

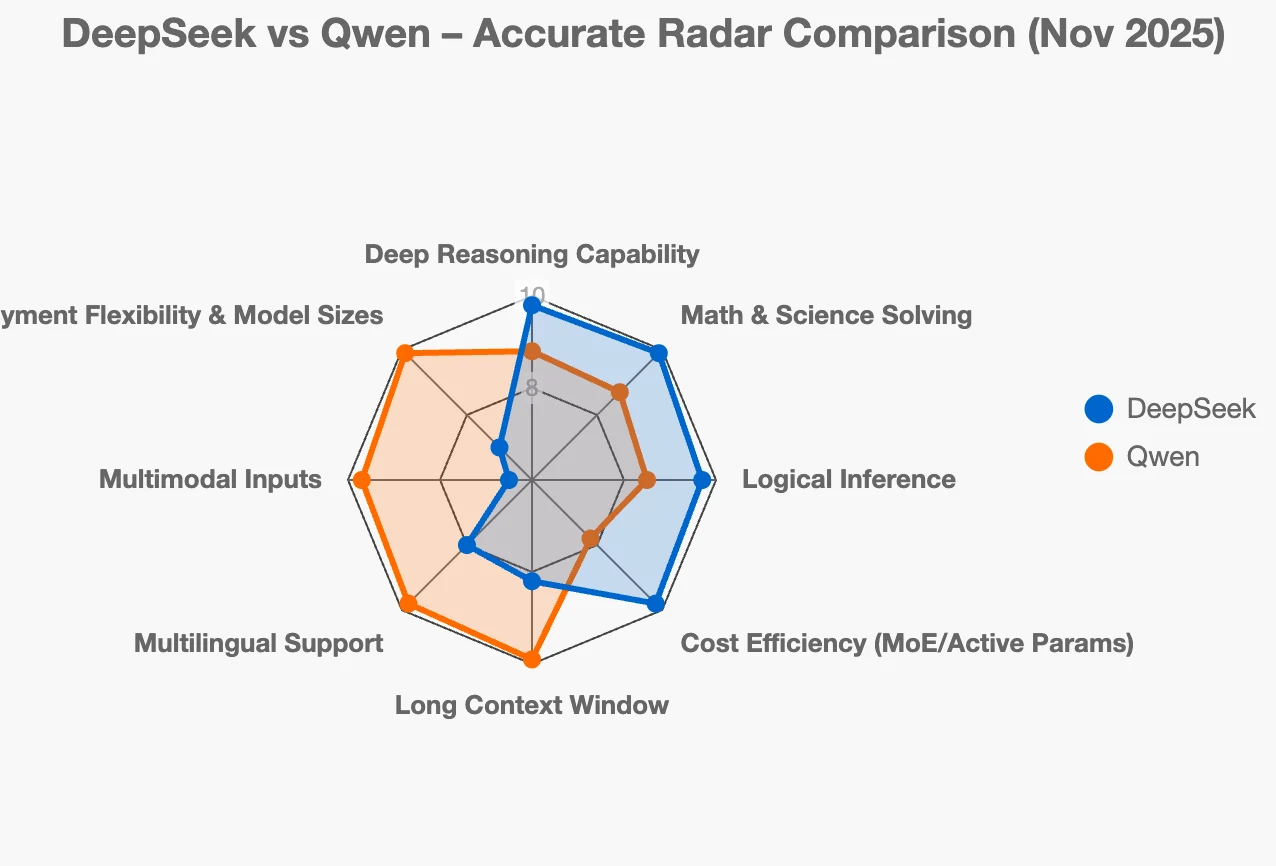
Die meisten Nutzer, die DeepSeek und Qwen vergleichen, sind verwirrt, denn beide Ökosysteme sind leistungsstark, quelloffen und schnell weiterentwickelt – und doch wurden sie entwickelt, um völlig unterschiedliche Probleme zu lösen. DeepSeek konzentriert sich auf tiefgehende Schlussfolgerung, Stabilität der Gedankenketten (Chain-of-Thought), Genauigkeit bei Mathematik/Programmierung und MoE-basierte Effizienz, während die Qwen-Familie auf Full-Stack-Bereitstellung setzt und alles von riesigen MoE-Modellen bis hin zu winzigen Edge-Modellen sowie multimodale Funktionen, RAG, Embeddings, Programmierfunktionen und unternehmensreife Tools abdeckt.
