

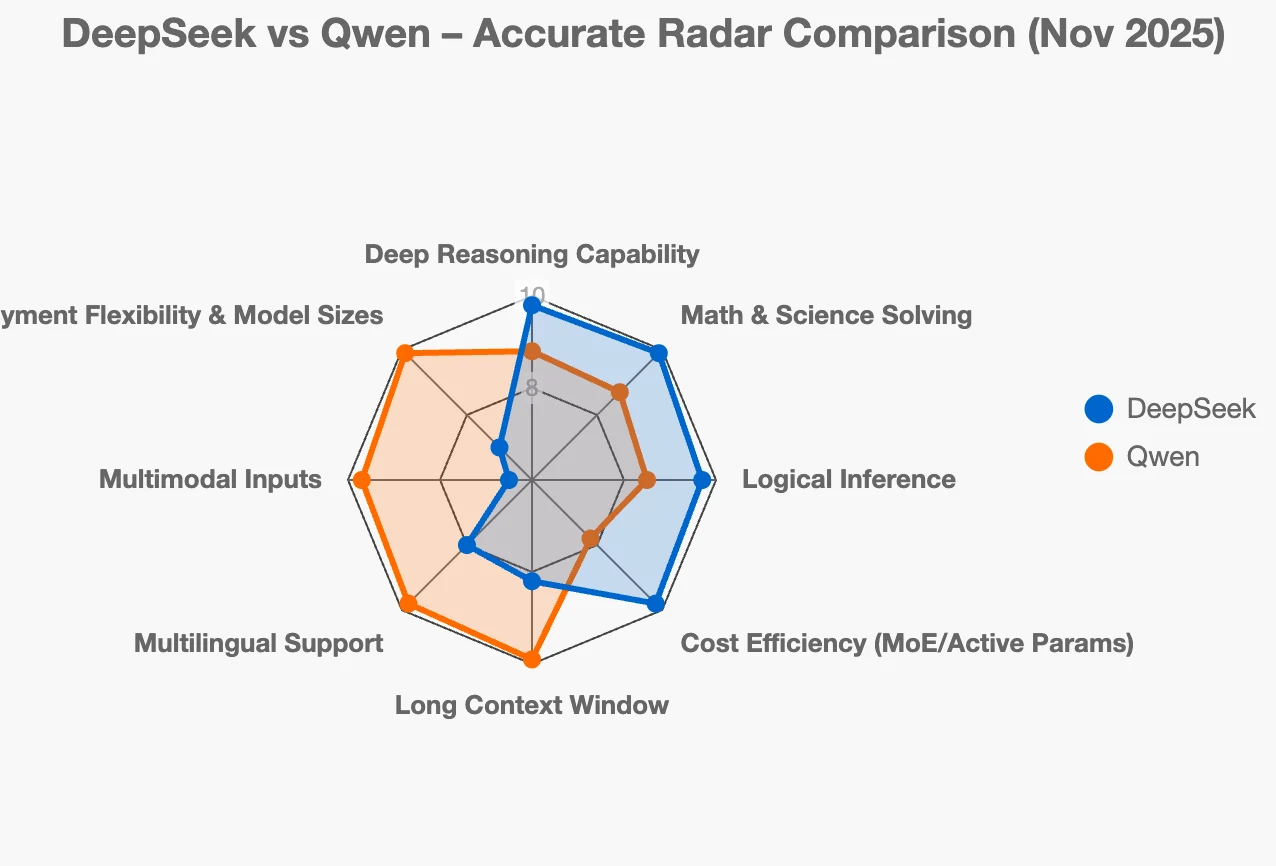
DeepSeekとQwenを比較している多くのユーザーは、両方のエコシステムが強力で、オープンソースであり、急速に進化しているにもかかわらず、まったく異なる課題を解決するように構築されているため、混乱しています。DeepSeekは深い推論、思考の連鎖の安定性、数学/コーディングの精度、MoEベースの効率性に重点を置いている一方、Qwenファミリーはフルスタックデプロイメントに重点を置き、巨大なMoEモデルから小さなエッジモデル、さらにマルチモーダル、RAG、埋め込み、コーディング、エンタープライズ向けツールまでをカバーしています。
この記事では、それぞれのフラッグシップモデル、蒸留バリアント、効率的なシリーズ、RAGモデル、ハードウェア要件を詳しく調べることで、各エコシステムが実際に何を達成しようとしているのか、そしてどれが運用上のニーズに合っているのかを明確にします。
DeepSeek vs Qwenは実際に何をしようとしているのか?
