

Wichtige Highlights
Qwen3-Coder-480B-A35B-Instruct: Spezialisiertes Codierungsmodell mit einer Kontextlänge von 262.000 Token, optimiert für algorithmische Exzellenz und Benchmark-Leistung bei Programmieraufgaben.
Kimi K2: Allgemeines Modell mit unternehmensorientierter Zuverlässigkeit, optimiert für die produktionsreife Codegenerierung und kosteneffiziente Entwicklungsabläufe.
Novita AI bietet nicht nur stabile API-Dienste, sondern auch extrem kostengünstige Preise. Beispielsweise kostet Qwen3-Coder-480B-A35B-Instruct 0,95 $ pro 1 Mio. Eingabe-Token und 5 $ pro 1 Mio. Ausgabe-Token, während Kimi K2 0,57 $ pro 1 Mio. Eingabe-Token und 2,3 $ pro 1 Mio. Ausgabe-Token kostet.
Grundlegende Einführung der Modelle
Qwen3-Coder-480B-A35B-Instruct
Qwen3-Coder-480B-A35B-Instruct ist ein hochmodernes, groß angelegtes kausales Sprachmodell, das von Alibaba im Juli 2025 veröffentlicht wurde und hauptsächlich für agentisches Codieren und Softwareentwicklungsaufgaben entwickelt wurde. Es verwendet eine Mixture-of-Experts (MoE)-Architektur mit insgesamt 480 Milliarden Parametern und 35 Milliarden aktiven Parametern pro Vorwärtsdurchlauf, wodurch eine Balance zwischen Modellkapazität und Inferenzeffizienz erreicht wird. Dieses Modell unterstützt nativ extrem lange Kontexte von 256K Token und erzielt unter den offenen Modellen eine Spitzenleistung.
Hauptmerkmale und Architektur
- Typ: Kausale Sprachmodelle
- Trainingsphase: Pre-Training und Post-Training
- Anzahl der Parameter: 480B insgesamt und 35B aktiviert
- Anzahl der Schichten: 62
- Anzahl der Aufmerksamkeitsköpfe (GQA): 96 für Q und 8 für KV
- Anzahl der Experten: 160
- Anzahl der aktivierten Experten: 8
- Kontextlänge: 262.144 nativ.
Kimi K2
Kimi K2 ist ein bahnbrechendes groß angelegtes Sprachmodell, das von Moonshot AI entwickelt und im Juli 2025 veröffentlicht wurde. Es zeichnet sich durch eine innovative Mixture-of-Experts (MoE)-Architektur mit insgesamt 1 Billion Parametern und 32 Milliarden aktiven Parametern pro Vorwärtsdurchlauf aus, was eine effiziente Skalierung und hohe Leistung ermöglicht. Kimi K2 ist sorgfältig für agentische Intelligenz optimiert, d. h. es kann autonom planen, argumentieren, Werkzeuge verwenden und Code mit mehrstufigen Problemlösungsfähigkeiten synthetisieren.
Hauptmerkmale und Architektur
- Architektur: MoE mit 384 Experten, wobei während der Inferenz 8 pro Token ausgewählt werden, um Effizienz und Leistungsfähigkeit auszugleichen.
- Parameter: 1 Billion insgesamt, 32 Milliarden gleichzeitig aktiv.
- Kontextfenster: 128K Token.
- Training: Trainiert auf 15,5 Billionen Token mit Moonshots proprietärem MuonClip-Optimierer, um die Trainingsstabilität zu gewährleisten.
- Sprachen: Hauptsächlich für Chinesisch und Englisch optimiert.
- Speicherplatz: Das vollständige Modell benötigt ca. 1,09 TB.
