

Большинство пользователей, сравнивающих DeepSeek и Qwen, испытывают путаницу, поскольку обе экосистемы являются мощными, с открытым исходным кодом и быстро развивающимися — при этом они созданы для решения совершенно разных задач. DeepSeek делает упор на глубокое рассуждение, стабильность цепочки рассуждений, точность в математике и программировании, а также эффективность на основе архитектуры MoE (смеси экспертов), тогда как семейство Qwen ориентировано на полноценное развертывание (full-stack deployment), охватывая всё: от огромных моделей MoE до компактных моделей для edge-устройств, а также мультимодальные возможности, RAG (генерация с усилением поиском), эмбеддинги, инструменты для программирования и корпоративные решения.
В этой статье мы разбираем эти различия, рассматривая флагманские модели обеих экосистем, дистиллированные варианты, эффективные серии, RAG-модели и требования к оборудованию, чтобы пользователи могли понять, на что действительно направлена каждая экосистема и какая из них подходит для их операционных нужд.
DeepSeek против Qwen: На что на самом деле направлены эти экосистемы?
Если вы хотите понять, какая открытая экосистема китайских LLM подходит для ваших задач, то двумя главными игроками на рынке сейчас являются семейства DeepSeek и Qwen. Обе они чрезвычайно мощные, но решают разные задачи и развиваются в разных направлениях.
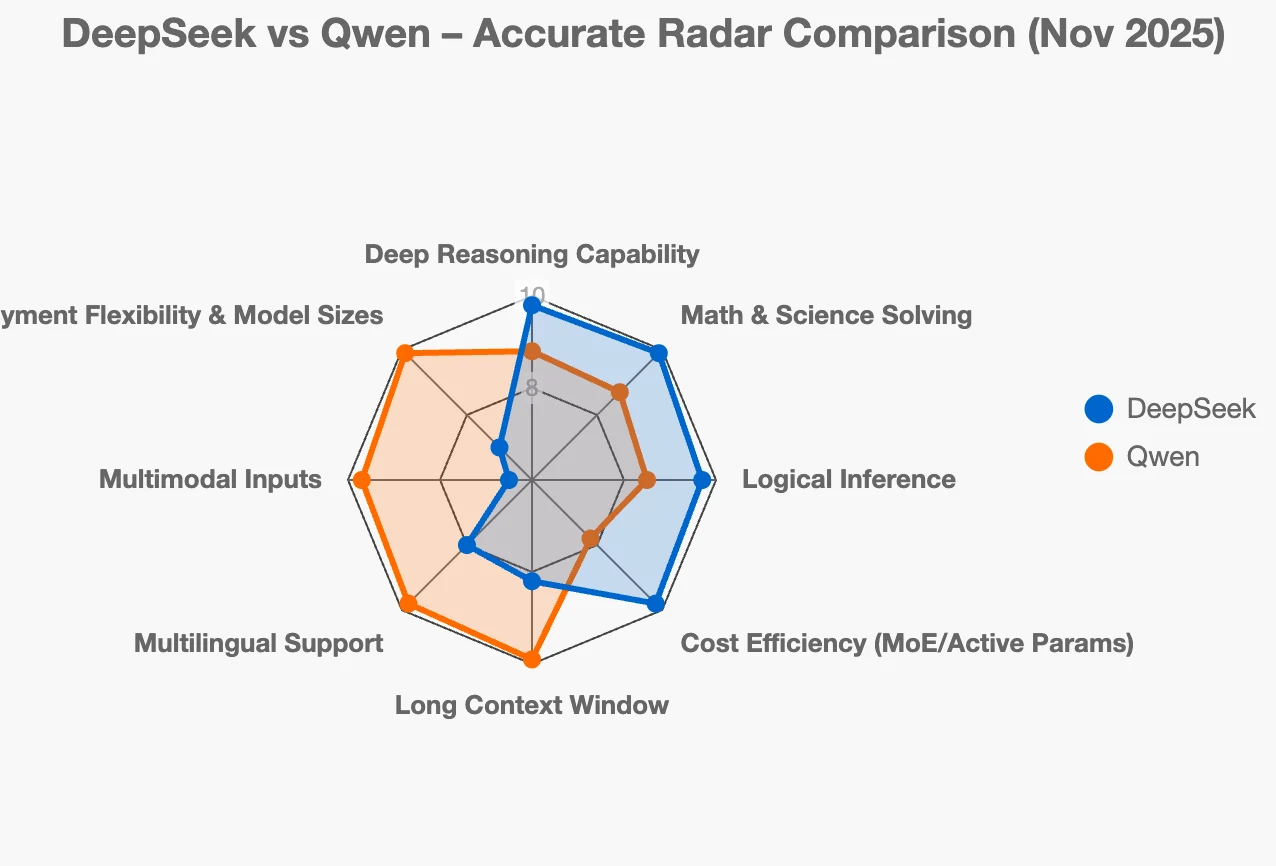
DeepSeek: «Мы хотим модели, которые могут действительно глубоко мыслить»
Представьте DeepSeek как «специалиста по рассуждениям». Их главные приоритеты:
- Создание моделей, которые genuinely хорошо справляются со сложным пошаговым мышлением — математическими доказательствами, научными задачами, сложным программированием, логическими головоломками.
- Расширение возможностей рассуждений по цепочке (chain-of-thought, CoT), чтобы модель не просто звучала умно… она действительно правильно решает задачу и может показать ход своих рассуждений.
- Использование эффективных подходов, таких как архитектура смеси экспертов (Mixture-of-Experts, MoE) + обучение с подкреплением, чтобы модель была мощной, но не требовала активации миллиардов параметров для каждого отдельного токена (это снижает стоимость и ускоряет вывод).
