

- Was du eigentlich vergleichst: Flaggschiff-Reasoning vs. skalierbare Effizienz
- Benchmark-Vergleich
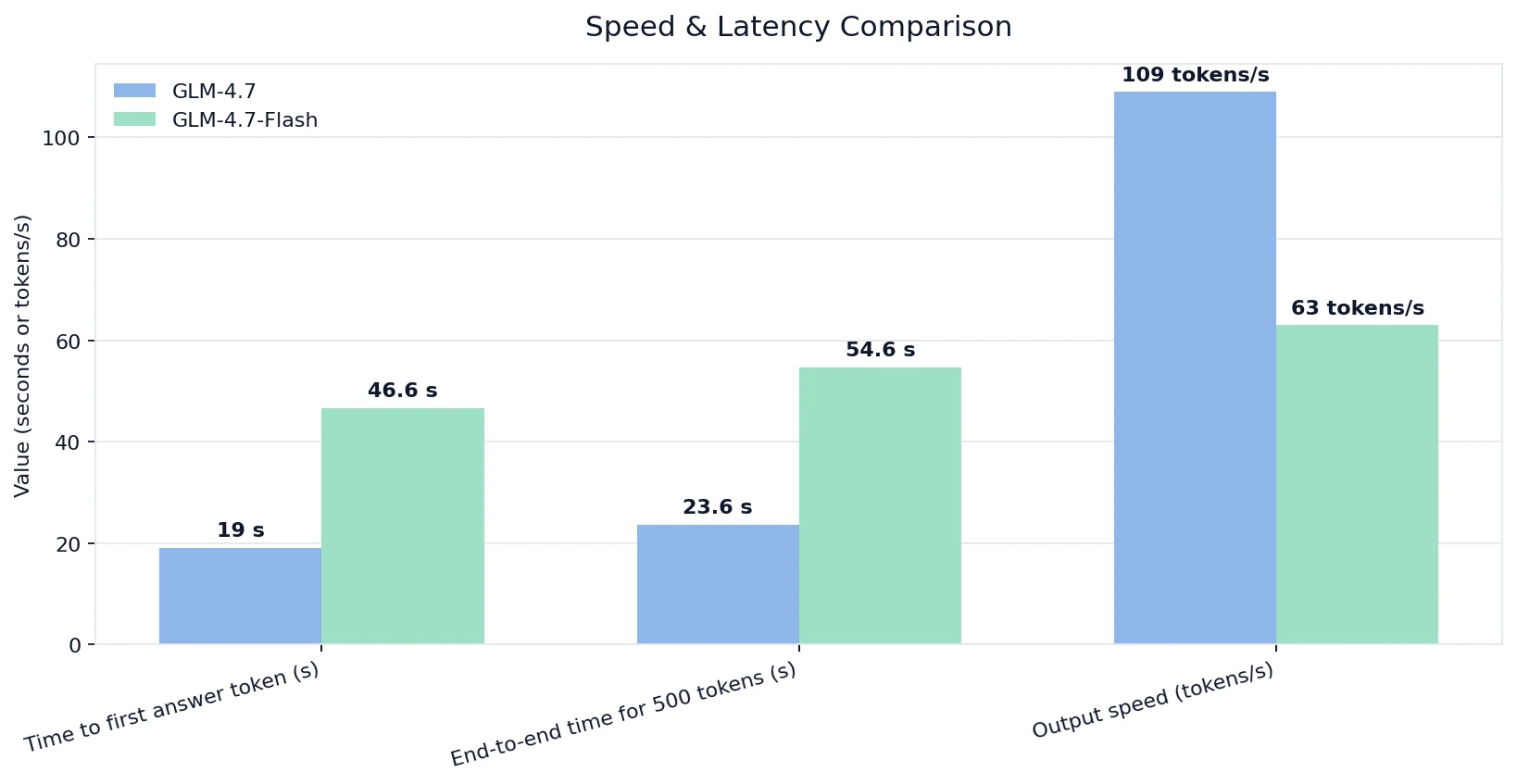
- Geschwindigkeits- und Latenzvergleich
- Preisvergleich
- Wann du welches Modell verwenden solltest
- Schnellstart: Teste beide Modelle sofort im Novita Playground
- Bereitstellungsoptionen: API, SDK, Drittanbieter-Integrationen und lokale Bereitstellung
- Fazit
Wenn du GLM-4.7 und GLM-4.7-Flash vergleichst, als wären sie austauschbar, optimierst du am Ende das Falsche.
