

- O que você está realmente comparando: Raciocínio de flagship versus eficiência escalável
- Comparação de benchmarks
- Comparação de velocidade e latência
- Comparação de preços
- Quando usar cada modelo
- Início rápido: Teste ambos os modelos instantaneamente no Playground da Novita
- Opções de implantação: API, SDK, integrações de terceiros e implantação local
- Conclusão
Se você está comparando o GLM-4.7 e o GLM-4.7-Flash como se fossem intercambiáveis, acabará otimizando a coisa errada.
Esses dois modelos não estão no mesmo nível por design:
- GLM-4.7 é um modelo de raciocínio de flagship — você o escolhe quando se importa com qualidade máxima e pode justificar um custo de token mais alto.
- GLM-4.7-Flash é uma “mula de carga” mais leve e econômica — você o escolhe quando se importa com throughput, economia por unidade e praticidade de contexto longo em escala.
Na Novita, você pode executar ambos com preços transparentes, APIs e um Playground fácil de usar para decidir rapidamente.
O que você está realmente comparando: Raciocínio de flagship versus eficiência escalável
GLM-4.7: o modelo de raciocínio de flagship
O GLM-4.7 é posicionado como um modelo primeiro no raciocínio de ponta (inteligência geral forte), com contexto longo e geração rápida — mas também é muito mais caro por token que o Flash.
GLM-4.7-Flash: a “mula de carga” MoE escalável para agentes/codificação
O GLM-4.7-Flash é construído em torno da eficiência (classe MoE 30B-A3B), visando codificação agentiva + fluxos de trabalho com ferramentas e tarefas de contexto longo nas quais você precisa de alto throughput e custo previsível.
Comparação de benchmarks
Índices de Inteligência / Codificação / Agência da Artificial Analysis
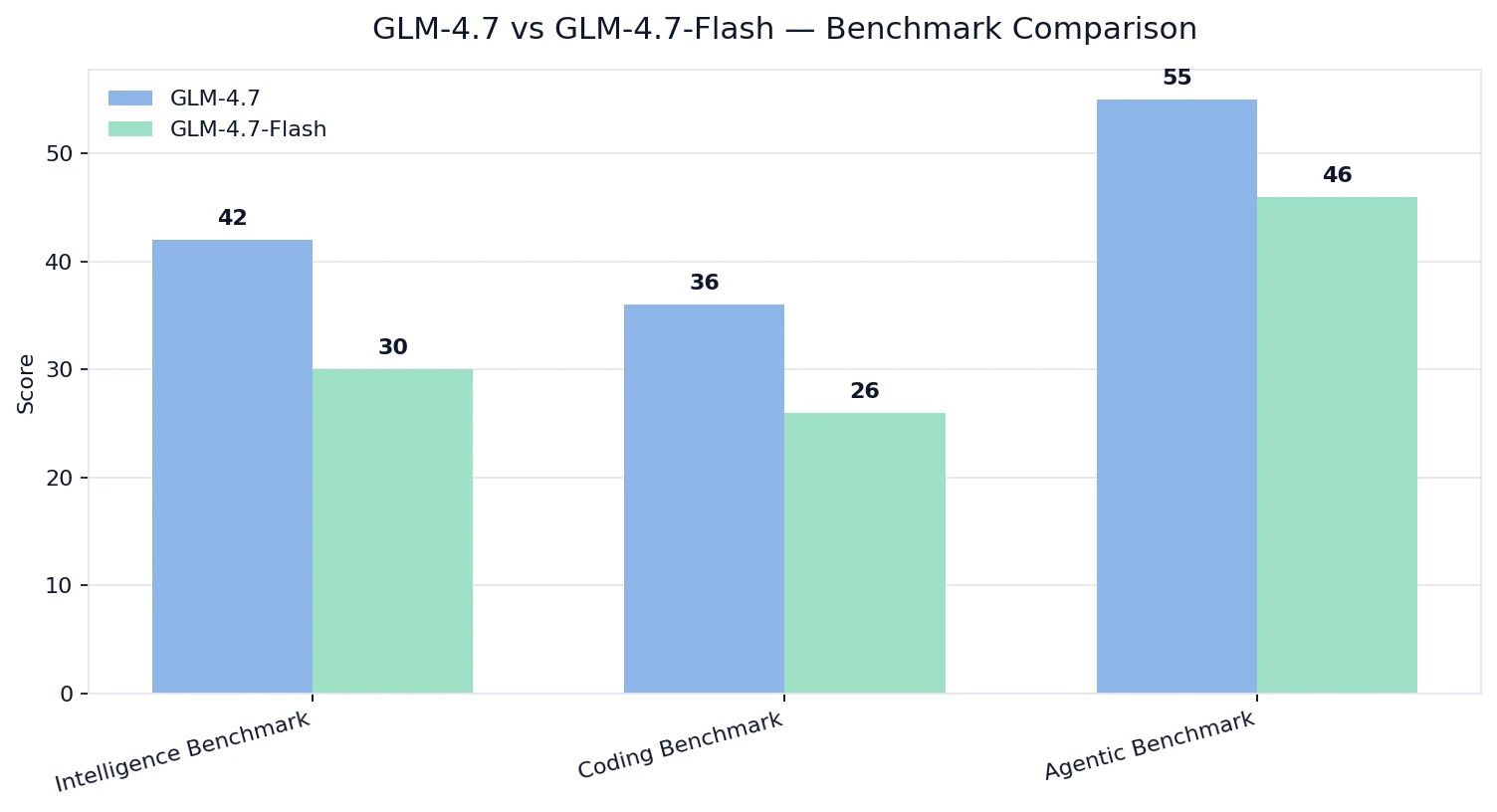
💡Interpretação:
- O GLM-4.7 vence em qualidade nas capacidades de inteligência, codificação e agência.
- O GLM-4.7-Flash ainda é forte, mas é ajustado para um alvo de otimização diferente: custo + capacidade de implantação + throughput prático.
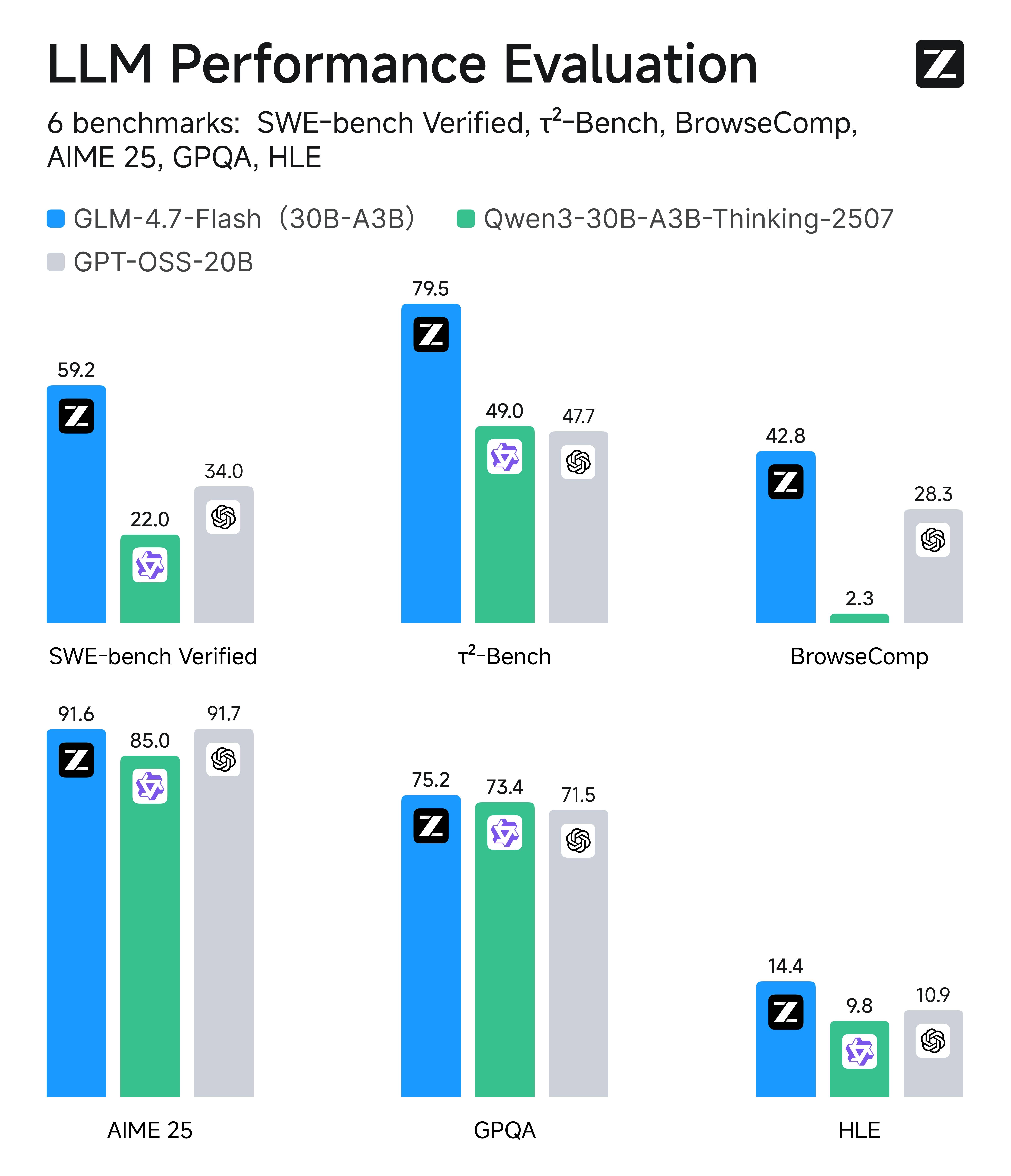
Eficiência de primeira classe: GLM-4.7-Flash versus pares de tamanho similar
O que é fácil de passar despercebido, porém, é que o GLM-4.7-Flash é um desempenho de ponta dentro da sua própria classe de eficiência (aproximadamente modelos MoE leves de 20B–30B). Em comparações com pares em seis avaliações do mundo real — abrangendo codificação, uso de agentes/ferramentas, tarefas de navegação, matemática e raciocínio de conhecimento — o Flash se classifica consistentemente no topo ou perto do topo entre alternativas de tamanho similar, o que é exatamente o motivo pelo qual faz sentido como escolha padrão para sistemas de produção de alto volume.