どのオープンソース中国語LLMエコシステムが自分のニーズに合っているのか疑問に思っているなら、現在の2大プレーヤーはDeepSeekとQwenファミリーです。どちらも非常に強力ですが、異なる問題を解決し、異なる方向に向かっています。
DeepSeek:「深く考えられるモデルを作りたい」
DeepSeekは「推論のスペシャリスト」と考えてください。
彼らが最も重視していること:
- 難しい、ステップバイステップの思考が本当に得意なモデルを作ること — 数学の証明、科学の問題、複雑なコーディング、論理パズルなど。
- 思考の連鎖(CoT)推論の限界を押し広げ、モデルが単に賢そうに聞こえるだけでなく…実際に問題を正しく解決し、その過程を示せるようにすること。
- Mixture-of-Experts(MoE)+ 強化学習のような巧妙なテクニックを使い、すべてのトークン毎に何十億ものパラメータをオンにする必要なく、モデルを強力にすること(これにより推論がより安く、速くなります)。
- 最高の推論モデルの小さな「蒸留」バージョンをリリースし、一般の人や中小企業でも実際に実行できるようにすること。
彼らが取り組んでいる現実世界の問題:
- ほとんどの巨大モデルはエッセイを書くのは得意ですが、基本的な数学や論理の問題ではまだ失敗します。DeepSeekはそれを修正したいと考えています。
- 推論においては、大きければ良いというわけではありません — 少ないアクティブパラメータでより多くの推論力を引き出そうとしています(GPU使用効率の向上)。
- ハイエンドの推論モデルは、通常、大規模な研究所以外で実行するには高価すぎます。DeepSeekはその能力を民主化したいと考えています。
- モデルがどのように答えにたどり着いたかを説明する必要がある場合(法律、医療、教育など)、透明性のある思考の連鎖が必要です — DeepSeekはこれを非常にうまく公開しています。
最適な用途:研究、教育、コーディングアシスタント、数学/科学ツール、「正しい答えを出し、その過程を示すこと」が一般的なチャットボットよりも重要なあらゆる状況。
Qwen:「現実の企業向けの完全なツールボックスを提供したい」
QwenはLLMの「スイスアーミーナイフ」のようなものです。
彼らが最も重視していること:
- 必要なあらゆるサイズと種類を提供:携帯電話用の極小モデル、サーバー用の中型モデル、最大パワー用の巨大モデル、DenseまたはMoEバージョン、ビジョンモデル、コーダーモデル、埋め込みモデル、リランカーモデル…名前を挙げればきりがありません。
- 強力な多言語性能(特に中国語 + 100以上の言語)。
- 非常に長いコンテキストウィンドウ(一部のバージョンでは最大128k、さらには100万トークン)。
- ビジネス向けのすぐに使えるデプロイメント:使いやすいAPI、オンプレミスオプション、エッジデバイスサポート、エンタープライズグレードのセキュリティとツール。
彼らが取り組んでいる現実世界の問題:
- 企業は単なるチャットボットを求めているのではなく、文書理解、検索、検索拡張生成(RAG)、画像+テキストアプリ、多言語カスタマーサポートなどが必要です。Qwenはスタック全体を提供します。
- 古いモデルは長い文書で詰まったり、言語を切り替えると壊れたりします。Qwenは両方を優雅に処理します。
- モバイル/エッジ用の小さなモデルと、高度な分析用の巨大モデルの両方が必要な場合がよくあります — Qwenはスムーズなサイズの梯子を提供し、行き詰まることがありません。
- 適切なエンタープライズ検索や知識ベースシステムを構築するには、優れた埋め込みとリランキングが必要です。Qwenの埋め込みモデルとリランカーモデルは、公開されている中でも最高のものの一部です。
最適な用途:エンタープライズ検索エンジン、多言語カスタマーサービスのボット、文書を多用するワークフロー、RAGパイプライン、ビジョン+テキストを組み合わせたアプリ、または信頼性と容易なデプロイメントが重要なあらゆる本番システム。
では、どちらを選ぶべきか?