Diese beiden Modelle sind nicht von Grund auf in der gleichen Leistungsklasse:
- GLM-4.7 ist ein Flaggschiff-Reasoning-Modell – du wählst es, wenn es dir auf maximale Qualität ankommt und du höhere Token-Kosten rechtfertigen kannst.
- GLM-4.7-Flash ist ein leichteres, kosteneffizientes „Arbeitstier“ – du wählst es, wenn es dir bei Skalierung auf Durchsatz, Stückkosten und praktische Langkontext-Nutzung ankommt.
Auf Novita kannst du beide mit transparenter Preisgestaltung, APIs und einem einfachen Playground schnell testen und entscheiden.
Was du eigentlich vergleichst: Flaggschiff-Reasoning vs. skalierbare Effizienz
GLM-4.7: Das Flaggschiff-Reasoning-Modell
GLM-4.7 ist als führendes Reasoning-first-Modell (starke allgemeine Intelligenz) positioniert, mit langem Kontext und schneller Generierung – es ist aber auch deutlich teurer pro Token als Flash.
GLM-4.7-Flash: Das skalierbare MoE-„Arbeitstier für Agenten/Coding“
GLM-4.7-Flash ist auf Effizienz ausgelegt (Klasse 30B-A3B MoE) und zielt auf agentisches Coding + Tool-Workflows sowie Langkontext-Aufgaben ab, bei denen du hohen Durchsatz und vorhersehbare Kosten brauchst.
Benchmark-Vergleich
Artificial Analysis Intelligence / Coding / Agentic-Indizes
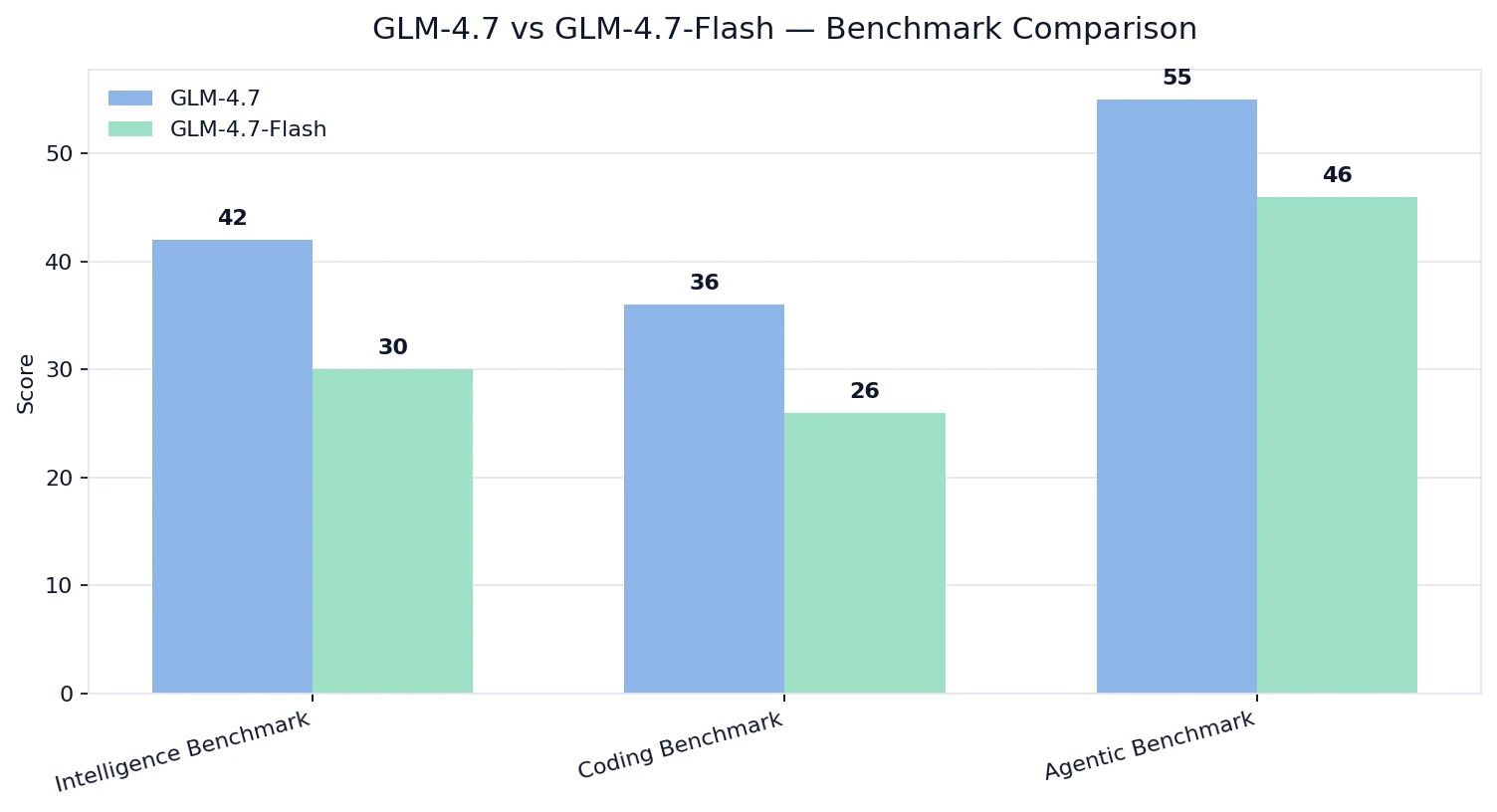
💡Interpretation:
- GLM-4.7 gewinnt bei der Qualität in den Bereichen Intelligenz, Coding und agentische Fähigkeiten.
- GLM-4.7-Flash ist trotzdem stark, aber es ist auf ein anderes Optimierungsziel abgestimmt: Kosten + Bereitstellbarkeit + praktischer Durchsatz.
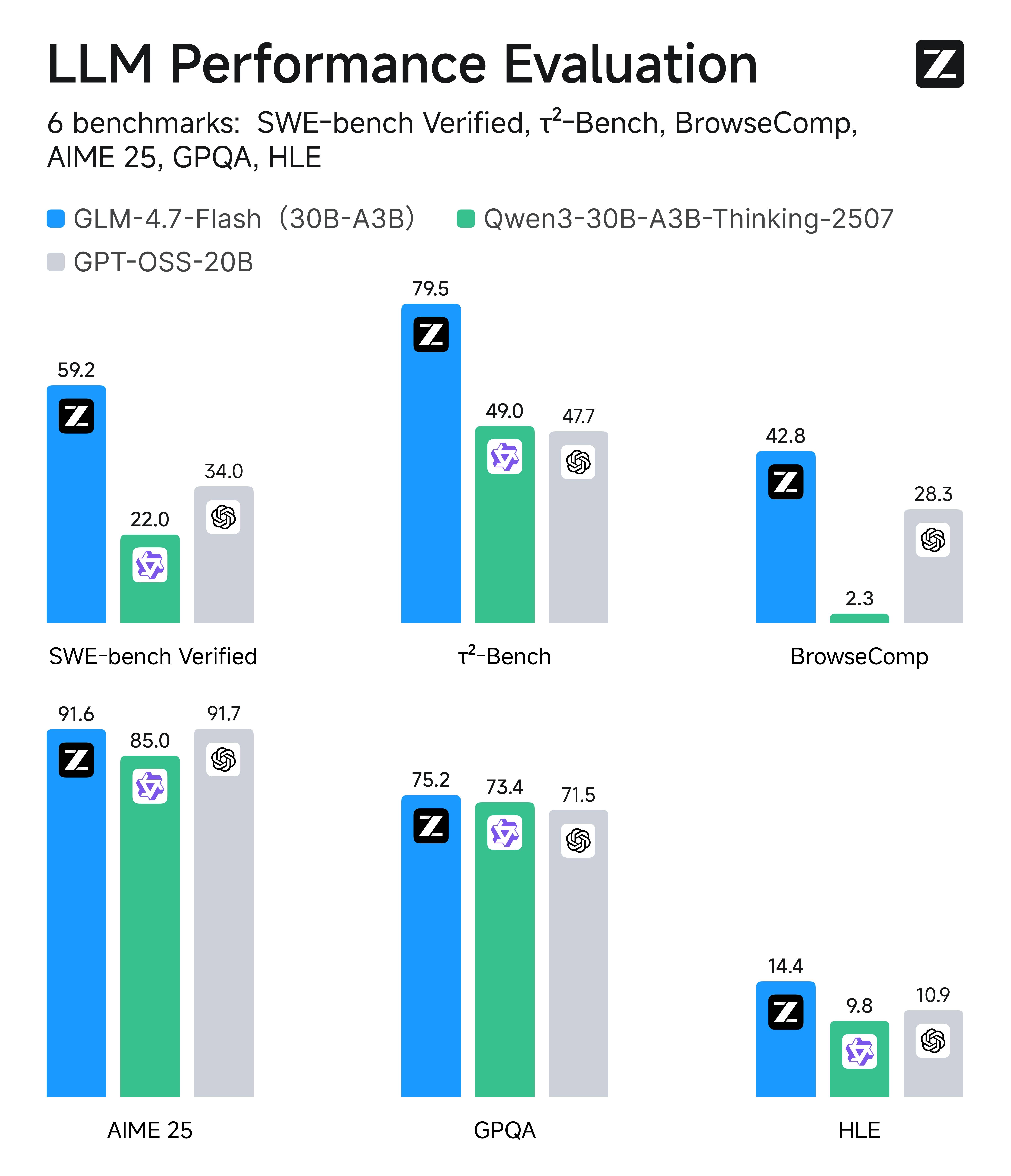
Spitzen-Effizienz: GLM-4.7-Flash im Vergleich zu gleichgroßen Konkurrenten
