

Puntos clave
Qwen3-Coder-480B-A35B-Instruct: Modelo de codificación especializado con una longitud de contexto de 262K tokens, optimizado para la excelencia algorítmica y el rendimiento en benchmarks de tareas de programación.
Kimi K2: Modelo de propósito general con fiabilidad de nivel empresarial, optimizado para la generación de código listo para producción y flujos de trabajo de desarrollo rentables.
Novita AI no solo proporciona servicios API estables, sino que también ofrece precios extremadamente rentables. Por ejemplo, Qwen3-Coder-480B-A35B-Instruct cuesta $0.95 por 1M de tokens de entrada y $5 por 1M de tokens de salida, mientras que Kimi K2 cuesta $0.57 por 1M de tokens de entrada y $2.3 por 1M de tokens de salida.
Introducción básica de los modelos
Qwen3-Coder-480B-A35B-Instruct
Qwen3-Coder-480B-A35B-Instruct es un modelo de lenguaje causal a gran escala de última generación lanzado por Alibaba en julio de 2025, diseñado principalmente para tareas de codificación agente y desarrollo de software. Emplea una arquitectura de mezcla de expertos (MoE) con 480 mil millones de parámetros totales y 35 mil millones de parámetros activos por paso hacia adelante, logrando un equilibrio entre capacidad del modelo y eficiencia de inferencia. Este modelo admite contextos extremadamente largos de forma nativa con 256K tokens y alcanza un rendimiento de vanguardia entre los modelos abiertos.
Características clave y arquitectura
- Tipo: Modelos de lenguaje causal
- Etapa de entrenamiento: Preentrenamiento y postentrenamiento
- Número de parámetros: 480B en total y 35B activados
- Número de capas: 62
- Número de cabezas de atención (GQA): 96 para Q y 8 para KV
- Número de expertos: 160
- Número de expertos activados: 8
- Longitud de contexto: 262,144 de forma nativa.
Kimi K2
Kimi K2 es un modelo de lenguaje a gran escala innovador desarrollado por Moonshot AI, lanzado en julio de 2025. Presenta una arquitectura innovadora de mezcla de expertos (MoE) con 1 billón de parámetros totales y 32 mil millones de parámetros activados por paso hacia adelante, lo que permite un escalado eficiente y un alto rendimiento. Kimi K2 está meticulosamente optimizado para la inteligencia agente, lo que significa que puede planificar, razonar, usar herramientas y sintetizar código de forma autónoma con capacidades de resolución de problemas en múltiples pasos.
Características clave y arquitectura
- Arquitectura: MoE con 384 expertos, seleccionando 8 por token durante la inferencia para equilibrar eficiencia y capacidad.
- Parámetros: 1 billón en total, 32 mil millones activos a la vez.
- Ventana de contexto: 128K tokens.
- Entrenamiento: Entrenado en 15.5 billones de tokens usando el optimizador propietario MuonClip de Moonshot para mantener la estabilidad del entrenamiento.
- Idiomas: Optimizado principalmente para chino e inglés.
- Espacio en disco: El modelo completo requiere aproximadamente 1.09 TB.
Comparación de benchmarks
1. Benchmarks de inteligencia aplicada

2. Ventana de contexto:
Qwen3-Coder-480B-A35B-Instruct: 262k tokens
Kimi K2: 128k tokens
3. Precios de API:
Qwen3-Coder-480B-A35B-Instruct: $0.95 / $5 entrada/salida por 1M de tokens
Kimi K2: $0.57 / $2.30 entrada/salida por 1M de tokens
Prueba de habilidades aplicadas
1. Capacidad de código: Desafío de diseño de estructura de datos
Objetivo: Evaluar habilidades de implementación y pensamiento algorítmico.
Prompt de ejemplo:
“Implementa una caché LRU (Least Recently Used) con métodos get(key) y put(key, value). La capacidad es fija. Ambas operaciones deben ser O(1). Máximo 25 líneas de código Python.”
Criterios de evaluación:
-
Corrección del algoritmo (40%):
- ¿Expulsa correctamente los elementos menos recientemente usados?