- プロジェクトが論理的推論、数学、またはコードの精度に依存している場合 → DeepSeekを選びましょう(特にDeepSeek-R1または新しいDeepSeek-V3推論モデル)。
- 検索、長文書、複数言語、画像を含む実際の製品を構築している場合、または0.5Bから72Bまでのモデルが必要な場合 → Qwenを選びましょう。
DeepSeekモデルエコシステム
DeepSeekモデルは主に、大規模なMixture-of-Experts(MoE)アーキテクチャと集中的な強化学習(RL)パイプラインを通じて推論力を最大化することに焦点を当てており、その結果、正確で高性能なモデル(671B〜685B)と特殊な小型バージョン(蒸留モデル)が生まれています。
DeepSeek フラッグシップモデル
各DeepSeekモデルバリアントの詳細なアーキテクチャ概要は以下の通りです:
| バリアント | 総パラメータ / アクティブパラメータ | コンテキストウィンドウ | 主要アーキテクチャと拡張機能 |
|---|---|---|---|
| DeepSeek V3 | 671B total, 37B active per token | 128K tokens | Mixture-of-Experts (MoE) アーキテクチャ;KVキャッシュサイズを削減するMulti-Head Latent Attention (MLA) を採用;Multi-Token Prediction (MTP) 目的関数を使用;補助損失なし負荷分散を採用。 |
| DeepSeek R1 | 671B total, 37B active per token |
128K tokens | V3と同じ基本アーキテクチャ(MoE + MLA)だが、推論/論理能力を強化するために集中的なRLパイプライン(SFT → RL → SFT → RL)を採用。 |
| DeepSeek V3.1 | 671B total, 37B active per token |
128K tokens | ハイブリッド推論モード:「Think」(思考連鎖)と「Non-Think」モードをサポート;V3の汎用能力とR1の推論力を組み合わせ;長コンテキストトレーニングを拡張。 |
| DeepSeek R1 0528 | 685B total parameters (active subset unspecified) | 64K tokens | 更新されたR1バージョンで、パラメータ数が増加し、コンテキストウィンドウが約64Kに縮小され、推論速度と安定性が向上(フル128Kではない)。(バリアントリストからのデータ) |
| DeepSeek V3 0324 | 671B total, 37B active per token | 128K tokens | V3と同じアーキテクチャだが、多言語処理(特に中国語)に最適化、関数呼び出し機能強化、フロントエンド/Web開発のユースケースが改善。 |
DeepSeek 蒸留モデル
DeepSeekの推論能力(論理、数学、ステップワイズ思考、CoT安定性)を、より安価で高速、かつコンシューマーGPUでも実行可能な小型のDenseモデルに移行します。
| 蒸留モデル | ベースモデル | 強化された能力 |
|---|---|---|
| R1-Distill Qwen 32B | Qwen 2.5–32B | 強力なCoT、より良い論理安定性、改善された多言語推論 |
| R1-0528 Qwen3 8B | Qwen3 8B | 高い推論精度(AIME 86%)、効率的なCoT、高速推論 |
| R1-Distill Qwen 7B | Qwen 2.5 Math-7B | 卓越した数学精度(MATH-500 92.8%)、構造化されたステップワイズ推論 |
| R1-Distill Llama 8B | Llama-8B | 改善された指示追従 + コンパクトな推論動作 |
| R1-Distill Llama 70B | Llama-70B | 強力な汎用推論、安定した長文CoT、一貫した出力 |
Qwenモデルエコシステム
Qwenファミリー(Qwen 2.5およびQwen 3)は、0.6Bから480Bパラメータまでの非常に柔軟なモデル範囲を提供し、多言語サポート、広範なコンテキスト処理、およびコーディング、埋め込み、マルチモーダルタスクに特化したバリアントを重視しています。
Qwen フラッグシップモデル
| バリアント | 総パラメータ / アクティブパラメータ | コンテキストウィンドウ | 主要焦点 / 特徴 |
|---|---|---|---|
| Qwen3-Coder 480B-A35B-Instruct | 480B / 35B (MoE) | 256K native, 約1Mトークンまで拡張可能 | エージェント型コーディングとマルチファイルリポジトリ理解;関数呼び出し/ツール使用に最適化;非思考モードのみ |
| Qwen3-VL-235B-A22B | 235B / 22B (MoE) | 256K native (約1Mまで拡張可能) | マルチモーダル視覚言語(画像/動画)モデル;ビジュアルからコード、3D推論、OCRに優れる;Instruct/Thinkingバリアントあり |
| Qwen3 32B | 32B / dense | 128K tokens | 汎用推論 + 多言語サポート;低コストデプロイメントのためのDenseバックボーン |
| Qwen2.5-72B Instruct | 72B (DenseまたはMoEバリアント) | 128K tokens | 強力な多言語サポート(29以上の言語); |
Qwen 3 効率的モデル
