

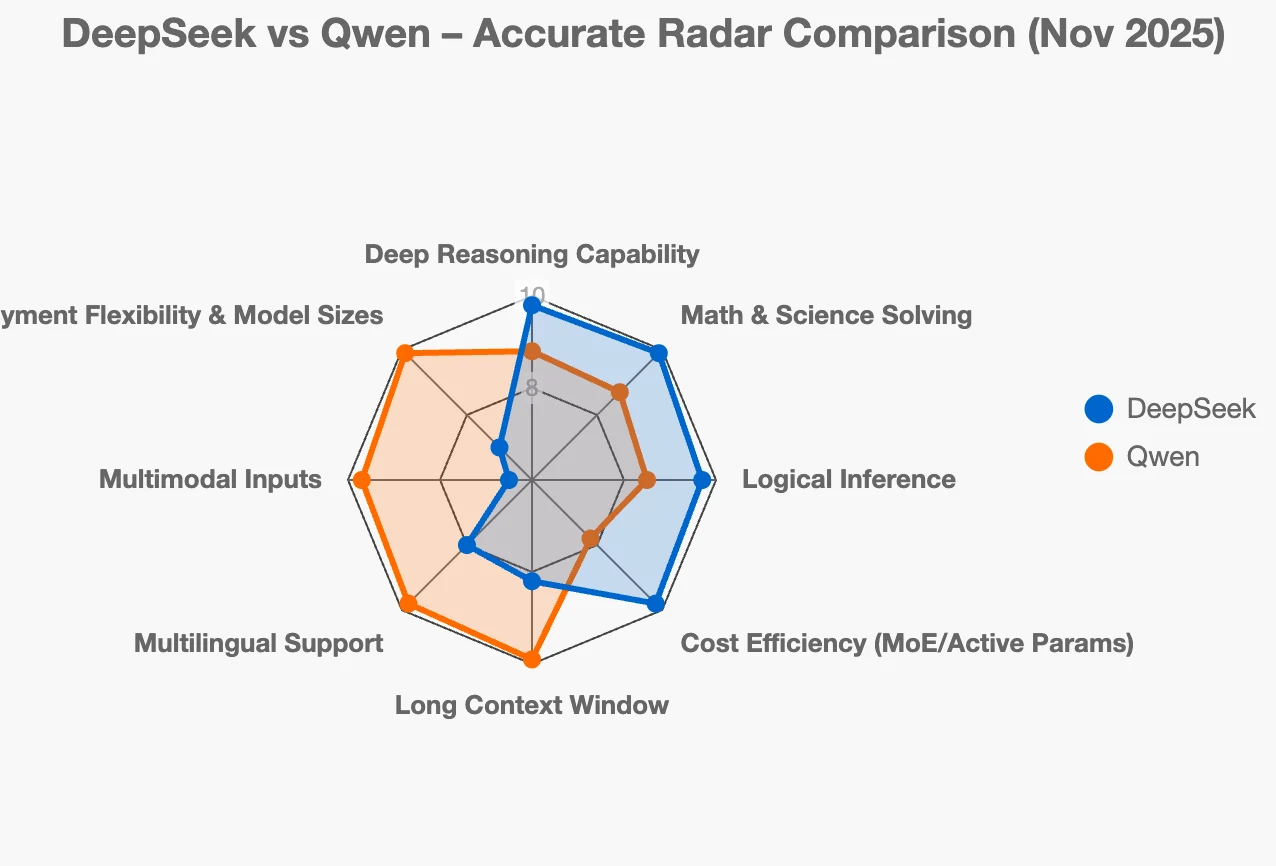
La plupart des utilisateurs qui comparent DeepSeek et Qwen sont confus, car les deux écosystèmes sont performants, open source et en évolution rapide — pourtant ils sont conçus pour résoudre des problèmes totalement différents. DeepSeek se concentre sur le raisonnement profond, la stabilité du raisonnement pas à pas (chain-of-thought), la précision en mathématiques/codage et l’efficacité basée sur MoE, tandis que la famille Qwen se concentre sur le déploiement full-stack, couvrant tout, des modèles MoE géants aux petits modèles pour périphériques edge, en passant par le multimodal, le RAG, les embeddings, le codage et des outils prêts pour l’entreprise.