- ¿Ambas operaciones get/put son realmente O(1)?
- ¿Maneja correctamente los límites de capacidad?
-
Elección de estructura de datos (30%):
- ¿Usa la combinación adecuada (dict + lista doblemente enlazada u OrderedDict)?
- ¿Muestra comprensión de los requisitos de complejidad temporal?
-
Calidad del código (20%):
- ¿Implementación limpia y legible?
- ¿Manejo adecuado de casos límite (caché vacía, capacidad 0)?
- ¿Se mantiene dentro del límite de líneas mientras es funcional?
-
Integridad de la implementación (10%):
- ¿Ambos métodos funcionan según lo especificado?
- ¿Incluye métodos/estructuras auxiliares necesarias?
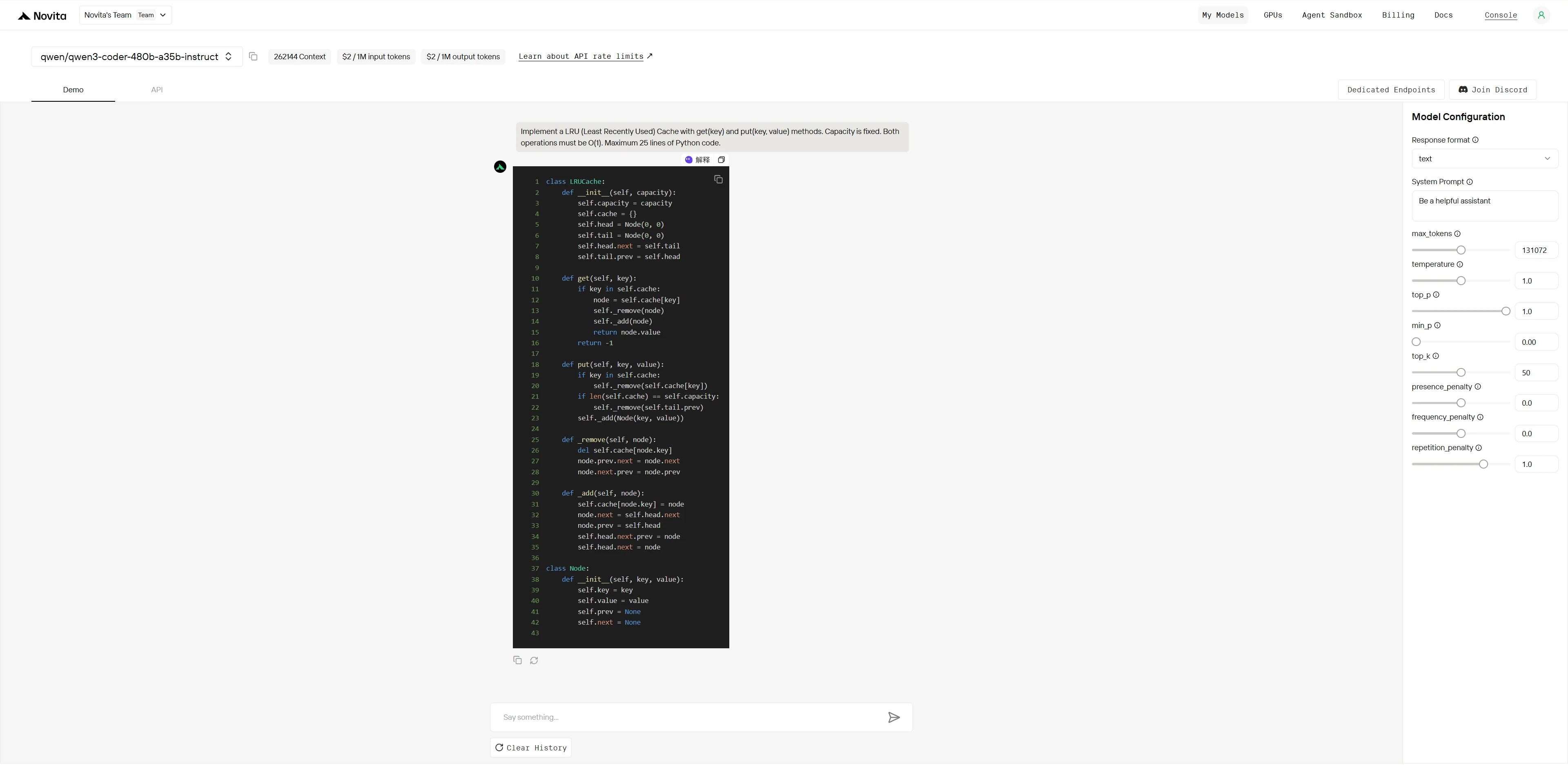
Qwen3-Coder-480B-A35B-Instruct:
Kimi K2:
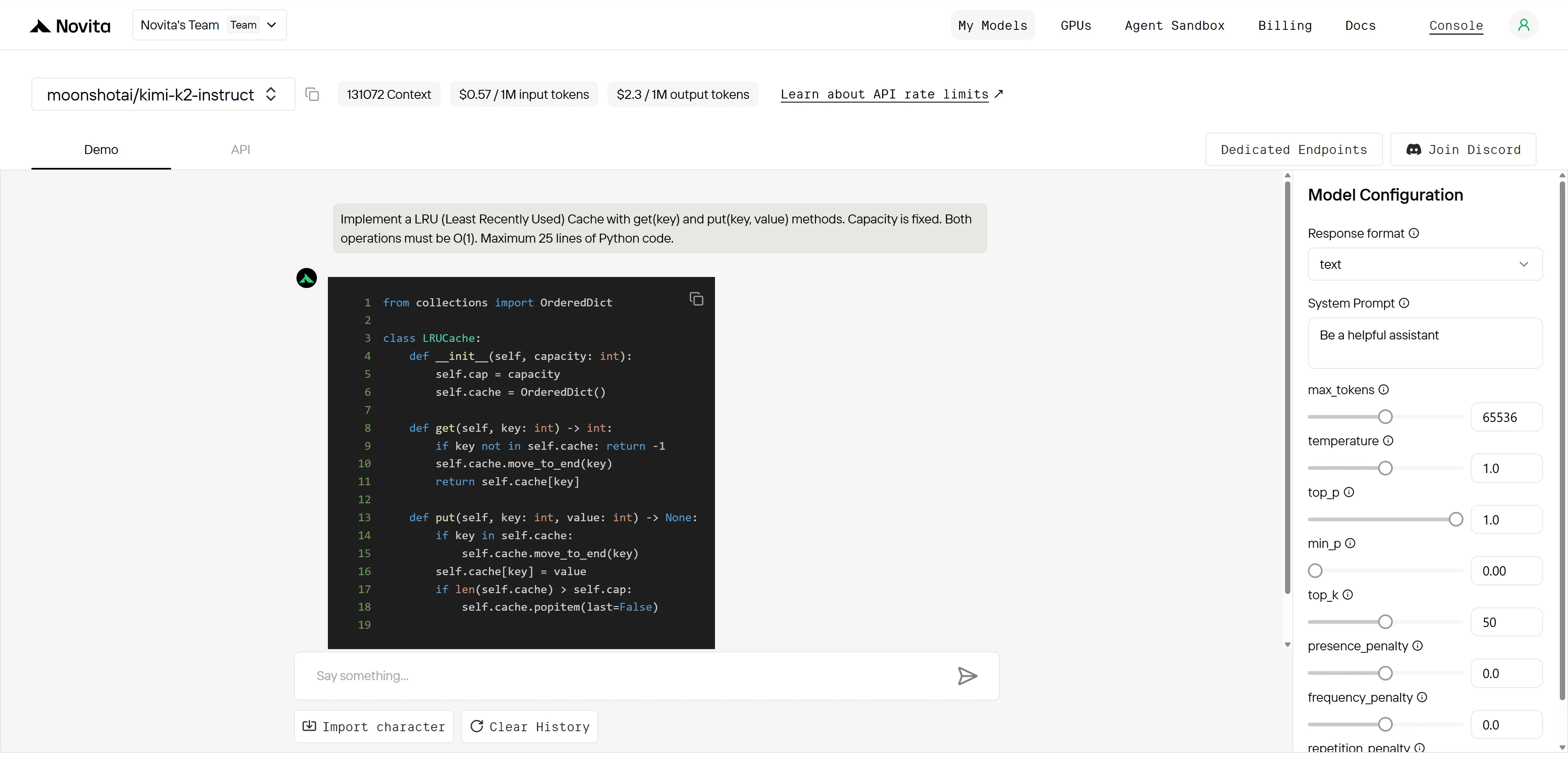
Ganador general: Kimi K2 (4.9/5) > Qwen (4.2/5)
| Dimensión | Qwen | Kimi K2 | Brecha |
|---|---|---|---|
| Conocimiento algorítmico | 5/5 | 5/5 | Ninguna |
| Precisión de implementación | 3/5 | 5/5 | Grande |
| Estructura del código | 4/5 | 5/5 | Pequeña |
| Preparación para producción | 2/5 | 5/5 | Enorme |
¡Prueba Qwen 3 Coder y Kimi K2!