Benchmark-Vergleich
1. Benchmarks für angewandte Intelligenz

2. Kontextfenster:
Qwen3-Coder-480B-A35B-Instruct: 262k Token
Kimi K2: 128k Token
3. API-Preise:
Qwen3-Coder-480B-A35B-Instruct: 0,95 $ / 5 $ pro 1 Mio. Token (Eingabe/Ausgabe)
Kimi K2: 0,57 $ / 2,30 $ pro 1 Mio. Token (Eingabe/Ausgabe)
Test der angewandten Fähigkeiten
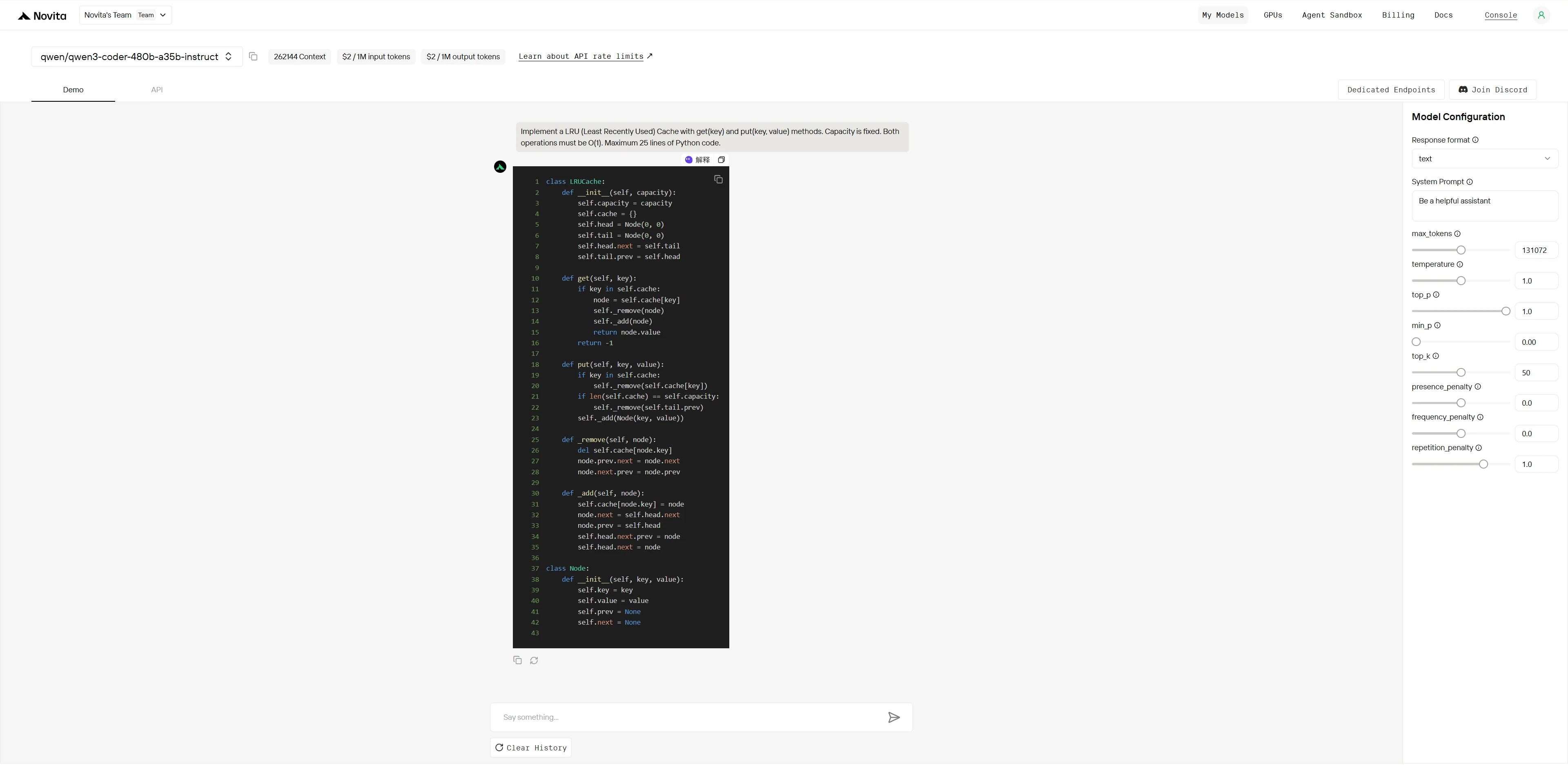
1. Codefähigkeit: Herausforderung beim Design von Datenstrukturen
Zielsetzung: Bewertung der Implementierungsfähigkeiten und des algorithmischen Denkens.
Beispiel-Prompt:
„Implementiere einen LRU (Least Recently Used) Cache mit den Methoden get(key) und put(key, value). Die Kapazität ist fest. Beide Operationen müssen O(1) sein. Maximum 25 Zeilen Python-Code."
Bewertungskriterien:
-
Korrektheit des Algorithmus (40%):
- Werden die am wenigsten kürzlich verwendeten Elemente korrekt entfernt?
- Sind sowohl get als auch put wirklich O(1)?
- Werden Kapazitätsgrenzen korrekt behandelt?
-
Wahl der Datenstruktur (30%):
- Wird eine geeignete Kombination verwendet (dict + doppelt verknüpfte Liste oder OrderedDict)?
- Zeigt das Verständnis der Zeitkomplexitätsanforderungen?
-
Codequalität (20%):
- Saubere, lesbare Implementierung?
- Korrekte Behandlung von Randfällen (leerer Cache, Kapazität 0)?
- Bleibt innerhalb der Zeilenbegrenzung, während es funktional bleibt?
-
Vollständigkeit der Implementierung (10%):
- Funktionieren beide Methoden wie angegeben?