Dieser Artikel klärt diese Unterschiede auf, indem er die Flaggschiff-Modelle, destillierten Varianten, effizienten Serien, RAG-Modelle und Hardware-Anforderungen beider Ökosysteme untersucht. So können Nutzer verstehen, welches Ziel jedes Ökosystem tatsächlich verfolgt und welches zu ihren betrieblichen Anforderungen passt.
Was verfolgen DeepSeek und Qwen eigentlich wirklich?
Wenn Sie sich fragen, welches quelloffene chinesische LLM-Ökosystem zu Ihren Anforderungen passt, sind die beiden größten Akteure derzeit die DeepSeek- und die Qwen-Familie. Beide sind äußerst leistungsstark, lösen aber unterschiedliche Probleme und verfolgen unterschiedliche Richtungen.
DeepSeek: „Wir wollen Modelle, die wirklich tiefgehend denken können“
Betrachten Sie DeepSeek als den „Schlussfolgerungsspezialisten“.
Was ihnen am wichtigsten ist:
- Modelle zu entwickeln, die wirklich gut im harten, schrittweisen Denken sind – bei mathematischen Beweisen, wissenschaftlichen Problemen, komplexer Programmierung und logischen Rätseln.
- Die Grenzen der Schlussfolgerung mit Gedankenketten (Chain-of-Thought, CoT) zu verschieben, sodass das Modell nicht nur intelligent klingt … sondern das Problem tatsächlich korrekt löst und seinen Lösungsweg nachvollziehbar machen kann.
- Clevere Techniken wie Mixture-of-Experts (MoE) + Reinforcement Learning (RL) einzusetzen, sodass das Modell leistungsstark ist, ohne für jedes einzelne Token Milliarden von Parametern aktivieren zu müssen (das macht Inferenz günstiger und schneller).
- Kleinere „destillierte“ Versionen ihrer besten Schlussfolgerungsmodelle zu veröffentlichen, damit normale Nutzer und kleinere Unternehmen diese tatsächlich ausführen können.
Die praktischen Probleme, die sie angehen:
- Die meisten riesigen Modelle sind großartig darin, Aufsätze zu schreiben, scheitern aber immer noch an einfachen Mathematik- oder Logikfragen. DeepSeek will das beheben.
- Größer ist nicht immer besser für Schlussfolgerungen – sie versuchen, mehr Schlussfolgerungskraft aus weniger aktiven Parametern zu holen (mehr Leistung für Ihr GPU-Budget).
- Hochwertige Schlussfolgerungsmodelle sind außerhalb großer Labore normalerweise zu teuer in der Ausführung. DeepSeek will diese Fähigkeit demokratisieren.
- Wenn Sie benötigen, dass das Modell erklärt, wie es zu einer Antwort gekommen ist (z. B. in Recht, Medizin, Bildung), möchten Sie eine nachvollziehbare Gedankenkette – DeepSeek macht das besonders gut.
Ideal für: Forschung, Bildung, Programmierassistenten, Mathematik-/Wissenschaftstools, alle Situationen, in denen „die richtige Antwort finden + den Lösungsweg nachvollziehbar machen“ wichtiger ist als ein allgemeiner Chatbot.
Qwen: „Wir wollen eine vollständige Werkzeugkiste für echte Unternehmen“
Qwen ist eher das „Schweizer Taschenmesser“ unter den LLMs.
Was ihnen am wichtigsten ist:
- Jede Größe und Ausprägung anzubieten, die Sie benötigen: winzige Modelle für Handys, mittlere für Server, riesige für maximale Leistung, dichte oder MoE-Versionen, Vision-Modelle, Programmiermodelle, Embedding-Modelle, Reranker-Modelle … Sie nennen es.
- Starke mehrsprachige Leistung (insbesondere Chinesisch + über 100 weitere Sprachen).
- Sehr lange Kontextfenster (bis zu 128k oder sogar 1M Token in einigen Versionen).
- Unternehmensreife Bereitstellung: einfache API, On-Prem-Optionen, Edge-Geräte-Unterstützung, Sicherheits- und Tooling auf Unternehmensniveau.
Die praktischen Probleme, die sie angehen:
- Unternehmen wollen nicht nur einen Chatbot – sie benötigen Dokumentenverständnis, Suche, Retrieval-Augmented Generation (RAG), Bild+Text-Apps, mehrsprachigen Kundensupport usw. Qwen bietet den gesamten Stack.
