

La mayoría de los usuarios que comparan DeepSeek y Qwen están confundidos porque ambos ecosistemas son fuertes, de código abierto y avanzan rápidamente; sin embargo, están diseñados para resolver problemas completamente diferentes. DeepSeek se centra en razonamiento profundo, estabilidad en cadena de pensamiento, precisión en matemáticas/código y eficiencia basada en MoE, mientras que la familia Qwen se enfoca en despliegue integral, cubriendo desde modelos MoE enormes hasta modelos pequeños para edge, además de multimodal, RAG, embeddings, codificación y herramientas preparadas para empresas.
Este artículo aclara estas diferencias examinando sus modelos emblemáticos, variantes destiladas, series eficientes, modelos RAG y requisitos de hardware, para que los usuarios comprendan qué intenta lograr realmente cada ecosistema y cuál se adapta a sus necesidades operativas.
¿Qué intenta realmente hacer DeepSeek vs Qwen?
Si te preguntas qué ecosistema de LLM chino de código abierto se adapta a tus necesidades, los dos jugadores más importantes actualmente son DeepSeek y la familia Qwen. Ambos son extremadamente sólidos, pero resuelven problemas diferentes y se dirigen en direcciones distintas.
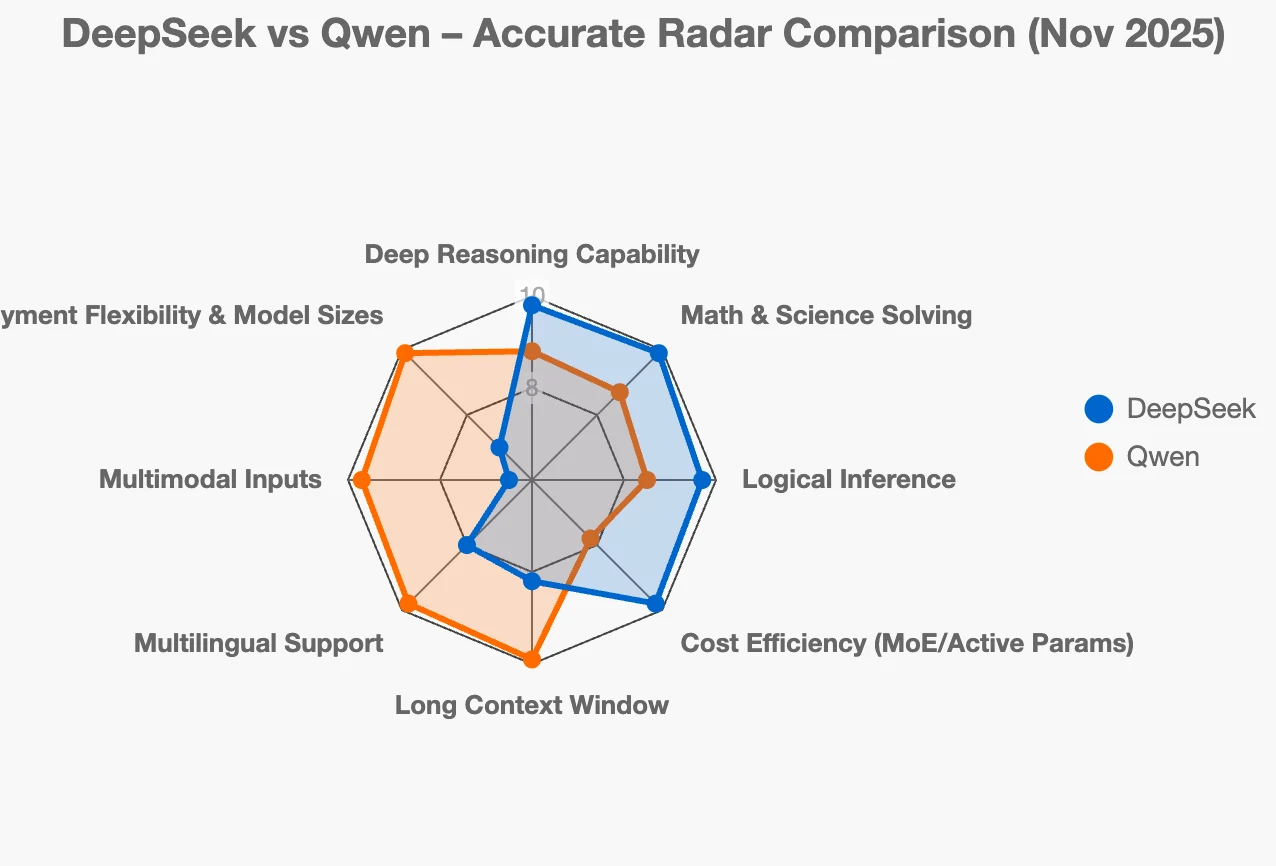
DeepSeek: “Queremos modelos que realmente puedan pensar profundamente”
Piensa en DeepSeek como el “especialista en razonamiento”.
