

أبرز النقاط
Qwen3-Coder-480B-A35B-Instruct: نموذج ترميز متخصص بطول سياق يبلغ 262 ألف رمز، محسَّن للتميز الخوارزمي وأداء المعايير في مهام البرمجة.
Kimi K2: نموذج عام بموثوقية على مستوى المؤسسات، محسَّن لتوليد كود جاهز للإنتاج وسير عمل تطويري فعال من حيث التكلفة.
لا توفر Novita AI خدمات API مستقرة فحسب، بل تقدم أيضًا أسعارًا فعالة للغاية من حيث التكلفة. على سبيل المثال، تبلغ تكلفة Qwen3-Coder-480B-A35B-Instruct 0.95 دولارًا لكل مليون رمز إدخال و5 دولارات لكل مليون رمز إخراج، بينما تبلغ تكلفة Kimi K2 0.57 دولارًا لكل مليون رمز إدخال و2.3 دولار لكل مليون رمز إخراج.
مقدمة أساسية عن النموذج
Qwen3-Coder-480B-A35B-Instruct
Qwen3-Coder-480B-A35B-Instruct هو نموذج لغة سببي واسع النطاق من أحدث الإصدارات أطلقته شركة Alibaba في يوليو 2025، وهو مصمم بشكل أساسي لمهام الترميز الوكيل وتطوير البرمجيات. يستخدم بنية خليط من الخبراء (MoE) بإجمالي 480 مليار معامل و35 مليار معامل نشط لكل تمريرة أمامية، مما يحقق توازنًا بين سعة النموذج وكفاءة الاستدلال. يدعم هذا النموذج سياقات طويلة جدًا بشكل أصلي تصل إلى 256 ألف رمز، ويحقق أداءً متطورًا بين النماذج المفتوحة.
الميزات الرئيسية والبنية
- النوع: نماذج لغة سببية
- مرحلة التدريب: ما قبل التدريب وما بعد التدريب
- عدد المعاملات: 480 مليار إجمالي و35 مليار نشط
- عدد الطبقات: 62
- عدد رؤوس الانتباه (GQA): 96 لـ Q و8 لـ KV
- عدد الخبراء: 160
- عدد الخبراء النشطين: 8
- طول السياق: 262,144 رمزًا بشكل أصلي.
Kimi K2
Kimi K2 هو نموذج لغة واسع النطاق مبتكر طورته Moonshot AI، وأُطلق في يوليو 2025. يتميز ببنية خليط من الخبراء (MoE) مبتكرة بإجمالي 1 تريليون معامل و32 مليار معامل نشط لكل تمريرة أمامية، مما يتيح توسعًا فعالًا وأداءً عاليًا. تم تحسين Kimi K2 بدقة للذكاء الوكيل، مما يعني أنه يمكنه التخطيط والاستدلال واستخدام الأدوات وتجميع الكود بشكل مستقل مع قدرات حل المشكلات متعددة الخطوات.
الميزات الرئيسية والبنية
- البنية: MoE مع 384 خبيرًا، يتم اختيار 8 لكل رمز أثناء الاستدلال لتحقيق التوازن بين الكفاءة والقدرة.
- المعاملات: 1 تريليون إجمالي، 32 مليار نشط في المرة الواحدة.
- نافذة السياق: 128 ألف رمز.
- التدريب: تم التدريب على 15.5 تريليون رمز باستخدام محسن MuonClip الخاص بـ Moonshot للحفاظ على استقرار التدريب.
- اللغات: محسَّنة بشكل أساسي للصينية والإنجليزية.
- مساحة القرص: يتطلب النموذج الكامل حوالي 1.09 تيرابايت.
مقارنة المعايير
1. معايير الذكاء التطبيقي

2. نافذة السياق:
Qwen3-Coder-480B-A35B-Instruct: 262 ألف رمز
Kimi K2: 128 ألف رمز
3. تسعير API:
Qwen3-Coder-480B-A35B-Instruct: 0.95 دولار / 5 دولار إدخال/إخراج لكل مليون رمز
Kimi K2: 0.57 دولار / 2.30 دولار إدخال/إخراج لكل مليون رمز
اختبار المهارات التطبيقية
1. القدرة على البرمجة: تحدي تصميم بنية البيانات
الهدف: تقييم مهارات التنفيذ والتفكير الخوارزمي.