- Выпуск более компактных «дистиллированных» версий своих лучших моделей для рассуждений, чтобы обычные пользователи и небольшие компании могли их запускать.
Реальные задачи, которые они решают:
- Большинство гигантских моделей хорошо справляются с написанием эссе, но всё ещё ошибаются в базовых математических или логических задачах. DeepSeek хочет исправить это.
- Для рассуждений bigger не всегда значит better — они пытаются получить больше возможностей для рассуждений из меньшего количества активных параметров (больше производительности за каждый вложенный в GPU доллар).
- Мощные модели для рассуждений обычно слишком дороги в запуске за пределами крупных лабораторий. DeepSeek хочет сделать эти возможности доступными для всех.
- Когда вам нужно, чтобы модель объяснила, как она пришла к ответу (в юридической, медицинской, образовательной сферах и т.д.), вам нужна прозрачная цепочка рассуждений — DeepSeek отлично предоставляет такую возможность.
Лучше всего подходит для: научных исследований, образования, ассистентов программирования, инструментов для математики и естественных наук, любых сценариев, где «получение правильного ответа + демонстрация хода рассуждений» важнее, чем быть универсальным чат-ботом.
Qwen: «Мы хотим предоставить полный набор инструментов для реальных компаний»
Qwen больше похож на «швейцарский нож» в мире LLM. Их главные приоритеты:
- Предложение моделей любого размера и специализации, которые могут вам понадобиться: компактные модели для телефонов, средние для серверов, огромные для максимальной производительности, плотные версии или на основе MoE, vision-модели, модели для программирования, эмбеддинги, модели для переранжирования… любая нужная вам версия.
- Высокая производительность в многоязычных задачах (особенно китайский + более 100 других языков).
- Очень длинные контекстные окна (до 128k, а в некоторых версиях даже до 1 млн токенов).
- Готовность к корпоративному развертыванию: простой API, возможность развертывания на собственных серверах (on-prem), поддержка edge-устройств, корпоративный уровень безопасности и инструменты.
Реальные задачи, которые они решают:
- Компаниям нужен не просто чат-бот — им требуется понимание документов, поиск, генерация с усилением поиском (RAG), приложения с обработкой изображений и текста, многоязычная поддержка клиентов и т.д. Qwen предоставляет весь необходимый стек технологий.