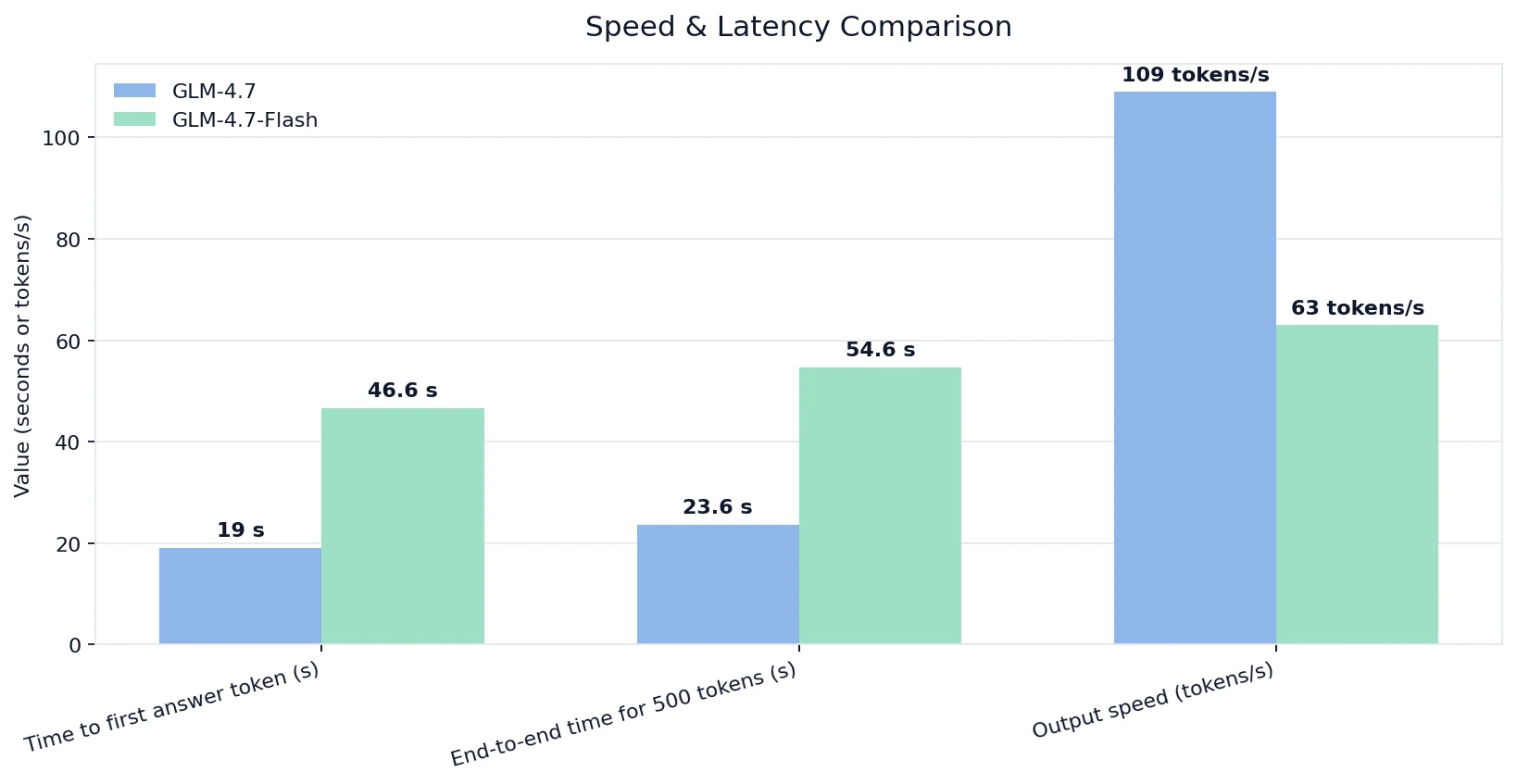
Comparação de velocidade e latência
Comparação de preços
Nos preços da Novita:
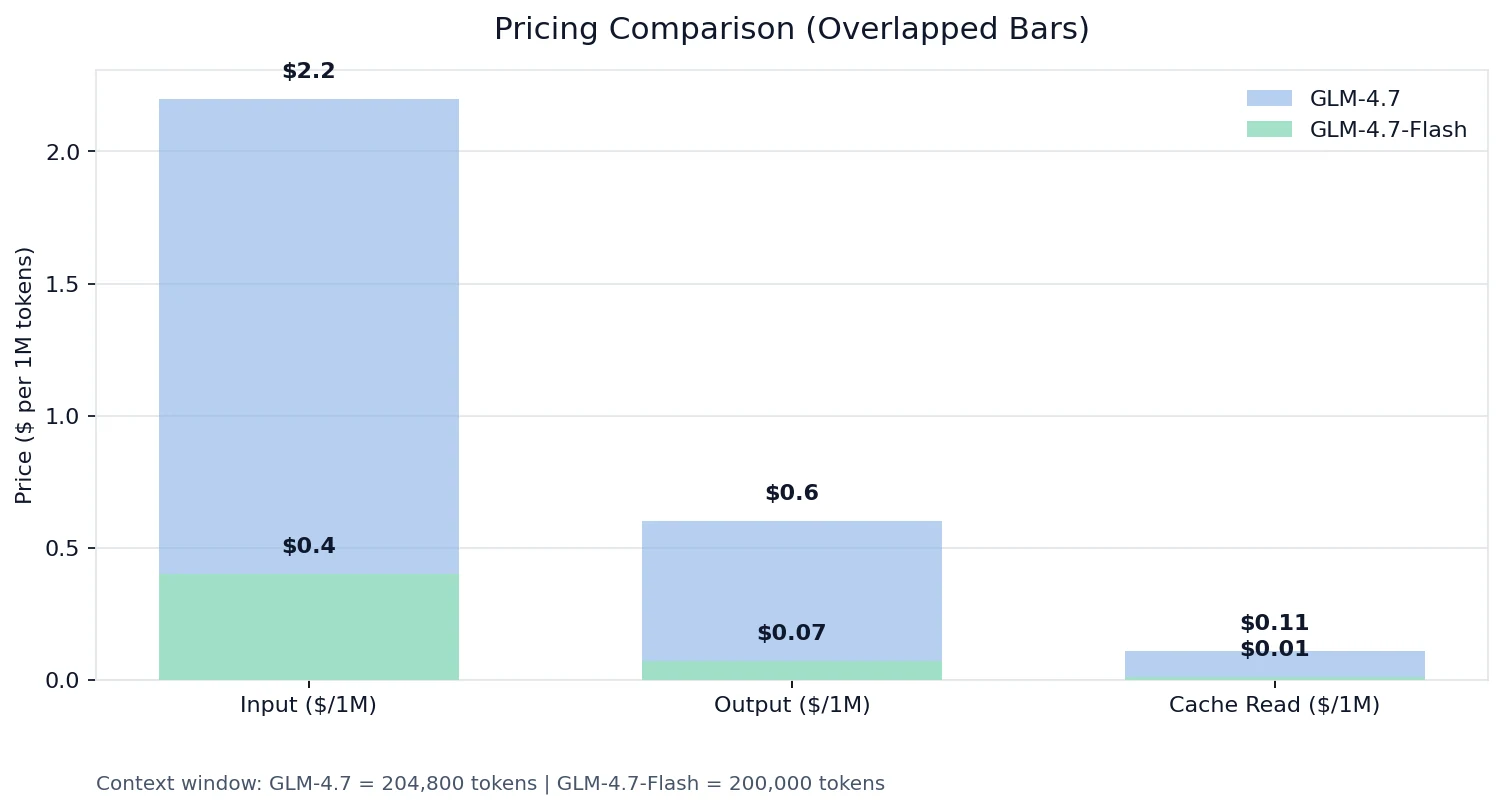
A realidade de “não estar no mesmo nível”
- Tokens de entrada: o GLM-4.7 é ~8,6× o Flash
- Tokens de saída: o GLM-4.7 é 5,5× o Flash
- Leitura de cache: o GLM-4.7 é 11× o Flash
Se você está construindo qualquer coisa com alto volume de solicitações, contexto longo ou esquemas de ferramentas que se repetem, a economia do Flash + o preço de leitura de cache pode alterar toda a sua curva de custos.
Quando usar cada modelo
O GLM-4.7 e o GLM-4.7-Flash não estão no mesmo nível — eles são construídos para alvos diferentes: GLM-4.7 = qualidade e raciocínio máximos, Flash = throughput escalável e economia por unidade.