- Enthält notwendige Hilfsmethoden/-strukturen?
Qwen3-Coder-480B-A35B-Instruct:
Kimi K2:
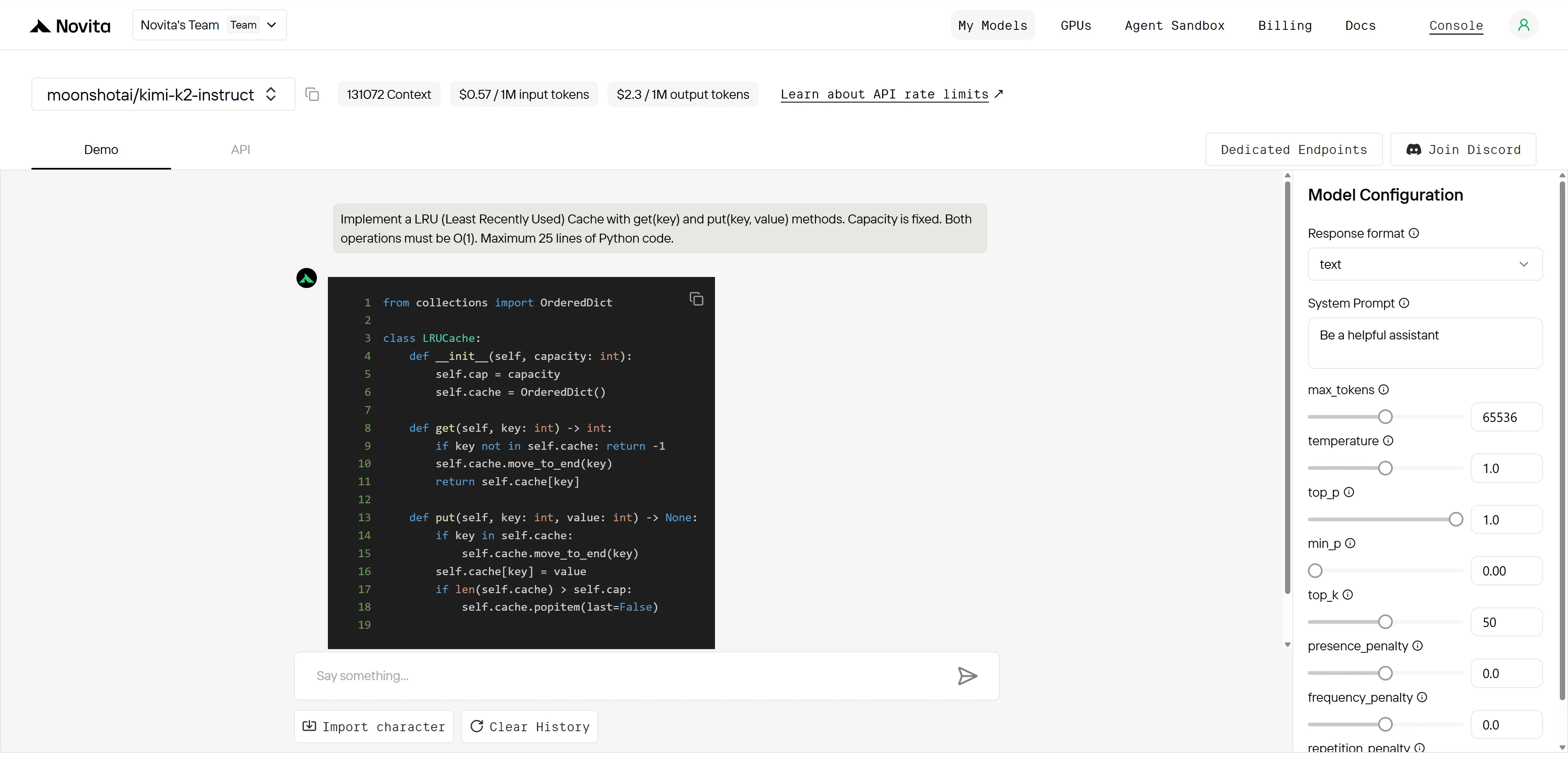
Gesamtsieger: Kimi K2 (4,9/5) > Qwen (4,2/5)
| Dimension | Qwen | Kimi K2 | Lücke |
|---|---|---|---|
| Algorithmuskenntnisse | 5/5 | 5/5 | Keine |
| Implementierungsgenauigkeit | 3/5 | 5/5 | Groß |
| Codestruktur | 4/5 | 5/5 | Klein |
| Produktionsreife | 2/5 | 5/5 | Sehr groß |
Teste Qwen 3 Coder und Kimi K2!