Was leicht übersehen wird: GLM-4.7-Flash ist ein Top-Performer in seiner eigenen Effizienzklasse (ca. 20B–30B MoE / leichte Modelle). In Vergleichen mit gleichgroßen Alternativen über sechs reale Evaluierungen – von Coding über Agenten/Tool-Nutzung, browsing-ähnliche Aufgaben, Mathematik bis hin zu Wissens-Reasoning – liegt Flash konsistent an der Spitze oder ganz oben unter den gleichgroßen Alternativen, was es genau zur Standardwahl für hochvolumige Produktionssysteme macht.
Geschwindigkeits- und Latenzvergleich
Preisvergleich
Auf den Novita-Preisen:
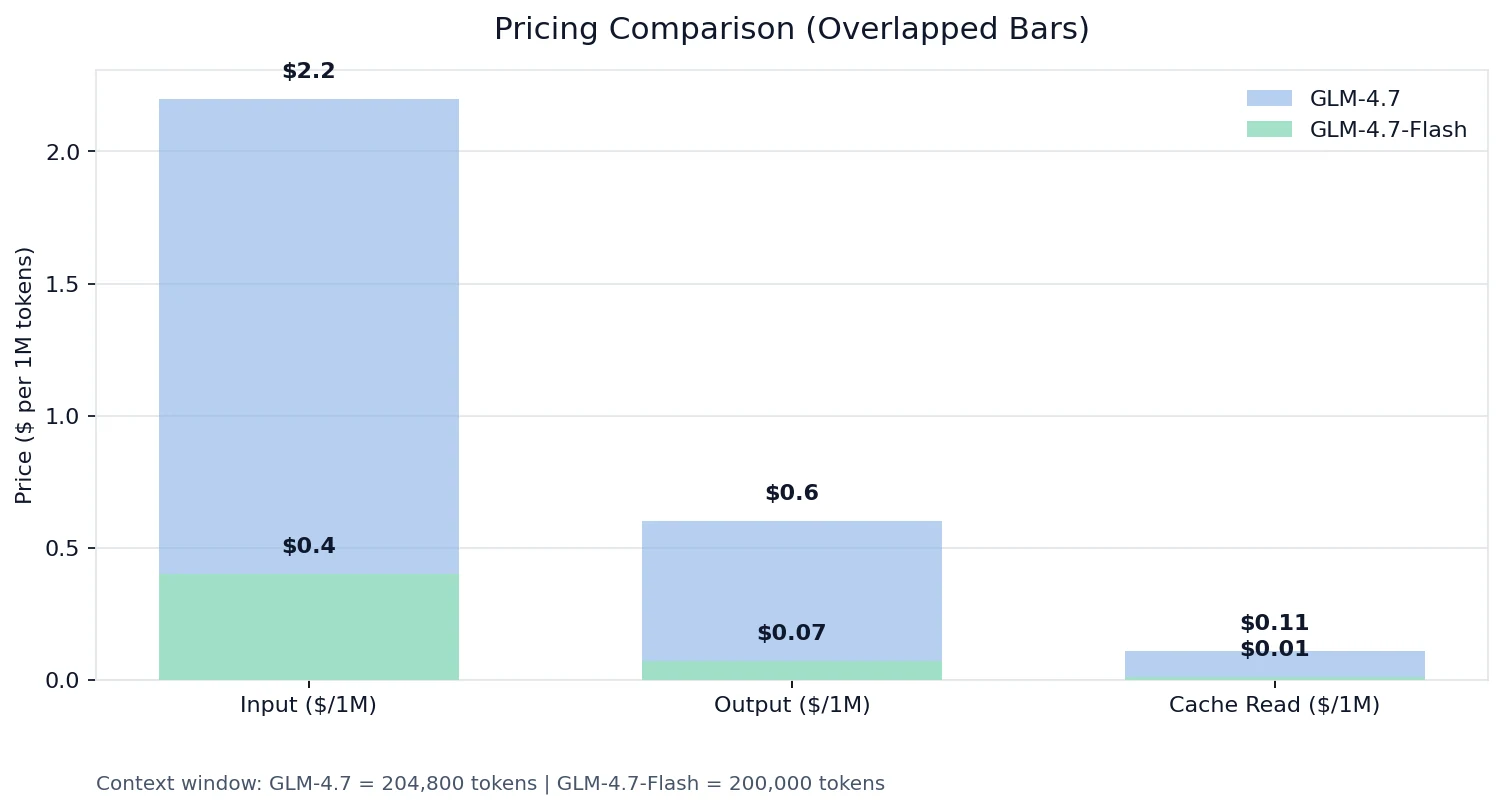
Die Realität: „Nicht die gleiche Leistungsklasse“
- Eingabe-Token: GLM-4.7 ist ~8,6× so teuer wie Flash
- Ausgabe-Token: GLM-4.7 ist 5,5× so teuer wie Flash
- Cache-Lesezugriffe: GLM-4.7 ist 11× so teuer wie Flash
Wenn du etwas mit hoher Anfrageanzahl, langem Kontext oder sich wiederholenden Tool-Schemas baust, können die Wirtschaftlichkeit von Flash + die Cache-Lesepreise deine gesamte Kostenkurve verändern.
Wann du welches Modell verwenden solltest
GLM-4.7 und GLM-4.7-Flash sind nicht die gleiche Leistungsklasse – sie sind für unterschiedliche Ziele ausgelegt: GLM-4.7 = maximale Qualität und Reasoning, Flash = skalierbarer Durchsatz und Stückkosten.
Wähle GLM-4.7, wenn Qualität das Produkt ist
Nutze es für:
- Tiefgehendes Reasoning / komplexe Aufgaben: mehrstufige Logik, Mathematik, anspruchsvolle Planung, Architektur- und Designdokumente
- Qualitätsorientierte Generierung: Langform-Texte, hochwertige Marketingtexte, ton-sensitive Übersetzungen
- Entscheidungsunterstützung mit hohen Risiken: rechtliche/medizinische/finanzielle/technische Entscheidungen (erfordert weiterhin menschliche Prüfung)
Gutes Kriterium: Wenn Fehler teuer sind, oder du lieber mehr zahlst, als Ausgaben neu generieren/reparieren zu müssen, wähle GLM-4.7.
