

关键要点
Qwen3-Coder-480B-A35B-Instruct:专注于编程的模型,拥有 262K token 上下文长度,在算法卓越性与编程任务基准测试中表现优异。
Kimi K2:通用模型,具备企业级可靠性,专为生成生产级代码和成本效益的开发工作流而优化。
Novita AI 不仅提供稳定的 API 服务,还拥有极具性价比的定价。例如, Qwen3-Coder-480B-A35B-Instruct 的价格为每百万输入 token $0.95,每百万输出 token $5;而 Kimi K2 的价格为每百万输入 token $0.57,每百万输出 token $2.3。
模型基础介绍
Qwen3-Coder-480B-A35B-Instruct
Qwen3-Coder-480B-A35B-Instruct 是阿里巴巴于 2025 年 7 月发布的最新一代大型因果语言模型,主要面向智能编码与软件开发任务。它采用混合专家(MoE)架构,总参数达 4800 亿,每次前向传播激活 350 亿参数,在模型容量与推理效率间取得平衡。该模型原生支持 256K token 的极长上下文,在开放模型中达到最先进的性能。
主要特性与架构
- 类型:因果语言模型
- 训练阶段:预训练与后训练
- 参数量:总计 480B,激活 35B
- 层数:62
- 注意力头数(GQA):Q 头 96,KV 头 8
- 专家数:160
- 激活专家数:8
- 上下文长度:原生 262,144 token
Kimi K2
Kimi K2 是 Moonshot AI 于 2025 年 7 月发布的突破性大型语言模型。它采用创新的混合专家(MoE)架构,总参数达 1 万亿,每次前向传播激活 320 亿参数,实现高效扩展与卓越性能。Kimi K2 专为智能体智能而精细优化,能够自主规划、推理、使用工具并合成代码,具备多步问题解决能力。
主要特性与架构
- 架构:MoE,包含 384 个专家,每次推理选择 8 个专家以平衡效率与能力。
- 参数:总计 1 万亿,同时激活 320 亿。
- 上下文窗口:128K token。
- 训练:使用 Moonshot 专有的 MuonClip 优化器在 15.5 万亿 token 上训练,保持训练稳定性。
- 语言:主要针对中文和英文优化。
- 磁盘空间:完整模型约需 1.09 TB。
基准测试对比
1. 应用智能基准测试

2. 上下文窗口:
Qwen3-Coder-480B-A35B-Instruct: 262k Token
Kimi K2: 128k Token
3. API 定价:
Qwen3-Coder-480B-A35B-Instruct: 每百万 token $0.95(输入)/ $5(输出)
Kimi K2: 每百万 token $0.57(输入)/ $2.30(输出)
应用技能测试
1. 代码能力:数据结构设计挑战
目标: 评估实现技能与算法思维。
示例提示:
“实现一个 LRU(最近最少使用)缓存,包含 get(key) 和 put(key, value) 方法。容量固定。两个操作必须为 O(1)。Python 代码最多 25 行。”
评估标准:
-
算法正确性(40%):
- 是否正确驱逐最久未使用的项目?
- get/put 操作是否真正 O(1)?
- 是否正确处理容量限制?
-
数据结构选择(30%):
- 是否使用了合适的组合(字典 + 双向链表或 OrderedDict)?
- 是否体现了对时间复杂度要求的理解?
-
代码质量(20%):
- 实现是否清晰、可读?
- 是否正确处理边界情况(空缓存、容量为 0)?
- 在保持功能的同时是否遵守行数限制?
-
实现完整性(10%):
- 两个方法是否按规范工作?
- 是否包含必要的辅助方法/结构?
