

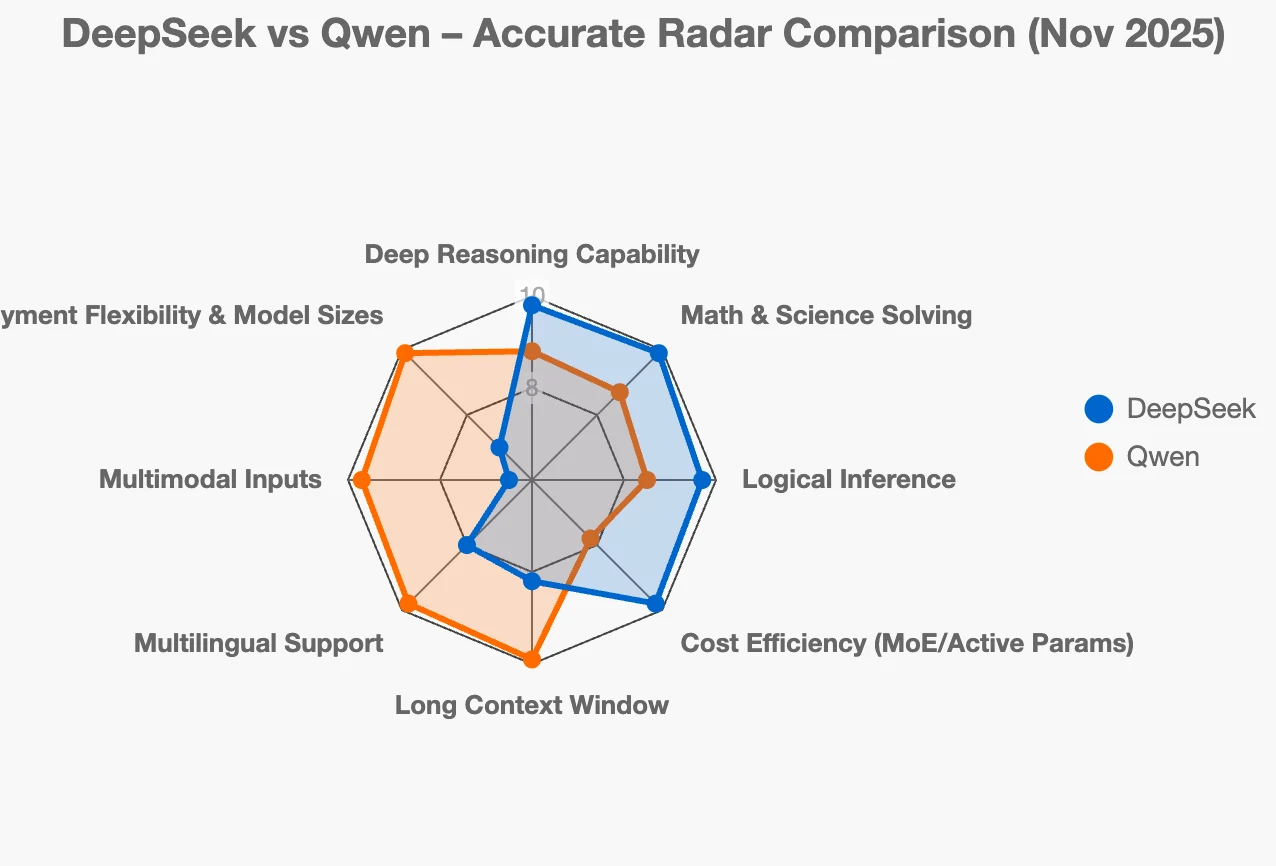
A maioria dos usuários que comparam DeepSeek e Qwen fica confusa, pois ambos os ecossistemas são robustos, de código aberto e em rápida evolução — no entanto, foram criados para resolver problemas completamente diferentes. O DeepSeek foca em raciocínio profundo, estabilidade de cadeia de pensamento, precisão em matemática/programação e eficiência baseada em MoE, enquanto a família Qwen foca em implantação full-stack, abrangendo desde modelos MoE gigantes até modelos de borda minúsculos, além de multimodal, RAG, embeddings, programação e ferramentas prontas para empresas.
Este artigo esclarece essas diferenças ao examinar seus modelos principais, variantes destiladas, séries eficientes, modelos RAG e requisitos de hardware, para que os usuários possam entender o que cada ecossistema realmente busca alcançar e qual se adapta às suas necessidades operacionais.
O que o DeepSeek e o Qwen realmente buscam fazer?