المثال التوضيحي:
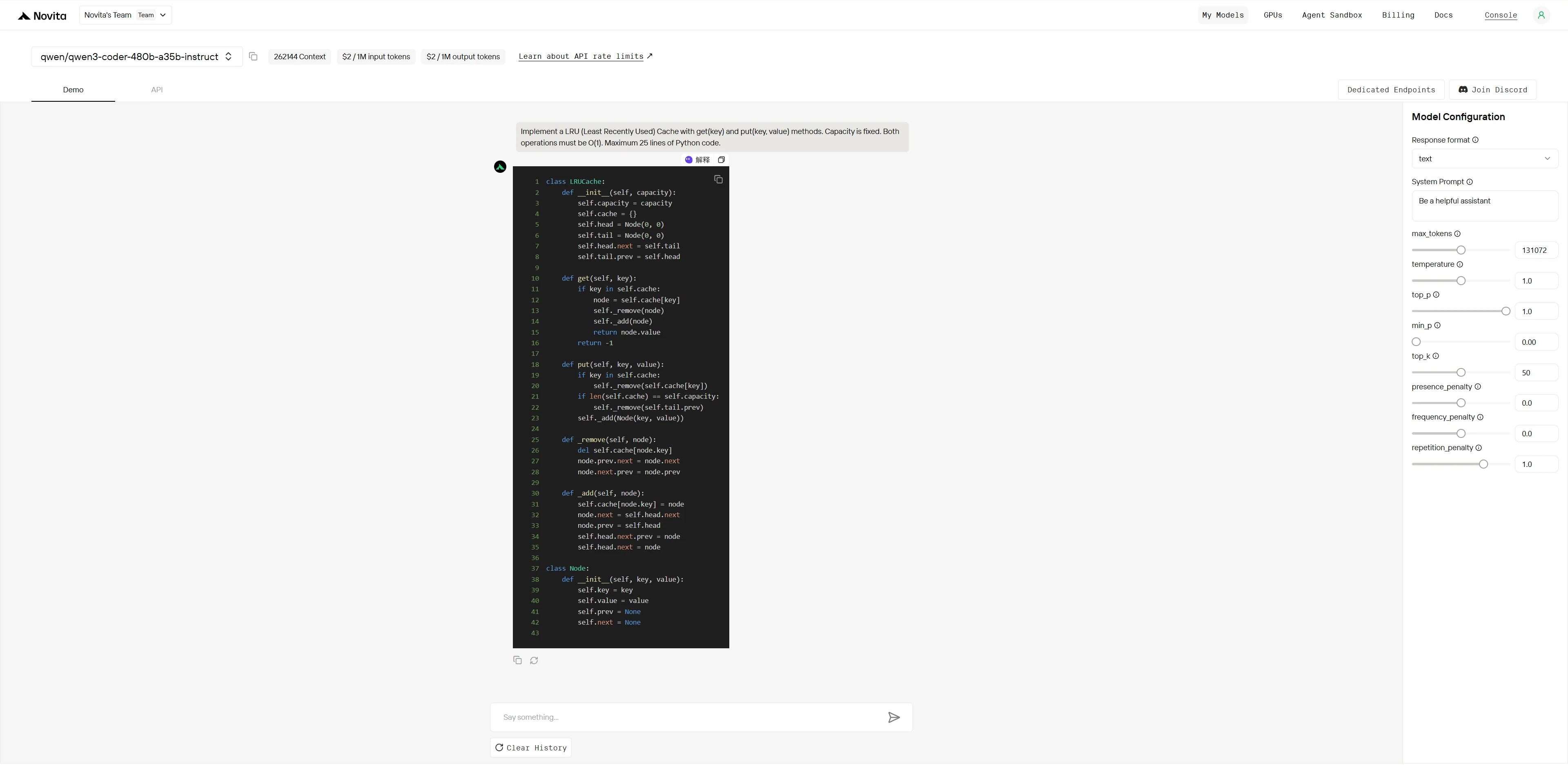
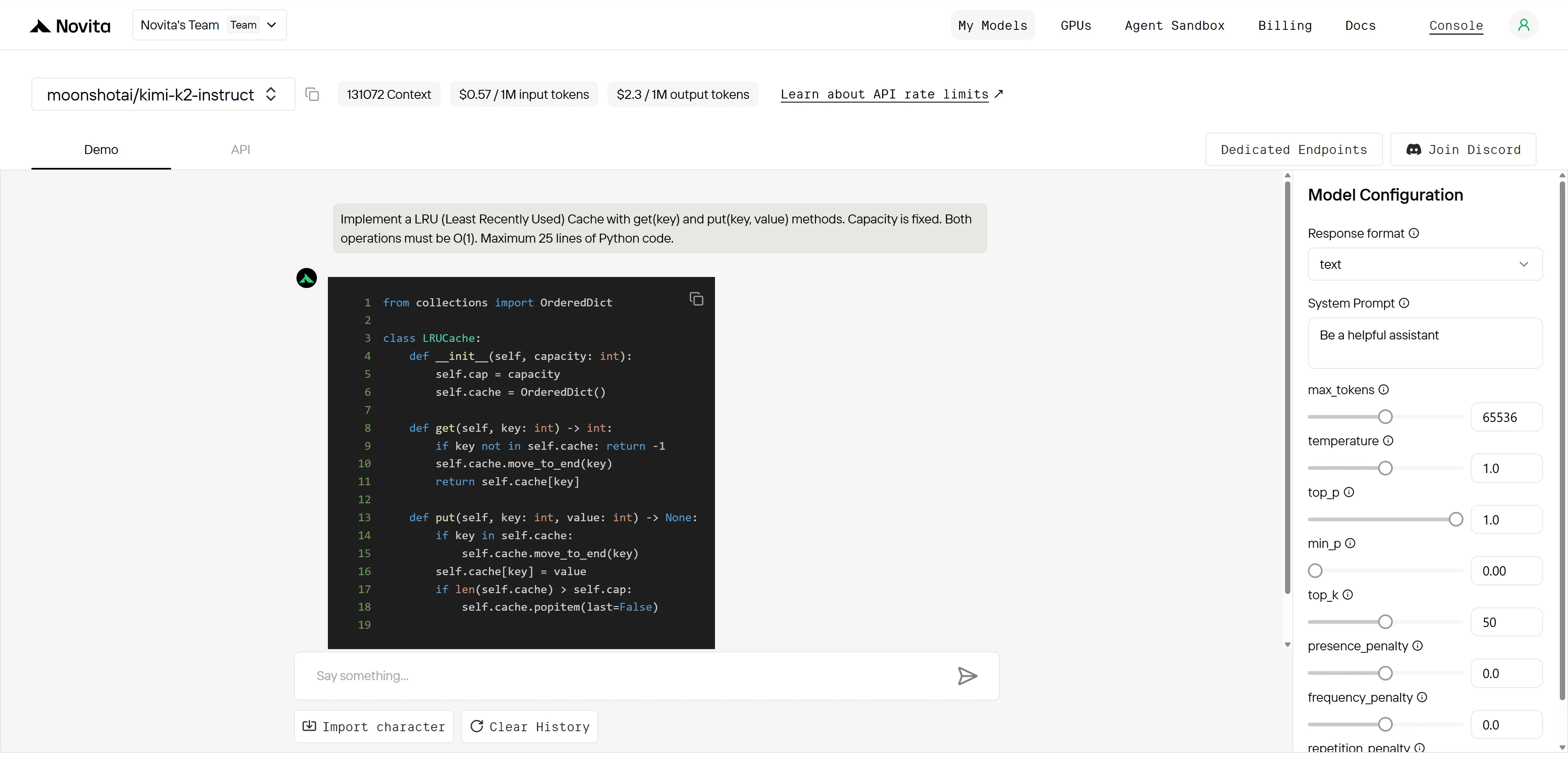
“نفذ ذاكرة تخزين مؤقت LRU (الأقل استخدامًا مؤخرًا) مع طريقتي get(key) وput(key, value). السعة ثابتة. يجب أن تكون كلتا العمليتين O(1). بحد أقصى 25 سطرًا من كود Python.”
معايير التقييم:
-
صحة الخوارزمية (40%):
- هل يقوم بإزالة العناصر الأقل استخدامًا بشكل صحيح؟
- هل كلتا عمليتي get/put هما بالفعل O(1)؟
- يتعامل مع حدود السعة بشكل صحيح؟
-
اختيار بنية البيانات (30%):
- يستخدم مجموعة مناسبة (dict + قائمة مرتبطة مزدوجة أو OrderedDict)؟
- يُظهر فهمًا لمتطلبات التعقيد الزمني؟
-
جودة الكود (20%):
- تنفيذ نظيف وقابل للقراءة؟
- معالجة مناسبة للحالات الحدودية (ذاكرة تخزين مؤقت فارغة، سعة 0)؟
- يظل ضمن حد الأسطر مع كونه وظيفيًا؟
-
اكتمال التنفيذ (10%):
- تعمل كلتا الطريقتين كما هو محدد؟
- تتضمن الطرق/الهياكل المساعدة اللازمة؟
Qwen3-Coder-480B-A35B-Instruct:
Kimi K2:
الفائز الإجمالي: Kimi K2 (4.9/5) > Qwen (4.2/5)
| البُعد | Qwen | Kimi K2 | الفجوة |
|---|---|---|---|
| المعرفة الخوارزمية | 5/5 | 5/5 | لا توجد |
| دقة التنفيذ | 3/5 | 5/5 | كبيرة |
| هيكل الكود | 4/5 | 5/5 | صغيرة |
| جاهزية الإنتاج | 2/5 | 5/5 | ضخمة |
كلا النموذجين يفهمان الخوارزمية بشكل مثالي، لكن Kimi K2 ينفذ بدون عيوب بينما يحتوي Qwen على خطأ حاسم يعطل الوظائف الأساسية. وهذا يُظهر دقة تنفيذ Kimi K2 الفائقة وضمان الجودة.