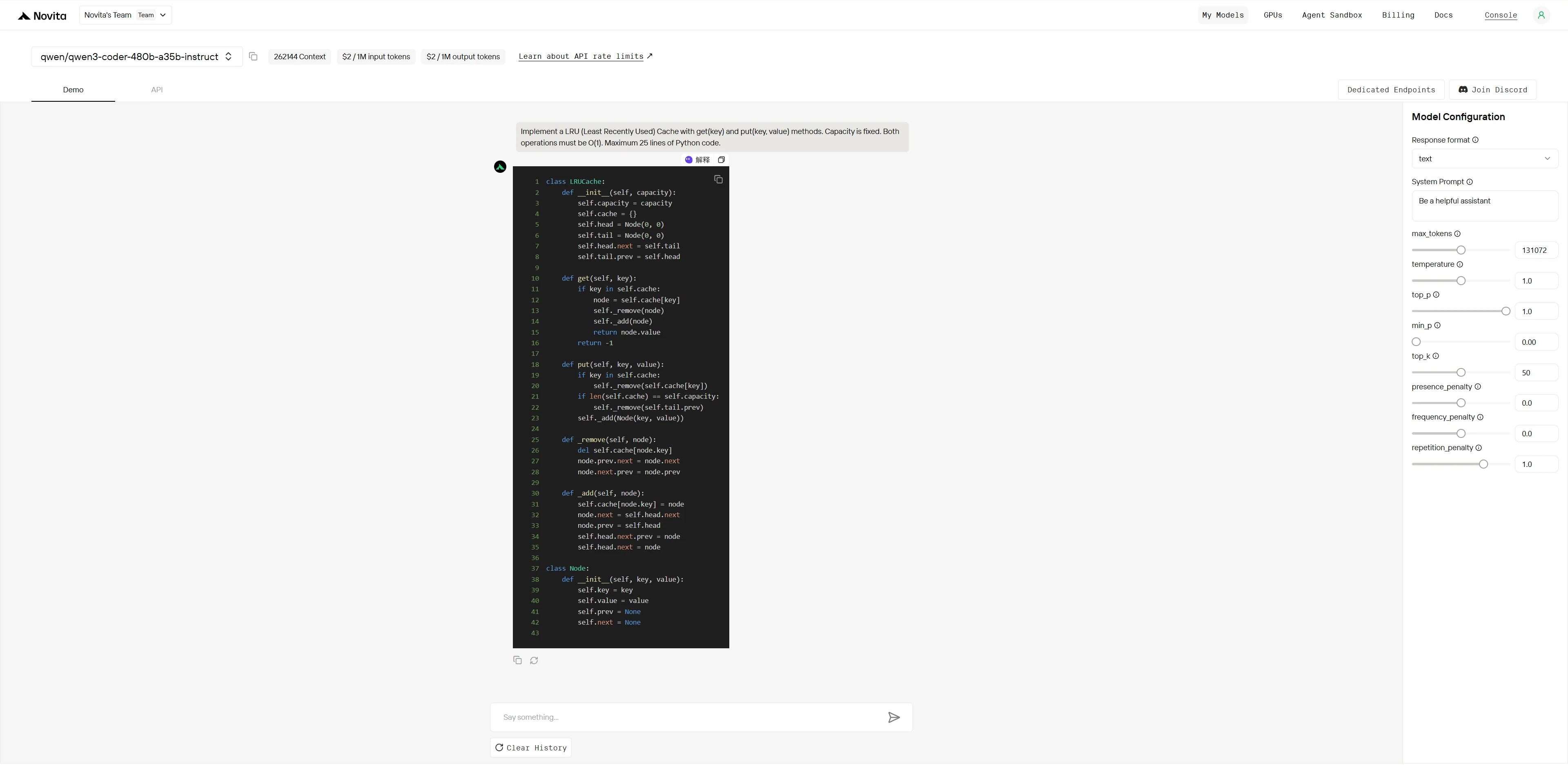
Qwen3-Coder-480B-A35B-Instruct:
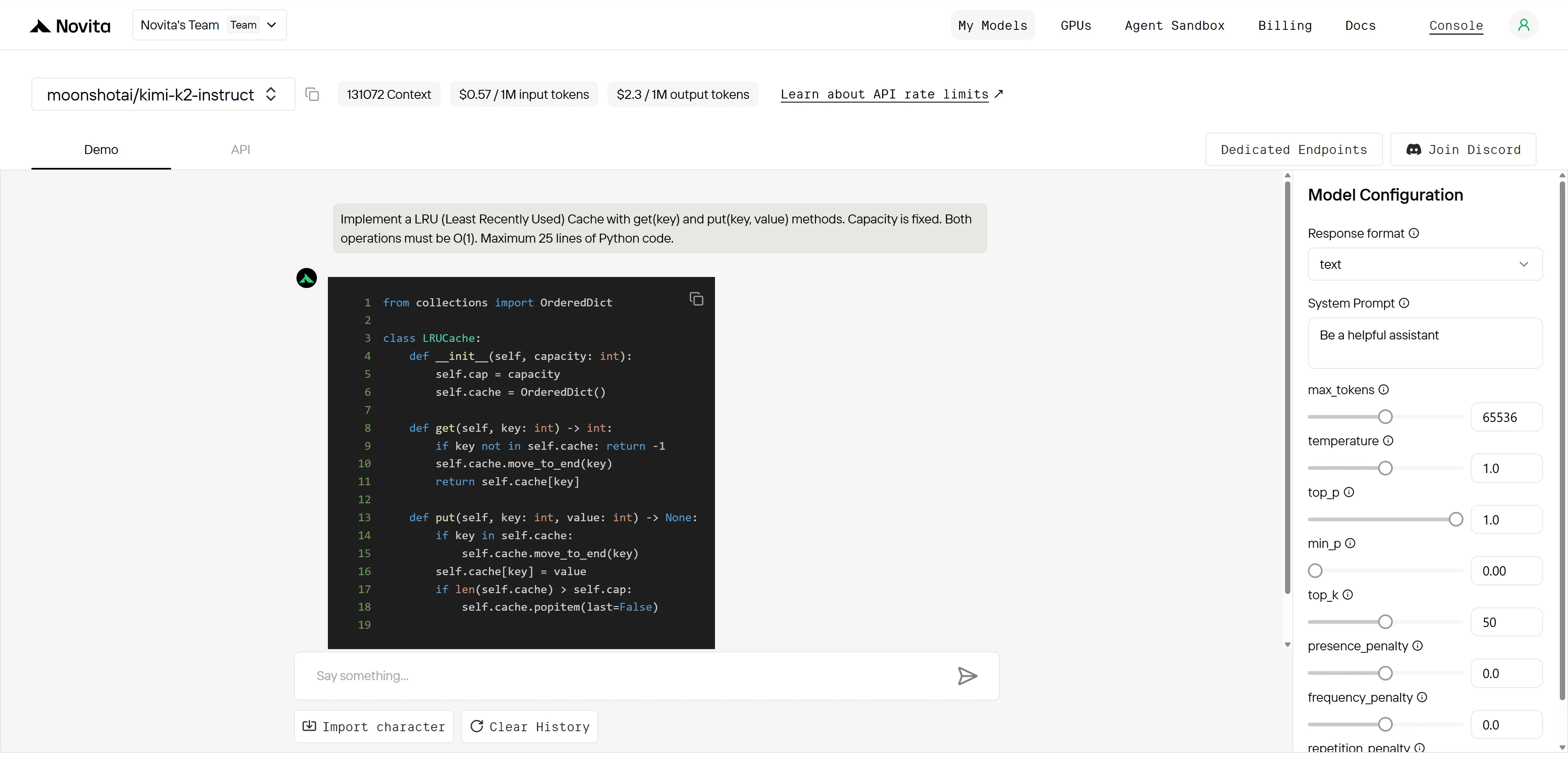
Kimi K2:
总体胜出者:Kimi K2(4.9/5)> Qwen(4.2/5)
| 维度 | Qwen | Kimi K2 | 差距 |
|---|---|---|---|
| 算法知识 | 5/5 | 5/5 | 无 |
| **实现准确性 ** | 3/5 | 5/5 | ** 大** |
| 代码结构 | 4/5 | 5/5 | 小 |
| **生产就绪度 ** | 2/5 | 5/5 | ** 巨大** |
两个模型都完全理解算法,但 Kimi K2 执行完美无缺,而 Qwen 存在一个严重错误 ,破坏了核心功能。这表明 Kimi K2 在 实现精度 和 质量保证方面更胜一筹。
2. 调试能力:多层错误分析
目标: 测试系统化调试与错误理解能力。
示例提示:
class BankAccount:
def __init__(self, initial_balance):
self.balance = initial_balance
self.transaction_history = []
def transfer_to(self, other_account, amount):
if self.balance >= amount:
self.balance -= amount
other_account.balance += amount
self.transaction_history.append(f"Transfer out: ${amount}")
other_account.transaction_history.append(f"Transfer in: ${amount}")
return True
return False
def get_total_transfers(self):
total = 0
for transaction in self.transaction_history:
if "Transfer" in transaction:
amount_str = transaction.split("$")[1]
total += int(amount_str)
return total
# Test case that reveals multiple issues:
acc1 = BankAccount(100.50)
acc2 = BankAccount(50.75)
acc1.transfer_to(acc2, 25.25)
print(f"Total transfers: ${acc1.get_total_transfers()}") # Crashes with ValueError
这段代码存在多个错误导致其运行失败。请找出所有问题,解释每个问题发生的原因,并提供修正后的版本。
评估标准:
-
问题识别(35%):
- 是否发现浮点数/整数转换错误?