Se você está se perguntando qual ecossistema de LLM de código aberto chinês atende às suas necessidades, os dois maiores players atualmente são a família DeepSeek e a Qwen. Ambos são extremamente robustos, mas resolvem problemas diferentes e seguem direções distintas.
DeepSeek: “Queremos modelos que realmente possam pensar profundamente”
Pense no DeepSeek como o “especialista em raciocínio”.
O que mais lhes importa:
- Criar modelos que sejam genuinamente bons em pensamento passo a passo difícil — provas de matemática, problemas de ciências, programação complexa, quebra-cabeças lógicos.
- Levar ao limite o raciocínio de cadeia de pensamento (CoT) para que o modelo não apenas pareça inteligente… ele realmente resolve o problema corretamente e pode mostrar seu processo.
- Usar truques inteligentes como Mixture-of-Experts (MoE) + aprendizado por reforço para que o modelo seja poderoso sem precisar ativar bilhões de parâmetros para cada token individual (isso mantém a inferência mais barata e rápida).
- Lançar versões “destiladas” menores de seus melhores modelos de raciocínio para que pessoas comuns e empresas menores possam realmente executá-los.
Os problemas do mundo real que eles estão atacando:
- A maioria dos modelos gigantes é ótima em escrever redações, mas ainda falha em perguntas básicas de matemática ou lógica. O DeepSeek quer corrigir isso.
- Maior nem sempre é melhor para raciocínio — eles estão tentando obter mais poder de raciocínio com menos parâmetros ativos (mais desempenho pelo seu investimento em GPU).
- Modelos de raciocínio de alta qualidade geralmente são muito caros para executar fora de grandes laboratórios. O DeepSeek quer democratizar essa capacidade.
- Quando você precisa que o modelo explique como chegou a uma resposta (jurídica, médica, educação etc.), você quer uma cadeia de pensamento transparente — o DeepSeek expõe isso muito bem.
Ideal para: pesquisa, educação, assistentes de programação, ferramentas de matemática/ciências, qualquer situação em que “obter a resposta correta + mostrar o processo” é mais importante do que ser um chatbot geral.
Qwen: “Queremos uma caixa de ferramentas completa para empresas reais”
A Qwen é mais como a “canivete suíço” dos LLMs.
O que mais lhes importa:
- Oferecer todos os tamanhos e tipos que você possa precisar: modelos minúsculos para celulares, modelos médios para servidores, modelos gigantes para poder máximo, versões densas ou MoE, modelos de visão, modelos de programação, modelos de embedding, modelos de reranking… você escolhe.
- Desempenho multilíngue forte (especialmente chinês + mais de 100 outros idiomas).
- Janelas de contexto muito longas (até 128k ou até 1M de tokens em algumas versões).
- Implantação pronta para empresas: API fácil, opções on-prem, suporte a dispositivos de borda, segurança e ferramentas de nível empresarial.
Os problemas do mundo real que eles estão atacando:
- Empresas não querem apenas um chatbot — elas precisam de compreensão de documentos, busca, geração aumentada por recuperação (RAG), aplicativos de imagem + texto, suporte ao cliente multilíngue etc. A Qwen fornece toda a pilha.
- Modelos mais antigos engasgam com documentos longos ou quebram quando você muda de idioma. A Qwen lida com ambos de forma elegante.
- Você geralmente precisa de modelos minúsculos para dispositivos móveis/borda e modelos gigantes para análises pesadas — a Qwen oferece uma escada de tamanhos suave para que você nunca fique sem opções.
- Construir um sistema de busca empresarial ou base de conhecimento adequado requer ótimos embeddings + reranking. Os modelos de embedding e reranking da Qwen estão entre os melhores disponíveis abertamente.
Ideal para: motores de busca empresariais, bots de atendimento ao cliente multilíngues, fluxos de trabalho com muitos documentos, pipelines de RAG, aplicativos que combinam visão + texto ou qualquer sistema de produção em que confiabilidade e implantação fácil são importantes.
Então, qual você deve escolher?
- Se o seu projeto depende de raciocínio lógico, matemática ou precisão em programação → escolha o DeepSeek (especialmente o DeepSeek-R1 ou os novos modelos de raciocínio DeepSeek-V3).
- Se você está construindo um produto real com busca, documentos longos, múltiplos idiomas, imagens ou precisa de modelos de 0,5B a 72B → escolha a Qwen.
