

Points clés
Qwen3-Coder-480B-A35B-Instruct : Modèle de codage spécialisé avec une longueur de contexte de 262 000 tokens, optimisé pour l’excellence algorithmique et les performances de benchmark dans les tâches de programmation.
Kimi K2 : Modèle généraliste avec une fiabilité de niveau entreprise, optimisé pour la génération de code prêt pour la production et des flux de développement rentables.
Novita AI propose non seulement des services API stables, mais aussi des tarifs extrêmement compétitifs. Par exemple, Qwen3-Coder-480B-A35B-Instruct coûte 0,95 $ pour 1 million de tokens en entrée et 5 $ pour 1 million de tokens en sortie, tandis que Kimi K2 coûte 0,57 $ pour 1 million de tokens en entrée et 2,3 $ pour 1 million de tokens en sortie.
Présentation générale des modèles
Qwen3-Coder-480B-A35B-Instruct
Qwen3-Coder-480B-A35B-Instruct est un modèle de langage causal à grande échelle de pointe publié par Alibaba en juillet 2025, conçu principalement pour le codage agentique et les tâches de développement logiciel. Il utilise une architecture Mixture-of-Experts (MoE) avec 480 milliards de paramètres totaux et 35 milliards de paramètres actifs par passage avant, offrant un équilibre entre capacité du modèle et efficacité d’inférence. Ce modèle prend en charge des contextes extrêmement longs de manière native (256 000 tokens) et atteint des performances de pointe parmi les modèles ouverts.
Caractéristiques et architecture principales
- Type : Modèles de langage causal
- Étape d’entraînement : Pré-entraînement et post-entraînement
- Nombre de paramètres : 480B au total et 35B activés
- Nombre de couches : 62
- Nombre de têtes d’attention (GQA) : 96 pour Q et 8 pour KV
- Nombre d’experts : 160
- Nombre d’experts activés : 8
- Longueur de contexte : 262 144 tokens de manière native.
Kimi K2
Kimi K2 est un modèle de langage à grande échelle révolutionnaire développé par Moonshot AI, publié en juillet 2025. Il dispose d’une architecture innovante Mixture-of-Experts (MoE) avec 1 billion de paramètres totaux et 32 milliards de paramètres activés par passage avant, permettant un passage à l’échelle efficace et des performances élevées. Kimi K2 est méticuleusement optimisé pour l’intelligence agentique, ce qui signifie qu’il peut planifier, raisonner, utiliser des outils et synthétiser du code de manière autonome avec des capacités de résolution de problèmes en plusieurs étapes.
Caractéristiques et architecture principales
- Architecture : MoE avec 384 experts, sélectionnant 8 par token lors de l’inférence pour équilibrer efficacité et capacité.
- Paramètres : 1 billion au total, 32 milliards actifs à la fois.
- Fenêtre de contexte : 128 000 tokens.
- Entraînement : Entraîné sur 15,5 billions de tokens en utilisant l’optimiseur propriétaire MuonClip de Moonshot pour maintenir la stabilité de l’entraînement.
- Langues : Principalement optimisé pour le chinois et l’anglais.
- Espace disque : Le modèle complet nécessite environ 1,09 To.
Comparaison des benchmarks
1. Benchmarks d’intelligence appliquée

2. Fenêtre de contexte :
Qwen3-Coder-480B-A35B-Instruct: 262 000 tokens
Kimi K2: 128 000 tokens
3. Tarification API :
Qwen3-Coder-480B-A35B-Instruct: 0,95 $ / 5 $ entrée/sortie pour 1 million de tokens
Kimi K2: 0,57 $ / 2,30 $ entrée/sortie pour 1 million de tokens
Test de compétences appliquées
1. Capacité de code : Défi de conception de structure de données
Objectif : Évaluer les compétences d’implémentation et la pensée algorithmique.
Exemple de prompt :
“Implémentez un cache LRU (Least Recently Used) avec les méthodes get(key) et put(key, value). La capacité est fixe. Les deux opérations doivent être en O(1). Maximum 25 lignes de code Python.”