Wähle GLM-4.7-Flash, wenn Skalierung das Produkt ist
Nutze es für:
- Alltägliche Aufgaben: Chat, einfache Q&A, Umschreiben, Formatierung, Tagging/Klassifizierung, Informationsextraktion
- Arbeitslasten mit hoher Gleichzeitigkeit: Kundensupport-Bots, Echtzeit-Chat, Batch-Verarbeitung, häufige API-Aufrufe
- Kostensensitive Umgebungen: MVPs, große Nutzerprodukte, CI/Testing, Dev/Staging
Gutes Kriterium: Wenn es dir auf Kosten pro Anfrage, Durchsatz und „ausreichend gute“ Qualität bei hohem Volumen ankommt, wähle Flash.
| Dimension | GLM-4.7 verwenden | GLM-4.7-Flash verwenden |
| Aufgabenkomplexität | Hoch | Niedrig bis mittel |
| Genauigkeitstoleranz | Streng | Einige Fehler akzeptabel |
| Budget | Komfortabel | Kostenkontrolle ist entscheidend |
| Gleichzeitigkeit | Niedrig bis mittel | Hoch |
Schnellstart: Teste beide Modelle sofort im Novita Playground
Der schnellste Weg, den Unterschied zwischen GLM-4.7 und GLM-4.7-Flash zu spüren, ist das Novita AI Playground – kein Code, keine Einrichtung.
Im Playground kannst du:
- Modelle sofort wechseln zwischen
zai-org/glm-4.7undzai-org/glm-4.7-flash - Den gleichen Prompt ausführen, um Qualität, Reasoning-Stil und Antwortgeschwindigkeit zu vergleichen
- Dein Prompt-Format (JSON, Tool-ähnliche Ausgaben) validieren, bevor du zur API wechselst
Empfohlene Test-Prompts
- Ein reasoning-schwerer Prompt (um die Leistungsgrenze von GLM-4.7 zu sehen)
- Ein hochvolumiger „Ops“-Prompt (Zusammenfassung / Extraktion), um die Praktikabilität und Kostenpassung von Flash zu sehen
Novita AI Playground
Bereitstellungsoptionen: API, SDK, Drittanbieter-Integrationen und lokale Bereitstellung
Option A: API
API-Schlüssel abrufen
- Schritt 1: Konto erstellen oder anmelden
Besuche [**https://novita.ai**](https://novita.ai) und registriere dich oder melde dich mit deinem bestehenden Konto an
- Schritt 2: Zum Schlüsselverwaltung navigieren
Nach der Anmeldung findest du „API-Schlüssel“

- Schritt 3: Einen neuen Schlüssel erstellen
Klicke auf die Schaltfläche „Neuen Schlüssel hinzufügen“.

- Schritt 4: Speichere deinen Schlüssel sofort
Kopiere und speichere den Schlüssel, sobald er generiert wird; er wird normalerweise nur einmal angezeigt und kann später nicht wieder abgerufen werden. Bewahre den Schlüssel an einem sicheren Ort auf, z. B. in einem Passwort-Manager oder verschlüsselten Notizen
OpenAI-kompatible API (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # or "zai-org/glm-4.7"
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
Option B: SDK
Wenn du agentische Workflows (Routing, Übergaben, Tool/Funktionsaufrufe) baust, funktioniert Novita mit OpenAI-kompatiblen SDKs mit minimalen Änderungen:
- Drop-in kompatibel: Behalte deine bestehende Client-Logik; ändere nur base_url + model
- Orchestrierungsbereit: Einfach zu implementierendes Routing (Standard: Flash → Eskalation zu GLM-4.7)
- Einrichtung: Zeige auf
https://api.novita.ai/openai, setzeNOVITA_API_KEY, wählezai-org/glm-4.7/zai-org/glm-4.7-flash
Option C: Drittanbieter-Plattformen
Du kannst auch von Novita gehostete GLM-Modelle über beliebte Ökosysteme ausführen:
- Agent-Frameworks & App-Builder: Folge Novitas Schritt-für-Schritt-Integrationsanleitungen, um beliebte Tools wie Continue, AnythingLLM, LangChain und Langflow anzubinden.
- Hugging Face Hub: Novita ist als Inferenz-Anbieter auf Hugging Face gelistet, sodass du unterstützte Modelle über den Anbieter-Workflow und das Ökosystem von Hugging Face ausführen kannst.
