

Key Hightlights
Qwen3-Coder-480B-A35B-Instruct: Specialized coding model with 262K token context length, optimized for algorithmic excellence and benchmark performance in programming tasks.
Kimi K2: General-purpose model with enterprise-grade reliability, optimized for production-ready code generation and cost-effective development workflows.
Novita AI not only provides stable API services but also offers extremely cost-effective pricing. For example, Qwen3-Coder-480B-A35B-Instruct costs $0.95 per 1M input tokens and $5 per 1M output tokens, while Kimi K2 costs $0.57 per 1M input tokens and $2.3 per 1M output tokens.
Basic Introduction of Model
Qwen3-Coder-480B-A35B-Instruct
Qwen3-Coder-480B-A35B-Instruct is a state-of-the-art large-scale causal language model released by Alibaba in July 2025, designed primarily for agentic coding and software development tasks. It employs a Mixture-of-Experts (MoE) architecture with 480 billion total parameters and 35 billion active parameters per forward pass, striking a balance between model capacity and inference efficiency. This model supports extremely long contexts natively at 256K tokens and achieves state-of-the-art performance among open models.
Key Features and Architecture
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 480B in total and 35B activated
- Number of Layers: 62
- Number of Attention Heads (GQA): 96 for Q and 8 for KV
- Number of Experts: 160
- Number of Activated Experts: 8
- Context Length: 262,144 natively.
Kimi K2
Kimi K2 is a breakthrough large-scale language model developed by Moonshot AI, released in July 2025. It features an innovative Mixture-of-Experts (MoE) architecture with 1 trillion total parameters and 32 billion parameters activated per forward pass, enabling efficient scaling and high performance. Kimi K2 is meticulously optimized for agentic intelligence, meaning it can autonomously plan, reason, use tools, and synthesize code with multi-step problem-solving capabilities.
Key Features and Architecture
- Architecture: MoE with 384 experts, selecting 8 per token during inference to balance efficiency and capability.
- Parameters: 1 trillion total, 32 billion active at a time.
- Context Window: 128K tokens.
- Training: Trained on 15.5 trillion tokens using Moonshot’s proprietary MuonClip optimizer to maintain training stability.
- Languages: Primarily optimized for Chinese and English.
- Disk Space: Full model requires approximately 1.09 TB.
Benchmark Comparison
1. Applied Intelligence Benchmarks

2. Context Window:
Qwen3-Coder-480B-A35B-Instruct: 262k Tokens
Kimi K2: 128k Tokens
3. API Pricing:
Qwen3-Coder-480B-A35B-Instruct: $0.95 / $5 in/out per 1M Tokens
Kimi K2: $0.57 / $2.30 in/out per 1M Tokens
Applied Skills Test
1. Code Ability: Data Structure Design Challenge
Objective: Evaluate implementation skills and algorithmic thinking.
Sample Prompt:
“Implement a LRU (Least Recently Used) Cache with get(key) and put(key, value) methods. Capacity is fixed. Both operations must be O(1). Maximum 25 lines of Python code.”
Evaluation Criteria:
-
Algorithm Correctness (40%):
- Does it properly evict least recently used items?
- Are both get/put operations truly O(1)?
- Handles capacity limits correctly?
-
Data Structure Choice (30%):
- Uses appropriate combination (dict + doubly linked list or OrderedDict)?
- Shows understanding of time complexity requirements?
-
Code Quality (20%):
- Clean, readable implementation?
- Proper edge case handling (empty cache, capacity 0)?
- Stays within line limit while being functional?
-
Implementation Completeness (10%):
- Both methods work as specified?
- Includes necessary helper methods/structures?