Beide Modelle verstehen den Algorithmus perfekt, aber Kimi K2 führt fehlerfrei aus, während Qwen einen kritischen Fehler hat, der die Kernfunktionalität beeinträchtigt. Dies zeigt die überlegene Implementierungspräzision und Qualitätssicherung von Kimi K2.
2. Debug-Fähigkeit: Mehrschichtige Fehleranalyse
Zielsetzung: Test der systematischen Debugging- und Fehlerverständnisfähigkeiten.
Beispiel-Prompt:
class BankAccount:
def __init__(self, initial_balance):
self.balance = initial_balance
self.transaction_history = []
def transfer_to(self, other_account, amount):
if self.balance >= amount:
self.balance -= amount
other_account.balance += amount
self.transaction_history.append(f"Transfer out: ${amount}")
other_account.transaction_history.append(f"Transfer in: ${amount}")
return True
return False
def get_total_transfers(self):
total = 0
for transaction in self.transaction_history:
if "Transfer" in transaction:
amount_str = transaction.split("$")[1]
total += int(amount_str)
return total
# Test case that reveals multiple issues:
acc1 = BankAccount(100.50)
acc2 = BankAccount(50.75)
acc1.transfer_to(acc2, 25.25)
print(f"Total transfers: ${acc1.get_total_transfers()}") # Crashes with ValueError
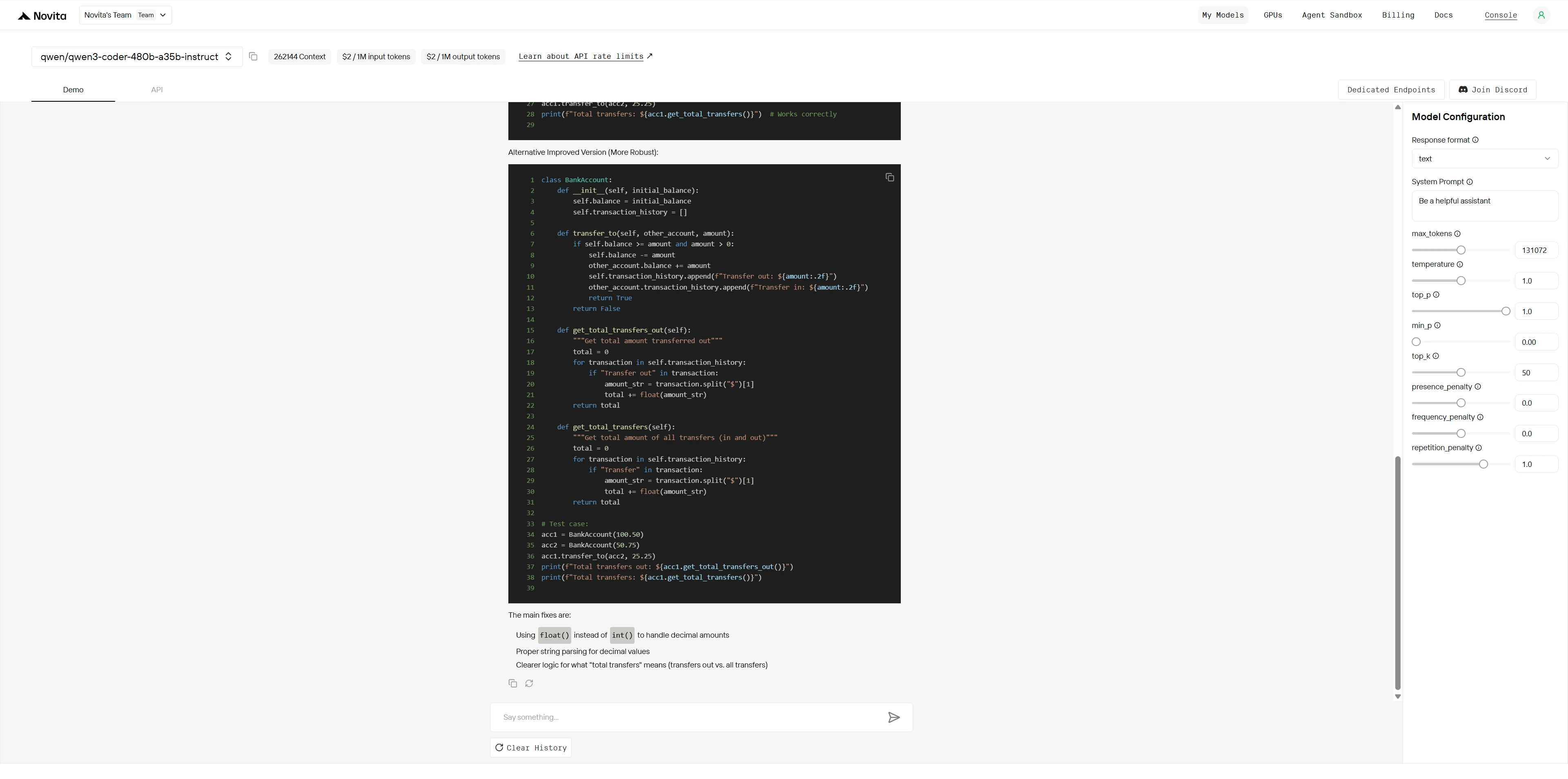
Dieser Code enthält mehrere Fehler, die ihn zum Absturz bringen. Identifizieren Sie ALLE Probleme, erklären Sie, warum jedes auftritt, und geben Sie die korrigierte Version an.