Qwen 3シリーズでは、すべてが非常に効率的な「ハイブリッド思考モード」(思考 vs 非思考)と幅広い多言語サポート(119言語)をサポートする、小型モデルの包括的なセットが導入されました。
| バリアント | 総パラメータ | コンテキストウィンドウ | 主要焦点 / 特徴 |
|---|---|---|---|
| Qwen3-14B | 14.8B | 32,768 tokens native;最大131,072まで拡張可能 | 汎用的な強力な中型モデル;「思考」と「非思考」モードをサポート;多言語およびエージェント機能 |
| Qwen3-8B | 8.19B | 128K tokens | 軽量推論モデル;数学および汎用推論タスクで競争力 |
| Qwen3-4B | 4.0B | 32K tokens native(拡張可能) | 効率性に最適化;低リソースデプロイメントで、強力なパフォーマンスを維持 |
| Qwen3-1.7B | 1.7B | 32K tokens | エッジユース/高速チャットボットに適切;最小フットプリント |
| Qwen3-0.6B | 0.6B | 32K tokens | 高同時実行/オンデバイスデプロイメント向け超軽量モデル |
Qwen 3 RAGモデル
Qwen3 Embeddingラインは、検索 + 埋め込み + 検索拡張ワークフローが最新のAIアプリケーション(検索、QA、RAG、コード)の中心であるという認識を反映しています。
| バリアント | 総パラメータ / アクティブ | コンテキストウィンドウ | 主要焦点 / 特徴 |
|---|---|---|---|
| Qwen3-Embedding 8B | 8B | 32K tokens | テキスト埋め込みモデル;多言語(100以上の言語);長入力サポート;構成可能な埋め込み次元(最大4096);MTEBベンチマークで優れた性能(70.58) |
| Qwen3-Reranker 8B | 8B | 32K tokens | クロスエンコーダーリランキングモデル;RAGパイプラインで検索された文書を関連性でソート;多言語検索で高精度 |
DeepSeekとQwenに安く素早くアクセスする方法
1. Webインターフェース(初心者に最も簡単)
2. APIアクセス(開発者向け)
ステップ1: ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリボタンをクリックします。

ステップ2: モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
ステップ3: 無料トライアルを開始
無料トライアルを開始して、選択したモデルの機能を試します。
ステップ4: APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「設定」ページに入り、画像のようにAPIキーをコピーします。

ステップ5: APIをインストール
プログラミング言語固有のパッケージマネージャーを使用してAPIをインストールします。
インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。これはPythonユーザー向けのチャット完了APIを使用する例です。
3. ローカルデプロイメント(上級者向け)
| モデル | 合計VRAM(FP16推論) | 最小コンシューマー構成 |
|---|---|---|
| DeepSeek-V3 / R1 / V3.1 671B MoE | ~780–820 GB | 8× RTX 4090 (24 GB) で大量オフロードすればかろうじて可能 |
| DeepSeek-R1-0528 685B | ~800–850 GB | 8× H100 80 GB (厳しい) |
| DeepSeek-V3-0324 671B | ~780–820 GB | 8× RTX 4090 (24 GB) で大量オフロードすればかろうじて可能 |
| モデル | 量子化 | 必要なVRAM | 実現可能なコンシューマー構成 |
|---|---|---|---|
| DeepSeek-R1/V3 671B | 4-bit (NF4/GPTQ/AWQ) | 170–190 GB | 8× RTX 4090 または 4× H100 80 GB |
| DeepSeek-R1/V3 671B | INT8 | 340–380 GB | 6–8× RTX 4090 または 4× A100/H100 80 GB |
| モデル | VRAM (FP16) | 実行可能なコンシューマーGPU |
|---|---|---|
| R1-Distill-Qwen-32B | 64 GB | 2× RTX 4090 |
| R1-0528-Qwen3-8B / Llama-8B | 16 GB | 1× RTX 4090 / 3090 Ti |
| R1-Distill-Qwen-7B Math | 14 GB | 1× RTX 4080/4090 |
| R1-Distill-Llama-70B | 140 GB | 4× RTX 4090 または 2× A100 80 GB |
| モデル | 合計VRAM (FP16/BF16) | 最小コンシューマー構成 |
|---|---|---|
| Qwen3-Coder 480B MoE | 560–600 GB (35B active) | 8× H100 80 GB |
| Qwen3-VL-235B MoE | 280–320 GB (22B active) | 4× H100 80 GB |