- Старые модели «задыхаются» на длинных документах или дают сбой при смене языка. Qwen справляется с обеими задачами без проблем.
- Часто для мобильных/edge-устройств нужны компактные модели, а для тяжёлой аналитики — огромные. Qwen предлагает плавный диапазон размеров моделей, так что вы никогда не окажетесь в тупике.
- Для построения полноценной корпоративной поисковой системы или системы управления знаниями требуются качественные эмбеддинги + переранжирование. Модели для эмбеддингов и переранжирования от Qwen являются одними из лучших среди открытых решений.
Лучше всего подходит для: корпоративных поисковых систем, многоязычных ботов поддержки клиентов, рабочих процессов с большим объёмом документов, RAG-конвейеров, приложений, сочетающих обработку изображений и текста, или любых производственных систем, где важны надёжность и простота развертывания.
Какую экосистему выбрать?
- Если успех вашего проекта зависит от логических рассуждений, точности в математике или программировании — выбирайте DeepSeek (в особенности модели DeepSeek-R1 или новые модели для рассуждений DeepSeek-V3).
- Если вы создаёте реальный продукт с поиском, обработкой длинных документов, поддержкой нескольких языков, обработкой изображений или вам нужны модели от 0,5B до 72B параметров — выбирайте Qwen.
Экосистема моделей DeepSeek
Модели DeepSeek в первую очередь ориентированы на максимизацию мощности рассуждений за счёт крупномасштабных архитектур смеси экспертов (Mixture-of-Experts, MoE) и интенсивных конвейеров обучения с подкреплением (Reinforcement Learning, RL), в результате чего получаются точные высокопроизводительные модели (от 671B до 685B параметров) и специализированные компактные версии (дистиллированные модели).
Флагманские модели DeepSeek
Ниже приведены подробные описания архитектуры каждой версии модели DeepSeek:
| Вариант | Общее количество параметров / Активных параметров на токен | Размер контекстного окна | Ключевые особенности архитектуры и улучшения |
|---|---|---|---|
| DeepSeek V3 | 671B всего, 37B активных на токен | 128K токенов | Архитектура смеси экспертов (MoE); использует Multi-Head Latent Attention (MLA) для уменьшения размера KV-кэша; использует цель Multi-Token Prediction (MTP); применяет балансировку нагрузки без вспомогательных потерь. |
| DeepSeek R1 | 671B всего, 37B активных на токен |
128K токенов | Та же базовая архитектура, что и у V3 (MoE + MLA), но с интенсивным RL-конвейером (SFT → RL → SFT → RL) для улучшения возможностей рассуждений и логики. |
| DeepSeek V3.1 | 671B всего, 37B активных на токен |
128K токенов | Гибридные режимы вывода: поддерживает режимы «Think» (цепочка рассуждений) и «Non-Think»; сочетает общие возможности V3 с мощью рассуждений R1; расширенное обучение на длинных контекстах. |
| DeepSeek R1 0528 | 685B всего параметров (активное подмножество не указано) | 64K токенов | Обновлённая версия R1 с увеличенным общим количеством параметров и уменьшенным контекстным окном до ~64K для повышения скорости и стабильности вывода (вместо полных 128K). (Данные из списка вариантов) |
| DeepSeek V3 0324 | 671B всего, 37B активных на токен | 128K токенов | Та же архитектура, что и у V3, но оптимизирована для многоязычной обработки (особенно китайского), улучшенная поддержка вызова функций (Function Calling), оптимизирована для задач фронтенд- и веб-разработки. |
Дистиллированные модели DeepSeek
Перенос возможностей рассуждений DeepSeek (логика, математика, пошаговое мышление, стабильность CoT) в более компактные плотные модели, которые дешевле в запуске, быстрее и работают на потребительских GPU.