2. قدرة تصحيح الأخطاء: تحليل الأخطاء متعدد الطبقات
الهدف: اختبار المهارات المنهجية في تصحيح الأخطاء وفهم الأخطاء.
المثال التوضيحي:
class BankAccount:
def __init__(self, initial_balance):
self.balance = initial_balance
self.transaction_history = []
def transfer_to(self, other_account, amount):
if self.balance >= amount:
self.balance -= amount
other_account.balance += amount
self.transaction_history.append(f"Transfer out: ${amount}")
other_account.transaction_history.append(f"Transfer in: ${amount}")
return True
return False
def get_total_transfers(self):
total = 0
for transaction in self.transaction_history:
if "Transfer" in transaction:
amount_str = transaction.split("$")[1]
total += int(amount_str)
return total
# Test case that reveals multiple issues:
acc1 = BankAccount(100.50)
acc2 = BankAccount(50.75)
acc1.transfer_to(acc2, 25.25)
print(f"Total transfers: ${acc1.get_total_transfers()}") # Crashes with ValueError
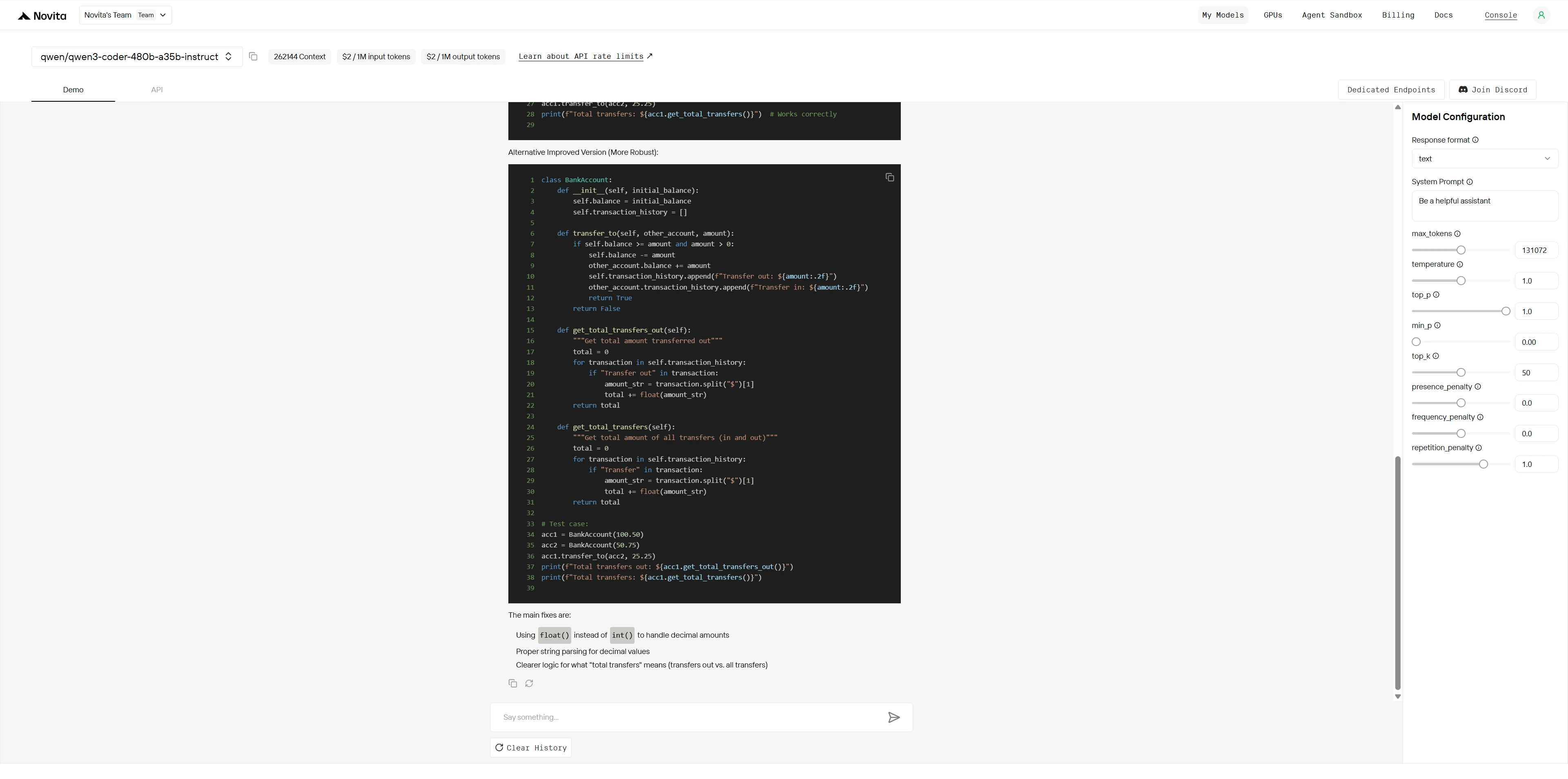
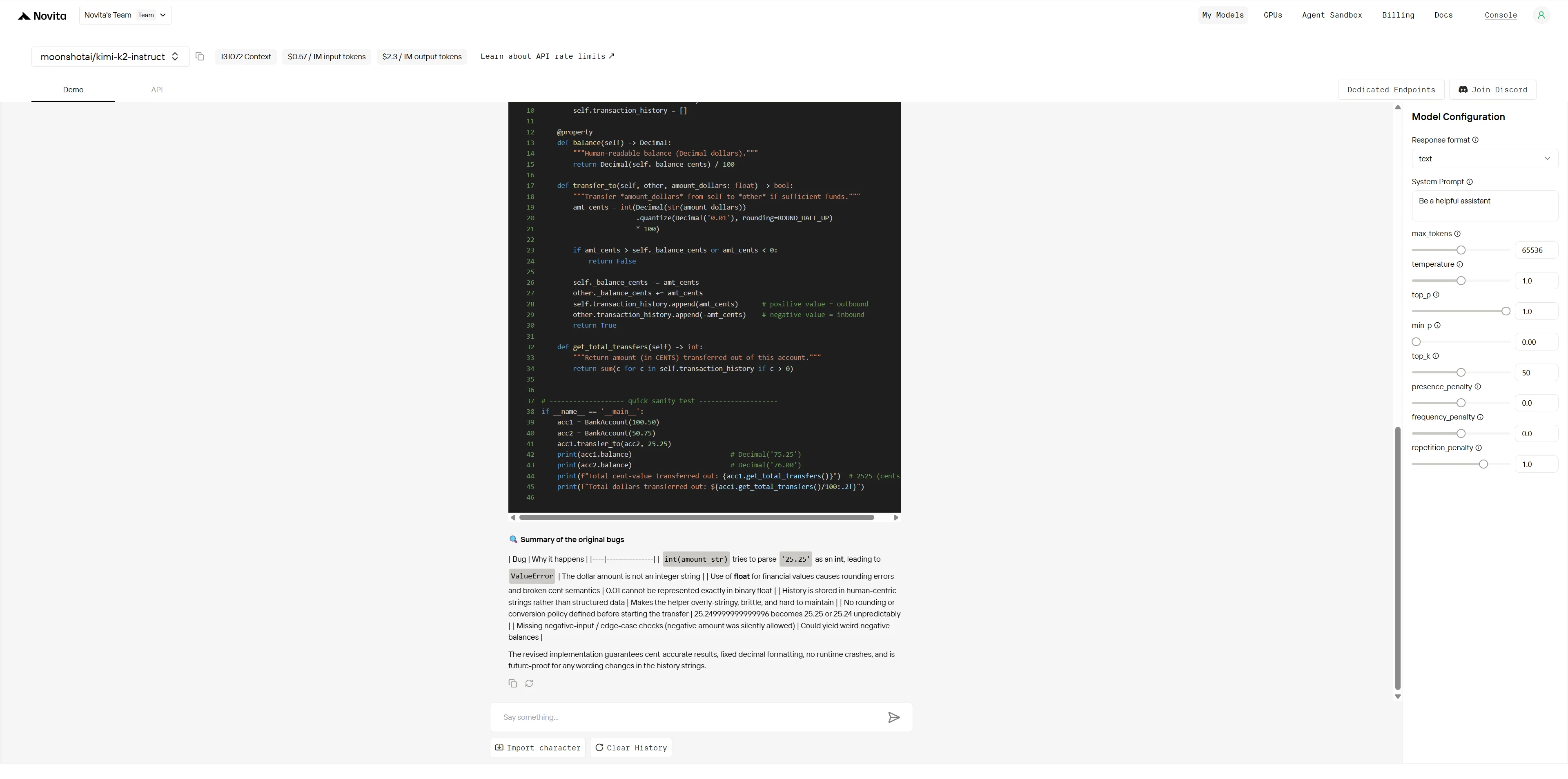
يحتوي هذا الكود على أخطاء متعددة تؤدي إلى فشله. حدد جميع المشكلات، واشرح سبب حدوث كل منها، وقدم النسخة المصححة.
