einen Vorteil bei quantitativer Forschung, wettbewerbsorientierter Problemlösung oder analyseintensiven Engineering-Anwendungsfällen, bei denen Genauigkeit wichtiger ist als Ausführungsgeschwindigkeit.
Fazit
- GLM-4.6 glänzt durch nachhaltiges Reasoning, präzise Codeentwicklung und raffinierte Kommunikation. Es verhält sich wie ein bewusster, kontextbewusster Problemlöser, der ideal für Forschung, technisches Schreiben und Agent-Frameworks ist, die Reasoning-Klarheit und Werkzeugzuverlässigkeit erfordern.
- Minimax-M2 ist ein agentennatives Modell, das für Ausführungsgeschwindigkeit, Robustheit und Anpassungsfähigkeit in der Praxis entwickelt wurde. Es fühlt sich an wie ein Entwicklerassistent, der handelt statt nur zu diskutieren – ideal für Produktionspipelines, Code-Orchestrierung und Langkontext-Agenten, die Durchsatz und Reaktionsfähigkeit schätzen.
GLM-4.6 vs Minimax-M2: Geschwindigkeit und Latenz
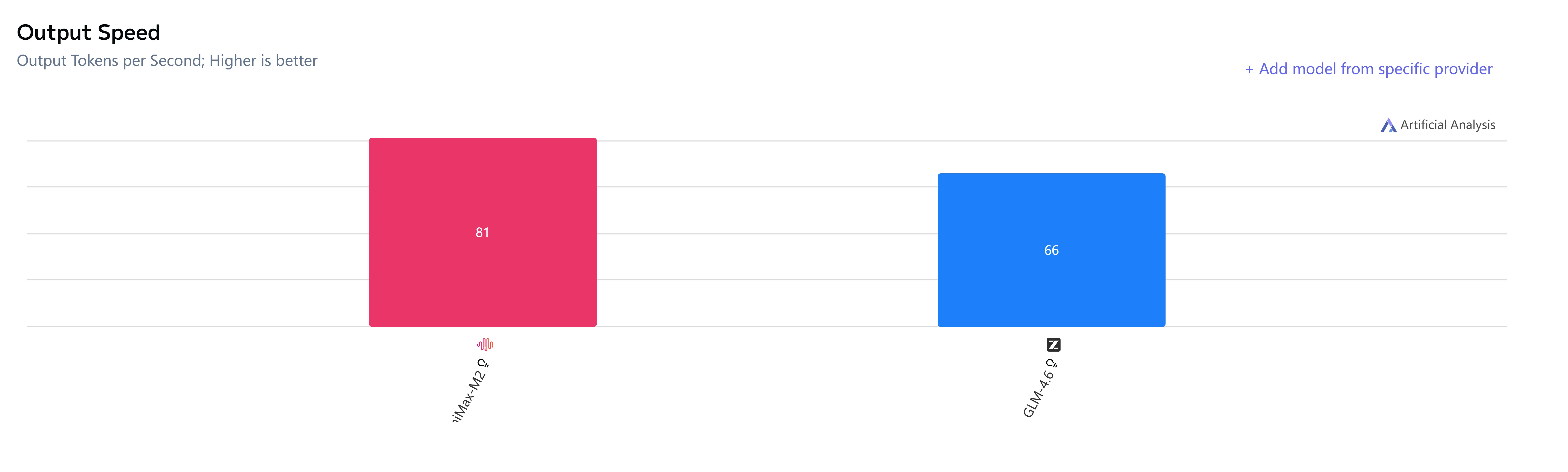
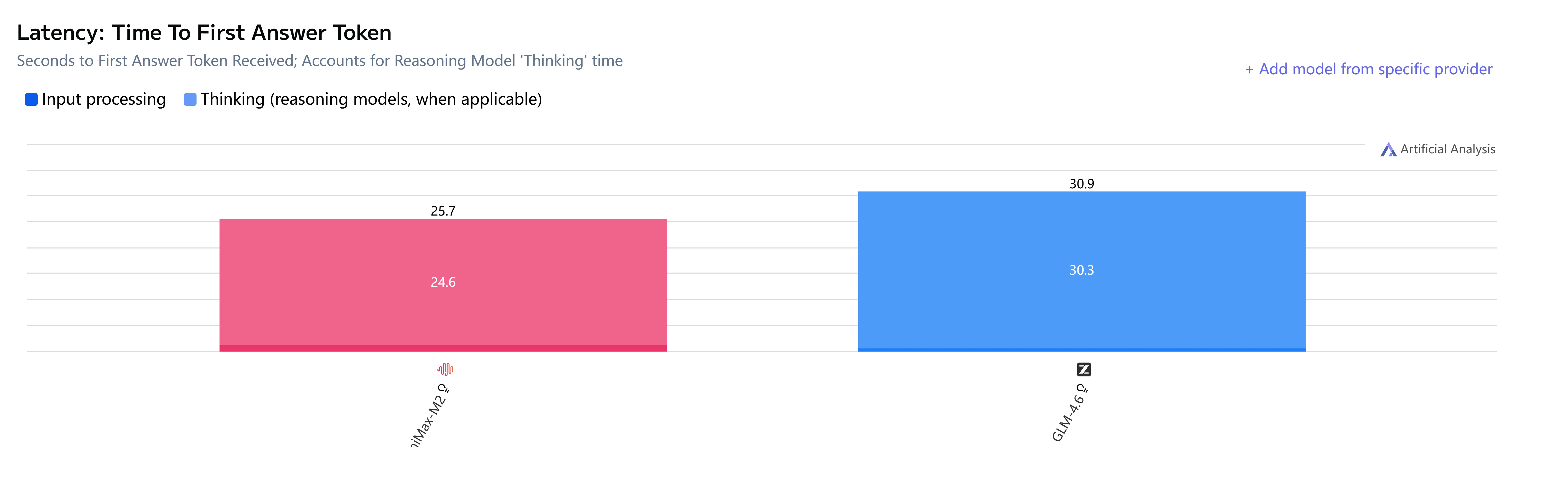