- 是否识别出数据类型不一致(浮点数余额 vs 整数解析)?
- 是否发现字符串解析的潜在脆弱性?
- 是否意识到缺少验证/错误处理?
-
根因分析(25%):
- 是否解释了为什么
int(amount_str)在处理 “25.25” 时失败? - 是否理解类型不匹配问题?
- 是否识别出字符串解析假设的缺陷?
- 是否解释了为什么
-
解决方案完整性(25%):
- 是否修复了所有识别出的问题?
- 在保持原有功能的同时是否使其健壮?
- 是否处理了边界情况(格式错误的字符串等)?
-
代码质量与最佳实践(15%):
- 是否一致地使用了合适的数据类型?
- 是否添加了适当的验证/错误处理?
- 是否保持了干净、可读的代码结构?
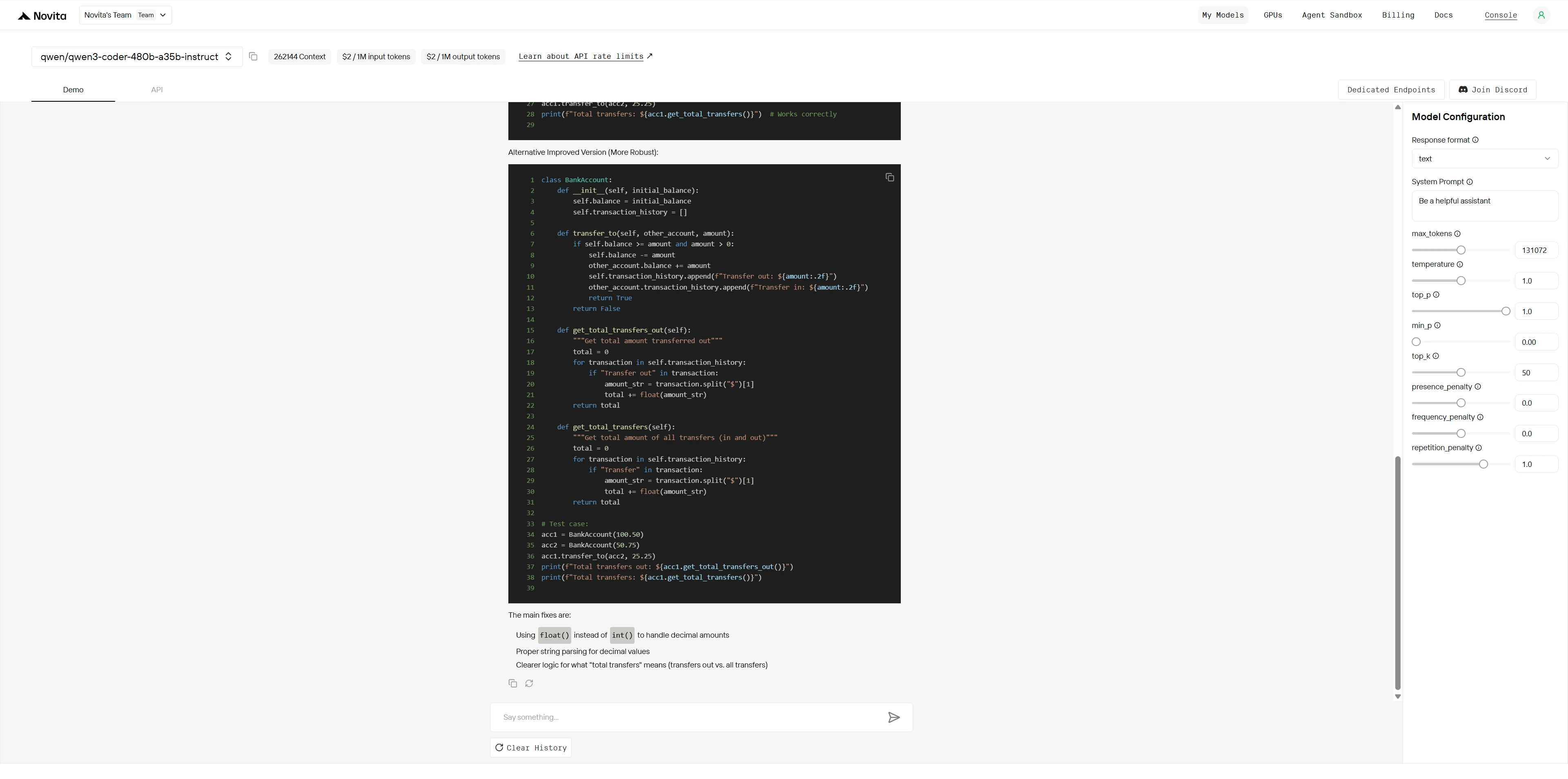
Qwen3-Coder-480B-A35B-Instruct:
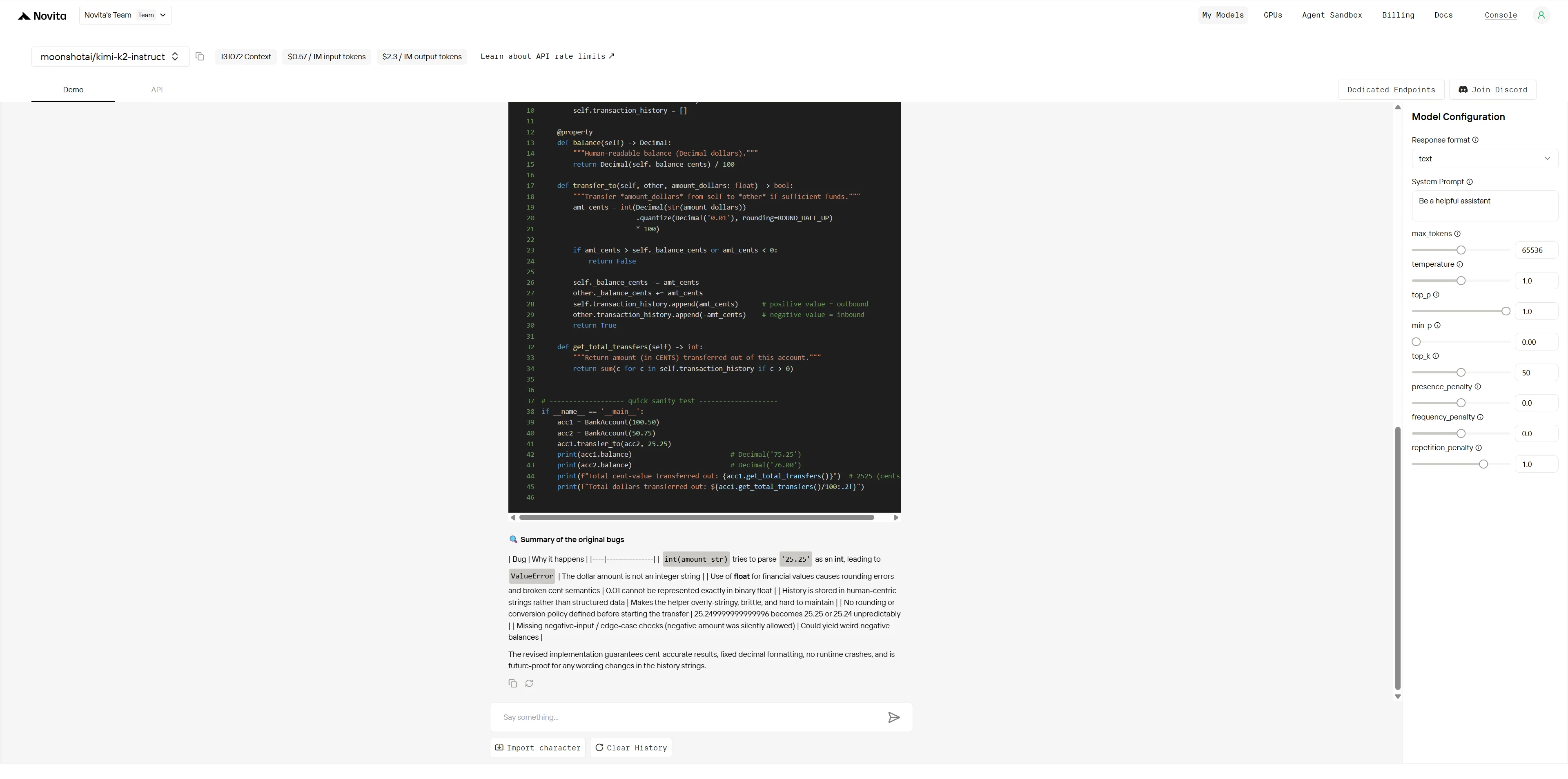
Kimi K2:
总体胜出者:Kimi K2(4.9/5)> Qwen(3.8/5)
| 维度 | Qwen | Kimi K2 | 差距 |
|---|---|---|---|
| 错误识别 | 4/5 | 5/5 | 小 |