Lo que más les importa:
- Crear modelos que sean realmente buenos en pensamiento complejo paso a paso: demostraciones matemáticas, problemas científicos, codificación compleja, acertijos lógicos.
- Llevar al límite el razonamiento de cadena de pensamiento (CoT) para que el modelo no solo suene inteligente… sino que realmente resuelva el problema correctamente y pueda mostrar su trabajo.
- Usar trucos inteligentes como Mixture-of-Experts (MoE) + aprendizaje por refuerzo para que el modelo sea potente sin necesidad de activar miles de millones de parámetros por cada token (esto mantiene la inferencia más barata y rápida).
- Lanzar versiones “destiladas” más pequeñas de sus mejores modelos de razonamiento para que personas normales y empresas más pequeñas puedan ejecutarlos.
Los problemas del mundo real que están atacando:
- La mayoría de los modelos gigantes son excelentes para redactar ensayos, pero aún fallan en preguntas básicas de matemáticas o lógica. DeepSeek quiere solucionar eso.
- Más grande no siempre es mejor para el razonamiento: intentan obtener más potencia de razonamiento con menos parámetros activos (más rendimiento por tu inversión en GPU).
- Los modelos de razonamiento de alta gama suelen ser demasiado costosos de ejecutar fuera de los grandes laboratorios. DeepSeek quiere democratizar esa capacidad.
- Cuando necesitas que el modelo explique cómo llegó a una respuesta (legal, médico, educativo, etc.), quieres una cadena de pensamiento transparente — DeepSeek la expone muy bien.
Mejor para: investigación, educación, asistentes de codificación, herramientas de matemáticas/ciencias, cualquier situación donde “obtener la respuesta correcta + mostrar el trabajo” sea más importante que ser un chatbot general.
Qwen: “Queremos una caja de herramientas completa para empresas reales”
Qwen es más como la “navaja suiza” de los LLM.
Lo que más les importa:
- Ofrecer todos los tamaños y sabores que puedas necesitar: modelos diminutos para teléfonos, medianos para servidores, enormes para máxima potencia, versiones densas o MoE, modelos de visión, modelos de codificación, modelos de embedding, modelos de reranking… lo que sea.
- Rendimiento multilingüe sólido (especialmente chino + más de 100 idiomas).
- Ventanas de contexto muy largas (hasta 128k o incluso 1M de tokens en algunas versiones).
- Despliegue listo para empresas: API fácil, opciones on-prem, soporte para dispositivos edge, seguridad y herramientas de nivel empresarial.
Los problemas del mundo real que están atacando:
- Las empresas no solo quieren un chatbot — necesitan comprensión de documentos, búsqueda, generación aumentada por recuperación (RAG), aplicaciones de imagen+texto, soporte al cliente multilingüe, etc. Qwen proporciona toda la pila.
- Los modelos antiguos se bloquean con documentos largos o fallan al cambiar de idioma. Qwen maneja ambos con elegancia.
- A menudo necesitas modelos diminutos para móvil/edge y modelos gigantes para análisis pesados — Qwen te da una escalera suave de tamaños para que nunca estés atascado.
- Construir un sistema de búsqueda o base de conocimiento empresarial adecuado requiere buenos embeddings + reranking. Los modelos de embedding y reranking de Qwen son algunos de los mejores disponibles abiertamente.
Mejor para: motores de búsqueda empresarial, bots de atención al cliente multilingües, flujos de trabajo intensivos en documentos, pipelines RAG, aplicaciones que combinan visión + texto, o cualquier sistema de producción donde la fiabilidad y la facilidad de despliegue sean importantes.
Entonces, ¿cuál deberías elegir?
- Si tu proyecto depende del razonamiento lógico, las matemáticas o la precisión en código → elige DeepSeek (especialmente DeepSeek-R1 o los nuevos modelos de razonamiento DeepSeek-V3).
- Si estás construyendo un producto real con búsqueda, documentos largos, múltiples idiomas, imágenes, o necesitas modelos desde 0.5B hasta 72B → elige Qwen.