- Ältere Modelle haben Probleme mit langen Dokumenten oder versagen, wenn Sie die Sprache wechseln. Qwen meistert beides problemlos.
- Oft benötigen Sie winzige Modelle für Mobile/Edge und riesige Modelle für aufwändige Analysen – Qwen bietet Ihnen eine nahtlose Skalierung der Größen, sodass Sie nie feststecken.
- Der Aufbau eines ordentlichen Unternehmenssuch- oder Wissensdatenbanksystems erfordert hervorragende Embeddings + Reranking. Qwen Embedding- und Reranker-Modelle gehören zu den besten, die es quelloffen gibt.
Ideal für: Unternehmenssuchmaschinen, mehrsprachige Kundenservice-Bots, dokumentenlastige Workflows, RAG-Pipelines, Apps, die Vision + Text kombinieren, oder jedes Produktionssystem, bei dem Zuverlässigkeit und einfache Bereitstellung wichtig sind.
Welches sollten Sie also wählen?
- Wenn Ihr Projekt von logischer Schlussfolgerung, Mathematik oder Programmiergenauigkeit abhängt → wählen Sie DeepSeek (insbesondere DeepSeek-R1 oder die neuen DeepSeek-V3-Schlussfolgerungsmodelle).
- Wenn Sie ein echtes Produkt mit Suche, langen Dokumenten, mehreren Sprachen, Bildern entwickeln oder Modelle von 0,5B bis 72B benötigen → wählen Sie Qwen.
Probieren Sie Modelle jetzt aus!
DeepSeek-Modellökosystem
Die DeepSeek-Modelle konzentrieren sich in erster Linie auf die Maximierung der Schlussfolgerungskraft durch groß angelegte Mixture-of-Experts (MoE)-Architekturen und intensive Reinforcement Learning (RL)-Pipelines. Daraus resultieren präzise, leistungsstarke Modelle (671B–685B) und spezialisierte kleinere Versionen (Distill-Modelle).
DeepSeek-Flaggschiff-Modelle
Hier finden Sie detaillierte Architekturzusammenfassungen jeder DeepSeek-Modellvariante:
| Variante | Gesamtparameter / Aktivierte Parameter | Kontextfenster | Wichtige Architektur & Erweiterungen |
|---|---|---|---|
| DeepSeek V3 | 671B gesamt, 37B aktiv pro Token | 128K Token | Mixture-of-Experts (MoE)-Architektur; verwendet Multi-Head Latent Attention (MLA) zur Reduzierung der KV-Cache-Größe; verwendet Multi-Token Prediction (MTP)-Ziel; verwendet lastenausgleich ohne Hilfsverluste. |
| DeepSeek R1 | 671B gesamt, 37B aktiv pro Token |
128K Token | Gleiche Basisarchitektur wie V3 (MoE + MLA), aber mit intensiver RL-Pipeline (SFT → RL → SFT → RL) zur Verbesserung der Schlussfolgerungs-/Logikfähigkeiten. |
| DeepSeek V3.1 | 671B gesamt, 37B aktiv pro Token |
128K Token | Hybride Inferenzmodi: unterstützt „Think“- (Gedankenkette) und „Non-Think“-Modi; kombiniert die allgemeine Fähigkeit von V3 mit der Schlussfolgerungsstärke von R1; erweitertes Langkontext-Training. |
| DeepSeek R1 0528 | 685B Gesamtparameter (aktive Teilmenge nicht angegeben) | 64K Token | Aktualisierte R1-Version mit höherer Parameteranzahl und reduziertem Kontextfenster auf ~64K für verbesserte Inferenzgeschwindigkeit/Stabilität (statt volle 128K). (Daten aus Variantenauflistung) |
| DeepSeek V3 0324 | 671B gesamt, 37B aktiv pro Token | 128K Token | Gleiche Architektur wie V3, aber optimiert für mehrsprachige Verarbeitung (insbesondere Chinesisch), erweiterte Funktionsaufrufe, verbesserte Anwendungsfälle für Frontend/Webentwicklung. |
DeepSeek-Destillierte Modelle
Übertragen Sie die Schlussfolgerungsfähigkeit von DeepSeek (Logik, Mathematik, schrittweises Denken, CoT-Stabilität) auf kleinere, dichte Modelle, die günstiger, schneller sind und auf Consumer-GPUs ausgeführt werden können.
