

- Что вы на самом деле сравниваете: флагманские рассуждения против масштабируемой эффективности
- Сравнение бенчмарков
- Сравнение скорости и задержки
- Сравнение цен
- Когда использовать какую модель
- Быстрый старт: попробуйте обе модели мгновенно в Novita Playground
- Варианты развертывания: API, SDK, интеграции с сторонними платформами и локальное развертывание
- Заключение
Если вы сравниваете GLM-4.7 и GLM-4.7-Flash как взаимозаменяемые модели, вы оптимизируете не то, что нужно.
Эти две модели по своей сути относятся к разным уровням:
- GLM-4.7 — это флагманская модель для рассуждений: её выбирают, когда важна максимальное качество, и вы готовы оправдать более высокую стоимость за токен.
- GLM-4.7-Flash — это более лёгкая, экономичная «рабочая лошадка»: её выбирают, когда на масштабе важны пропускная способность, экономика на единицу запроса и практичность работы с длинным контекстом.
На платформе Novita вы можете запускать обе модели с прозрачной тарификацией, через API и удобный Playground, чтобы быстро принять решение.
Что вы на самом деле сравниваете: флагманские рассуждения против масштабируемой эффективности
GLM-4.7: флагманская модель для рассуждений
GLM-4.7 позиционируется как ведущая модель с приоритетом рассуждений (высокий общий интеллект), с поддержкой длинного контекста и быстрой генерацией — но она также значительно дороже за токен, чем Flash.
GLM-4.7-Flash: масштабируемая MoE-модель «рабочая лошадка для агентов и кодирования»
GLM-4.7-Flash создана с упором на эффективность (класс MoE 30B-A3B), предназначена для агентного кодирования, рабочих процессов с инструментами и задач с длинным контекстом, где нужны высокая пропускная способность и предсказуемая стоимость.
Сравнение бенчмарков