Cet article clarifie ces différences en examinant leurs modèles phares, leurs versions distillées, leurs séries efficaces, leurs modèles RAG et leurs exigences matérielles, afin que les utilisateurs puissent comprendre ce que chaque écosystème cherche réellement à accomplir et lequel correspond à leurs besoins opérationnels.
Que cherchent réellement à faire DeepSeek et Qwen ?
Si vous vous demandez quel écosystème de LLM open source chinois correspond à vos besoins, les deux acteurs majeurs actuellement sont l’écosystème DeepSeek et la famille Qwen. Ils sont tous deux extrêmement performants, mais ils résolvent des problèmes différents et évoluent dans des directions distinctes.
DeepSeek : « Nous voulons des modèles capables de réellement penser en profondeur »
Considérez DeepSeek comme le « spécialiste du raisonnement ».
Ce qui leur importe le plus :
- Concevoir des modèles véritablement performants pour des raisonnements pas à pas complexes : démonstrations mathématiques, problèmes scientifiques, codage complexe, puzzles logiques.
- Pousser les limites du raisonnement pas à pas (chain-of-thought, CoT) pour que le modèle ne donne pas seulement l’impression d’être intelligent… il résout réellement le problème correctement et peut montrer son raisonnement.
- Utiliser des astuces intelligentes comme le mélange d’experts (Mixture-of-Experts, MoE) associé à l’apprentissage par renforcement, pour que le modèle soit puissant sans avoir à activer des milliards de paramètres pour chaque jeton (cela rend l’inférence moins chère et plus rapide).
- Publier des versions « distillées » plus petites de leurs meilleurs modèles de raisonnement pour que les particuliers et les petites entreprises puissent réellement les exécuter.
Les problèmes concrets qu’ils cherchent à résoudre :
- La plupart des modèles géants sont excellents pour rédiger des essais mais échouent toujours sur des questions de mathématiques ou de logique basiques. DeepSeek veut corriger cela.
- Plus gros n’est pas toujours mieux pour le raisonnement — ils cherchent à obtenir plus de puissance de raisonnement avec moins de paramètres actifs (un meilleur rapport qualité-prix pour votre GPU).
- Les modèles de raisonnement haut de gamme sont généralement trop chers à exécuter en dehors des grands laboratoires. DeepSeek veut démocratiser cette capacité.
- Lorsque vous avez besoin que le modèle explique comment il est parvenu à une réponse (droit, médecine, éducation, etc.), vous voulez un raisonnement pas à pas transparent — DeepSeek l’expose particulièrement bien.
Idéal pour : la recherche, l’éducation, les assistants de codage, les outils de mathématiques/sciences, toute situation où « obtenir la bonne réponse + montrer le raisonnement » importe plus que d’être un chatbot généraliste.
Qwen : « Nous voulons une boîte à outils complète pour les entreprises réelles »
Qwen est plus comme le « couteau suisse » des LLM.
Ce qui leur importe le plus :
- Proposer toutes les tailles et toutes les variantes dont vous pourriez avoir besoin : petits modèles pour téléphones, modèles de taille moyenne pour serveurs, modèles géants pour une puissance maximale, versions denses ou MoE, modèles de vision, modèles de codage, modèles d’embedding, modèles de reranking… tout ce que vous voulez.
- Des performances multilingues solides (en particulier chinois + plus de 100 autres langues).
- Des fenêtres de contexte très longues (jusqu’à 128k voire 1M de jetons dans certaines versions).
- Un déploiement prêt pour l’entreprise : API facile, options sur site (on-prem), support pour les périphériques edge, sécurité et outils de niveau entreprise.