| Destilliertes Modell | Basis-Modell | Verbesserte Fähigkeiten |
|---|---|---|
| R1-Distill Qwen 32B | Qwen 2.5–32B | Starke CoT, bessere Logikstabilität, verbesserte mehrsprachige Schlussfolgerung |
| R1-0528 Qwen3 8B | Qwen3 8B | Hohe Schlussfolgerungsgenauigkeit (AIME 86 %), effiziente CoT, schnelle Inferenz |
| R1-Distill Qwen 7B | Qwen 2.5 Math-7B | Außergewöhnliche Mathematikgenauigkeit (MATH-500 92,8 %), strukturiertes schrittweises Denken |
| R1-Distill Llama 8B | Llama-8B | Bessere Anweisungsbefolgung + kompaktes Schlussfolgerungsverhalten |
| R1-Distill Llama 70B | Llama-70B | Starke allgemeine Schlussfolgerung, stabile Langform-CoT, konsistente Ausgaben |
Probieren Sie Modelle jetzt aus!
Qwen-Modellökosystem
Die Qwen-Familie (Qwen 2.5 und Qwen 3) bietet eine äußerst flexible Palette von Modellen von 0,6B bis 480B Parametern, mit Schwerpunkt auf mehrsprachiger Unterstützung, umfangreicher Kontextverarbeitung und spezialisierten Varianten für Programmierung, Embeddings und multimodale Aufgaben.
Qwen-Flaggschiff-Modelle
| Variante | Gesamtparameter / Aktive Parameter | Kontextfenster | Hauptfokus / Funktionen |
|---|---|---|---|
| Qwen3-Coder 480B-A35B-Instruct | 480B / 35B (MoE) | 256K nativ, erweiterbar auf ~1M Token | Agentische Programmierung und Verständnis von Multi-Datei-Repositories; Funktionsaufruf/Tool-Nutzung optimiert; nur Non-Think-Modus |
| Qwen3-VL-235B-A22B | 235B / 22B (MoE) | 256K nativ (erweiterbar auf ~1M) | Multimodales Vision-Sprache-Modell (Bilder/Videos); glänzt bei visuell-zu-Code, 3D-Schlussfolgerung, OCR; verfügt über Instruct/Thinking-Varianten |
| Qwen3 32B | 32B / dicht | 128K Token | Allgemeine Schlussfolgerung + mehrsprachige Unterstützung; dichter Backbone für kostengünstigere Bereitstellung |
| Qwen2.5-72B Instruct | 72B (Dichte oder MoE-Variante) | 128K Token | Starke mehrsprachige Unterstützung (29+ Sprachen); |
Qwen 3 Effiziente Modelle
Die Qwen 3-Serie umfasst eine umfassende Reihe kleinerer Modelle, die alle die hocheffizienten „Hybriden Denkmodi“ (Denken vs. Nicht-Denken) und breite mehrsprachige Unterstützung (119 Sprachen) unterstützen.
| Variante | Gesamtparameter | Kontextfenster | Hauptfokus / Funktionen |
|---|---|---|---|
| Qwen3-14B | 14,8B | 32.768 Token nativ; erweiterbar auf 131.072 | Leistungsstarkes Mid-Size-Modell für allgemeine Zwecke; unterstützt „Denken“- und „Nicht-Denken“-Modi; mehrsprachige und agentische Fähigkeiten |
| Qwen3-8B | 8,19B | 128K Token | Leichtgewichtiges Schlussfolgerungsmodell; wettbewerbsfähig bei Mathematik- und allgemeinen Schlussfolgerungsaufgaben |
| Qwen3-4B | 4,0B | 32K Token nativ (erweiterbar) | Optimiert für Effizienz; Bereitstellungen mit geringen Ressourcen, bei gleichzeitig starker Leistung |
| Qwen3-1.7B | 1,7B | 32K Token | Geeignet für Edge-Nutzung / schnelle Chatbots; minimaler Ressourcenbedarf |
| Qwen3-0.6B | 0,6B | 32K Token | Ultraleichtes Modell für Bereitstellungen mit hoher Parallelität / On-Device |
Qwen 3 RAG-Modelle
Die Qwen3-Embedding-Reihe spiegelt die Erkenntnis wider, dass Abruf + Embeddings + retrieval-augmentierte Workflows zentral für moderne KI-Anwendungen (Suche, QA, RAG, Code) sind.