| 根因分析 | 4/5 | 5/5 | 小 |
| 解决方案质量 | 4/5 | 5/5 | 小 |
| **领域专长 ** | 3/5 | 5/5 | ** 大** |
| **生产就绪度 ** | 3/5 | 5/5 | ** 大** |
| **架构思维 ** | 3/5 | 5/5 | ** 大** |
立即亲自试用 Kimi K2 和 Qwen 3 Coder!
虽然两个模型都能识别明显的错误,但 Kimi K2 ** 展现了专家级的调试能力**,拥有深厚的领域知识、系统化的问题解决能力和生产级解决方案。Qwen 提供了合格但表面的修复,而 Kimi K2 则交付了专业级的架构改进,能预防未来问题。
优势与劣势
Qwen3-Coder-480B-A35B-Instruct
优势:
- 超长上下文窗口:262K token(是 Kimi 容量的 2 倍)
劣势:
- 实现不一致:有时会产生带有严重逻辑缺陷的代码
- 调试流于表面:关注明显问题,忽略架构性问题
- 领域专长有限:通用的编程方法,缺乏专门知识
Kimi K2
优势:
- 一致的代码质量:可靠、生产就绪的实现,始终在极少监督下生成功能性代码
- 全面的问题解决:能识别边界情况和架构问题