Les problèmes concrets qu’ils cherchent à résoudre :
- Les entreprises ne veulent pas seulement un chatbot — elles ont besoin de compréhension de documents, de recherche, de génération augmentée par récupération (RAG), d’applications image+texte, de support client multilingue, etc. Qwen fournit toute la pile technologique.
- Les anciens modèles sont dépassés par les longs documents ou dysfonctionnent lorsque vous changez de langue. Qwen gère les deux cas avec aisance.
- Vous avez souvent besoin de petits modèles pour mobile/edge et de modèles géants pour des analyses lourdes — Qwen vous propose une gamme de tailles fluide pour que vous ne soyez jamais bloqué.
- Construire un système de recherche d’entreprise ou de base de connaissances approprié nécessite d’excellents embeddings + du reranking. Les modèles d’embedding et de reranking de Qwen sont parmi les meilleurs disponibles en open source.
Idéal pour : les moteurs de recherche d’entreprise, les chatbots de service client multilingues, les workflows comportant beaucoup de documents, les pipelines RAG, les applications combinant vision + texte, ou tout système de production où la fiabilité et le déploiement facile sont importants.
Alors, lequel choisir ?
- Si votre projet dépend entièrement du raisonnement logique, des mathématiques ou de la précision du code → optez pour DeepSeek (en particulier DeepSeek-R1 ou les nouveaux modèles de raisonnement DeepSeek-V3).
- Si vous construisez un produit réel avec de la recherche, des documents longs, plusieurs langues, des images, ou si vous avez besoin de modèles de 0,5B à 72B → optez pour Qwen.
Essayez les modèles maintenant !
Écosystème de modèles DeepSeek
Les modèles DeepSeek sont principalement conçus pour maximiser la puissance de raisonnement grâce à des architectures de mélange d’experts (Mixture-of-Experts, MoE) à grande échelle et des pipelines d’apprentissage par renforcement (Reinforcement Learning, RL) intensifs, ce qui donne des modèles précis et performants (671B à 685B paramètres) et des versions plus petites spécialisées (modèles Distill).
Modèles phares DeepSeek
Voici des résumés détaillés de l’architecture de chaque variante de modèle DeepSeek :
| Variante | Paramètres totaux / Paramètres activés | Fenêtre de contexte | Architecture clé et améliorations |
|---|---|---|---|
| DeepSeek V3 | 671B au total, 37B activés par jeton | 128k jetons | Architecture de mélange d’experts (MoE) ; utilise l’attention latente multi-têtes (Multi-Head Latent Attention, MLA) pour réduire la taille du cache KV ; utilise l’objectif de prédiction multi-jetons (Multi-Token Prediction, MTP) ; utilise un équilibrage de charge sans perte auxiliaire. |
| DeepSeek R1 | 671B au total, 37B activés par jeton |
128k jetons | Même architecture de base que V3 (MoE + MLA) mais avec un pipeline RL intensif (SFT → RL → SFT → RL) pour améliorer les capacités de raisonnement et logiques. |
| DeepSeek V3.1 | 671B au total, 37B activés par jeton |
128k jetons | Modes d’inférence hybrides : prend en charge les modes « Think » (raisonnement pas à pas) et « Non-Think » ; combine les capacités générales de V3 avec la force de raisonnement de R1 ; entraînement étendu sur du long contexte. |
| DeepSeek R1 0528 | 685B paramètres au total (sous-ensemble actif non spécifié) | 64k jetons | Version mise à jour de R1 avec un nombre de paramètres plus élevé et une fenêtre de contexte réduite à ~64k pour améliorer la vitesse/stabilité de l’inférence (plutôt que le 128k complet). (Données issues de la liste des variantes) |
| DeepSeek V3 0324 | 671B au total, 37B activés par jeton | 128k jetons | Même architecture que V3 mais optimisée pour le traitement multilingue (en particulier le chinois), appel de fonctions amélioré, cas d’usage de développement frontend/web améliorés. |
Modèles distillés DeepSeek
Transférez la capacité de raisonnement de DeepSeek (logique, mathématiques, raisonnement pas à pas, stabilité du CoT) vers des modèles denses plus petits, moins chers, plus rapides et exécutables sur des GPU grand public.