| Variante | Gesamtparameter / Aktiv | Kontextfenster | Hauptfokus / Funktionen |
|---|---|---|---|
| Qwen3-Embedding 8B | 8B | 32K Token | Text-Embedding-Modell; mehrsprachig (>100 Sprachen); Unterstützung langer Eingaben; konfigurierbare Embedding-Dimensionen bis 4096; glänzt im MTEB-Benchmark (70,58) |
| Qwen3-Reranker 8B | 8B | 32K Token | Cross-Encoder-Reranking-Modell; sortiert abgerufene Dokumente nach Relevanz in RAG-Pipelines; hohe Präzision bei mehrsprachigem Abruf |
Probieren Sie Modelle jetzt aus!
Wie können Sie DeepSeek und Qwen günstig und schnell nutzen?
1. Weboberfläche (Am einfachsten für Einsteiger)
Probieren Sie Modelle jetzt aus!
2. API-Zugriff (Für Entwickler)
Schritt 1: Melden Sie sich an und greifen Sie auf die Modellbibliothek zu
Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Probieren Sie Modelle jetzt aus!
Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completion-API für Python-Nutzer.
3. Lokale Bereitstellung (Für fortgeschrittene Nutzer)
| Modell | Gesamter VRAM (FP16-Inferenz) | Minimale Consumer-Konfiguration |
|---|---|---|
| DeepSeek-V3 / R1 / V3.1 671B MoE | ~780–820 GB | 8× RTX 4090 (24 GB) nur mit schwerem Offloading knapp möglich |
| DeepSeek-R1-0528 685B | ~800–850 GB | 8× H100 80 GB (knapp) |
| DeepSeek-V3-0324 671B | ~780–820 GB | 8× RTX 4090 (24 GB) nur mit schwerem Offloading knapp möglich |
| Modell | Quantisierung | Erforderlicher VRAM | Machbare Consumer-Konfiguration |
|---|---|---|---|
| DeepSeek-R1/V3 671B | 4-Bit (NF4/GPTQ/AWQ) | 170–190 GB | 8× RTX 4090 oder 4× H100 80 GB |
| DeepSeek-R1/V3 671B | INT8 | 340–380 GB | 6–8× RTX 4090 oder 4× A100/H100 80 GB |
| Modell | VRAM (FP16) | Kompatible Consumer-GPU |
|---|---|---|
| R1-Distill-Qwen-32B | 64 GB | 2× RTX 4090 |
| R1-0528-Qwen3-8B / Llama-8B | 16 GB | 1× RTX 4090 / 3090 Ti |
| R1-Distill-Qwen-7B Math | 14 GB | 1× RTX 4080/4090 |
| R1-Distill-Llama-70B | 140 GB | 4× RTX 4090 oder 2× A100 80 GB |
| Modell | Gesamter VRAM (FP16/BF16) | Minimale Consumer-Konfiguration |
|---|---|---|
| Qwen3-Coder 480B MoE | 560–600 GB (35B aktiv) | 8× H100 80 GB |
| Qwen3-VL-235B MoE | 280–320 GB (22B aktiv) | 4× H100 80 GB |
| Qwen2.5-72B / Qwen3-32B Dicht | 140–160 GB | 4× RTX 4090 oder 2× A100 80 GB |
| Qwen3-14B | 28–32 GB | 1× RTX 4090 |
| Qwen3-8B | 16–18 GB | 1× RTX 4080/4090 |
| Qwen3-4B | 8–10 GB | 1× RTX 4060 Ti / 4070 |
| Qwen3-1.7B & 0,6B | 4 GB | Mobiltelefone, RTX 3050 |
| Qwen3-Embedding / Reranker 8B | 16 GB | 1× RTX 4090 |
Installationsschritte:
- Laden Sie Modellgewichte von HuggingFace oder ModelScope herunter
- Wählen Sie ein Inferenz-Framework: vLLM oder SGLang werden unterstützt
- Befolgen Sie den Bereitstellungshandbuch im offiziellen GitHub-Repository
4. Integration
Nutzung von CLIs wie Trae, Claude Code, Qwen Code
Wenn Sie die Top-Modelle von Novita AI (wie Qwen3-Coder, Kimi K2, DeepSeek R1) für KI-Programmierunterstützung in Ihrer lokalen Umgebung oder IDE nutzen möchten, ist der Prozess einfach: Holen Sie sich Ihren API-Schlüssel, installieren Sie das Tool, konfigurieren Sie Umgebungsvariablen und beginnen Sie zu programmieren.