Qwen3-Coder-480B-A35B-Instruct:
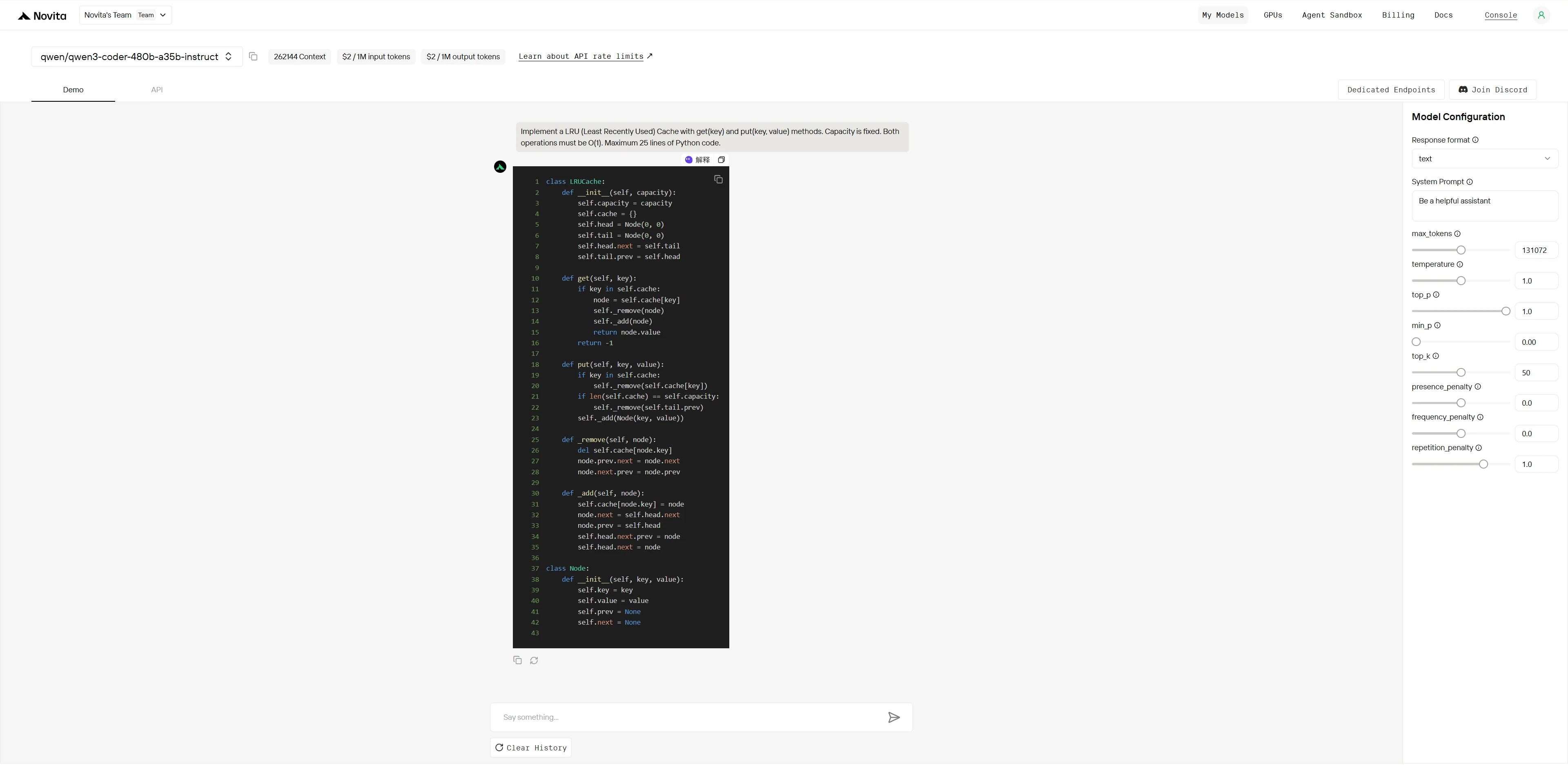
Kimi K2:
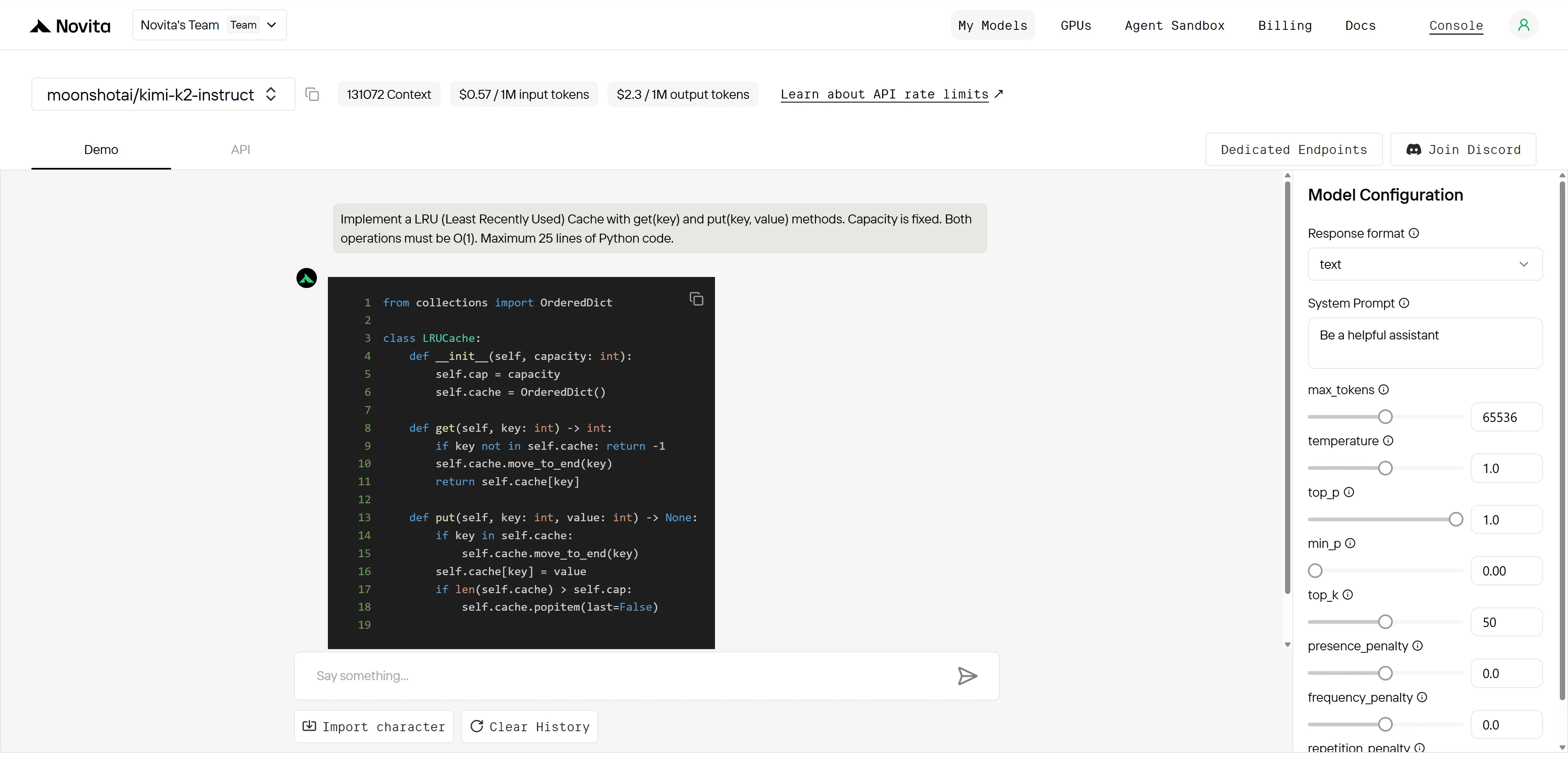
Overall Winner: Kimi K2 (4.9/5) > Qwen (4.2/5)
| Dimension | Qwen | Kimi K2 | Gap |
|---|---|---|---|
| Algorithm Knowledge | 5/5 | 5/5 | None |
| Implementation Accuracy | 3/5 | 5/5 | Large |
| Code Structure | 4/5 | 5/5 | Small |
| Production Readiness | 2/5 | 5/5 | Huge |
Both models understand the algorithm perfectly, but Kimi K2 executes flawlessly while Qwen has a critical bug that breaks core functionality. This shows Kimi K2’s superior implementation precision and quality assurance.
2. Debug Ability: Multi-Layer Error Analysis
Objective: Test systematic debugging and error comprehension skills.