معايير التقييم:
-
تحديد المشكلة (35%):
- هل يجد خطأ تحويل float/int؟
- هل يحدد أنواع البيانات غير المتسقة (أرصدة float مقابل تحليل int)؟
- هل يكتشف هشاشة تحليل السلسلة المحتملة؟
- هل يدرك عدم وجود التحقق/معالجة الأخطاء؟
-
تحليل السبب الجذري (25%):
- هل يشرح سبب فشل
int(amount_str)في “25.25”؟ - هل يفهم مشكلة عدم تطابق النوع؟
- هل يحدد عيب افتراض تحليل السلسلة؟
- هل يشرح سبب فشل
-
اكتمال الحل (25%):
- هل يصلح جميع المشكلات المحددة؟
- هل يحافظ على الوظائف الأصلية مع جعلها قوية؟
- هل يتعامل مع الحالات الحدودية (سلاسل مشوهة، إلخ)؟
-
جودة الكود وأفضل الممارسات (15%):
- هل يستخدم أنواع البيانات المناسبة بشكل متسق؟
- هل يضيف التحقق/معالجة الأخطاء المناسبة؟
- هل يحافظ على هيكل كود نظيف وقابل للقراءة؟
Qwen3-Coder-480B-A35B-Instruct:
Kimi K2:
الفائز الإجمالي: Kimi K2 (4.9/5) > Qwen (3.8/5)
| البُعد | Qwen | Kimi K2 | الفجوة |
|---|---|---|---|
| تحديد الأخطاء | 4/5 | 5/5 | صغيرة |
| تحليل السبب الجذري | 4/5 | 5/5 | صغيرة |
| جودة الحل | 4/5 | 5/5 | صغيرة |
| الخبرة في المجال | 3/5 | 5/5 | كبيرة |
| جاهزية الإنتاج | 3/5 | 5/5 | كبيرة |
| التفكير المعماري | 3/5 | 5/5 | كبيرة |
جرب Kimi K2 وQwen 3 Coder بنفسك!
بينما يمكن لكلا النموذجين تحديد الأخطاء الواضحة، فإن Kimi K2 يظهر خبرة على مستوى الخبراء في تصحيح الأخطاء مع معرفة عميقة بالمجال، وحل منهجي للمشكلات، وحلول على مستوى الإنتاج. يقدم Qwen إصلاحات كفؤة ولكن سطحية، بينما يقدم Kimi K2 تحسينات معمارية بجودة احترافية تمنع المشكلات المستقبلية.
نقاط القوة والضعف
Qwen3-Coder-480B-A35B-Instruct
نقاط القوة:
- نافذة سياق ضخمة: 262 ألف رمز (ضعف سعة Kimi)
نقاط الضعف:
- عدم اتساق التنفيذ: ينتج أحيانًا كودًا به عيوب منطقية حاسمة
- تصحيح أخطاء سطحي: يركز على المشكلات الواضحة، ويفتقد المشكلات المعمارية
- خبرة محدودة في المجال: نهج برمجة عام بدون معرفة متخصصة
Kimi K2
نقاط القوة:
- جودة كود متسقة: تنفيذات موثوقة وجاهزة للإنتاج، تنتج باستمرار كودًا وظيفيًا مع إشراف ضئيل
- حل شامل للمشكلات: يحدد الحالات الحدودية والمشكلات المعمارية
- كفاءة تكلفة فائقة: 0.57-2.30 دولار لكل مليون رمز (أرخص حتى مرتين)
- هندسة احترافية: معالجة مناسبة للأخطاء وبرمجة دفاعية
نقاط الضعف:
- نافذة سياق أصغر: 128 ألف رمز (نصف سعة Qwen)
كيفية الوصول إلى Qwen3-Coder-480B-A35B-Instruct وKimi K2 على Novita AI
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
قم بتسجيل الدخول إلى حسابك وانقر على زر مكتبة النماذج.
جرب Kimi K2 وQwen 3 Coder الآن!
الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ النسخة التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف قدرات النموذج المحدد.