Ambos modelos entienden el algoritmo perfectamente, pero Kimi K2 ejecuta impecablemente mientras que Qwen tiene un error crítico que rompe la funcionalidad principal. Esto muestra la precisión de implementación y el aseguramiento de calidad superiores de Kimi K2.
2. Capacidad de depuración: Análisis de errores multicapa
Objetivo: Probar habilidades sistemáticas de depuración y comprensión de errores.
Prompt de ejemplo:
class BankAccount:
def __init__(self, initial_balance):
self.balance = initial_balance
self.transaction_history = []
def transfer_to(self, other_account, amount):
if self.balance >= amount:
self.balance -= amount
other_account.balance += amount
self.transaction_history.append(f"Transfer out: ${amount}")
other_account.transaction_history.append(f"Transfer in: ${amount}")
return True
return False
def get_total_transfers(self):
total = 0
for transaction in self.transaction_history:
if "Transfer" in transaction:
amount_str = transaction.split("$")[1]
total += int(amount_str)
return total
# Caso de prueba que revela múltiples problemas:
acc1 = BankAccount(100.50)
acc2 = BankAccount(50.75)
acc1.transfer_to(acc2, 25.25)
print(f"Total transfers: ${acc1.get_total_transfers()}") # Fallo con ValueError
Este código tiene múltiples errores que causan su fallo. Identifica TODOS los problemas, explica por qué ocurre cada uno y proporciona la versión corregida.
Criterios de evaluación:
-
Identificación de problemas (35%):
- ¿Encuentra el error de conversión float/int?
- ¿Identifica los tipos de datos inconsistentes (saldos float vs análisis int)?
- ¿Detecta posible fragilidad en el análisis de cadenas?
- ¿Reconoce la falta de validación/manejo de errores?
-
Análisis de causa raíz (25%):
- ¿Explica por qué
int(amount_str)falla en “25.25”? - ¿Comprende el problema de incompatibilidad de tipos?
- ¿Identifica la falla en la suposición de análisis de cadenas?
- ¿Explica por qué
-
Completitud de la solución (25%):
- ¿Corrige todos los problemas identificados?
- ¿Mantiene la funcionalidad original mientras la hace robusta?
- ¿Maneja casos límite (cadenas malformadas, etc.)?
-
Calidad del código y mejores prácticas (15%):
- ¿Usa tipos de datos apropiados de manera consistente?
- ¿Agrega validación/manejo de errores adecuado?
- ¿Mantiene una estructura de código limpia y legible?