Ausführliche Einrichtungbefehle und Beispiele finden Sie in den offiziellen Tutorials:
- Trae: Schritt-für-Schritt-Anleitung zum Zugriff auf KI-Modelle in Ihrer IDE
- Claude Code: So verwenden Sie Kimi-K2 in Claude Code unter Windows, Mac und Linux
- Qwen Code: So verwenden Sie die OpenAI-kompatible API in Qwen Code (60-Sekunden-Einrichtung!)
Multi-Agent-Workflows mit dem OpenAI Agents SDK
Erstellen Sie fortschrittliche Multi-Agent-Systeme durch Integration von Novita AI mit dem OpenAI Agents SDK:
- Plug-and-Play: Nutzen Sie die LLMs von Novita AI in jedem OpenAI Agents-Workflow.
- Unterstützt Übergaben, Routing und Tool-Nutzung: Entwerfen Sie Agenten, die delegieren, triagieren oder Funktionen ausführen können, alle angetrieben von den Modellen von Novita AI.
- Python-Integration: Setzen Sie einfach den SDK-Endpunkt auf
https://api.novita.ai/v3/openaiund verwenden Sie Ihren API-Schlüssel.
API auf Drittanbieterplattformen verbinden
OpenAI-kompatible API: Genießen Sie problemlose Migration und Integration mit Tools wie Cline und Cursor, die für den OpenAI-API-Standard entwickelt wurden.
Hugging Face: Nutzen Sie Modelle in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
Agent- und Orchestrierungs-Frameworks: Verbinden Sie Novita AI einfach mit Partnerplattformen wie Continue, AnythingLLM,LangChain, Dify und Langflow über offizielle Connectors und Schritt-für-Schritt-Integrationsanleitungen.
DeepSeek zielt auf maximale Schlussfolgerungskraft mit Modellen wie DeepSeek-V3, DeepSeek-R1 und DeepSeek-V3.1 ab, unterstützt durch leichtgewichtige Destillationen wie R1-Distill-Qwen-32B und R1-Distill-Qwen3-8B. Qwen strebt Vielseitigkeit und Unternehmensreife an mit Modellen wie Qwen3-Coder-480B-A35B-Instruct, Qwen3-VL-235B-A22B, effizienten Modellen von Qwen3-14B bis Qwen3-0.6B und RAG-orientierten Modellen wie Qwen3-Embedding-8B und Qwen3-Reranker-8B. Kurz gesagt: DeepSeek optimiert für tiefgehende Schlussfolgerungsleistung; Qwen optimiert für eine vollständige, bereitstellbare, mehrsprachige, multimodale KI-Werkzeugkiste.
Häufig gestellte Fragen
Was ist die Kernstärke von DeepSeek-V3 im Vergleich zu Qwen-Modellen?
DeepSeek-V3 verwendet eine MoE-Architektur mit MLA und MTP, um die Schlussfolgerungsqualität zu maximieren, während Qwen-Modelle sich stärker auf mehrsprachige Abdeckung, Bereitstellungsspektrum und Anwendungsvielfalt konzentrieren.
Warum sollte jemand DeepSeek-V3.1 statt Qwen3-14B wählen?
DeepSeek-V3.1 bietet hybride „Denken/Nicht-Denken“-Schlussfolgerungsmodi, die für die Tiefe der Gedankenkette optimiert sind, während Qwen3-14B allgemeine Inferenz, mehrsprachige Aufgaben und effiziente Bereitstellung priorisiert.
Welches Modellökosystem eignet sich besser für Workflows mit langen Dokumenten?
Qwen glänzt mit Modellen wie Qwen3-Coder-480B-A35B-Instruct und Qwen3-VL-235B-A22B, die Kontextfenster von bis zu 256K–1M Token bieten, während DeepSeek sich auf Schlussfolgerungen statt auf die Verarbeitung von ultralangen Dokumenten konzentriert.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine kostengünstige und zuverlässige GPU-Cloud für Aufbau und Skalierung bereitstellt.