Ecossistema de Modelos DeepSeek
Os modelos DeepSeek são focados principalmente em maximizar o poder de raciocínio por meio de arquiteturas de Mixture-of-Experts (MoE) em larga escala e pipelines intensivos de Aprendizado por Reforço (RL), resultando em modelos precisos e de alto desempenho (671B–685B) e versões menores especializadas (modelos Destilados).
Modelos Principais do DeepSeek
Aqui estão resumos detalhados da arquitetura de cada variante de modelo DeepSeek:
| Variante | Total de Parâmetros / Parâmetros Ativados | Janela de Contexto | Arquitetura Principal e Aprimoramentos |
|---|---|---|---|
| DeepSeek V3 | 671B no total, 37B ativos por token | 128K tokens | Arquitetura Mixture-of-Experts (MoE); usa Multi-Head Latent Attention (MLA) para reduzir o tamanho do KV-cache; usa objetivo Multi-Token Prediction (MTP); usa balanceamento de carga sem perda auxiliar. |
| DeepSeek R1 | 671B no total, 37B ativos por token |
128K tokens | Mesma arquitetura base do V3 (MoE + MLA), mas com pipeline intensivo de RL (SFT → RL → SFT → RL) para aprimorar capacidades de raciocínio/lógica. |
| DeepSeek V3.1 | 671B no total, 37B ativos por token |
128K tokens | Modos de inferência híbridos: suporta modos “Pensar” (cadeia de pensamento) e “Não Pensar”; combina a capacidade geral do V3 com a força de raciocínio do R1; treinamento estendido de contexto longo. |
| DeepSeek R1 0528 | 685B parâmetros no total (subconjunto ativo não especificado) | 64K tokens | Versão atualizada do R1 com contagem de parâmetros maior e janela de contexto reduzida para ~64K para melhorar velocidade/estabilidade de inferência (em vez de 128K completo). (Dados da listagem de variantes) |
| DeepSeek V3 0324 | 671B no total, 37B ativos por token | 128K tokens | Mesma arquitetura do V3, mas otimizada para processamento multilíngue (especialmente chinês), Chamada de Função aprimorada, casos de uso de desenvolvimento frontend/web melhorados. |
Modelos Destilados do DeepSeek
Transfira a capacidade de raciocínio do DeepSeek (lógica, matemática, pensamento passo a passo, estabilidade de CoT) para modelos densos menores que são mais baratos, mais rápidos e executáveis em GPUs de consumo.
| Modelo Destilado | Modelo Base | Capacidades Reforçadas |
|---|---|---|
| R1-Distill Qwen 32B | Qwen 2.5–32B | CoT forte, melhor estabilidade lógica, raciocínio multilíngue aprimorado |
| R1-0528 Qwen3 8B | Qwen3 8B | Alta precisão de raciocínio (AIME 86%), CoT eficiente, inferência rápida |
| R1-Distill Qwen 7B | Qwen 2.5 Math-7B | Precisão matemática excepcional (MATH-500 92,8%), raciocínio passo a passo estruturado |
| R1-Distill Llama 8B | Llama-8B | Melhor cumprimento de instruções + comportamento de raciocínio compacto |
| R1-Distill Llama 70B | Llama-70B | Raciocínio geral forte, CoT longo estável, saídas consistentes |
Ecossistema de Modelos Qwen
A família Qwen (Qwen 2.5 e Qwen 3) oferece uma gama altamente flexível de modelos de 0,6B a 480B parâmetros, com ênfase em suporte multilíngue, manipulação extensa de contexto e variantes especializadas para programação, embeddings e tarefas multimodais.
Modelos Principais da Qwen
| Variante | Total de Parâmetros / Parâmetros Ativos | Janela de Contexto | Foco Principal / Recursos |
|---|---|---|---|
| Qwen3-Coder 480B-A35B-Instruct | 480B / 35B (MoE) | 256K nativo, extensível para ~1M tokens | Programação agentiva e compreensão de repositórios de múltiplos arquivos; otimizado para chamada de funções/uso de ferramentas; apenas modo sem pensamento |
| Qwen3-VL-235B-A22B | 235B / 22B (MoE) | 256K nativo (extensível para ~1M) | Modelo de linguagem multimodal visão (imagens/vídeos); excelente em código a partir de visual, raciocínio 3D, OCR; tem variantes Instruct/Pensamento |
| Qwen3 32B | 32B / denso | 128K tokens | Raciocínio geral + suporte multilíngue; backbone denso para implantação de menor custo |
| Qwen2.5-72B Instruct | 72B (Variante Densa ou MoE) | 128K tokens | Suporte multilíngue forte (mais de 29 idiomas); |
Modelos Eficientes Qwen 3
A série Qwen 3 introduziu um conjunto abrangente de modelos menores, todos com suporte aos “Modos de Pensamento Híbrido” altamente eficientes (Pensamento vs. Não Pensamento) e suporte multilíngue amplo (119 idiomas).