Bewertungskriterien:
-
Problemidentifikation (35%):
- Wird der Float/Int-Konvertierungsfehler gefunden?
- Werden inkonsistente Datentypen (Float-Guthaben vs. Int-Parsing) identifiziert?
- Wird die potenzielle Anfälligkeit des String-Parsings erkannt?
- Wird das Fehlen von Validierung/Fehlerbehandlung erkannt?
-
Ursachenanalyse (25%):
- Wird erklärt, warum
int(amount_str)bei „25.25" fehlschlägt? - Wird das Problem des Typkonflikts verstanden?
- Wird der Fehler in der Annahme des String-Parsings identifiziert?
- Wird erklärt, warum
-
Vollständigkeit der Lösung (25%):
- Werden alle identifizierten Probleme behoben?
- Wird die ursprüngliche Funktionalität beibehalten, während sie robust gemacht wird?
- Werden Randfälle (fehlerhafte Strings usw.) behandelt?
-
Codequalität und Best Practices (15%):
- Werden durchgängig geeignete Datentypen verwendet?
- Wird eine ordnungsgemäße Validierung/Fehlerbehandlung hinzugefügt?
- Wird eine saubere, lesbare Codestruktur beibehalten?
Qwen3-Coder-480B-A35B-Instruct:
Kimi K2:
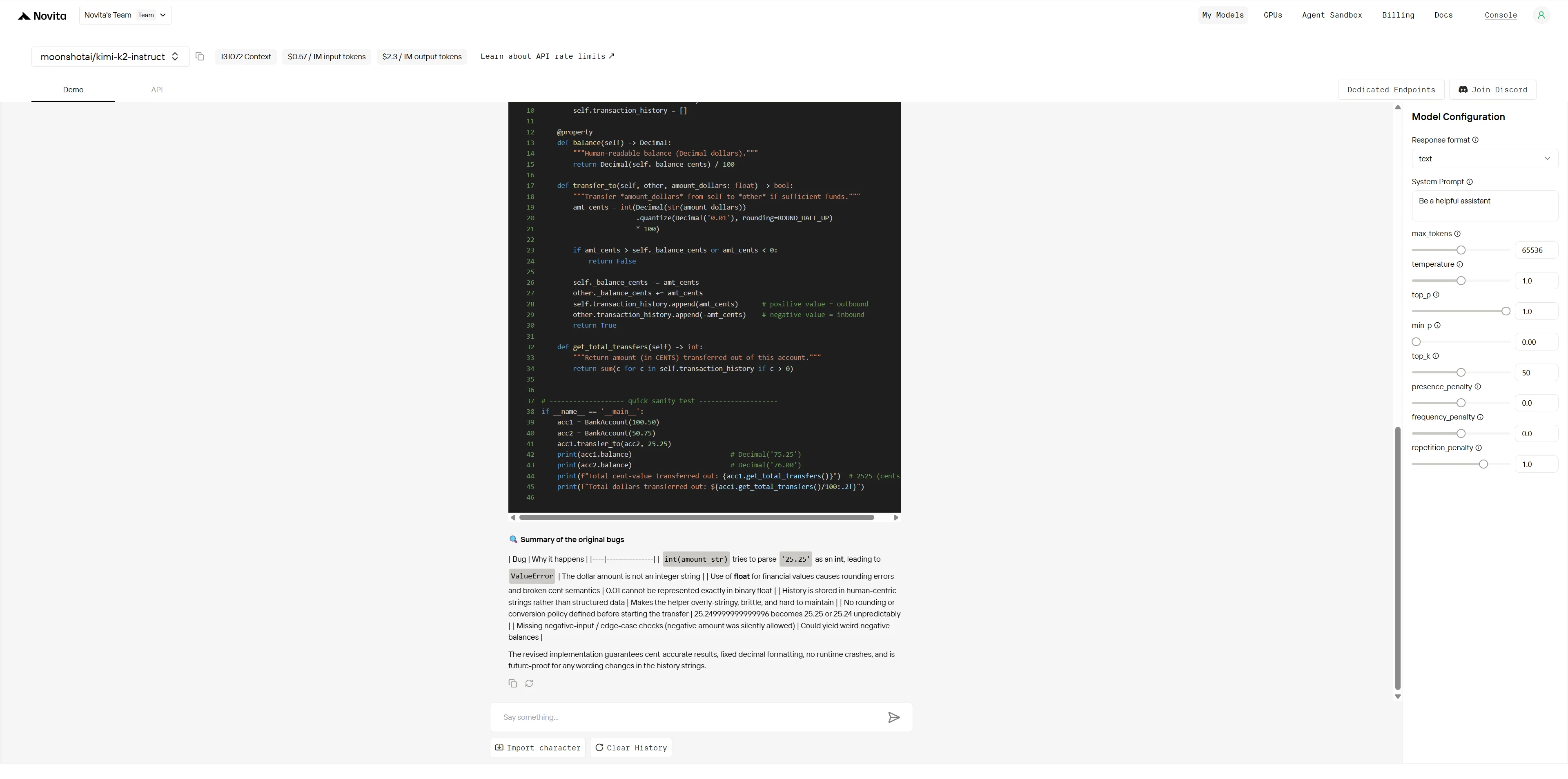
Gesamtsieger: Kimi K2 (4,9/5) > Qwen (3,8/5)
| Dimension | Qwen | Kimi K2 | Lücke |
|---|---|---|---|
| Fehleridentifikation | 4/5 | 5/5 | Klein |
| Ursachenanalyse | 4/5 | 5/5 | Klein |
| Lösungsqualität | 4/5 | 5/5 | Klein |
| Fachkenntnisse | 3/5 | 5/5 | Groß |
| Produktionsreife | 3/5 | 5/5 | Groß |
| Architekturdenken | 3/5 | 5/5 | Groß |
Teste Kimi K2 und Qwen 3 Coder selbst!