Critères d’évaluation :
-
Correction algorithmique (40 %) :
- Expulse-t-il correctement les éléments les moins récemment utilisés ?
- Les opérations get/put sont-elles vraiment en O(1) ?
- Gère-t-il correctement les limites de capacité ?
-
Choix de la structure de données (30 %) :
- Utilise-t-il une combinaison appropriée (dict + liste doublement chaînée ou OrderedDict) ?
- Montre-t-il une compréhension des exigences de complexité temporelle ?
-
Qualité du code (20 %) :
- Implémentation propre et lisible ?
- Gestion correcte des cas limites (cache vide, capacité 0) ?
- Reste dans la limite de lignes tout en étant fonctionnel ?
-
Exhaustivité de l’implémentation (10 %) :
- Les deux méthodes fonctionnent-elles comme spécifié ?
- Inclut-il les méthodes/structures d’aide nécessaires ?
Qwen3-Coder-480B-A35B-Instruct:
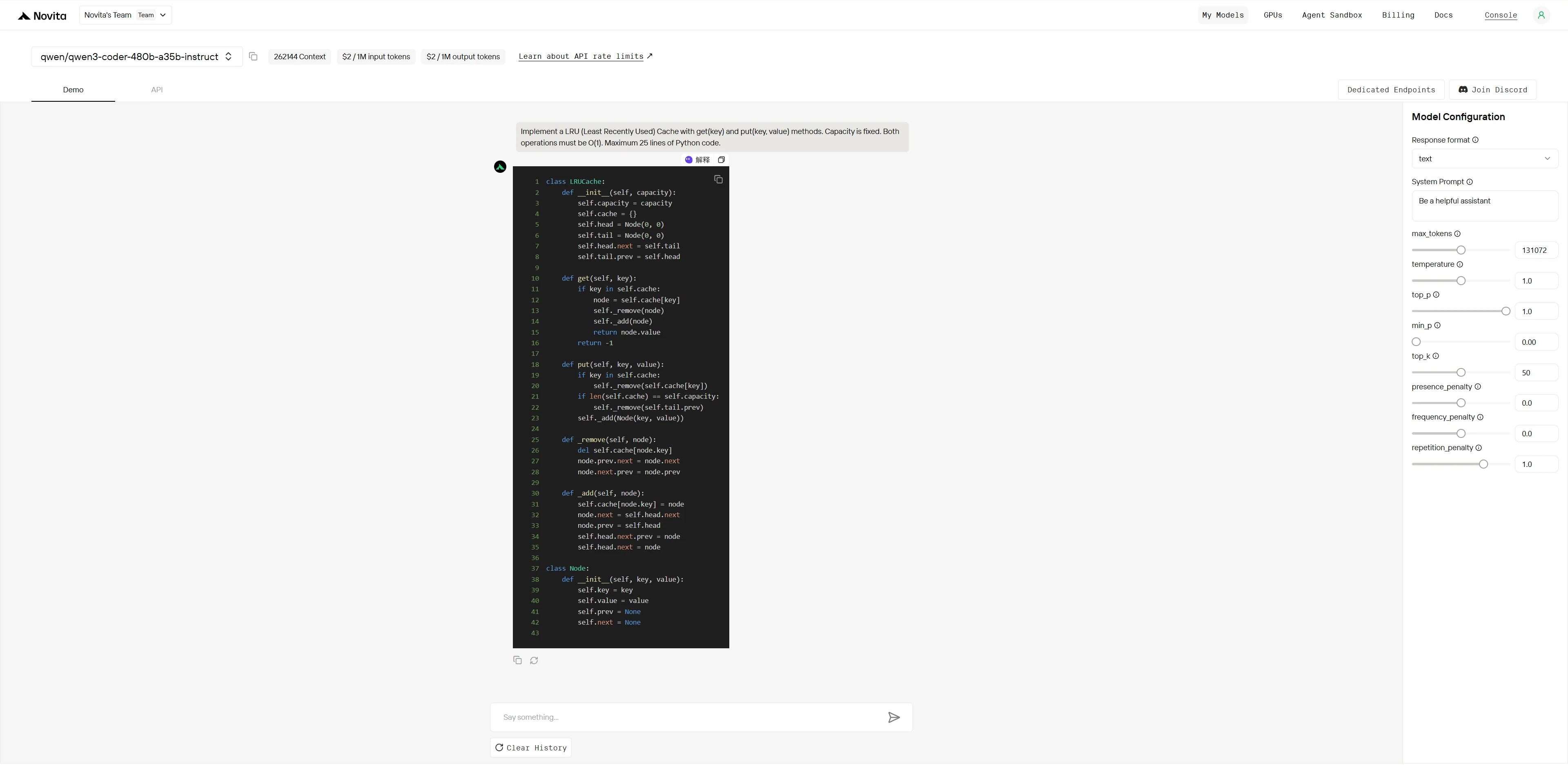
Kimi K2 :
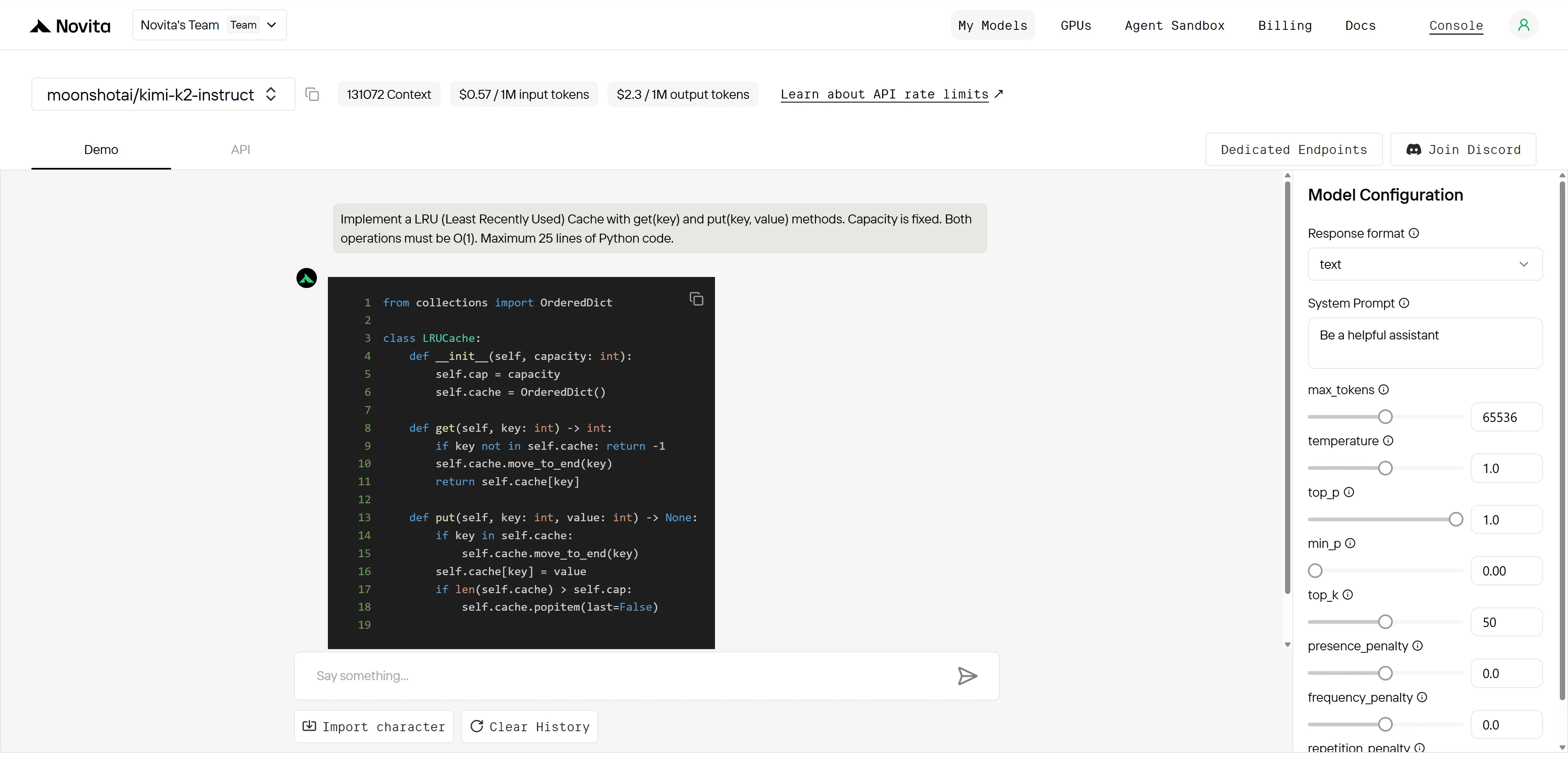
Vainqueur global : Kimi K2 (4,9/5) > Qwen (4,2/5)
| Dimension | Qwen | Kimi K2 | Écart |
|---|---|---|---|
| Connaissance algorithmique | 5/5 | 5/5 | Aucun |
| Précision d’implémentation | 3/5 | 5/5 | Grand |
| Structure du code | 4/5 | 5/5 | Petit |
| Préparation à la production | 2/5 | 5/5 | Énorme |
Essayez Qwen 3 Coder et Kimi K2 !