| Modèle distillé | Modèle de base | Capacités renforcées |
|---|---|---|
| R1-Distill Qwen 32B | Qwen 2.5–32B | CoT solide, meilleure stabilité logique, raisonnement multilingue amélioré |
| R1-0528 Qwen3 8B | Qwen3 8B | Haute précision de raisonnement (AIME 86%), CoT efficace, inférence rapide |
| R1-Distill Qwen 7B | Qwen 2.5 Math-7B | Précision mathématique exceptionnelle (MATH-500 92,8%), raisonnement pas à pas structuré |
| R1-Distill Llama 8B | Llama-8B | Meilleur respect des instructions + comportement de raisonnement compact |
| R1-Distill Llama 70B | Llama-70B | Raisonnement général solide, CoT long stable, sorties cohérentes |
Essayez les modèles maintenant !
Écosystème de modèles Qwen
La famille Qwen (Qwen 2.5 et Qwen 3) propose une gamme de modèles très flexible, de 0,6B à 480B paramètres, en mettant l’accent sur le support multilingue, la gestion d’un contexte étendu et des variantes spécialisées pour le codage, les embeddings et les tâches multimodales.
Modèles phares Qwen
| Variante | Paramètres totaux / Paramètres actifs | Fenêtre de contexte | Focus principal / Fonctionnalités |
|---|---|---|---|
| Qwen3-Coder 480B-A35B-Instruct | 480B / 35B (MoE) | 256k jetons natifs, extensible à ~1M de jetons | Codage agentiel et compréhension de dépôts multi-fichiers ; appel de fonctions/utilisation d’outils optimisée ; mode sans raisonnement uniquement |
| Qwen3-VL-235B-A22B | 235B / 22B (MoE) | 256k jetons natifs (extensible à ~1M) | Modèle vision-langage multimodal (images/vidéos) ; excelle dans la conversion visuelle vers code, le raisonnement 3D, l’OCR ; dispose de variantes Instruct/Thinking |
| Qwen3 32B | 32B / dense | 128k jetons | Raisonnement généraliste + support multilingue ; backbone dense pour un déploiement à moindre coût |
| Qwen2.5-72B Instruct | 72B (variante Dense ou MoE) | 128k jetons | Support multilingue solide (29+ langues) ; |
Modèles efficaces Qwen 3
La série Qwen 3 a introduit un ensemble complet de modèles plus petits, tous prenant en charge les « modes de raisonnement hybrides » très efficaces (Thinking vs Non-Thinking) et un support multilingue étendu (119 langues).
| Variante | Paramètres totaux | Fenêtre de contexte | Focus principal / Fonctionnalités |
|---|---|---|---|
| Qwen3-14B | 14,8B | 32 768 jetons natifs ; extensible jusqu’à 131 072 | Modèle de taille moyenne polyvalent et performant ; prend en charge les modes « thinking » et « non-thinking » ; capacités multilingues et agentielles |
| Qwen3-8B | 8,19B | 128k jetons | Modèle de raisonnement léger ; compétitif pour les tâches de mathématiques et de raisonnement général |
| Qwen3-4B | 4,0B | 32k jetons natifs (extensible) | Optimisé pour l’efficacité ; déploiements à faibles ressources, tout en maintenant des performances solides |
| Qwen3-1.7B | 1,7B | 32k jetons | Adapté aux usages edge / chatbots rapides ; empreinte minimale |
| Qwen3-0.6B | 0,6B | 32k jetons | Modèle ultra-léger pour des déploiements à haute concurrence / sur appareil |
Modèles RAG Qwen 3
La gamme Qwen3 Embedding reflète la reconnaissance que la récupération + les embeddings + les workflows augmentés par récupération sont centraux pour les applications d’IA modernes (recherche, questions-réponses, RAG, codage).