| Дистиллированная модель | Базовая модель | Улучшенные возможности |
|---|---|---|
| R1-Distill Qwen 32B | Qwen 2.5–32B | Высокая стабильность CoT, улучшенная стабильность логики, улучшенные многоязычные рассуждения |
| R1-0528 Qwen3 8B | Qwen3 8B | Высокая точность рассуждений (AIME 86%), эффективный CoT, быстрый вывод |
| R1-Distill Qwen 7B | Qwen 2.5 Math-7B | Исключительная точность в математике (MATH-500 92,8%), структурированные пошаговые рассуждения |
| R1-Distill Llama 8B | Llama-8B | Улучшенное следование инструкциям + компактное поведение при рассуждениях |
| R1-Distill Llama 70B | Llama-70B | Мощные общие рассуждения, стабильный длинный CoT, последовательные выводы |
Экосистема моделей Qwen
Семейство Qwen (Qwen 2.5 и Qwen 3) предлагает очень гибкий диапазон моделей от 0,6B до 480B параметров, с упором на многоязычную поддержку, обработку больших контекстов и специализированные варианты для программирования, создания эмбеддингов и мультимодальных задач.
Флагманские модели Qwen
| Вариант | Общее количество параметров / Активных параметров | Размер контекстного окна | Ключевые особенности и возможности |
|---|---|---|---|
| Qwen3-Coder 480B-A35B-Instruct | 480B / 35B (MoE) | 256K нативно, расширяемо до ~1M токенов | Агентное программирование и понимание многофайловых репозиториев; оптимизирована для вызова функций и использования инструментов; поддерживает только режим без рассуждений (non-thinking) |
| Qwen3-VL-235B-A22B | 235B / 22B (MoE) | 256K нативно (расширяемо до ~1M) | Мультимодальная vision-language модель (обработка изображений и видео); отлично справляется с преобразованием визуальных данных в код, 3D-рассуждениями, OCR; доступны варианты Instruct и Thinking |
| Qwen3 32B | 32B / плотная | 128K токенов | Универсальные рассуждения + многоязычная поддержка; плотная backbone-архитектура для более дешёвого развертывания |
| Qwen2.5-72B Instruct | 72B (плотная или MoE-вариант) | 128K токенов | Мощная многоязычная поддержка (более 29 языков); |
Эффективные модели Qwen 3
В серии Qwen 3 представлен полный набор компактных моделей, все из которых поддерживают высокоэффективные «гибридные режимы мышления» (режим рассуждений Thinking и режим без рассуждений Non-Thinking), а также широкую многоязычную поддержку (119 языков).
| Вариант | Общее количество параметров | Размер контекстного окна | Ключевые особенности и возможности |
|---|---|---|---|
| Qwen3-14B | 14,8B | 32 768 токенов нативно; расширяемо до 131 072 | Мощная универсальная модель среднего размера; поддерживает режимы «рассуждений» и «без рассуждений»; многоязычные возможности и поддержка агентных сценариев |
| Qwen3-8B | 8,19B | 128K токенов | Лёгкая модель для рассуждений; показывает конкурентоспособные результаты в математических и общих задачах на рассуждения |
| Qwen3-4B | 4,0B | 32K токенов нативно (расширяемо) | Оптимизирована для эффективности; подходит для развертывания на оборудовании с ограниченными ресурсами, сохраняя высокую производительность |
| Qwen3-1.7B | 1,7B | 32K токенов | Подходит для edge-сценариев / быстрых чат-ботов; минимальное потребление ресурсов |
| Qwen3-0.6B | 0,6B | 32K токенов | Ультралёгкая модель для развертывания с высокой нагрузкой / непосредственно на устройствах |
RAG-модели Qwen 3
Линейка эмбеддингов Qwen3 отражает признание того, что поиск + эмбеддинги + рабочие процессы с усилением поиском являются центральными для современных AI-приложений (поиск, ответы на вопросы, RAG, программирование).
| Вариант | Общее количество параметров / Активных | Размер контекстного окна | Ключевые особенности и возможности |
|---|---|---|---|
| Qwen3-Embedding 8B | 8B | 32K токенов | Текстовая эмбеддинг-модель; многоязычная (более 100 языков); поддержка длинных входных данных; настраиваемая размерность эмбеддингов до 4096; показывает высокие результаты на бенчмарке MTEB (70,58) |
| Qwen3-Reranker 8B | 8B | 32K токенов | Модель переранжирования на основе cross-encoder; сортирует найденные документы по релевантности в RAG-конвейерах; высокая точность при многоязычном поиске |
Как получить доступ к DeepSeek и Qwen дёшево и быстро?