Ecosistema de modelos DeepSeek
Los modelos DeepSeek se centran principalmente en maximizar el poder de razonamiento a través de arquitecturas MoE a gran escala y pipelines intensivos de aprendizaje por refuerzo (RL), lo que resulta en modelos precisos y de alto rendimiento (671B–685B) y versiones especializadas más pequeñas (modelos destilados).
Modelos emblemáticos de DeepSeek
Aquí hay resúmenes detallados de la arquitectura de cada variante del modelo DeepSeek en español:
| Variante | Parámetros totales / activados | Ventana de contexto | Arquitectura clave y mejoras |
|---|---|---|---|
| DeepSeek V3 | 671B total, 37B activos por token | 128K tokens | Arquitectura MoE; usa Multi-Head Latent Attention (MLA) para reducir el tamaño de KV-cache; usa objetivo de Multi-Token Prediction (MTP); usa balanceo de carga sin pérdida auxiliar. |
| DeepSeek R1 | 671B total, 37B activos por token |
128K tokens | Misma arquitectura base que V3 (MoE + MLA) pero con pipeline RL intensivo (SFT → RL → SFT → RL) para mejorar las capacidades de razonamiento/lógica. |
| DeepSeek V3.1 | 671B total, 37B activos por token |
128K tokens | Modos de inferencia híbridos: admite modos “Think” (cadena de pensamiento) y “Non-Think”; combina la capacidad general de V3 con la fortaleza de razonamiento de R1; entrenamiento extendido de contexto largo. |
| DeepSeek R1 0528 | 685B parámetros totales (subconjunto activo no especificado) | 64K tokens | Versión R1 actualizada con mayor número de parámetros y ventana de contexto reducida a ~64K para mejorar la velocidad/estabilidad de inferencia (en lugar de los 128K completos). (Datos del listado de variantes) |
| DeepSeek V3 0324 | 671B total, 37B activos por token | 128K tokens | Misma arquitectura que V3 pero optimizada para procesamiento multilingüe (especialmente chino), Function Calling mejorado, casos de uso de desarrollo frontend/web mejorados. |
Modelos destilados de DeepSeek
Transferir la capacidad de razonamiento de DeepSeek (lógica, matemáticas, pensamiento paso a paso, estabilidad CoT) a modelos densos más pequeños que sean más baratos, rápidos y ejecutables en GPUs de consumo.
| Modelo destilado | Modelo base | Capacidades reforzadas |
|---|---|---|
| R1-Distill Qwen 32B | Qwen 2.5–32B | CoT fuerte, mejor estabilidad lógica, razonamiento multilingüe mejorado |
| R1-0528 Qwen3 8B | Qwen3 8B | Alta precisión de razonamiento (AIME 86%), CoT eficiente, inferencia rápida |
| R1-Distill Qwen 7B | Qwen 2.5 Math-7B | Precisión matemática excepcional (MATH-500 92.8%), razonamiento estructurado paso a paso |
| R1-Distill Llama 8B | Llama-8B | Mejor seguimiento de instrucciones + comportamiento de razonamiento compacto |
| R1-Distill Llama 70B | Llama-70B | Razonamiento general sólido, CoT estable de formato largo, salidas consistentes |
Ecosistema de modelos Qwen
La familia Qwen (Qwen 2.5 y Qwen 3) ofrece una gama altamente flexible de modelos desde 0.6B hasta 480B parámetros, enfatizando el soporte multilingüe, el manejo extenso de contexto y variantes especializadas para codificación, embeddings y tareas multimodales.
Modelos emblemáticos de Qwen
| Variante | Parámetros totales / activos | Ventana de contexto | Enfoque / características clave |
|---|---|---|---|
| Qwen3-Coder 480B-A35B-Instruct | 480B / 35B (MoE) | 256K nativo, extensible a ~1M tokens | Codificación agente y comprensión de repositorios multiarchivo; optimizado para llamadas a función/uso de herramientas; solo modo sin pensamiento |
| Qwen3-VL-235B-A22B | 235B / 22B (MoE) | 256K nativo (extensible a ~1M) | Modelo multimodal visión-lenguaje (imágenes/videos); destaca en visual-a-código, razonamiento 3D, OCR; tiene variantes Instruct/Thinking |
| Qwen3 32B | 32B / denso | 128K tokens | Razonamiento de propósito general + soporte multilingüe; backbone denso para despliegue de menor costo |
| Qwen2.5-72B Instruct | 72B (variante densa o MoE) | 128K tokens | Fuerte soporte multilingüe (29+ idiomas); |
Modelos eficientes Qwen 3
La serie Qwen 3 introdujo un conjunto completo de modelos más pequeños, todos compatibles con los “Modos de pensamiento híbrido” altamente eficientes (Thinking vs. Non-Thinking) y amplio soporte multilingüe (119 idiomas).