Индексы интеллекта / кодирования / агентных возможностей от Artificial Analysis
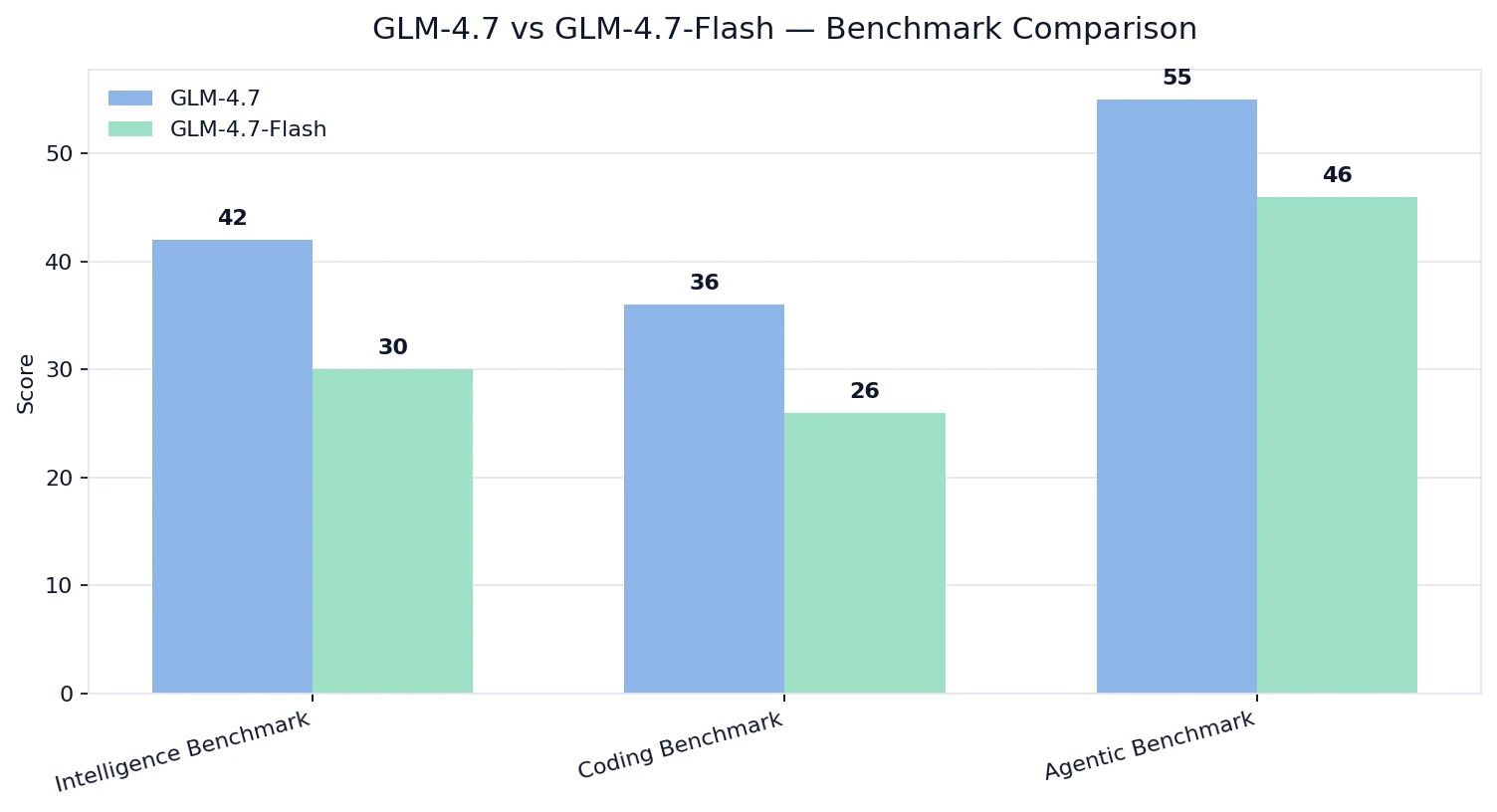
Данные предоставлены Artificial Analysis
💡Интерпретация:
- GLM-4.7 превосходит по качеству в показателях интеллекта, кодирования и агентных возможностей.
- GLM-4.7-Flash также показывает высокие результаты, но он настроен на другую цель оптимизации: стоимость + возможность развертывания + практическая пропускная способность.
Эффективность высшего класса: GLM-4.7-Flash против аналогов сопоставимого размера
Однако легко упустить из виду, что GLM-4.7-Flash является одним из лидеров в своём классе эффективности (примерно MoE-модели на 20–30B параметров / лёгкие модели). В сравнениях с аналогами по шести реальным оценкам, охватывающим кодирование, использование агентов/инструментов, задачи в стиле браузера, математику и рассуждения на основе знаний, Flash