Les deux modèles comprennent parfaitement l’algorithme, mais Kimi K2 exécute sans faille tandis que Qwen a un bug critique qui brise la fonctionnalité principale. Cela montre la précision d’implémentation et l’assurance qualité supérieures de Kimi K2.
2. Capacité de débogage : Analyse d’erreurs multicouche
Objectif : Tester les compétences de débogage systématique et de compréhension des erreurs.
Exemple de prompt :
class BankAccount:
def __init__(self, initial_balance):
self.balance = initial_balance
self.transaction_history = []
def transfer_to(self, other_account, amount):
if self.balance >= amount:
self.balance -= amount
other_account.balance += amount
self.transaction_history.append(f"Transfer out: ${amount}")
other_account.transaction_history.append(f"Transfer in: ${amount}")
return True
return False
def get_total_transfers(self):
total = 0
for transaction in self.transaction_history:
if "Transfer" in transaction:
amount_str = transaction.split("$")[1]
total += int(amount_str)
return total
# Test case that reveals multiple issues:
acc1 = BankAccount(100.50)
acc2 = BankAccount(50.75)
acc1.transfer_to(acc2, 25.25)
print(f"Total transfers: ${acc1.get_total_transfers()}") # Crashes with ValueError
Ce code contient plusieurs bogues qui le font échouer. Identifiez TOUS les problèmes, expliquez pourquoi chacun se produit et fournissez la version corrigée.
Critères d’évaluation :
-
Identification des problèmes (35 %) :
- Trouve-t-il l’erreur de conversion float/int ?
- Identifie-t-il les types de données incohérents (soldes float vs analyse int) ?
- Repère-t-il la fragilité potentielle de l’analyse de chaîne ?
- Reconnaît-il le manque de validation/gestion des erreurs ?
-
Analyse des causes racines (25 %) :
- Explique-t-il pourquoi
int(amount_str)échoue sur “25.25” ? - Comprend-il le problème de décalage de type ?
- Identifie-t-il le défaut d’hypothèse d’analyse de chaîne ?
- Explique-t-il pourquoi
-
Exhaustivité de la solution (25 %) :
- Corrige-t-il tous les problèmes identifiés ?
- Maintient-il la fonctionnalité d’origine tout en la rendant robuste ?
- Gère-t-il les cas limites (chaînes malformées, etc.) ?
-
Qualité du code et bonnes pratiques (15 %) :
- Utilise-t-il des types de données appropriés de manière cohérente ?
- Ajoute-t-il une validation/gestion des erreurs appropriée ?
- Maintient-il une structure de code propre et lisible ?