Während beide Modelle offensichtliche Fehler erkennen können, zeigt Kimi K2 Debugging auf Expertenniveau mit tiefem Fachwissen, systematischer Problemlösung und produktionsreifen Lösungen. Qwen liefert zwar kompetente, aber oberflächliche Korrekturen, während Kimi K2 architektonische Verbesserungen auf professionellem Niveau bietet, die zukünftige Probleme verhindern.
Stärken & Schwächen
Qwen3-Coder-480B-A35B-Instruct
Stärken:
- Massives Kontextfenster: 262K Token (2x Kimis Kapazität)
Schwächen:
- Inkonsistenz bei der Implementierung: Produziert manchmal Code mit kritischen Logikfehlern
- Oberflächliches Debugging: Konzentriert sich auf offensichtliche Probleme, übersieht architektonische Probleme
- Begrenztes Fachwissen: Generischer Programmieransatz ohne spezialisiertes Wissen
Kimi K2
Stärken:
- Konsistente Codequalität: Zuverlässige, produktionsreife Implementierungen, liefert durchgängig funktionalen Code mit wenig Aufsicht
- Umfassende Problemlösung: Identifiziert Randfälle und architektonische Probleme
- Überlegene Kosteneffizienz: 0,57–2,30 $ pro 1 Mio. Token (bis zu 2x günstiger)
- Professionelles Engineering: Korrekte Fehlerbehandlung und defensive Programmierung
Schwächen:
- Kleineres Kontextfenster: 128K Token (die Hälfte von Qwens Kapazität)
So greifen Sie auf Qwen3-Coder-480B-A35B-Instruct und Kimi K2 auf Novita AI zu
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Model Library.