стабильно занимает первое или близкое к нему место среди альтернатив сопоставимого размера — именно поэтому он является оптимальным выбором по умолчанию для высоконагруженных производственных систем.
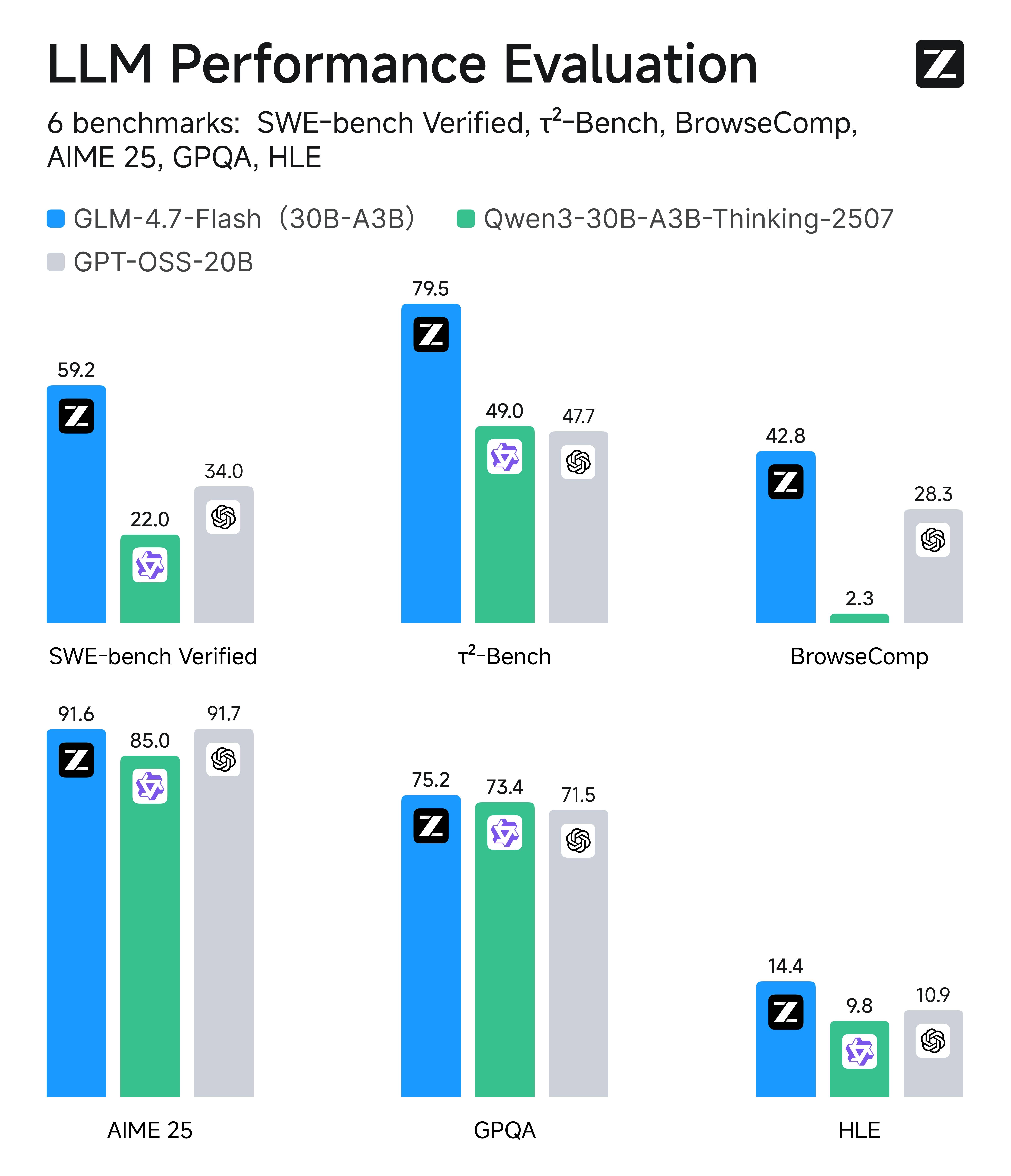
Сравнение скорости и задержки
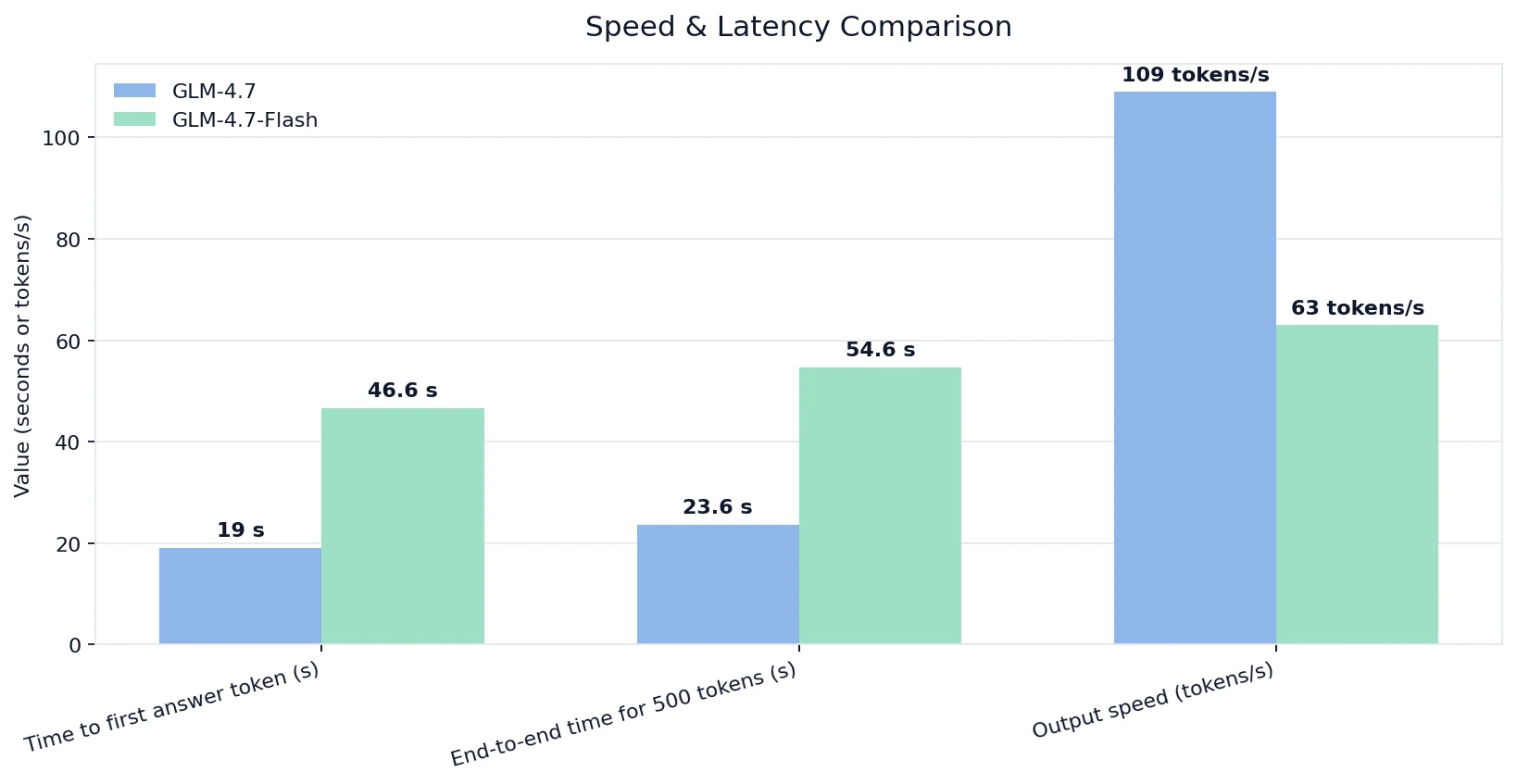
Данные предоставлены Artificial Analysis
Сравнение цен
По данным тарифов Novita:
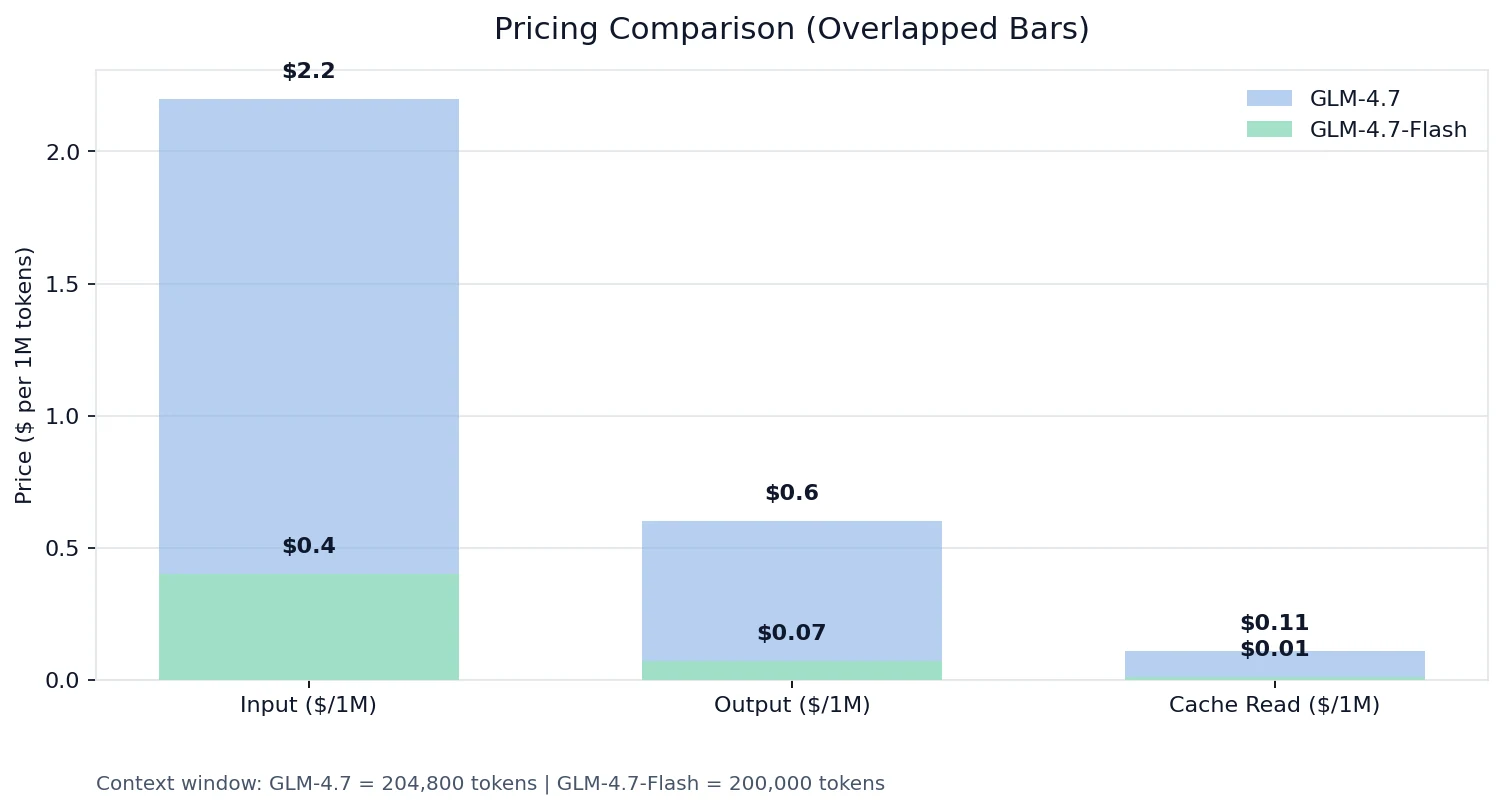
Реальность: модели относятся к разным уровням
- Входные токены: GLM-4.7 стоит примерно в 8,6 раза дороже, чем Flash
- Выходные токены: GLM-4.7 стоит в 5,5 раза дороже, чем Flash
- Чтение из кэша: GLM-4.7 стоит в 11 раз дороже, чем Flash
Если вы создаёте продукт с большим объёмом запросов, длинным контекстом или повторяющимися схемами инструментов, экономика Flash + тарифы на чтение из кэша могут кардинально изменить вашу кривую затрат.