| Variante | Total de Parâmetros | Janela de Contexto | Foco Principal / Recursos |
|---|---|---|---|
| Qwen3-14B | 14,8B | 32.768 tokens nativos; extensível até 131.072 | Modelo de médio porte forte para uso geral; suporta modos “pensamento” e “não pensamento”; capacidades multilíngues e agentes |
| Qwen3-8B | 8,19B | 128K tokens | Modelo de raciocínio leve; competitivo em tarefas de matemática e raciocínio geral |
| Qwen3-4B | 4,0B | 32K tokens nativos (extensível) | Otimizado para eficiência; implantações de baixo recurso, mantendo desempenho forte |
| Qwen3-1.7B | 1,7B | 32K tokens | Adequado para uso em borda / chatbots rápidos; pegada mínima |
| Qwen3-0.6B | 0,6B | 32K tokens | Modelo ultra-leve para implantação de alta concorrência / no dispositivo |
Modelos RAG Qwen 3
A linha de embeddings Qwen3 reflete o reconhecimento de que recuperação + embeddings + fluxos de trabalho aumentados por recuperação são centrais para aplicações modernas de IA (busca, perguntas e respostas, RAG, programação).
| Variante | Total de Parâmetros / Ativos | Janela de Contexto | Foco Principal / Recursos |
|---|---|---|---|
| Qwen3-Embedding 8B | 8B | 32K tokens | Modelo de embedding de texto; multilíngue (mais de 100 idiomas); suporte a entrada longa; dimensões de embedding configuráveis até 4096; excelente no benchmark MTEB (70,58) |
| Qwen3-Reranker 8B | 8B | 32K tokens | Modelo de reranking cross-encoder; classifica documentos recuperados por relevância em pipelines de RAG; alta precisão em recuperação multilíngue |
Como Acessar o DeepSeek e o Qwen de Forma Barata e Rápida?
1. Interface Web (Mais fácil para iniciantes)
2. Acesso via API (Para desenvolvedores)
Passo 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha seu modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie seu teste gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha sua chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusão de chat para usuários de Python.
3. Implantação Local (Usuários avançados)
| Modelo | VRAM Total (Inferência FP16) | Configuração Mínima de Consumo |
|---|---|---|
| DeepSeek-V3 / R1 / V3.1 671B MoE | ~780–820 GB | 8× RTX 4090 (24 GB) mal possível com offloading pesado |
| DeepSeek-R1-0528 685B | ~800–850 GB | 8× H100 80 GB (apertado) |
| DeepSeek-V3-0324 671B | ~780–820 GB | 8× RTX 4090 (24 GB) mal possível com offloading pesado |
| Modelo | Quantização | VRAM Necessária | Configuração de Consumo Viável |
|---|---|---|---|
| DeepSeek-R1/V3 671B | 4-bit (NF4/GPTQ/AWQ) | 170–190 GB | 8× RTX 4090 ou 4× H100 80 GB |
| DeepSeek-R1/V3 671B | INT8 | 340–380 GB | 6–8× RTX 4090 ou 4× A100/H100 80 GB |
| Modelo | VRAM (FP16) | GPU de Consumo que Pode Executá-lo |
|---|---|---|
| R1-Distill-Qwen-32B | 64 GB | 2× RTX 4090 |
| R1-0528-Qwen3-8B / Llama-8B | 16 GB | 1× RTX 4090 / 3090 Ti |
| R1-Distill-Qwen-7B Math | 14 GB | 1× RTX 4080/4090 |
| R1-Distill-Llama-70B | 140 GB | 4× RTX 4090 ou 2× A100 80 GB |
| Modelo | VRAM Total (FP16/BF16) | Configuração Mínima de Consumo |
|---|---|---|
| Qwen3-Coder 480B MoE | 560–600 GB (35B ativos) | 8× H100 80 GB |
| Qwen3-VL-235B MoE | 280–320 GB (22B ativos) | 4× H100 80 GB |
| Qwen2.5-72B / Qwen3-32B Dense | 140–160 GB | 4× RTX 4090 ou 2× A100 80 GB |
| Qwen3-14B | 28–32 GB | 1× RTX 4090 |
| Qwen3-8B | 16–18 GB | 1× RTX 4080/4090 |
| Qwen3-4B | 8–10 GB | 1× RTX 4060 Ti / 4070 |
| Qwen3-1.7B & 0.6B | 4 GB | Celulares, RTX 3050 |
| Qwen3-Embedding / Reranker 8B | 16 GB | 1× RTX 4090 |
Passos de Instalação:
- Baixe os pesos do modelo no HuggingFace ou ModelScope
- Escolha o framework de inferência: suporte a vLLM ou SGLang
- Siga o guia de implantação no repositório oficial do GitHub
4. Integração
Usando CLI como Trae, Claude Code, Qwen Code
Se você quiser usar os principais modelos da Novita AI (como Qwen3-Coder, Kimi K2, DeepSeek R1) para assistência de programação com IA no seu ambiente local ou IDE, o processo é simples: obtenha sua chave de API, instale a ferramenta, configure as variáveis de ambiente e comece a programar.