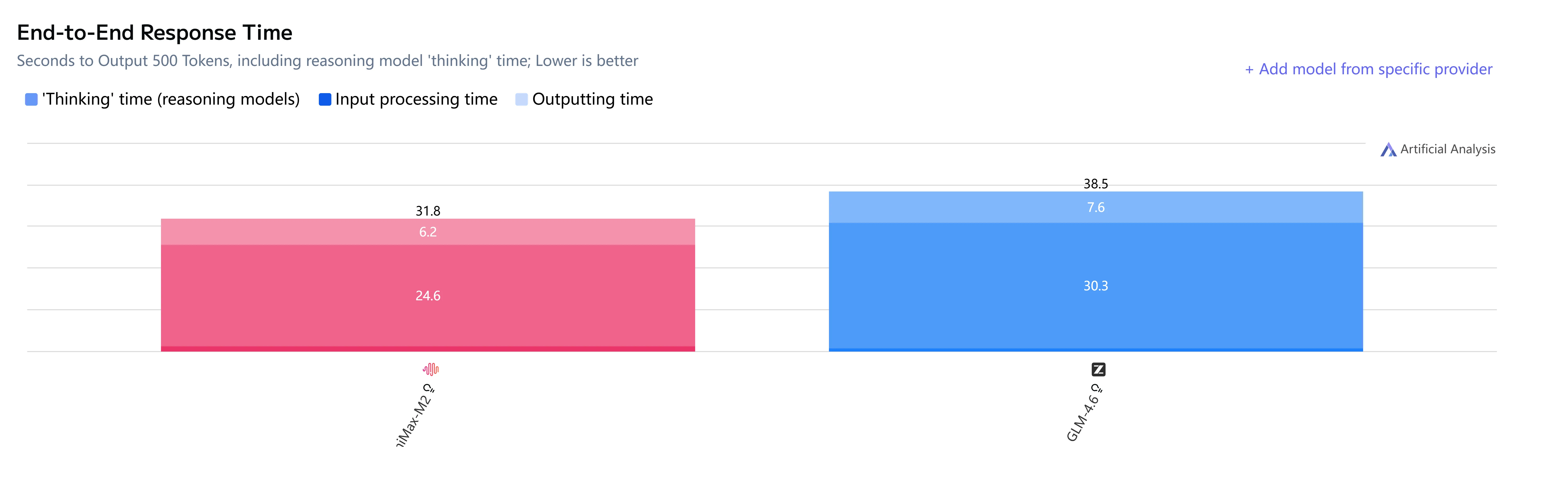
GLM-4.6 vs Minimax-M2: Anwendungsfälle
Beide Modelle liefern beeindruckende Leistungen, spiegeln aber unterschiedliche Designphilosophien wider – GLM-4.6 ist der strukturierte Denker, während Minimax-M2 der adaptive Ausführer ist.
Ihre Stärken zeigen sich in unterschiedlichen praktischen Szenarien:
GLM-4.6: Strukturiertes Reasoning und Langform-Intelligenz
GLM-4.6 glänzt dort, wo Genauigkeit, Reasoning-Klarheit und kontextuelle Stabilität den Wert definieren.
Sein 200K-Token-Fenster und die optimierte Sprachausrichtung machen es ideal für Aufgaben, die anhaltendes Denken und Interpretierbarkeit erfordern.
- Analytische Forschungs-Workflows: Synthese von Erkenntnissen aus langen Berichten, Multi-PDF-Datensätzen oder juristischen/finanziellen Dokumenten mit Querverweis-Logik.
- Technisches Schreiben & Dokumentation: Erstellung strukturierter Berichte, Architekturübersichten oder Benutzerhandbücher, die Konsistenz im Ton und faktische Genauigkeit erfordern.