| Variante | Paramètres totaux / Actifs | Fenêtre de contexte | Focus principal / Fonctionnalités |
|---|---|---|---|
| Qwen3-Embedding 8B | 8B | 32k jetons | Modèle d’embedding de texte ; multilingue (>100 langues) ; support d’entrées longues ; dimensions d’embedding configurables jusqu’à 4096 ; excelle sur le benchmark MTEB (70,58) |
| Qwen3-Reranker 8B | 8B | 32k jetons | Modèle de reranking cross-encoder ; trie les documents récupérés par pertinence dans les pipelines RAG ; haute précision dans la récupération multilingue |
Essayez les modèles maintenant !
Comment accéder à DeepSeek et Qwen de manière rapide et peu coûteuse ?
1. Interface web (la plus simple pour les débutants)
Essayez les modèles maintenant !
2. Accès API (pour les développeurs)
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Essayez les modèles maintenant !
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec les LLM de Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
3. Déploiement local (utilisateurs avancés)
| Modèle | VRAM totale (inférence FP16) | Configuration grand public minimale |
|---|---|---|
| DeepSeek-V3 / R1 / V3.1 671B MoE | ~780 à 820 Go | 8× RTX 4090 (24 Go) à peine possible avec un déchargement lourd |
| DeepSeek-R1-0528 685B | ~800 à 850 Go | 8× H100 80 Go (serré) |
| DeepSeek-V3-0324 671B | ~780 à 820 Go | 8× RTX 4090 (24 Go) à peine possible avec un déchargement lourd |
| Modèle | Quantification | VRAM requise | Configuration grand public réalisable |
|---|---|---|---|
| DeepSeek-R1/V3 671B | 4 bits (NF4/GPTQ/AWQ) | 170 à 190 Go | 8× RTX 4090 ou 4× H100 80 Go |
| DeepSeek-R1/V3 671B | INT8 | 340 à 380 Go | 6 à 8× RTX 4090 ou 4× A100/H100 80 Go |
| Modèle | VRAM (FP16) | GPU grand public pouvant l’exécuter |
|---|---|---|
| R1-Distill-Qwen-32B | 64 Go | 2× RTX 4090 |
| R1-0528-Qwen3-8B / Llama-8B | 16 Go | 1× RTX 4090 / 3090 Ti |
| R1-Distill-Qwen-7B Math | 14 Go | 1× RTX 4080/4090 |
| R1-Distill-Llama-70B | 140 Go | 4× RTX 4090 ou 2× A100 80 Go |
| Modèle | VRAM totale (FP16/BF16) | Configuration grand public minimale |
|---|---|---|
| Qwen3-Coder 480B MoE | 560 à 600 Go (35B actifs) | 8× H100 80 Go |
| Qwen3-VL-235B MoE | 280 à 320 Go (22B actifs) | 4× H100 80 Go |
| Qwen2.5-72B / Qwen3-32B Dense | 140 à 160 Go | 4× RTX 4090 ou 2× A100 80 Go |
| Qwen3-14B | 28 à 32 Go | 1× RTX 4090 |
| Qwen3-8B | 16 à 18 Go | 1× RTX 4080/4090 |
| Qwen3-4B | 8 à 10 Go | 1× RTX 4060 Ti / 4070 |
| Qwen3-1.7B et 0,6B | 4 Go | Téléphones mobiles, RTX 3050 |
| Qwen3-Embedding / Reranker 8B | 16 Go | 1× RTX 4090 |
Étapes d’installation :
- Téléchargez les poids des modèles depuis HuggingFace ou ModelScope
- Choisissez le framework d’inférence : vLLM ou SGLang sont pris en charge
- Suivez le guide de déploiement dans le dépôt GitHub officiel
4. Intégration
Utilisation d’outils CLI comme Trae, Claude Code, Qwen Code
Si vous souhaitez utiliser les meilleurs modèles de Novita AI (comme Qwen3-Coder, Kimi K2, DeepSeek R1) pour l’assistance au codage par IA dans votre environnement local ou votre IDE, le processus est simple : récupérez votre clé API, installez l’outil, configurez les variables d’environnement et commencez à coder.