| Variante | Parámetros totales | Ventana de contexto | Enfoque / características clave |
|---|---|---|---|
| Qwen3-14B | 14.8B | 32,768 tokens nativos; extensible hasta 131,072 | Modelo mediano robusto de propósito general; admite modos “thinking” y “non-thinking”; capacidades multilingües y de agente |
| Qwen3-8B | 8.19B | 128K tokens | Modelo de razonamiento ligero; competitivo en tareas de matemáticas y razonamiento general |
| Qwen3-4B | 4.0B | 32K tokens nativos (extensible) | Optimizado para eficiencia; despliegues de bajos recursos, manteniendo un rendimiento sólido |
| Qwen3-1.7B | 1.7B | 32K tokens | Adecuado para uso en edge / chatbots rápidos; huella mínima |
| Qwen3-0.6B | 0.6B | 32K tokens | Modelo ultraligero para despliegue de alta concurrencia / en dispositivo |
Modelos RAG Qwen 3
La línea Qwen3 Embedding refleja un reconocimiento de que recuperación + embeddings + flujos de trabajo aumentados por recuperación son centrales en las aplicaciones modernas de IA (búsqueda, preguntas y respuestas, RAG, código).
| Variante | Parámetros totales / activos | Ventana de contexto | Enfoque / características clave |
|---|---|---|---|
| Qwen3-Embedding 8B | 8B | 32K tokens | Modelo de embedding de texto; multilingüe (>100 idiomas); soporte de entrada larga; dimensiones de embedding configurables hasta 4096; destaca en benchmark MTEB (70.58) |
| Qwen3-Reranker 8B | 8B | 32K tokens | Modelo de reranking cross-encoder; ordena documentos recuperados por relevancia en pipelines RAG; alta precisión en recuperación multilingüe |
¿Cómo acceder a DeepSeek y Qwen de forma rápida y económica?
1. Interfaz web (La más fácil para principiantes)
2. Acceso a la API (Para desarrolladores)
Paso 1: Inicia sesión y accede a la Biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página “Settings” y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico para tu lenguaje de programación.
Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
3. Despliegue local (Usuarios avanzados)
| Modelo | VRAM total (inferencia FP16) | Configuración mínima de consumo |
|---|---|---|
| DeepSeek-V3 / R1 / V3.1 671B MoE | ~780–820 GB | 8× RTX 4090 (24 GB) apenas posible con descarga pesada |
| DeepSeek-R1-0528 685B | ~800–850 GB | 8× H100 80 GB (ajustado) |
| DeepSeek-V3-0324 671B | ~780–820 GB | 8× RTX 4090 (24 GB) apenas posible con descarga pesada |
| Modelo | Cuantización | VRAM requerida | Configuración de consumo factible |
|---|---|---|---|
| DeepSeek-R1/V3 671B | 4-bit (NF4/GPTQ/AWQ) | 170–190 GB | 8× RTX 4090 o 4× H100 80 GB |
| DeepSeek-R1/V3 671B | INT8 | 340–380 GB | 6–8× RTX 4090 o 4× A100/H100 80 GB |
| Modelo | VRAM (FP16) | GPU de consumo que puede ejecutarlo |
|---|---|---|
| R1-Distill-Qwen-32B | 64 GB | 2× RTX 4090 |
| R1-0528-Qwen3-8B / Llama-8B | 16 GB | 1× RTX 4090 / 3090 Ti |
| R1-Distill-Qwen-7B Math | 14 GB | 1× RTX 4080/4090 |
| R1-Distill-Llama-70B | 140 GB | 4× RTX 4090 o 2× A100 80 GB |
| Modelo | VRAM total (FP16/BF16) | Configuración mínima de consumo |
|---|---|---|
| Qwen3-Coder 480B MoE | 560–600 GB (35B activos) | 8× H100 80 GB |
| Qwen3-VL-235B MoE | 280–320 GB (22B activos) | 4× H100 80 GB |
| Qwen2.5-72B / Qwen3-32B Denso | 140–160 GB | 4× RTX 4090 o 2× A100 80 GB |
| Qwen3-14B | 28–32 GB | 1× RTX 4090 |
| Qwen3-8B | 16–18 GB | 1× RTX 4080/4090 |
| Qwen3-4B | 8–10 GB | 1× RTX 4060 Ti / 4070 |
| Qwen3-1.7B y 0.6B | 4 GB | Teléfonos móviles, RTX 3050 |
| Qwen3-Embedding / Reranker 8B | 16 GB | 1× RTX 4090 |
Pasos de instalación:
- Descarga los pesos del modelo desde HuggingFace o ModelScope
- Elige el framework de inferencia: vLLM o SGLang compatibles
- Sigue la guía de despliegue en el repositorio oficial de GitHub
4. Integración
Usando CLI como Trae, Claude Code, Qwen Code
Si deseas usar los mejores modelos de Novita AI (como Qwen3-Coder, Kimi K2, DeepSeek R1) para asistencia de codificación con IA en tu entorno local o IDE, el proceso es simple: obtén tu clave API, instala la herramienta, configura las variables de entorno y comienza a codificar.