- Komplexes Code-Reasoning: Erklärung von Algorithmen, Refactoring großer Projekte oder Optimierung von Systemdesigns bei gleichbleibender kohärenter Begründung.
- Kontextbewusste Assistenten: Betrieb von Dialogsystemen oder Bildungs-Bots, die über hunderte von Turns hinweg logisch konsistent bleiben müssen.
Minimax-M2: Ausführung, Agilität und Agentische Leistung
Minimax-M2 entfaltet seine Stärken in Umgebungen, in denen Geschwindigkeit, Autonomie und Anpassungsfähigkeit Priorität haben.
Seine agentennative Architektur ermöglicht nahtlose Werkzeugnutzung, was es ideal macht für dynamische, mehrstufige Workflows.
- Entwicklerautomatisierung: Durchführung von Multi-Datei-Bearbeitungen, Abhängigkeitskorrekturen oder CI/CD-Debugging in Terminal- oder IDE-Kontexten mit niedriger Latenz.
- Agentische Retrieval-Aufgaben: Ausführung von Browse-and-Synthesize-Pipelines, die Quellen lokalisieren, Daten extrahieren und Ergebnisse autonom verifizieren.
- Workflow-Orchestrierung: Koordinierung verketteter Aktionen über Shell, Browser und Code-Runner hinweg für Geschäfts- oder Datenautomatisierung.
- Skalierbare Bereitstellung: Einsatz als kosteneffiziente, hochdurchsatzige Engine für produktionsbereite Agenten oder kollaborative Codeplattformen.
GLM-4.6 vs Minimax-M2: Preise
| Modell | Eingabepreis (pro 1M Tokens) | Ausgabepreis (pro 1M Tokens) |
|---|---|---|
| GLM-4.6 (via Novita AI) | $0,6 | $2,2 |
| Minimax-M2 (via Novita AI) | $0,3 | $1,2 |
Novita AI unterstützt sowohl GLM-4.6 als auch MiniMax-M2 über seine REST-API und bietet fortschrittliches Reasoning, erweiterten Kontext und hohe Codeeffizienz.
So greifen Sie auf GLM-4.6 oder Minimax-M2 bei Novita AI zu
Option 1: Nutzung über die API
Schritt 1: Einloggen und Zugriff auf die Modellbibliothek
Loggen Sie sich in Ihrem Konto ein und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Schritt 3: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung über die API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.
Schritt 4: Installieren Sie die API (GLM 4.6 als Beispiel)
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die benötigten Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.6",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2: Multi-Agent-Workflows mit OpenAI Agents SDK
Erstellen Sie anspruchsvolle Multi-Agent-Systeme unter Nutzung der Dual-Mode-Fähigkeiten von DeepSeek-V3.1:
- Plug-and-Play-Integration: Nutzen Sie DeepSeek V3.1 in jedem OpenAI Agents-Workflow
- Erweiterte Agent-Fähigkeiten: Unterstützung für Übergaben, Routing und Werkzeugintegration
- Skalierbare Architektur: Entwerfen Sie Agenten, die die Fähigkeiten von DeepSeek V3.1 nutzen
Option 3: Verbindung mit anderen Drittanbieter-Plattformen
Entwicklungstools: Integrieren Sie sich nahtlos in beliebte IDEs und Entwicklungsumgebungen wie Cursor, Trae, Qwen Code und Cline über die Novita AI-API, die vollständig OpenAI-kompatibel ist. Darüber hinaus ist der von Novita AI bereitgestellte GLM-4.6 auch Anthropic-kompatibel, sodass eine direkte Integration in Claude Code möglich ist.
Orchestrierungs-Frameworks: Verbinden Sie sich mit LangChain, Dify, CrewAI, Langflow und anderen KI-Orchestrierungsplattformen über offizielle Konnektoren.
Hugging Face Integration: Novita AI ist offizieller Inferenzanbieter von Hugging Face und gewährleistet eine breite Ökosystemkompatibilität.
Häufig gestellte Fragen
Was ist der Hauptunterschied zwischen GLM-4.6 und Minimax-M2? GLM-4.6 konzentriert sich auf fortschrittliches Reasoning und Langkontext-Leistung, während Minimax-M2 praktische Effizienz und konversationelle Stabilität betont.
Ist GLM-4.6 für Codeentwicklung und Software Engineering geeignet? Ja. GLM-4.6 bewältigt komplexe Multi-Datei-Projekte und strukturiertes Debugging besser als die meisten Open-Weight-Modelle, was es zu einer soliden Wahl für Entwickler macht.
Was macht Minimax-M2 ideal für schnelle Anwendungen? Minimax-M2 verwendet ein Mixture-of-Experts (MoE)-Design, das pro Abfrage nur 10B Parameter aktiviert, was nahezu Echtzeit-Antworten mit minimaler Latenz für Chatbots und Automatisierungsaufgaben ermöglicht.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Aufbau und Skalierung bereitstellt.