1. Веб-интерфейс (самый простой для начинающих)
2. Доступ по API (для разработчиков)
Шаг 1: Войдите в аккаунт и перейдите в библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.

Шаг 2: Выберите нужную модель
Просмотрите доступные варианты и выберите модель, подходящую для ваших задач.
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 4: Получите ваш API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Settings» (Настройки), вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с LLM от Novita AI. Ниже приведён пример использования API завершения чата для пользователей Python.
3. Локальное развертывание (для продвинутых пользователей)
| Модель | Общий объём VRAM (вывод в FP16) | Минимальная конфигурация для потребительского оборудования |
|---|---|---|
| DeepSeek-V3 / R1 / V3.1 671B MoE | ~780–820 ГБ | 8× RTX 4090 (24 ГБ) практически возможно только с тяжёлым выгрузкой (offloading) |
| DeepSeek-R1-0528 685B | ~800–850 ГБ | 8× H100 80 ГБ (очень мало места) |
| DeepSeek-V3-0324 671B | ~780–820 ГБ | 8× RTX 4090 (24 ГБ) практически возможно только с тяжёлым выгрузкой (offloading) |
| Модель | Квантизация | Требуемый объём VRAM | Доступная конфигурация для потребительского оборудования |
|---|---|---|---|
| DeepSeek-R1/V3 671B | 4-битная (NF4/GPTQ/AWQ) | 170–190 ГБ | 8× RTX 4090 или 4× H100 80 ГБ |
| DeepSeek-R1/V3 671B | INT8 | 340–380 ГБ | 6–8× RTX 4090 или 4× A100/H100 80 ГБ |
| Модель | Объём VRAM (FP16) | Потребительская GPU, на которой можно запустить |
|---|---|---|
| R1-Distill-Qwen-32B | 64 ГБ | 2× RTX 4090 |
| R1-0528-Qwen3-8B / Llama-8B | 16 ГБ | 1× RTX 4090 / 3090 Ti |
| R1-Distill-Qwen-7B Math | 14 ГБ | 1× RTX 4080/4090 |
| R1-Distill-Llama-70B | 140 ГБ | 4× RTX 4090 или 2× A100 80 ГБ |
| Модель | Общий объём VRAM (FP16/BF16) | Минимальная конфигурация для потребительского оборудования |
|---|---|---|
| Qwen3-Coder 480B MoE | 560–600 ГБ (35B активных) | 8× H100 80 ГБ |
| Qwen3-VL-235B MoE | 280–320 ГБ (22B активных) | 4× H100 80 ГБ |
| Qwen2.5-72B / Qwen3-32B Dense | 140–160 ГБ | 4× RTX 4090 или 2× A100 80 ГБ |
| Qwen3-14B | 28–32 ГБ | 1× RTX 4090 |
| Qwen3-8B | 16–18 ГБ | 1× RTX 4080/4090 |
| Qwen3-4B | 8–10 ГБ | 1× RTX 4060 Ti / 4070 |
| Qwen3-1.7B и 0.6B | 4 ГБ | Мобильные телефоны, RTX 3050 |
| Qwen3-Embedding / Reranker 8B | 16 ГБ | 1× RTX 4090 |
Шаги установки:
- Скачайте веса моделей с HuggingFace или ModelScope
- Выберите фреймворк для вывода: поддерживаются vLLM и SGLang
- Следуйте руководству по развертыванию в официальном репозитории GitHub
4. Интеграция
Использование CLI, таких как Trae,Claude Code, Qwen Code
Если вы хотите использовать топовые модели Novita AI (такие как Qwen3-Coder, Kimi K2, DeepSeek R1) для AI-ассистента программирования в локальной среде или IDE, процесс прост: получите ваш API-ключ, установите инструмент, настройте переменные окружения и начните программировать.