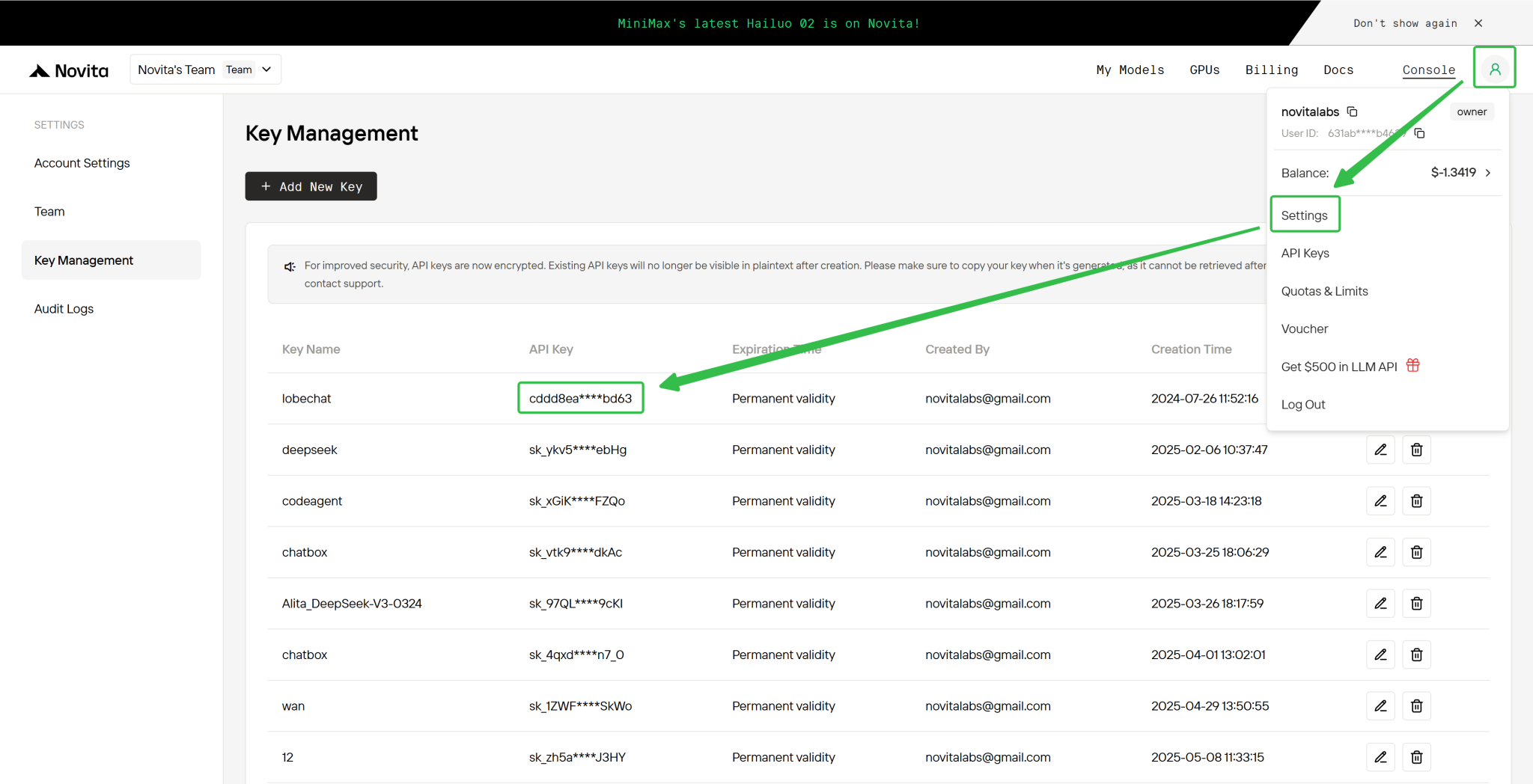
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنزودك بمفتاح API جديد. بالدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.
الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.
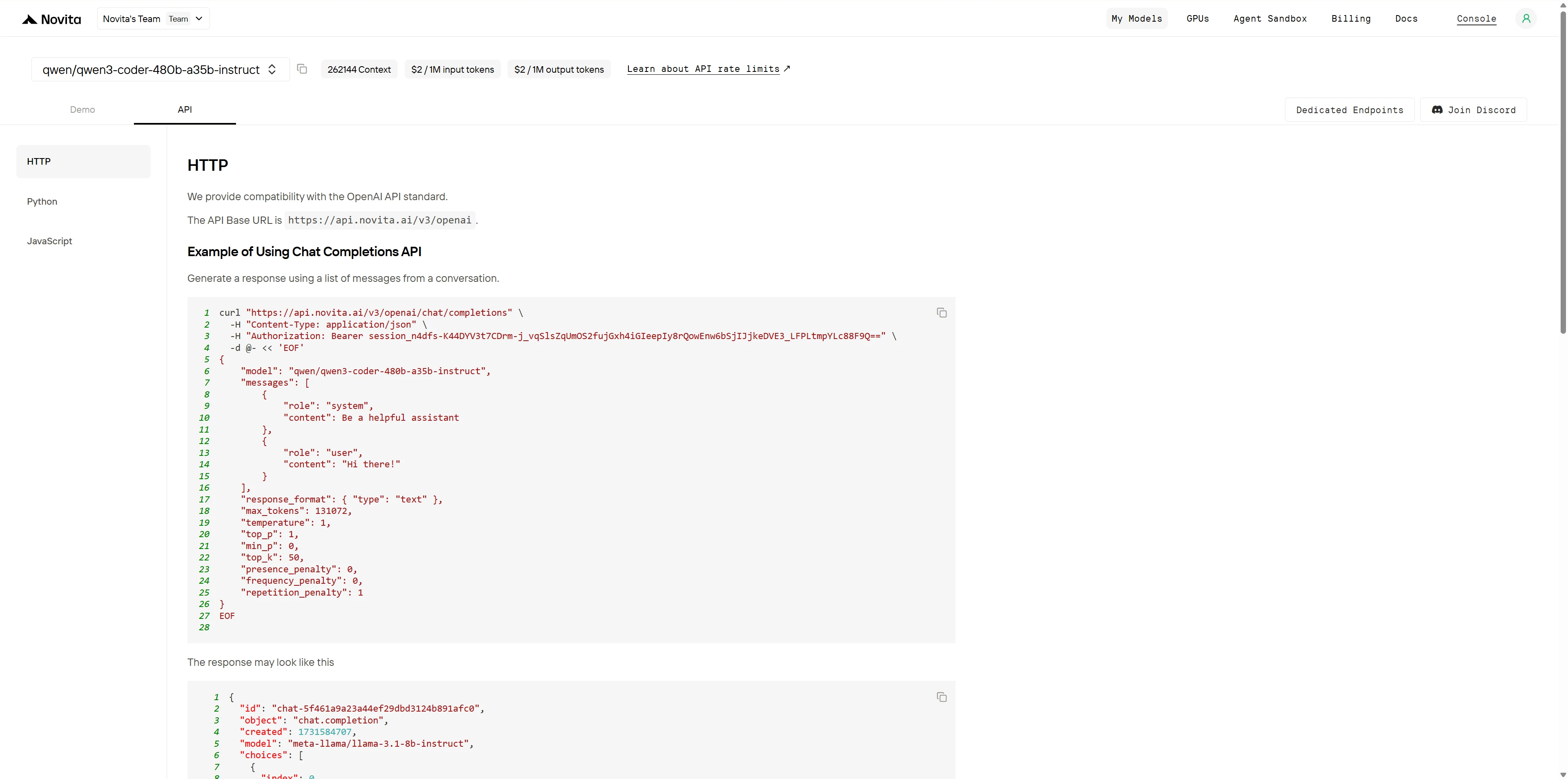
بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام واجهة برمجة تطبيقات chat completions لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_n4dfs-K44DYV3t7CDrm-j_vqSlsZqUmOS2fujGxh4iGIeepIy8rQowEnw6bSjIJjkeDVE3_LFPLtmpYLc88F9Q==",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 131072
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
يتفوق كل من Qwen3-Coder وKimi K2 في أبعاد مختلفة من التطوير بمساعدة الذكاء الاصطناعي. يتميز Qwen3-Coder-480B بأداء المعايير، ومع ذلك، يظهر Kimi K2 التزامًا فائقًا بالتعليمات وتوليدًا عمليًا للكود، مما ينتج باستمرار كودًا وظيفيًا بأقل إشراف. بينما يتألق Qwen3-Coder-480B بقدراته التقنية في مهام البرمجة المنعزلة، فإن موثوقية Kimi K2 وتكامله مع سير العمل يجعله أكثر ملاءمة لبيئات التطوير التعاونية والتطبيقات على مستوى المؤسسات.