Qwen3-Coder-480B-A35B-Instruct:
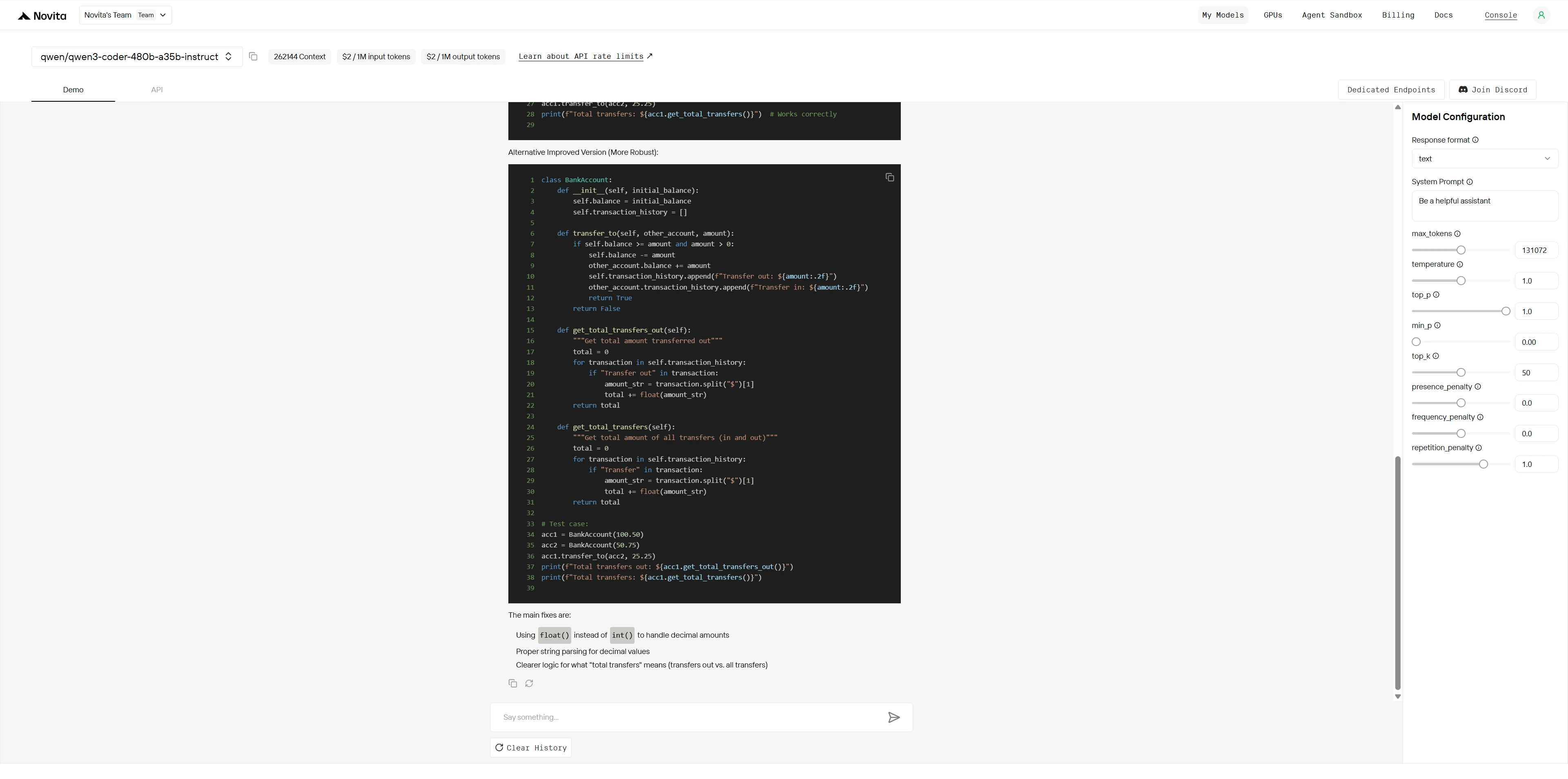
Kimi K2 :
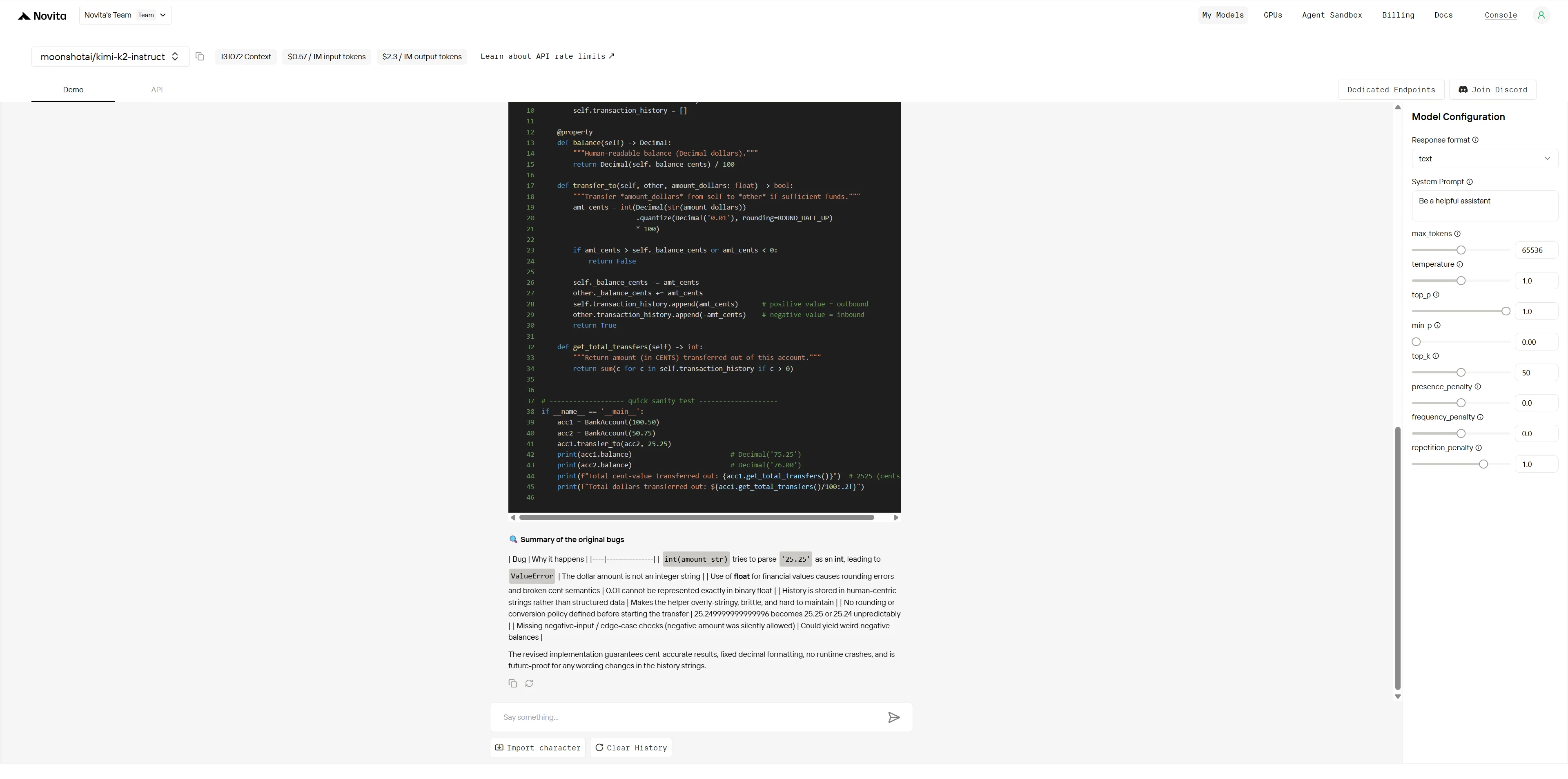
Vainqueur global : Kimi K2 (4,9/5) > Qwen (3,8/5)
| Dimension | Qwen | Kimi K2 | Écart |
|---|---|---|---|
| Identification des bogues | 4/5 | 5/5 | Petit |
| Analyse des causes racines | 4/5 | 5/5 | Petit |
| Qualité de la solution | 4/5 | 5/5 | Petit |
| Expertise du domaine | 3/5 | 5/5 | Grand |
| Préparation à la production | 3/5 | 5/5 | Grand |
| Pensée architecturale | 3/5 | 5/5 | Grand |
Essayez Kimi K2 et Qwen 3 Coder vous-même !