Sample Prompt:
class BankAccount:
def __init__(self, initial_balance):
self.balance = initial_balance
self.transaction_history = []
def transfer_to(self, other_account, amount):
if self.balance >= amount:
self.balance -= amount
other_account.balance += amount
self.transaction_history.append(f"Transfer out: ${amount}")
other_account.transaction_history.append(f"Transfer in: ${amount}")
return True
return False
def get_total_transfers(self):
total = 0
for transaction in self.transaction_history:
if "Transfer" in transaction:
amount_str = transaction.split("$")[1]
total += int(amount_str)
return total
# Test case that reveals multiple issues:
acc1 = BankAccount(100.50)
acc2 = BankAccount(50.75)
acc1.transfer_to(acc2, 25.25)
print(f"Total transfers: ${acc1.get_total_transfers()}") # Crashes with ValueErrorThis code has multiple bugs that cause it to fail. Identify ALL issues, explain why each occurs, and provide the corrected version.
Evaluation Criteria:
-
Issue Identification (35%):
- Finds the float/int conversion error?
- Identifies inconsistent data types (float balances vs int parsing)?
- Spots potential string parsing fragility?
- Recognizes missing validation/error handling?
-
Root Cause Analysis (25%):
- Explains why
int(amount_str)fails on “25.25”? - Understands the type mismatch problem?
- Identifies the string parsing assumption flaw?
- Explains why
-
Solution Completeness (25%):
- Fixes all identified issues?
- Maintains original functionality while making it robust?
- Handles edge cases (malformed strings, etc.)?
-
Code Quality & Best Practices (15%):
- Uses appropriate data types consistently?
- Adds proper validation/error handling?
- Maintains clean, readable code structure?
Qwen3-Coder-480B-A35B-Instruct:
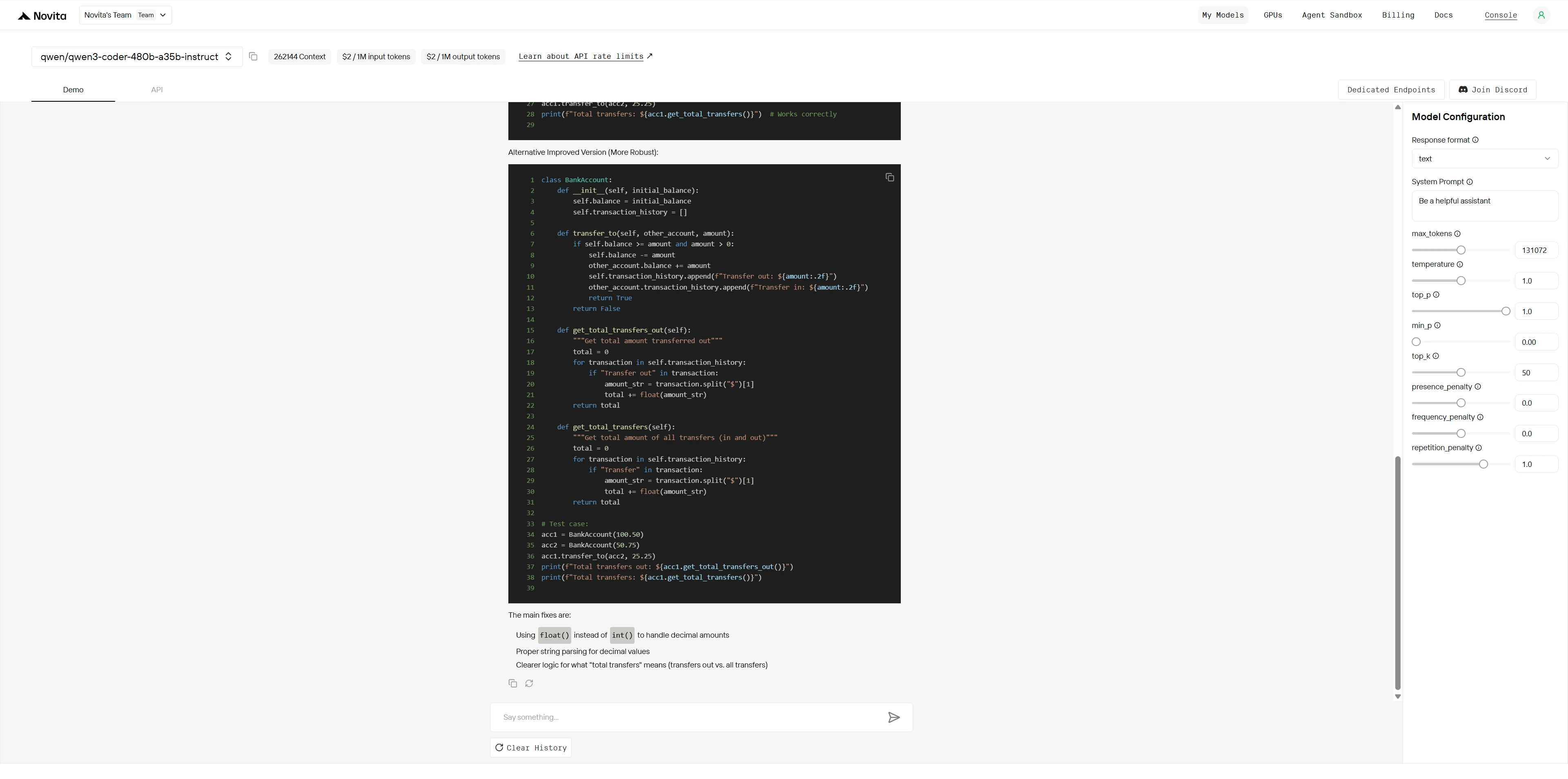
Kimi K2:
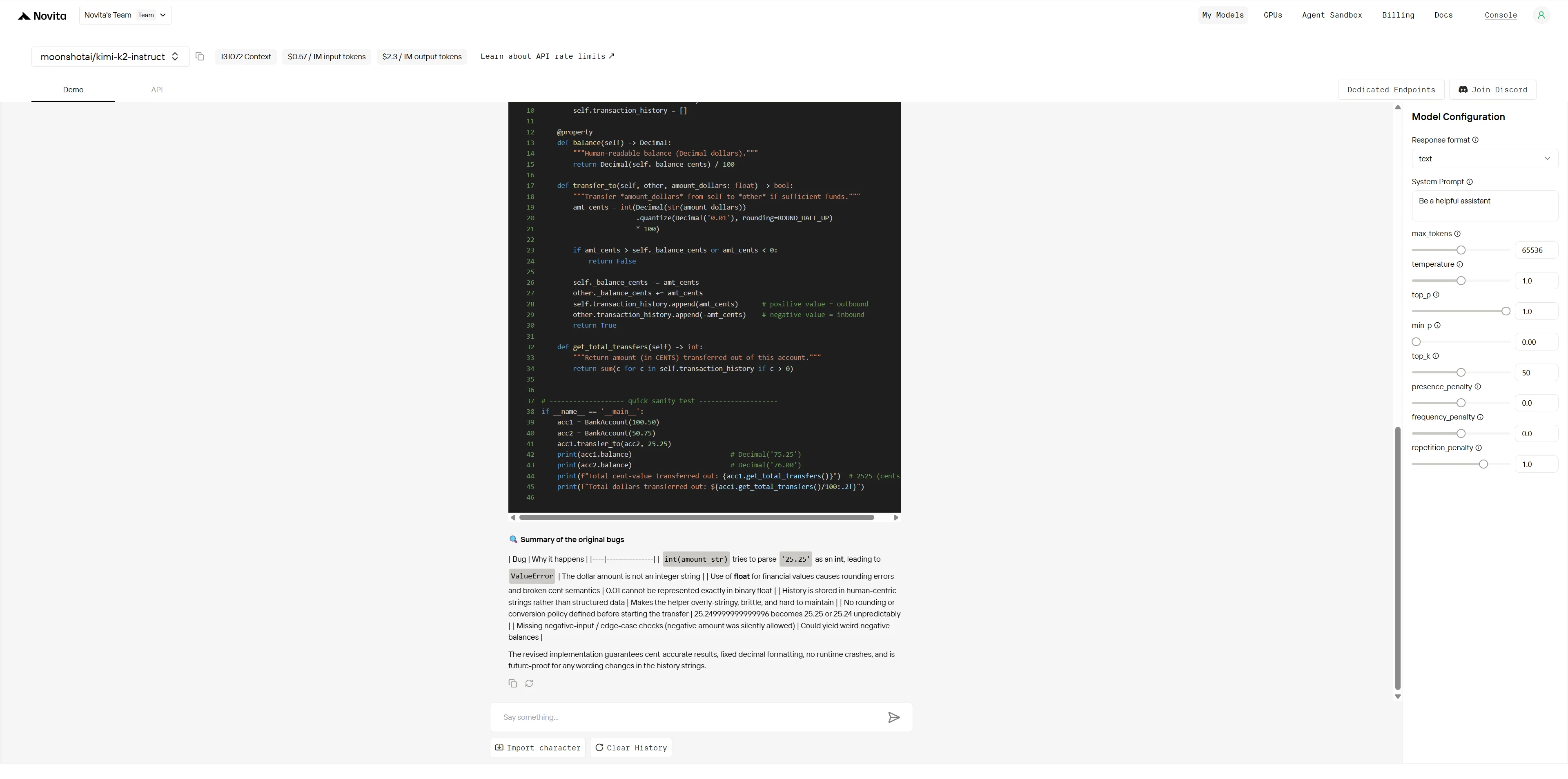
Overall Winner: Kimi K2 (4.9/5) > Qwen (3.8/5)
| Dimension | Qwen | Kimi K2 | Gap |
|---|---|---|---|
| Bug Identification | 4/5 | 5/5 | Small |
| Root Cause Analysis | 4/5 | 5/5 | Small |
| Solution Quality | 4/5 | 5/5 | Small |
| Domain Expertise | 3/5 | 5/5 | Large |
| Production Readiness | 3/5 | 5/5 | Large |
| Architectural Thinking | 3/5 | 5/5 | Large |
Try Kimi K2 and Qwen 3 Coder Yourself!