Para comandos de configuração detalhados e exemplos, consulte os tutoriais oficiais:
- Trae: Guia passo a passo para acessar modelos de IA no seu IDE
- Claude Code: Como usar o Kimi-K2 no Claude Code no Windows, Mac e Linux
- Qwen Code: Como usar a API compatível com OpenAI no Qwen Code (Configuração em 60s!)
Fluxos de Trabalho Multiagente com o SDK OpenAI Agents
Construa sistemas multiagente avançados integrando a Novita AI com o SDK OpenAI Agents:
- Plug and play: Use os LLMs da Novita AI em qualquer fluxo de trabalho do OpenAI Agents.
- Suporta transferências, roteamento e uso de ferramentas: Projete agentes que possam delegar, triar ou executar funções, todos alimentados pelos modelos da Novita AI.
- Integração com Python: Basta definir o endpoint do SDK como
https://api.novita.ai/v3/openaie usar sua chave de API.
Conecte a API em Plataformas de Terceiros
API compatível com OpenAI: Aproveite uma migração e integração sem complicações com ferramentas como Cline e Cursor, projetadas para o padrão de API do OpenAI.
Hugging Face: Use modelos nos Spaces, pipelines ou com a biblioteca Transformers por meio dos endpoints da Novita AI.
Frameworks de Agentes e Orquestração: Conecte facilmente a Novita AI com plataformas parceiras como Continue, AnythingLLM,LangChain, Dify e Langflow por meio de conectores oficiais e guias de integração passo a passo.
O DeepSeek tem como alvo o poder máximo de raciocínio com modelos como DeepSeek-V3, DeepSeek-R1 e DeepSeek-V3.1, apoiados por destilações leves como R1-Distill-Qwen-32B e R1-Distill-Qwen3-8B. A Qwen tem como objetivo a versatilidade e a prontidão empresarial com modelos como Qwen3-Coder-480B-A35B-Instruct, Qwen3-VL-235B-A22B, modelos eficientes de Qwen3-14B a Qwen3-0.6B e modelos voltados para RAG como Qwen3-Embedding-8B e Qwen3-Reranker-8B. Em resumo: o DeepSeek otimiza para desempenho de raciocínio profundo; a Qwen otimiza para uma caixa de ferramentas de IA completa, implantável, multilíngue e multimodal.
Perguntas Frequentes
Qual é a força principal do DeepSeek-V3 em comparação com os modelos Qwen?
O DeepSeek-V3 usa uma arquitetura MoE com MLA e MTP para maximizar a qualidade do raciocínio, enquanto os modelos Qwen focam mais em cobertura multilíngue, amplitude de implantação e versatilidade de aplicação.
Por que alguém escolheria o DeepSeek-V3.1 em vez do Qwen3-14B?
O DeepSeek-V3.1 oferece modos de raciocínio híbridos “Pensar / Não Pensar” otimizados para profundidade de cadeia de pensamento, enquanto o Qwen3-14B prioriza inferência de uso geral, tarefas multilíngues e implantação eficiente.
Qual ecossistema de modelos é melhor para fluxos de trabalho com documentos longos?
A Qwen se destaca com modelos como Qwen3-Coder-480B-A35B-Instruct e Qwen3-VL-235B-A22B, que oferecem contexto de até 256K–1M de tokens, enquanto o DeepSeek foca no raciocínio, e não no manuseio de documentos com contexto ultra longo.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