Alors que les deux modèles peuvent identifier les bogues évidents, Kimi K2 démontre un débogage de niveau expert avec une connaissance approfondie du domaine, une résolution de problèmes systématique et des solutions de qualité production. Qwen fournit des correctifs compétents mais superficiels, tandis que Kimi K2 propose des améliorations architecturales de niveau professionnel qui préviennent les problèmes futurs.
Forces et faiblesses
Qwen3-Coder-480B-A35B-Instruct
Points forts :
- Fenêtre de contexte massive : 262 000 tokens (2x la capacité de Kimi)
Points faibles :
- Incohérence d’implémentation : Produit parfois du code avec des défauts logiques critiques
- Débogage superficiel : Se concentre sur les problèmes évidents, manque les problèmes architecturaux
- Expertise de domaine limitée : Approche de programmation générique sans connaissances spécialisées
Kimi K2
Points forts :
- Qualité de code constante : Implémentations fiables et prêtes pour la production, produisant constamment du code fonctionnel avec une supervision minimale
- Résolution de problèmes complète : Identifie les cas limites et les problèmes architecturaux
- Rentabilité supérieure : 0,57 $ à 2,30 $ par million de tokens (jusqu’à 2x moins cher)
- Ingénierie professionnelle : Gestion appropriée des erreurs et programmation défensive
Points faibles :
- Fenêtre de contexte plus petite : 128 000 tokens (moitié de la capacité de Qwen)
Comment accéder à Qwen3-Coder-480B-A35B-Instruct et Kimi K2 sur Novita AI
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.
Essayez Kimi K2 et Qwen 3 Coder maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page Settings, vous pouvez copier la clé API comme indiqué sur l’image.
Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_n4dfs-K44DYV3t7CDrm-j_vqSlsZqUmOS2fujGxh4iGIeepIy8rQowEnw6bSjIJjkeDVE3_LFPLtmpYLc88F9Q==",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 131072
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen3-Coder et Kimi K2 excellent tous deux dans différentes dimensions du développement assisté par IA. Qwen3-Coder-480B excelle dans les performances de benchmark, mais Kimi K2 montre une adhésion supérieure aux instructions et une génération de code pratique, produisant constamment du code fonctionnel avec une supervision minimale. Alors que la puissance technique de Qwen3-Coder-480B brille dans les tâches de codage isolées, la fiabilité et l’intégration dans le flux de travail de Kimi K2 le rendent plus adapté aux environnements de développement collaboratifs et aux applications de niveau entreprise.
Qwen3-Coder et Kimi K2 peuvent tous deux être intégrés de manière transparente dans votre flux de développement grâce à l’API compatible OpenAI de Qwen Code, apportant une assistance au codage IA puissante directement dans votre environnement terminal. Cliquez pour en savoir plus.
Vous pouvez également utiliser Kimi K2 dans Claude Code pour des capacités de codage agentiques améliorées avec des économies de coûts significatives. Apprenez à configurer Kimi K2 avec Claude Code.
Foire aux questions
Est-ce que Qwen3 est bon pour le codage ?
Oui, Qwen3-Coder excelle dans le codage avec des performances de benchmark de premier ordre, une fenêtre de contexte massive de 262 000 tokens pour gérer de grandes bases de code, et de fortes capacités de résolution de problèmes algorithmiques.
Qu’est-ce que Kimi K2 ?
Kimi K2 est un modèle d’IA généraliste développé par Moonshot AI qui offre une génération de code fiable, une expertise de domaine solide et des tarifs économiques à 0,57 $ - 2,30 $ par million de tokens.
Kimi est-il meilleur que ChatGPT ?
Kimi K2 offre un meilleur rapport qualité-prix avec des prix plus bas et une qualité de code fiable, tandis que ChatGPT fournit des connaissances générales plus larges et des capacités de conversation plus polies - le choix dépend de votre cas d’utilisation spécifique et de votre budget.
À propos de Novita AI
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA en utilisant notre API simple, tout en fournissant également le cloud GPU abordable et fiable pour construire et passer à l’échelle.