| Qwen2.5-72B / Qwen3-32B Dense | 140–160 GB | 4× RTX 4090 または 2× A100 80 GB |
| Qwen3-14B | 28–32 GB | 1× RTX 4090 |
| Qwen3-8B | 16–18 GB | 1× RTX 4080/4090 |
| Qwen3-4B | 8–10 GB | 1× RTX 4060 Ti / 4070 |
| Qwen3-1.7B & 0.6B | 4 GB | 携帯電話、RTX 3050 |
| Qwen3-Embedding / Reranker 8B | 16 GB | 1× RTX 4090 |
インストール手順:
- モデルの重みをダウンロード: HuggingFace または ModelScope から
- 推論フレームワークを選択: vLLM または SGLang がサポートされています
- デプロイメントガイドに従う: 公式 GitHub リポジトリのガイドに従ってください
4. 統合
Trae、Claude Code、Qwen Code などの CLI を使用
Novita AIのトップモデル(Qwen3-Coder、Kimi K2、DeepSeek R1など)をローカル環境やIDEでAIコーディングアシスタンスとして使用する場合、プロセスは簡単です:APIキーを取得し、ツールをインストールし、環境変数を設定し、コーディングを開始します。
詳細なセットアップコマンドと例については、公式チュートリアルを確認してください:
- Trae : Step-by-Step Guide to Access AI Models in Your IDE
- Claude Code:How to Use Kimi-K2 in Claude Code on Windows, Mac, and Linux
- Qwen Code:How to Use OpenAI Compatible API in Qwen Code (60s Setup!)
OpenAI Agents SDK を使用したマルチエージェントワークフロー
Novita AI を OpenAI Agents SDK と統合して、高度なマルチエージェントシステムを構築:
- プラグアンドプレイ: 任意の OpenAI Agents ワークフローで Novita AI の LLM を使用します。
- ハンドオフ、ルーティング、ツール使用をサポート: Novita AI のモデルを活用して、タスクを委任、トリアージ、または機能を実行できるエージェントを設計します。
- Python 統合: SDK エンドポイントを
https://api.novita.ai/v3/openaiに設定し、API キーを使用するだけです。
サードパーティプラットフォームでの API 接続
OpenAI互換API: Cline や Cursor などのツールと、OpenAI API 標準向けに設計されたシームレスな移行と統合を実現します。
Hugging Face: Novita AI エンドポイント経由で Spaces、パイプライン、または Transformers ライブラリでモデルを使用します。
エージェント&オーケストレーションフレームワーク: Continue、AnythingLLM、LangChain、Dify、Langflow などのパートナープラットフォームと、公式コネクタやステップバイステップの統合ガイドを通じて簡単に接続できます。
DeepSeekは、DeepSeek-V3、DeepSeek-R1、DeepSeek-V3.1 などのモデルで最大の推論力を目指し、R1-Distill-Qwen-32B や R1-Distill-Qwen3-8B などの軽量蒸留モデルによってサポートされています。Qwenは、Qwen3-Coder-480B-A35B-Instruct、Qwen3-VL-235B-A22B、Qwen3-14B から Qwen3-0.6B までの効率的なモデル、そして Qwen3-Embedding-8B や Qwen3-Reranker-8B などのRAG指向モデルを用いて、汎用性とエンタープライズ対応を目指しています。要するに:DeepSeekは深い推論性能に最適化されており、Qwenは完全でデプロイ可能な多言語・マルチモーダルAIツールボックスに最適化されています。
よくある質問
DeepSeek-V3のQwenモデルに対する中核的な強みは何ですか?
DeepSeek-V3は、MLAとMTPを備えたMoEアーキテクチャを使用して推論品質を最大化する一方、Qwenモデルは多言語カバレッジ、デプロイメント範囲、アプリケーションの汎用性に重点を置いています。
なぜQwen3-14BではなくDeepSeek-V3.1を選ぶのでしょうか?
DeepSeek-V3.1は思考連鎖の深さに最適化されたハイブリッド「Think / Non-Think」推論モードを提供する一方、Qwen3-14Bは汎用推論、多言語タスク、効率的なデプロイメントを優先しています。
長文書ワークフローにはどのモデルエコシステムが適していますか?
Qwenは、Qwen3-Coder-480B-A35B-InstructやQwen3-VL-235B-A22Bなどのモデルで最大256K〜100万トークンのコンテキストを提供して優れていますが、DeepSeekは超長コンテキスト文書処理よりも推論に重点を置いています。
Novita AI はAIクラウドプラットフォームであり、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるようにすると同時に、手頃な価格で信頼性の高いGPUクラウドを提供し、構築とスケーリングを支援します。