While both models can identify obvious bugs, Kimi K2 demonstrates expert-level debugging with deep domain knowledge, systematic problem-solving, and production-grade solutions. Qwen provides competent but surface-level fixes, while Kimi K2 delivers professional-grade architectural improvements that prevent future issues.
Strengths & Weaknesses
Qwen3-Coder-480B-A35B-Instruct
Strengths:
- Massive Context Window: 262K tokens (2x Kimi’s capacity)
Weaknesses:
- Implementation Inconsistency: Sometimes produces code with critical logic flaws
- Surface-Level Debugging: Focuses on obvious issues, misses architectural problems
- Limited Domain Expertise: Generic programming approach without specialized knowledge
Kimi K2
Strengths:
- Consistent Code Quality: Reliable, production-ready implementations, consistently produced functional code with little oversight
- Comprehensive Problem-Solving: Identifies edge cases and architectural issues
- Superior Cost Efficiency: $0.57-2.30 per 1M tokens (up to 2x cheaper)
- Professional Engineering: Proper error handling and defensive programming
Weaknesses:
- Smaller Context Window: 128K tokens (half of Qwen’s capacity)
How to Access Qwen3-Coder-480B-A35B-Instruct and Kimi K2 on Novita AI
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.
Try Kimi K2 and Qwen 3 Coder Now!
Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
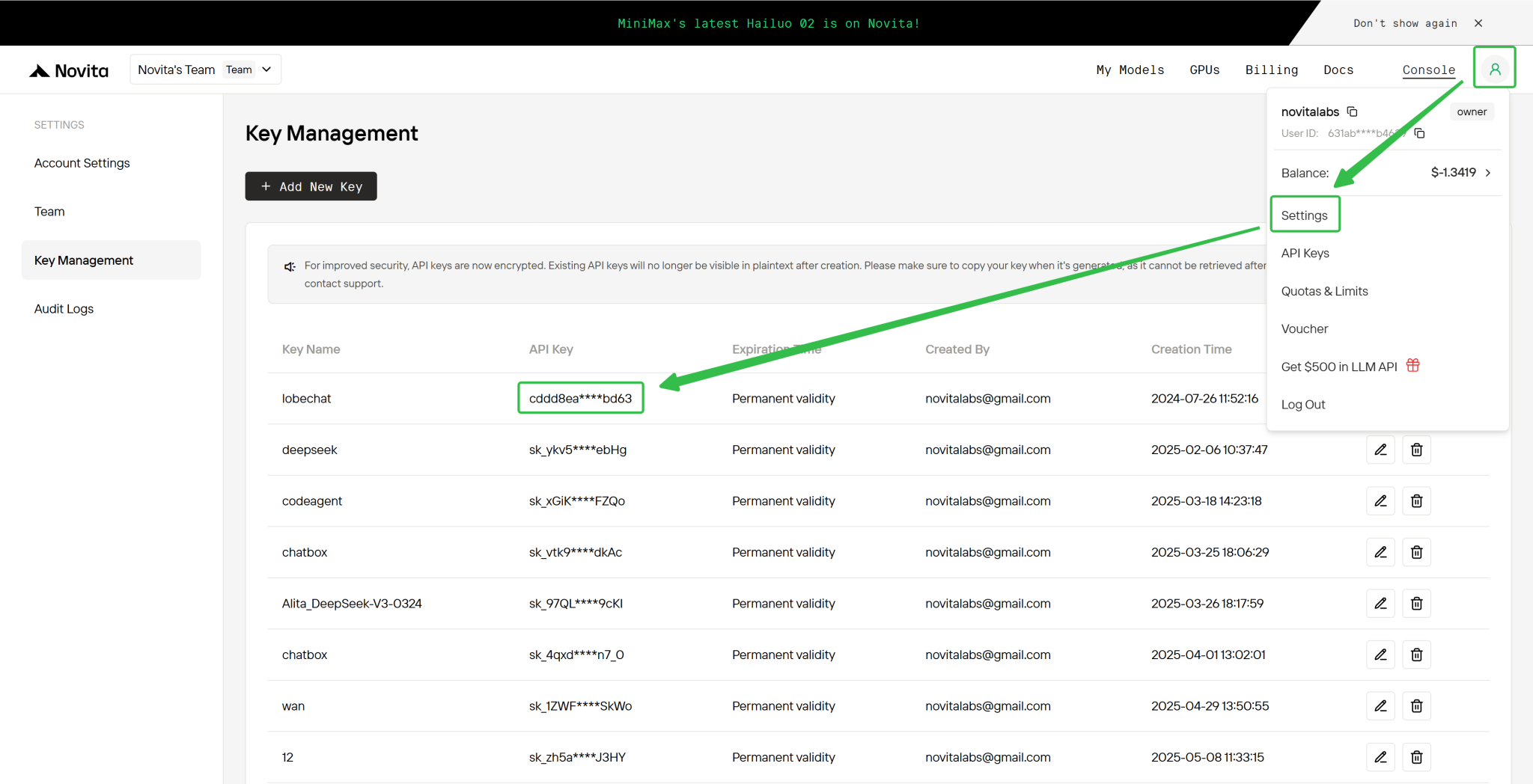
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.
Step 5: Install the API
Install API using the package manager specific to your programming language.
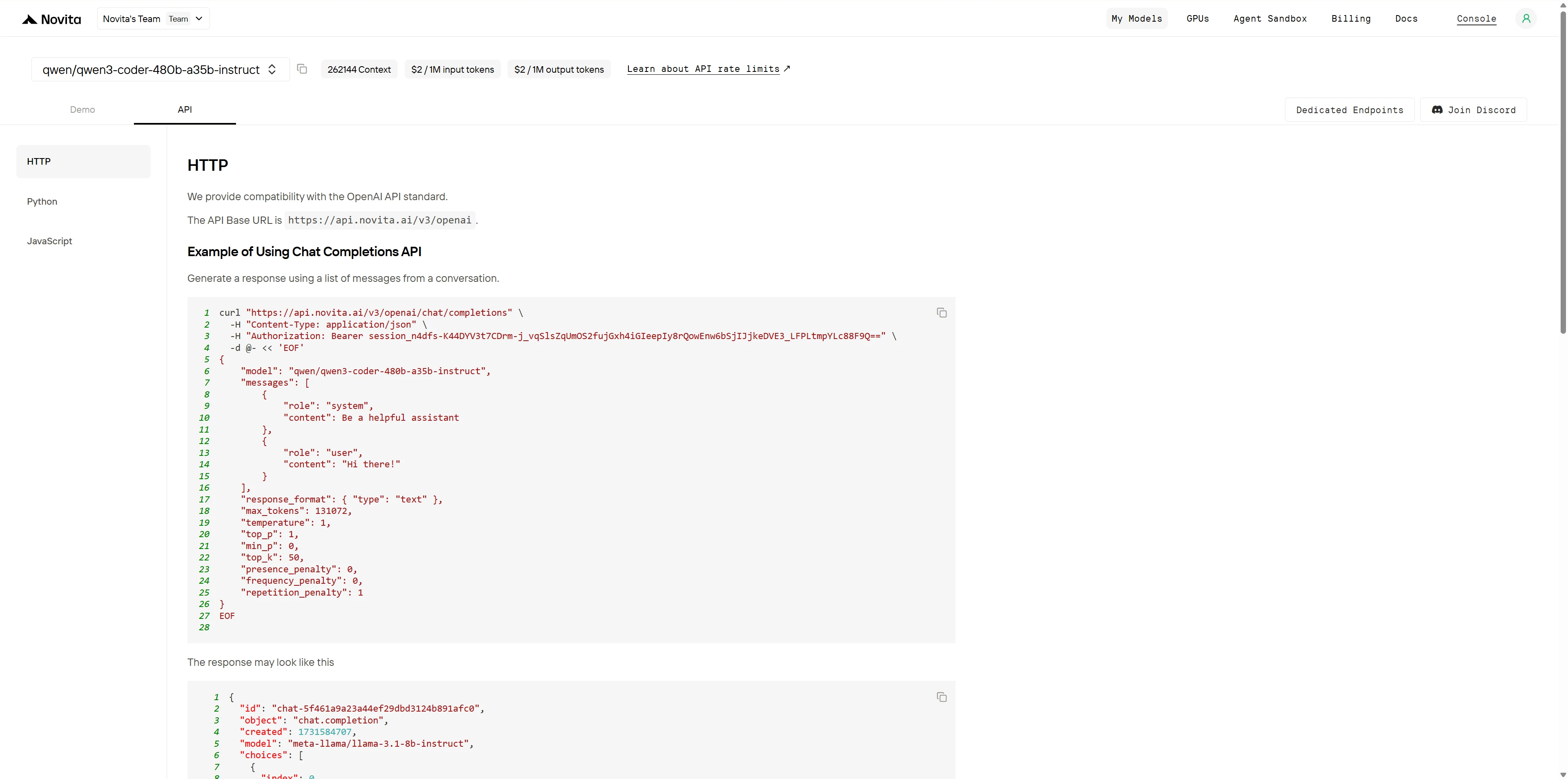
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_n4dfs-K44DYV3t7CDrm-j_vqSlsZqUmOS2fujGxh4iGIeepIy8rQowEnw6bSjIJjkeDVE3_LFPLtmpYLc88F9Q==",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 131072
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)Both Qwen3-Coder and Kimi K2 excel in different dimensions of AI-assisted development. Qwen3-Coder-480B excels in benchmark performance, however, Kimi K2 shows superior instruction adherence and practical code generation, consistently producing functional code with minimal supervision. While Qwen3-Coder-480B’s technical prowess shines in isolated coding tasks, Kimi K2’s reliability and workflow integration make it more suitable for collaborative development environments and enterprise-grade applications.
Both Qwen3-Coder and Kimi K2 can be seamlessly integrated into your development workflow through Qwen Code’s OpenAI-compatible API, bringing powerful AI coding assistance directly to your terminal environment. Click to see more.
You can also use Kimi K2 in Claude Code for enhanced agentic coding capabilities with significant cost savings . Learn how to set up Kimi K2 with Claude Code.
Frequently Asked Questions
Is Qwen3 good for coding?
Yes, Qwen3-Coder excels at coding with top benchmark performance, massive 262K context window for handling large codebases, and strong algorithmic problem-solving capabilities.
What is Kimi K2?
Kimi K2 is a general-purpose AI model developed by Moonshot AI that offers reliable code generation, strong domain expertise, and cost-effective pricing at $0.57-2.30 per 1M tokens.
Is Kimi better than ChatGPT?
Kimi K2 offers better value with lower pricing and reliable code quality, while ChatGPT provides broader general knowledge and more polished conversational abilities - the choice depends on your specific use case and budget.
About Novita AI
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