يمكن دمج كل من Qwen3-Coder وKimi K2 بسلاسة في سير العمل التطويري الخاص بك من خلال واجهة برمجة تطبيقات Qwen Code المتوافقة مع OpenAI، مما يجلب مساعدة قوية في البرمكة بالذكاء الاصطناعي مباشرة إلى بيئة الطرفية الخاصة بك. انقر لمعرفة المزيد.
يمكنك أيضًا استخدام Kimi K2 في Claude Code للحصول على قدرات ترميز وكيل محسّنة مع توفير كبير في التكاليف. تعلم كيفية إعداد Kimi K2 مع Claude Code.
الأسئلة الشائعة
هل Qwen3 جيد للبرمجة؟
نعم، يتفوق Qwen3-Coder في البرمجة بأداء معياري رائد، ونافذة سياق ضخمة 262 ألف رمز لمعالجة قواعد الأكواد الكبيرة، وقدرات قوية على حل المشكلات الخوارزمية.
ما هو Kimi K2؟
Kimi K2 هو نموذج ذكاء اصطناعي عام طورته Moonshot AI يقدم توليد كود موثوقًا، وخبرة قوية في المجال، وتسعيرًا فعالًا من حيث التكلفة يتراوح بين 0.57 و2.30 دولار لكل مليون رمز.
هل Kimi أفضل من ChatGPT؟
يقدم Kimi K2 قيمة أفضل مع أسعار أقل وجودة كود موثوقة، بينما يوفر ChatGPT معرفة عامة أوسع وقدرات محادثة أكثر صقلًا - يعتمد الاختيار على حالة الاستخدام المحددة والميزانية.
حول Novita AI
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط الخاص بنا، مع توفير أيضًا سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.