Escolha o GLM-4.7 quando a qualidade é o produto
Use-o para:
- Raciocínio profundo / tarefas complexas: lógica de múltiplos passos, matemática, planejamento complexo, documentos de arquitetura e design
- Geração com foco em qualidade: redação longa, copy de marketing premium, tradução sensível ao tom
- Suporte a decisões de alto risco: decisões jurídicas/médicas/financeiras/de engenharia (ainda requer revisão humana)
Sinal de que é a escolha certa: se erros são caros, ou se você prefere pagar mais do que ter que reexecutar/reparar as saídas, escolha o GLM-4.7.
Escolha o GLM-4.7-Flash quando a escala é o produto
Use-o para:
- Tarefas do dia a dia: chat, perguntas e respostas básicas, reescrita, formatação, marcação/classificação, extração de informações
- Cargas de trabalho de alta concorrência: bots de suporte ao cliente, chat em tempo real, processamento em lote, chamadas de API de alta frequência
- Ambientes sensíveis a custo: MVPs, produtos com grande base de usuários, CI/testes, dev/staging
Sinal de que é a escolha certa: se você se importa com custo por solicitação, throughput e qualidade “boa o suficiente” em volume, escolha o Flash.
| Dimensão | Usar GLM-4.7 | Usar GLM-4.7-Flash |
| Complexidade da tarefa | Alta | Baixa a média |
| Tolerância a precisão | Rigorosa | Alguns erros são aceitáveis |
| Orçamento | Confortável | Controle de custo é fundamental |
| Concorrência | Baixa a média | Alta |
Início rápido: Teste ambos os modelos instantaneamente no Playground da Novita
A maneira mais rápida de sentir a diferença entre o GLM-4.7 e o GLM-4.7-Flash é o Playground da Novita AI — sem código, sem configuração.
No Playground, você pode:
- Alternar modelos instantaneamente entre
zai-org/glm-4.7ezai-org/glm-4.7-flash - Executar o mesmo prompt para comparar qualidade, estilo de raciocínio e velocidade de resposta
- Validar o formato do seu prompt (saídas JSON, no estilo de ferramenta) antes de migrar para a API
Prompts de teste recomendados
- Um prompt com muito raciocínio (para ver o limite do GLM-4.7)
- Um prompt de “operações” de alto volume (resumo / extração) para ver a praticidade e a adequação de custo do Flash
Playground da Novita AI
Opções de implantação: API, SDK, integrações de terceiros e implantação local
Opção A: API
Obtenha uma chave de API
- Passo 1: Crie ou faça login na sua conta
Acesse [**https://novita.ai**](https://novita.ai) e cadastre-se ou faça login na sua conta existente
- Passo 2: Acesse o gerenciamento de chaves
Depois de fazer login, encontre “Chaves de API”

- Passo 3: Crie uma nova chave
Clique no botão “Adicionar nova chave”.

- Passo 4: Salve sua chave imediatamente
Copie e armazene a chave assim que ela for gerada; geralmente ela é exibida apenas uma vez e não pode ser recuperada posteriormente. Guarde a chave em um local seguro, como um gerenciador de senhas ou notas criptografadas
API compatível com OpenAI (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # or "zai-org/glm-4.7"
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
Opção B: SDK
Se você está construindo fluxos de trabalho agentivos (roteamento, transferências, chamadas de ferramentas/funções), a Novita funciona com SDKs compatíveis com OpenAI com alterações mínimas:
- Compatível para uso imediato: mantenha a lógica do seu cliente existente; basta alterar o base_url + model
- Pronto para orquestração: fácil de implementar roteamento (padrão Flash → escalonamento para GLM-4.7)
- Configuração: aponte para
https://api.novita.ai/openai, defina aNOVITA_API_KEY, selecionezai-org/glm-4.7/zai-org/glm-4.7-flash
Opção C: Plataformas de terceiros
Você também pode executar os modelos GLM hospedados na Novita por meio de ecossistemas populares:
- Frameworks de agentes e construtores de aplicativos: Siga os guias de integração passo a passo da Novita para conectar-se a ferramentas populares como Continue, AnythingLLM, LangChain e Langflow.