- 出色的成本效益:每百万 token $0.57–$2.30(最高便宜 2 倍)
- 专业工程能力:恰当的错误处理和防御性编程
劣势:
- 较小的上下文窗口:128K token(仅为 Qwen 容量的一半)
如何在 Novita AI 上访问 Qwen3-Coder-480B-A35B-Instruct 和 Kimi K2
步骤 1:登录并访问模型库
登录您的账户,点击 模型库 按钮。
步骤 2:选择您的模型
浏览可用选项,选择适合您需求的模型。
步骤 3:开始免费试用
开始免费试用,探索所选模型的能力。
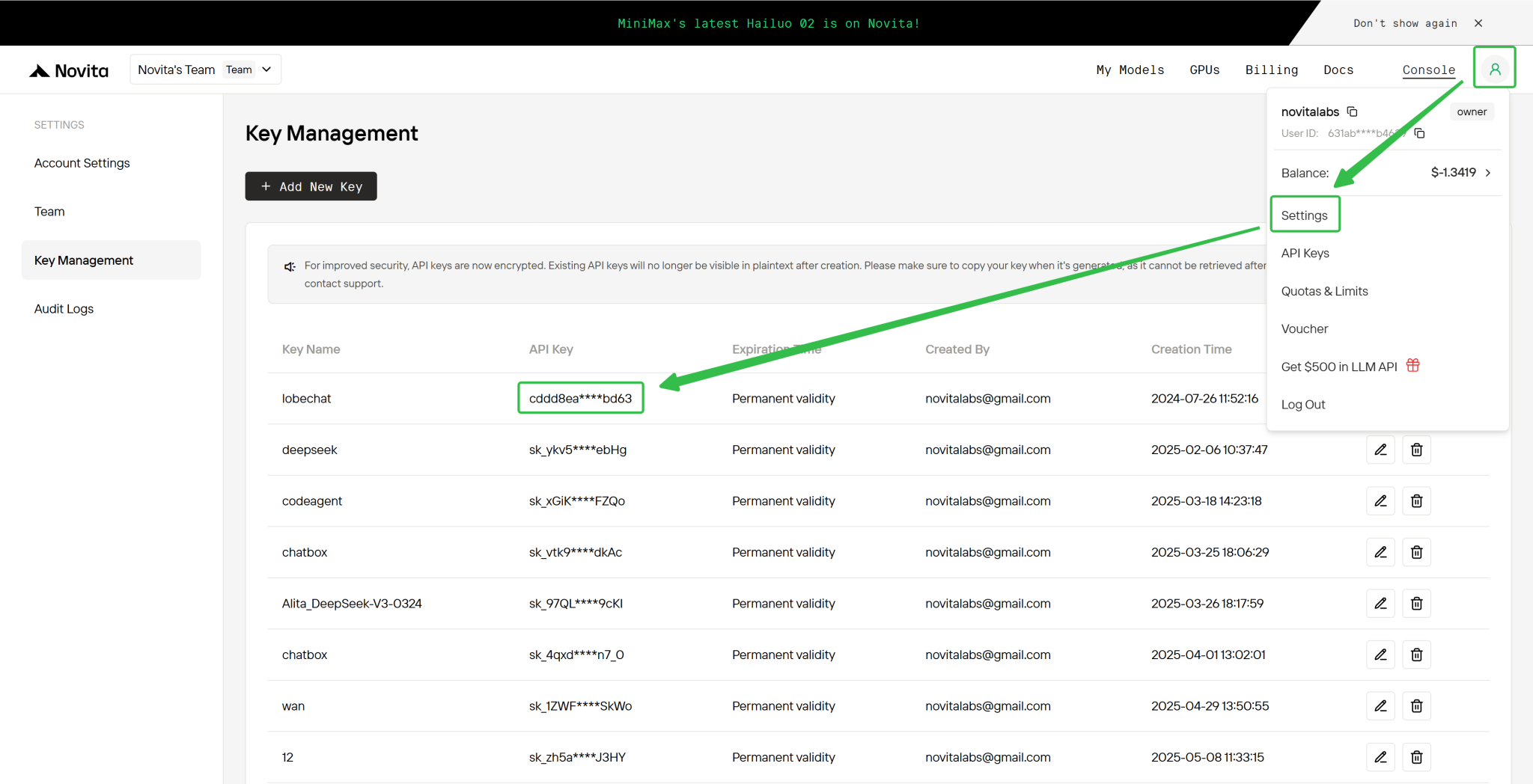
步骤 4:获取您的 API 密钥
为通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入“设置”页面,您可以按图中所示复制 API 密钥。
步骤 5:安装 API
使用您编程语言的专用包管理器安装 API。
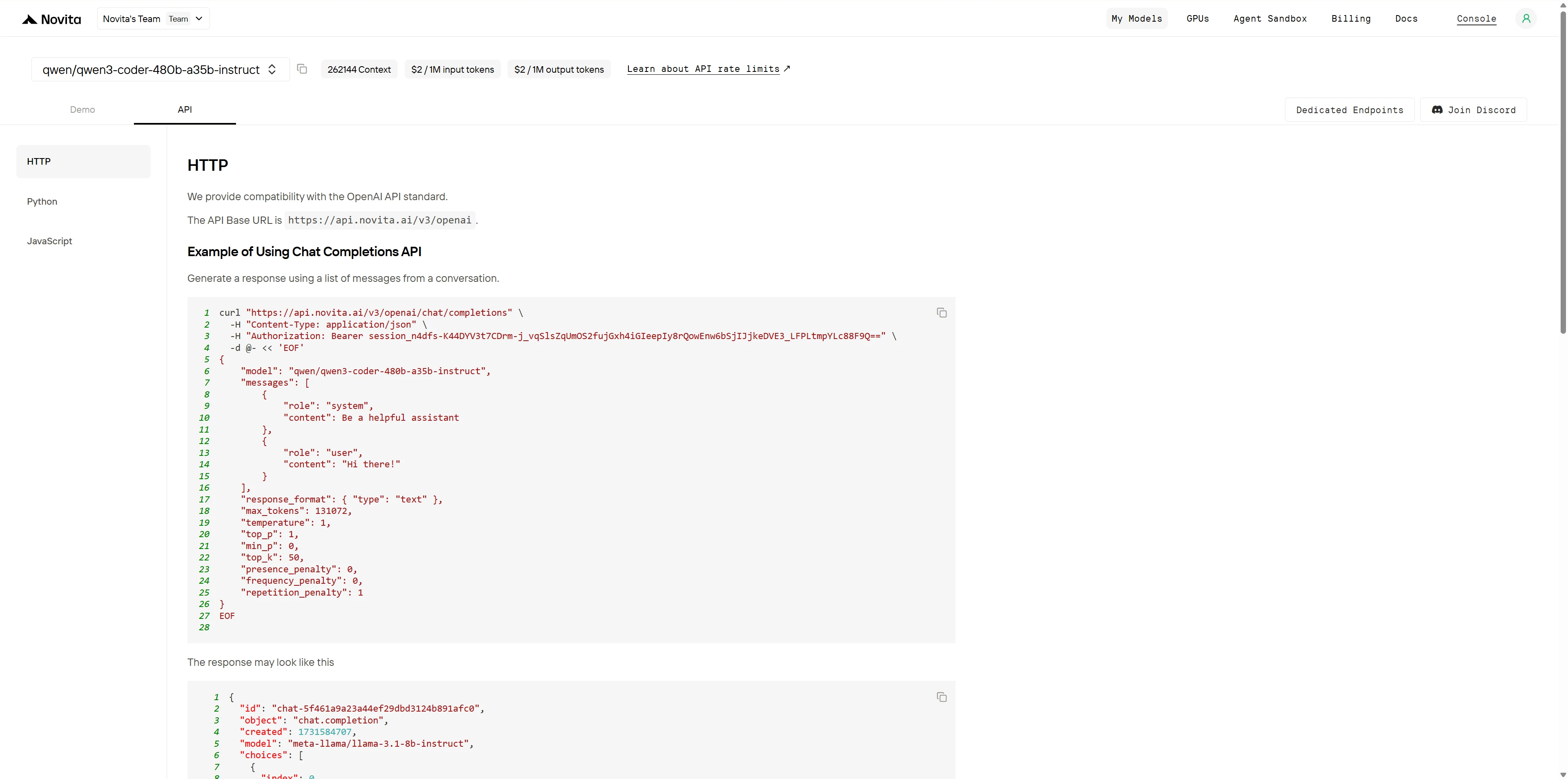