Para comandos de configuración detallados y ejemplos, consulta los tutoriales oficiales:
- Trae: Guía paso a paso para acceder a modelos de IA en tu IDE
- Claude Code: Cómo usar Kimi-K2 en Claude Code en Windows, Mac y Linux
- Qwen Code: Cómo usar la API compatible con OpenAI en Qwen Code (¡Configuración en 60s!)
Flujos de trabajo multiagente con OpenAI Agents SDK
Construye sistemas multiagente avanzados integrando Novita AI con OpenAI Agents SDK:
- Plug-and-play: Usa los LLM de Novita AI en cualquier flujo de trabajo de OpenAI Agents.
- Compatible con handoffs, enrutamiento y uso de herramientas: Diseña agentes que puedan delegar, triage o ejecutar funciones, todo impulsado por los modelos de Novita AI.
- Integración con Python: Simplemente establece el endpoint del SDK a
https://api.novita.ai/v3/openaiy usa tu clave API.
Conectar API en plataformas de terceros
API compatible con OpenAI: Disfruta de una migración e integración sin problemas con herramientas como Cline y Cursor, diseñadas para el estándar de API de OpenAI.
Hugging Face: Usa modelos en Spaces, pipelines o con la biblioteca Transformers a través de los endpoints de Novita AI.
Frameworks de agentes y orquestación: Conecta fácilmente Novita AI con plataformas asociadas como Continue, AnythingLLM, LangChain, Dify y Langflow a través de conectores oficiales y guías de integración paso a paso.
DeepSeek apunta a un poder de razonamiento máximo con modelos como DeepSeek-V3, DeepSeek-R1 y DeepSeek-V3.1, respaldados por destilaciones ligeras como R1-Distill-Qwen-32B y R1-Distill-Qwen3-8B. Qwen busca versatilidad y preparación empresarial con modelos como Qwen3-Coder-480B-A35B-Instruct, Qwen3-VL-235B-A22B, modelos eficientes desde Qwen3-14B hasta Qwen3-0.6B, y modelos orientados a RAG como Qwen3-Embedding-8B y Qwen3-Reranker-8B. En resumen: DeepSeek optimiza para rendimiento de razonamiento profundo; Qwen optimiza para una caja de herramientas de IA completa, desplegable, multilingüe y multimodal.
Preguntas frecuentes
¿Cuál es la fortaleza principal de DeepSeek-V3 en comparación con los modelos Qwen?
DeepSeek-V3 utiliza una arquitectura MoE con MLA y MTP para maximizar la calidad del razonamiento, mientras que los modelos Qwen se centran más en la cobertura multilingüe, el rango de despliegue y la versatilidad de las aplicaciones.
¿Por qué alguien elegiría DeepSeek-V3.1 sobre Qwen3-14B?
DeepSeek-V3.1 ofrece modos de razonamiento híbridos “Think / Non-Think” optimizados para la profundidad de la cadena de pensamiento, mientras que Qwen3-14B prioriza la inferencia de propósito general, tareas multilingües y un despliegue eficiente.
¿Qué ecosistema de modelos es mejor para flujos de trabajo con documentos largos?
Qwen destaca con modelos como Qwen3-Coder-480B-A35B-Instruct y Qwen3-VL-235B-A22B que ofrecen contexto de hasta 256K–1M tokens, mientras que DeepSeek se centra en el razonamiento en lugar del manejo de documentos de contexto ultralargo.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona una GPU en la nube asequible y confiable para construir y escalar.