Для подробных команд установки и примеров ознакомьтесь с официальными руководствами:
- Trae: Пошаговое руководство по доступу к AI-моделям в вашем IDE
- Claude Code: Как использовать Kimi-K2 в Claude Code на Windows, Mac и Linux
- Qwen Code: Как использовать OpenAI-совместимый API в Qwen Code (настройка за 60 секунд!)
Мультиагентные рабочие процессы с SDK OpenAI Agents
Создавайте продвинутые мультиагентные системы, интегрируя Novita AI с SDK OpenAI Agents:
- Plug-and-play (подключи и работай): Используйте LLM от Novita AI в любом рабочем процессе OpenAI Agents.
- Поддержка передачи задач, маршрутизации и использования инструментов: Проектируйте агентов, которые могут делегировать задачи, сортировать их или запускать функции, все на основе моделей Novita AI.
- Интеграция с Python: Просто установите endpoint SDK на
https://api.novita.ai/v3/openaiи используйте ваш API-ключ.
Подключение API на сторонних платформах
OpenAI-совместимый API: Наслаждайтесь простой миграцией и интеграцией с такими инструментами, как Cline и Cursor, разработанными по стандарту API OpenAI.
Hugging Face: Используйте модели в Spaces, конвейерах или с библиотекой Transformers через endpoints Novita AI.
Фреймворки для агентов и оркестрации: Легко подключайте Novita AI к партнёрским платформам, таким как Continue, AnythingLLM,LangChain, Dify и Langflow через официальные коннекторы и пошаговые руководства по интеграции.
DeepSeek ориентирован на максимальную мощность рассуждений с моделями, такими как DeepSeek-V3, DeepSeek-R1 и DeepSeek-V3.1, поддерживаемыми лёгкими дистиллированными версиями, такими как R1-Distill-Qwen-32B и R1-Distill-Qwen3-8B. Qwen стремится к универсальности и готовности к корпоративному использованию с моделями, такими как Qwen3-Coder-480B-A35B-Instruct, Qwen3-VL-235B-A22B, эффективными моделями от Qwen3-14B до Qwen3-0.6B, а также RAG-ориентированными моделями, такими как Qwen3-Embedding-8B и Qwen3-Reranker-8B. Короче говоря: DeepSeek оптимизирован для производительности в глубоких рассуждениях; Qwen оптимизирован для полноценного, готового к развертыванию, многоязычного, мультимодального набора инструментов для AI.
Часто задаваемые вопросы
В чём ключевое преимущество DeepSeek-V3 по сравнению с моделями Qwen? DeepSeek-V3 использует архитектуру MoE с MLA и MTP для максимизации качества рассуждений, тогда как модели Qwen в большей степени ориентированы на многоязычную поддержку, диапазон вариантов развертывания и универсальность применения.
Почему стоит выбрать DeepSeek-V3.1 вместо Qwen3-14B? DeepSeek-V3.1 предлагает гибридные режимы рассуждений «Think / Non-Think», оптимизированные для глубины цепочки рассуждений, тогда как Qwen3-14B в первую очередь ориентирован на универсальный вывод, многоязычные задачи и эффективное развертывание.
Какая экосистема моделей лучше подходит для рабочих процессов с длинными документами? Qwen выделяется моделями, такими как Qwen3-Coder-480B-A35B-Instruct и Qwen3-VL-235B-A22B, которые предлагают контекстное окно до 256K–1M токенов, тогда как DeepSeek ориентирован на рассуждения, а не на обработку документов с ультрадлинным контекстом.
Novita AI — это облачная AI-платформа, которая предоставляет разработчикам простой способ развертывать AI-модели с помощью нашего простого API, а также доступное и надёжное облако GPU для построения и масштабирования решений.