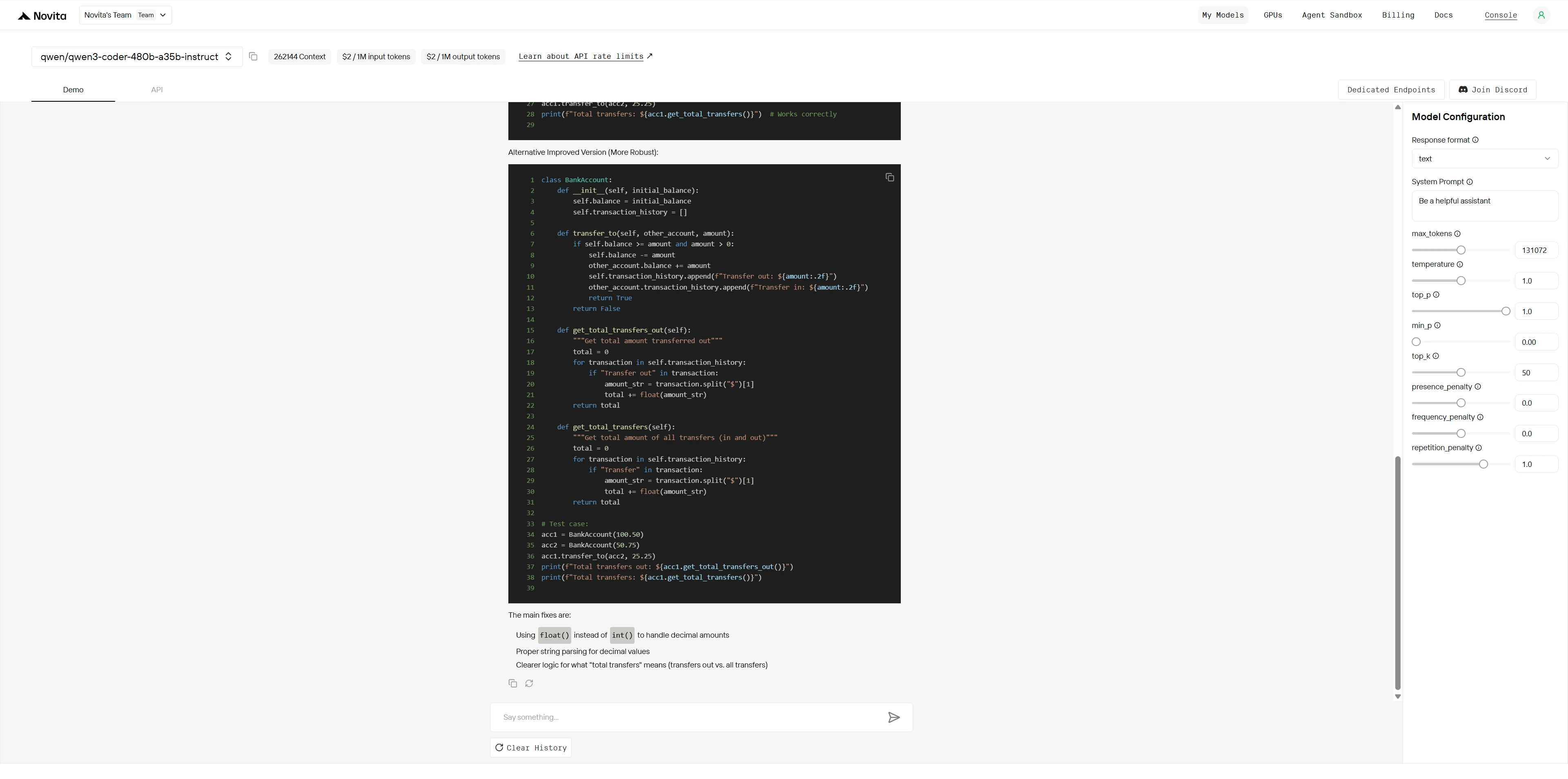
Qwen3-Coder-480B-A35B-Instruct:
Kimi K2:
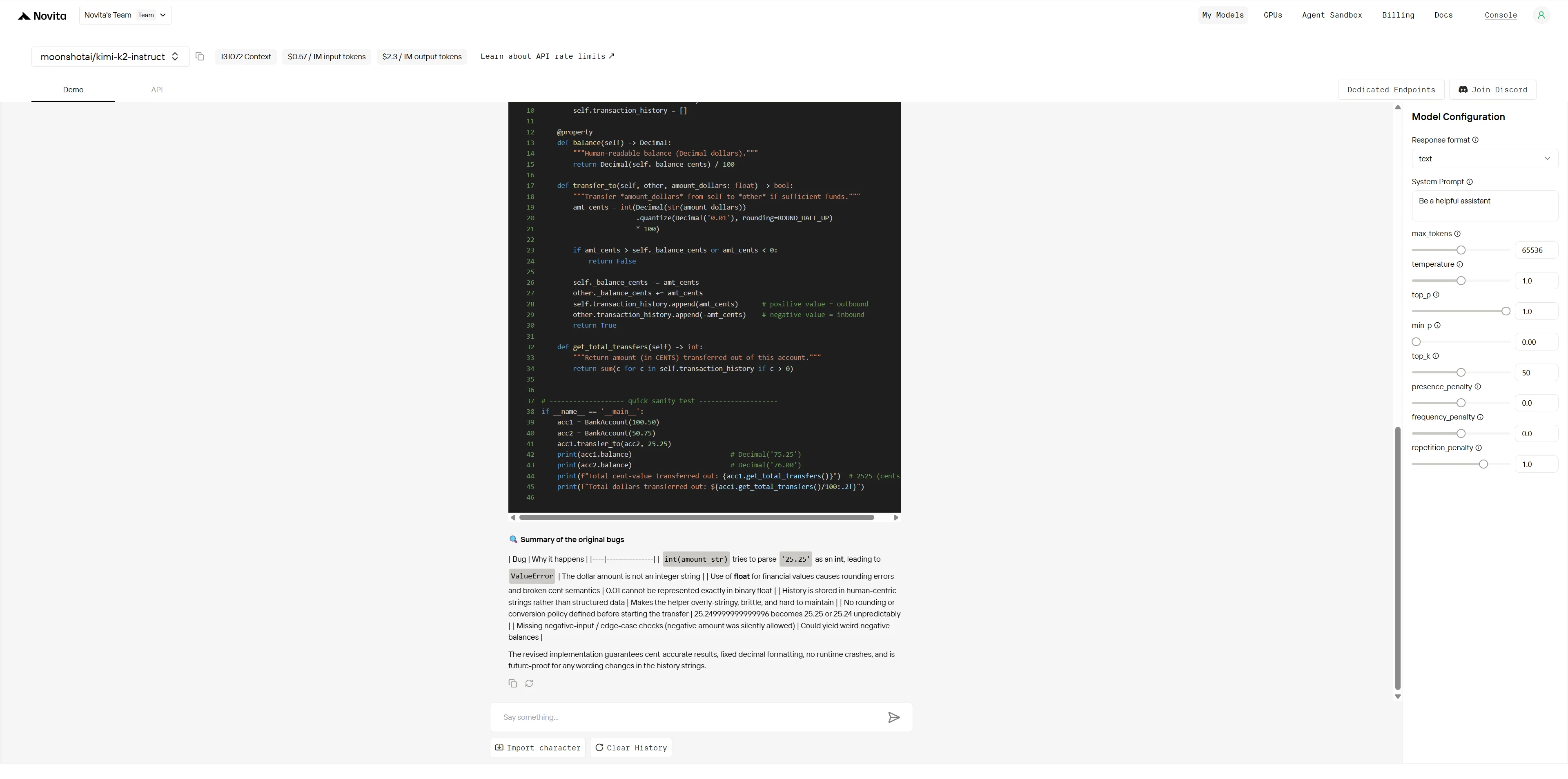
Ganador general: Kimi K2 (4.9/5) > Qwen (3.8/5)
| Dimensión | Qwen | Kimi K2 | Brecha |
|---|---|---|---|
| Identificación de errores | 4/5 | 5/5 | Pequeña |
| Análisis de causa raíz | 4/5 | 5/5 | Pequeña |
| Calidad de la solución | 4/5 | 5/5 | Pequeña |
| Experiencia en el dominio | 3/5 | 5/5 | Grande |
| Preparación para producción | 3/5 | 5/5 | Grande |
| Pensamiento arquitectónico | 3/5 | 5/5 | Grande |
¡Prueba Kimi K2 y Qwen 3 Coder tú mismo!