Jetzt Kimi K2 und Qwen 3 Coder testen!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
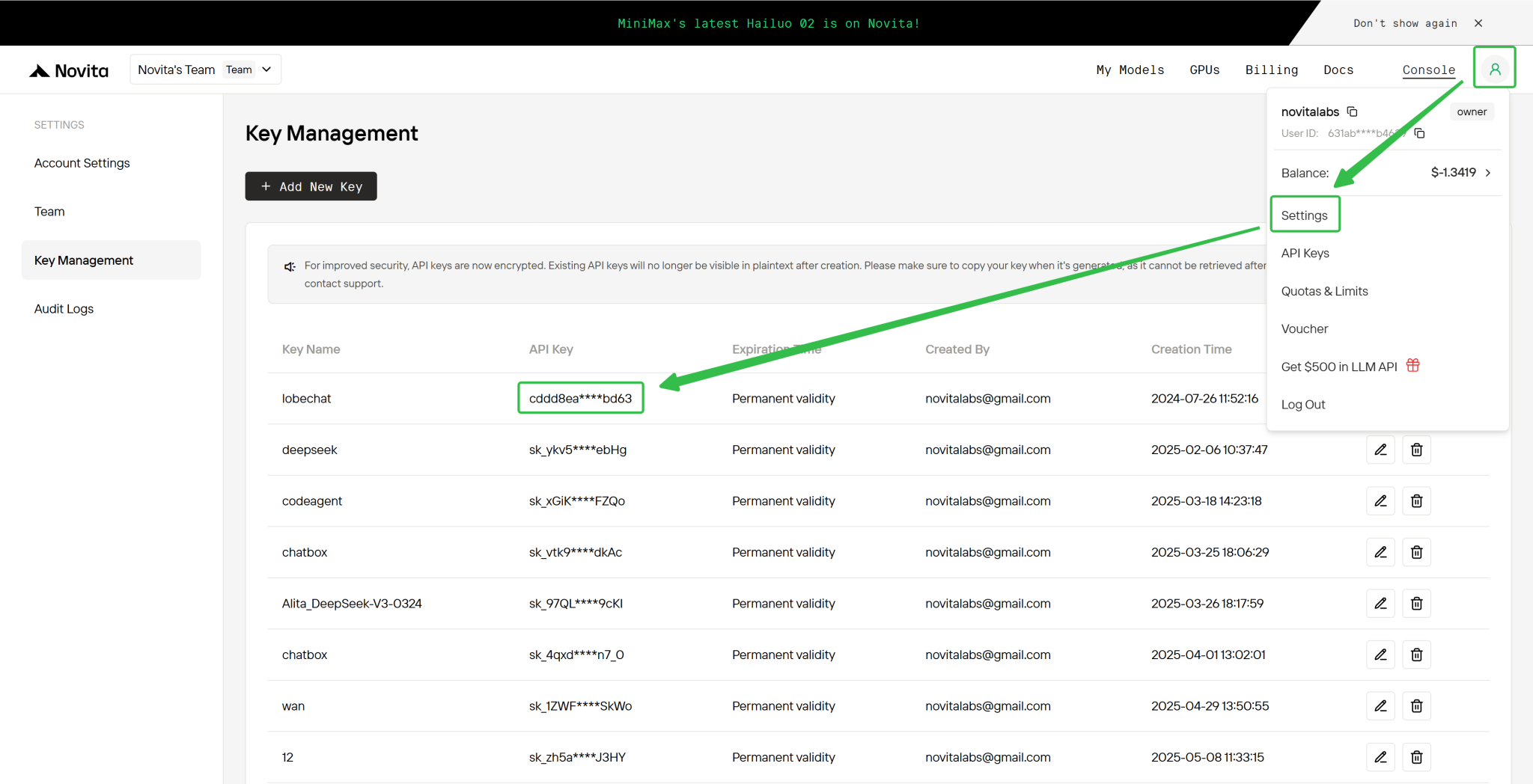
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Rufen Sie die Seite „Settings“ auf und kopieren Sie den API-Schlüssel wie im Bild dargestellt.
Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
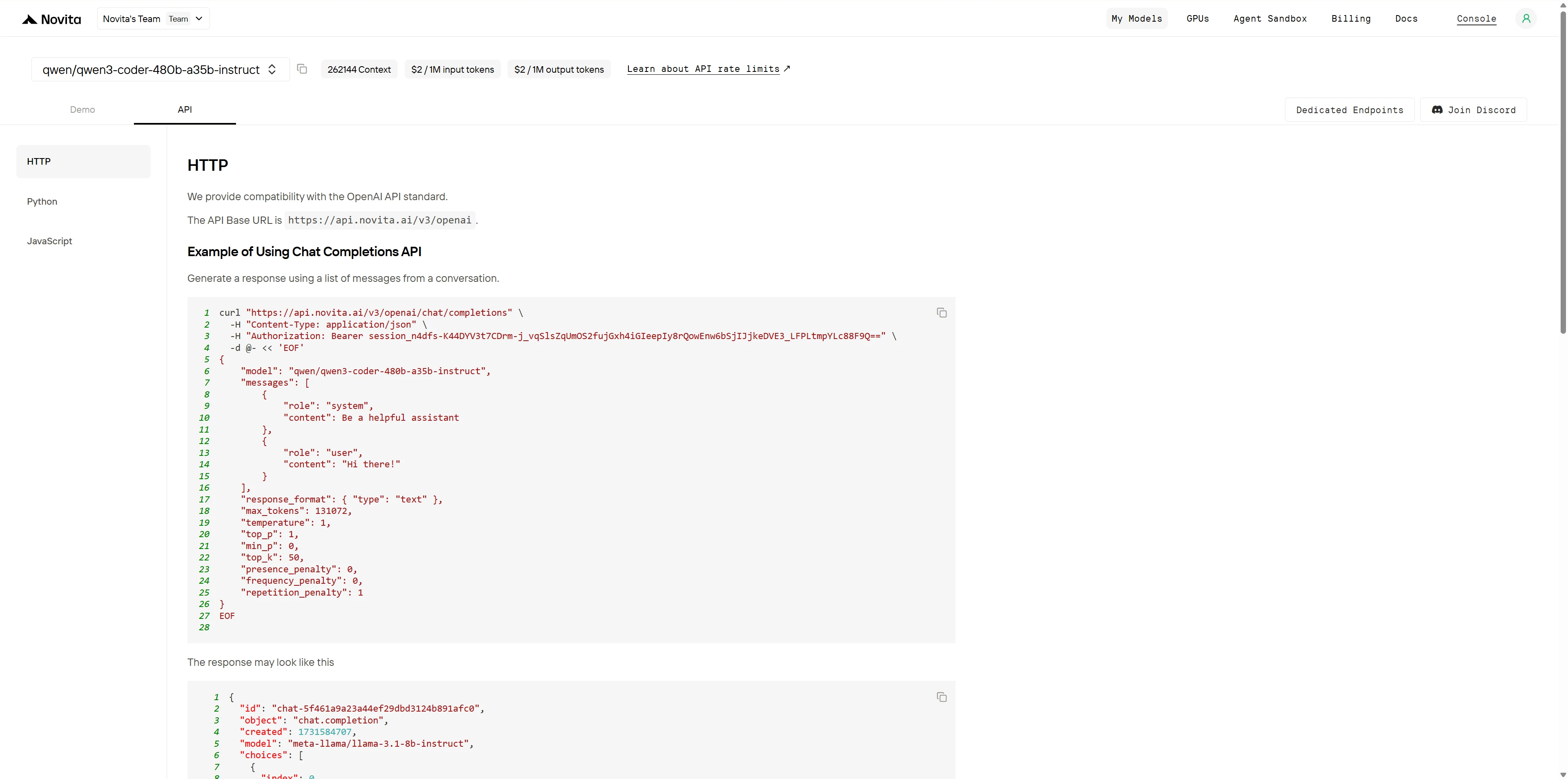
Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_n4dfs-K44DYV3t7CDrm-j_vqSlsZqUmOS2fujGxh4iGIeepIy8rQowEnw6bSjIJjkeDVE3_LFPLtmpYLc88F9Q==",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 131072
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Sowohl Qwen3-Coder als auch Kimi K2 zeichnen sich in verschiedenen Dimensionen der KI-gestützten Entwicklung aus. Qwen3-Coder-480B glänzt bei Benchmark-Leistungen, während Kimi K2 eine überragende Befolgung von Anweisungen und praktische Codegenerierung zeigt, die durchgängig funktionalen Code mit minimaler Aufsicht produziert. Während die technische Leistungsfähigkeit von Qwen3-Coder-480B in isolierten Codierungsaufgaben glänzt, machen Kimi K2s Zuverlässigkeit und Workflow-Integration es besser geeignet für kollaborative Entwicklungsumgebungen und unternehmensorientierte Anwendungen.