安装后,将必要的库导入您的开发环境。使用您的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是为 Python 用户提供的聊天补全 API 示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_n4dfs-K44DYV3t7CDrm-j_vqSlsZqUmOS2fujGxh4iGIeepIy8rQowEnw6bSjIJjkeDVE3_LFPLtmpYLc88F9Q==",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 131072
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen3-Coder 和 Kimi K2 在 AI 辅助开发的不同维度上各有卓越之处。Qwen3-Coder-480B 在基准测试中表现优异,但 Kimi K2 在指令遵循和实际代码生成方面更胜一筹,能在极少监督下持续生成功能性代码。虽然 Qwen3-Coder-480B 的技术实力在孤立编码任务中熠熠生辉,但 Kimi K2 的可靠性和工作流集成使其更适合协作开发环境和企业级应用。
Qwen3-Coder 和 Kimi K2 都可以通过 Qwen Code 的 OpenAI 兼容 API 无缝集成到您的开发工作流中,将强大的 AI 编程辅助直接带入您的终端环境。 点击了解更多。
您还可以在 Claude Code 中使用 Kimi K2,以获得增强的智能编码能力并显著节省成本。 ** 了解如何使用 Claude Code 设置 Kimi K2。**
常见问题
Qwen3 适合编程吗?
是的,Qwen3-Coder 在编程方面表现出色,拥有顶尖的基准测试性能、用于处理大型代码库的超大 262K 上下文窗口,以及强大的算法问题解决能力。
什么是 Kimi K2?
Kimi K2 是 Moonshot AI 开发的通用 AI 模型,提供可靠的代码生成、强大的领域专长以及具有成本效益的定价(每百万 token $0.57–$2.30)。
Kimi 比 ChatGPT 更好吗?
Kimi K2 以更低的价格和可靠的代码质量提供更好的价值,而 ChatGPT 提供更广泛的通用知识和更流畅的对话能力——选择取决于您的具体用例和预算。
关于 Novita AI
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时还提供经济实惠且可靠的 GPU 云服务。
请注意:以上内容为翻译后的简体中文版本,已按照要求处理所有格式和术语。