Mientras que ambos modelos pueden identificar errores obvios, Kimi K2 demuestra una depuración a nivel experto con profundo conocimiento del dominio, resolución sistemática de problemas y soluciones de grado de producción. Qwen proporciona correcciones competentes pero superficiales, mientras que Kimi K2 ofrece mejoras arquitectónicas de nivel profesional que previenen problemas futuros.
Fortalezas y debilidades
Qwen3-Coder-480B-A35B-Instruct
Fortalezas:
- Ventana de contexto masiva: 262K tokens (2x la capacidad de Kimi)
Debilidades:
- Inconsistencia en la implementación: A veces produce código con fallos lógicos críticos
- Depuración superficial: Se enfoca en problemas obvios, pasa por alto problemas arquitectónicos
- Experiencia de dominio limitada: Enfoque de programación genérica sin conocimiento especializado
Kimi K2
Fortalezas:
- Calidad de código consistente: Implementaciones confiables y listas para producción, produce código funcional de manera consistente con poca supervisión
- Resolución integral de problemas: Identifica casos límite y problemas arquitectónicos
- Eficiencia de costos superior: $0.57-2.30 por 1M de tokens (hasta 2x más barato)
- Ingeniería profesional: Manejo adecuado de errores y programación defensiva
Debilidades:
- Ventana de contexto más pequeña: 128K tokens (la mitad de la capacidad de Qwen)
Cómo acceder a Qwen3-Coder-480B-A35B-Instruct y Kimi K2 en Novita AI
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.
¡Prueba Kimi K2 y Qwen 3 Coder ahora!
Paso 2: Elige tu modelo
Navega entre las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página de Configuración, puedes copiar la clave API como se indica en la imagen.
Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
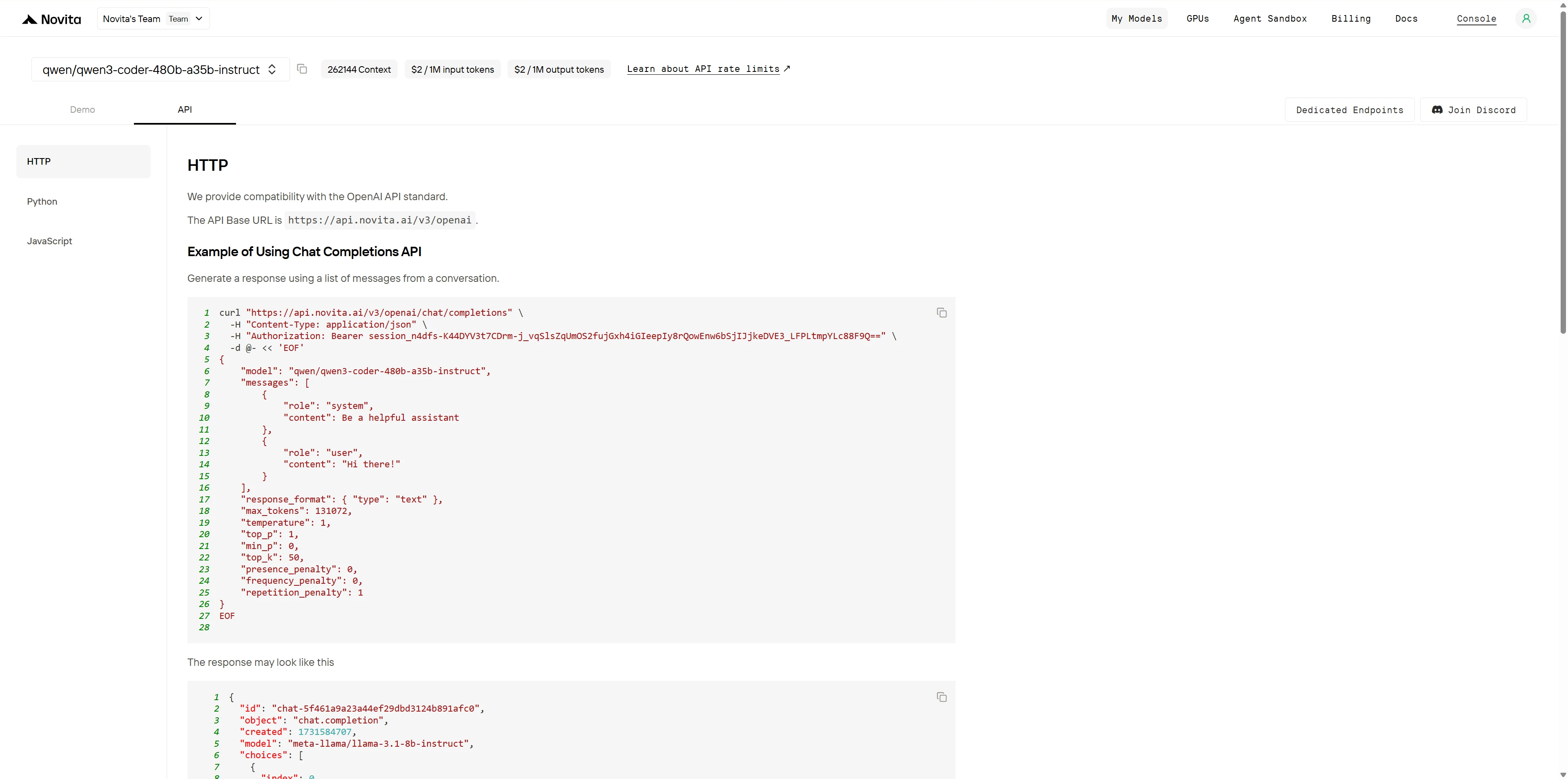
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de finalización de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_n4dfs-K44DYV3t7CDrm-j_vqSlsZqUmOS2fujGxh4iGIeepIy8rQowEnw6bSjIJjkeDVE3_LFPLtmpYLc88F9Q==",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 131072