Sowohl Qwen3-Coder als auch Kimi K2 können nahtlos in Ihren Entwicklungs-Workflow integriert werden, und zwar über die OpenAI-kompatible API von Qwen Code, die leistungsstarke KI-Codeunterstützung direkt in Ihre Terminalumgebung bringt. Klicken Sie hier, um mehr zu erfahren.
Sie können Kimi K2 auch in Claude Code verwenden, um die agentischen Codierungsfähigkeiten bei erheblichen Kosteneinsparungen zu verbessern. Erfahren Sie, wie Sie Kimi K2 mit Claude Code einrichten.
Häufig gestellte Fragen
Ist Qwen3 gut zum Codieren?
Ja, Qwen3-Coder zeichnet sich beim Codieren aus mit Spitzen-Benchmark-Leistung, einem massiven 262K-Kontextfenster für die Handhabung großer Codebasen und starken algorithmischen Problemlösungsfähigkeiten.
Was ist Kimi K2?
Kimi K2 ist ein allgemeines KI-Modell, das von Moonshot AI entwickelt wurde, und bietet zuverlässige Codegenerierung, starkes Fachwissen und kostengünstige Preise von 0,57–2,30 $ pro 1 Mio. Token.
Ist Kimi besser als ChatGPT?
Kimi K2 bietet ein besseres Preis-Leistungs-Verhältnis mit niedrigeren Preisen und zuverlässiger Codequalität, während ChatGPT ein breiteres allgemeines Wissen und ausgefeiltere Konversationsfähigkeiten bietet – die Wahl hängt von Ihrem spezifischen Anwendungsfall und Budget ab.
Über Novita AI
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für die Skalierung bereitstellt.