- Hugging Face Hub: A Novita está listada como um Provedor de Inferência no Hugging Face, então você pode executar modelos suportados por meio do fluxo de trabalho e ecossistema de provedores do Hugging Face.
- API compatível com OpenAI: Os endpoints de LLM da Novita são compatíveis com o padrão de API da OpenAI, facilitando a migração de aplicativos existentes no estilo OpenAI e a conexão com muitas ferramentas compatíveis com OpenAI ( Cline, Cursor, Trae e Qwen Code) .
- API compatível com Anthropic: A Novita também fornece acesso compatível com o SDK da Anthropic para que você possa integrar modelos suportados pela Novita em fluxos de trabalho de codificação agentiva no estilo Claude Code.
- OpenCode: A Novita AI agora está integrada diretamente ao OpenCode como um provedor suportado, então os usuários podem selecionar a Novita no OpenCode sem configuração manual.
Opção D: Implantação local e privada
O GLM-4.7-Flash geralmente é a escolha mais prática para implantação local/privada porque é mais leve e fácil de executar em clusters on-premise, VPC /nuvens privadas e ambientes híbridos. Funciona especialmente bem para necessidades de conformidade/residência de dados, aplicativos internos sensíveis à latência e cargas de trabalho de contexto longo/agentivas com orçamentos de GPU fixos.
Uma configuração comum é:
- Executar o Flash localmente para tráfego de alto volume
- Escalonar para o GLM-4.7 (hospedado) para solicitações complexas ou de alto risco
O GLM-4.7 também pode ser implantado localmente, mas geralmente é reservado para equipes com grande capacidade de GPU e maturidade operacional, principalmente para sistemas internos críticos para qualidade e de baixo throughput. Para uso interno amplo, o Flash continua sendo a opção padrão.
💡Mesmo que executar o GLM-4.7 on-premise seja muito caro, você ainda pode usá-lo em produção por meio da API hospedada da Novita, ou executá-lo na infraestrutura de GPU da Novita para evitar o custo inicial de hardware e o ônus operacional.
Conclusão
A comparação entre GLM-4.7 e GLM-4.7-Flash não é uma disputa justa de “qual é melhor” — porque eles são construídos para trabalhos diferentes. Use o GLM-4.7 quando precisar do maior limite para raciocínio, codificação e confiabilidade agentiva. Use o GLM-4.7-Flash quando precisar de um modelo forte que você possa realmente escalar — econômico, implantável e altamente competitivo dentro da sua classe de eficiência.
O melhor padrão de produção geralmente é híbrido: use o Flash como padrão para volume e roteie solicitações complexas ou de alto risco para o GLM-4.7. Com o Playground da Novita e as APIs compatíveis com OpenAI, você pode testar ambos em minutos e implementar a estratégia de roteamento sem alterar sua stack.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.
Perguntas frequentes
O que é o GLM-4.7-Flash?
O GLM-4.7-Flash é um modelo de linguagem grande de classe 30B do tipo Mixture-of-Experts (MoE) desenvolvido pela Zhipu AI, projetado para oferecer desempenho forte em raciocínio, codificação e agentividade, com alta eficiência e baixa latência.
Quanto custa o GLM-4.7-Flash?
Na Novita AI (serverless), o GLM-4.7-Flash é precificado em $0,07/M por tokens de entrada, $0,01/M por tokens de leitura de cache e $0,40/M por tokens de saída, tornando-o econômico para cargas de trabalho de contexto grande e alto throughput.
Qual é a relação entre o GLM-4.7-Flash e o GLM-4.7?
O GLM-4.7-Flash e o GLM-4.7 pertencem à mesma família de modelos, mas visam níveis diferentes: o GLM-4.7 é o modelo de flagship otimizado para qualidade máxima de raciocínio, enquanto o GLM-4.7-Flash é uma variante mais leve e econômica, projetada para implantação escalável e de alto volume.