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Tanto Qwen3-Coder como Kimi K2 sobresalen en diferentes dimensiones del desarrollo asistido por IA. Qwen3-Coder-480B destaca en el rendimiento de benchmarks, sin embargo, Kimi K2 muestra una adherencia superior a las instrucciones y una generación de código práctica, produciendo código funcional de manera consistente con una supervisión mínima. Mientras que la destreza técnica de Qwen3-Coder-480B brilla en tareas de codificación aisladas, la fiabilidad e integración en flujos de trabajo de Kimi K2 lo hacen más adecuado para entornos de desarrollo colaborativo y aplicaciones de nivel empresarial.
Tanto Qwen3-Coder como Kimi K2 pueden integrarse sin problemas en tu flujo de trabajo de desarrollo a través de la API compatible con OpenAI de Qwen Code, llevando una potente asistencia de codificación IA directamente a tu entorno de terminal. Haz clic para ver más.
También puedes usar Kimi K2 en Claude Code para capacidades mejoradas de codificación agente con importantes ahorros de costos. Aprende cómo configurar Kimi K2 con Claude Code.
Preguntas frecuentes
¿Es Qwen3 bueno para codificar?
Sí, Qwen3-Coder sobresale en codificación con el mejor rendimiento en benchmarks, una ventana de contexto masiva de 262K para manejar grandes bases de código y sólidas capacidades de resolución de problemas algorítmicos.
¿Qué es Kimi K2?
Kimi K2 es un modelo de IA de propósito general desarrollado por Moonshot AI que ofrece generación de código confiable, sólida experiencia en el dominio y precios rentables a $0.57-2.30 por 1M de tokens.
¿Es Kimi mejor que ChatGPT?
Kimi K2 ofrece mejor valor con precios más bajos y calidad de código confiable, mientras que ChatGPT proporciona un conocimiento general más amplio y habilidades conversacionales más pulidas; la elección depende de tu caso de uso específico y presupuesto.
Acerca de Novita AI
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona la GPU en la nube asequible y confiable para construir y escalar.