- OpenAI-kompatible API: Novitas LLM-Endpunkte sind kompatibel mit dem OpenAI-API-Standard, sodass du bestehende OpenAI-Apps einfach migrieren und viele OpenAI-kompatible Tools anbinden kannst ( Cline, Cursor , Trae und Qwen Code) .
- Anthropic-kompatible API: Novita bietet auch Anthropic SDK-kompatiblen Zugriff, sodass du von Novita unterstützte Modelle in agentische Coding-Workflows im Stil von Claude Code integrieren kannst.
- OpenCode: Novita AI ist jetzt direkt als unterstützter Anbieter in OpenCode integriert, sodass Nutzer Novita in OpenCode ohne manuelle Konfiguration auswählen können.
Option D: Lokale und private Bereitstellung
GLM-4.7-Flash ist normalerweise die praktischere Wahl für lokale/private Bereitstellung, da es leichter ist und einfacher auf On-Prem-Clustern, VPC /privaten Clouds und hybriden Umgebungen ausgeführt werden kann. Es eignet sich besonders für Compliance-/Data-Residency-Anforderungen, latenzempfindliche interne Apps und Langkontext-/agentische Arbeitslasten mit festen GPU-Budgets.
Ein häufiges Setup ist:
- Flash lokal ausführen für hochvolumigen Datenverkehr
- Zu GLM-4.7 (gehostet) eskalieren für komplexe oder risikoreiche Anfragen
GLM-4.7 kann auch lokal bereitgestellt werden, ist aber normalerweise Teams mit hoher GPU-Kapazität und operativer Reife vorbehalten, hauptsächlich für qualitätskritische, niedrig-durchsatzige interne Systeme. Für breite interne Nutzung bleibt Flash die Standardwahl.
💡Selbst wenn die Ausführung von GLM-4.7 on-prem zu kostspielig ist, kannst du es weiterhin in Produktion über Novitas gehostete API nutzen oder auf Novitas GPU-Infrastruktur ausführen, um die anfänglichen Hardware- und Betriebskosten zu vermeiden.
Fazit
Der Vergleich zwischen GLM-4.7 und GLM-4.7-Flash ist kein fairer „Welches ist besser“-Wettbewerb – denn sie sind für unterschiedliche Einsatzzwecke ausgelegt. Nutze GLM-4.7, wenn du die höchste Leistungsgrenze für Reasoning, Coding und agentische Zuverlässigkeit brauchst. Nutze GLM-4.7-Flash, wenn du ein starkes Modell brauchst, das du tatsächlich skalieren kannst – kosteneffizient, bereitstellbar und hochgradig wettbewerbsfähig in seiner Effizienzklasse.
Das beste Produktionsmuster ist normalerweise hybrid: Standardmäßig Flash für hohes Volumen nutzen und komplexe oder risikoreiche Anfragen an GLM-4.7 weiterleiten. Mit Novitas Playground und OpenAI-kompatiblen APIs kannst du beide in Minuten testen und die Routing-Strategie ausliefern, ohne deinen Stack zu ändern.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.
Häufig gestellte Fragen
Was ist GLM-4.7-Flash?
GLM-4.7-Flash ist ein Large Language Model der 30B-Klasse mit Mixture-of-Experts (MoE)-Architektur, entwickelt von Zhipu AI. Es wurde entwickelt, um starke Reasoning-, Coding- und agentische Leistung bei hoher Effizienz und niedriger Latenz zu liefern.
Wie viel kostet GLM-4.7-Flash?
Auf Novita AI (serverless) liegt der Preis für GLM-4.7-Flash bei $0,07/M Eingabe-Token, $0,01/M gelesene Cache-Token und $0,40/M Ausgabe-Token, was es kosteneffizient für Arbeitslasten mit großem Kontext und hohem Durchsatz macht.
Wie ist das Verhältnis zwischen GLM-4.7-Flash und GLM-4.7?
GLM-4.7-Flash und GLM-4.7 gehören zur gleichen Modellfamilie, zielen aber auf unterschiedliche Leistungsklassen ab: GLM-4.7 ist das Flaggschiff-Modell, optimiert für maximale Reasoning-Qualität, während GLM-4.7-Flash eine leichtere, kosteneffiziente Variante ist, die für skalierbare, hochvolumige Bereitstellung ausgelegt ist.