Pour des commandes d’installation détaillées et des exemples, consultez les tutoriels officiels :
- Trae : Guide pas à pas pour accéder aux modèles d’IA dans votre IDE
- Claude Code : Comment utiliser Kimi-K2 dans Claude Code sur Windows, Mac et Linux
- Qwen Code : Comment utiliser l’API compatible OpenAI dans Qwen Code (installation en 60s !)
Flux de travail multi-agents avec le SDK OpenAI Agents
Construisez des systèmes multi-agents avancés en intégrant Novita AI avec le SDK OpenAI Agents :
- Prêt à l’emploi : Utilisez les LLM de Novita AI dans tout flux de travail OpenAI Agents.
- Prend en charge les transferts, le routage et l’utilisation d’outils : Concevez des agents qui peuvent déléguer, trier ou exécuter des fonctions, le tout alimenté par les modèles de Novita AI.
- Intégration Python : Définissez simplement le point de terminaison du SDK sur
https://api.novita.ai/v3/openaiet utilisez votre clé API.
Connecter l’API sur des plateformes tierces
API compatible OpenAI : Profitez d’une migration et d’une intégration sans problème avec des outils comme Cline et Cursor, conçus pour la norme d’API OpenAI.
Hugging Face : Utilisez les modèles dans Spaces, les pipelines ou avec la bibliothèque Transformers via les points de terminaison de Novita AI.
Frameworks d’agents et d’orchestration : Connectez facilement Novita AI à des plateformes partenaires comme Continue, AnythingLLM,LangChain, Dify et Langflow via des connecteurs officiels et des guides d’intégration pas à pas.
DeepSeek cible une puissance de raisonnement maximale avec des modèles comme DeepSeek-V3, DeepSeek-R1 et DeepSeek-V3.1, soutenus par des distillations légères comme R1-Distill-Qwen-32B et R1-Distill-Qwen3-8B. Qwen vise la polyvalence et la préparation pour l’entreprise avec des modèles comme Qwen3-Coder-480B-A35B-Instruct, Qwen3-VL-235B-A22B, des modèles efficaces de Qwen3-14B à Qwen3-0.6B, et des modèles orientés RAG comme Qwen3-Embedding-8B et Qwen3-Reranker-8B. En résumé : DeepSeek est optimisé pour les performances de raisonnement profond ; Qwen est optimisé pour une boîte à outils IA complète, déployable, multilingue et multimodale.
Questions fréquemment posées
Quelle est la force principale de DeepSeek-V3 par rapport aux modèles Qwen ?
DeepSeek-V3 utilise une architecture MoE avec MLA et MTP pour maximiser la qualité du raisonnement, tandis que les modèles Qwen se concentrent davantage sur la couverture multilingue, la gamme de déploiement et la polyvalence des applications.
Pourquoi quelqu’un choisirait-il DeepSeek-V3.1 plutôt que Qwen3-14B ?
DeepSeek-V3.1 propose des modes de raisonnement hybrides « Think / Non-Think » optimisés pour la profondeur du raisonnement pas à pas, tandis que Qwen3-14B priorise l’inférence généraliste, les tâches multilingues et le déploiement efficace.
Quel écosystème de modèles est meilleur pour les workflows avec des documents longs ?
Qwen excelle avec des modèles comme Qwen3-Coder-480B-A35B-Instruct et Qwen3-VL-235B-A22B offrant un contexte allant jusqu’à 256k à 1M de jetons, tandis que DeepSeek se concentre sur le raisonnement plutôt que sur le traitement de documents à contexte ultra long.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA grâce à notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle des projets.