Когда использовать какую модель
GLM-4.7 и GLM-4.7-Flash относятся к разным уровням — они созданы для разных целей: GLM-4.7 = максимальное качество и возможности рассуждений, Flash = масштабируемая пропускная способность и экономика на единицу запроса.
Выбирайте GLM-4.7, когда качество является приоритетом продукта
Используйте его для:
- Глубокие рассуждения / сложные задачи: многошаговая логика, математика, сложное планирование, документы по архитектуре и дизайну
- Генерация с приоритетом качества: длинные тексты, премиум-копирайтинг, перевод с учётом тональности
- Поддержка принятия важных решений: юридические, медицинские, финансовые, инженерные решения (всё равно требуют проверки человеком)
Хороший признак: если ошибки стоят дорого, или вы готовы платить больше, чем перезапускать/исправлять результаты, выбирайте GLM-4.7.
Выбирайте GLM-4.7-Flash, когда масштаб является приоритетом продукта
Используйте его для:
- Повседневные задачи: чат, простые ответы на вопросы, переписывание текста, форматирование, тегирование/классификация, извлечение информации
- Высоконагруженные рабочие процессы: боты поддержки клиентов,实时 чат, пакетная обработка, частые вызовы API
- Среды с ограниченным бюджетом: MVP, продукты с большим числом пользователей, CI/тестирование, окружения для разработки и тестирования
Хороший признак: если для вас важны стоимость на запрос, пропускная способность и «достаточно хорошее» качество при больших объёмах, выбирайте Flash.
| Параметр | Использовать GLM-4.7 | Использовать GLM-4.7-Flash |
| Сложность задач | Высокая | Низкая до средней |
| Допустимая погрешность | Строгая | Допустимы отдельные ошибки |
| Бюджет | Нет ограничений | Ключевой приоритет — контроль затрат |
| Количество одновременных запросов | Низкое до среднего | Высокое |
Быстрый старт: попробуйте обе модели мгновенно в Novita Playground
Самый быстрый способ почувствовать разницу между GLM-4.7 и GLM-4.7-Flash — это Novita AI Playground: не нужно писать код, не требуется настройка.
В Playground вы можете:
- Мгновенно переключаться между моделями
zai-org/glm-4.7иzai-org/glm-4.7-flash - Запускать один и тот же запрос, чтобы сравнить качество, стиль рассуждений и скорость ответа
- Проверять формат вашего запроса (JSON, вывод в стиле инструментов) перед переходом к API
Рекомендуемые тестовые запросы
- Запрос с упором на рассуждения (чтобы увидеть максимальные возможности GLM-4.7)
- Высоконагруженный операционный запрос (суммаризация / извлечение информации), чтобы оценить практичность и экономическую эффективность Flash
Novita AI Playground
Варианты развертывания: API, SDK, интеграции с сторонними платформами и локальное развертывание
Вариант А: API
Получите API-ключ
-
Шаг 1: Создайте аккаунт или войдите в существующий Перейдите на
[**https://novita.ai**](https://novita.ai)и зарегистрируйтесь или войдите в уже существующий аккаунт -
Шаг 2: Перейдите в раздел управления ключами После входа в аккаунт найдите раздел «API Keys»

- Шаг 3: Создайте новый ключ Нажмите кнопку «Add New Key».

- Шаг 4: Немедленно сохраните ваш ключ Скопируйте и сохраните ключ сразу после генерации: обычно он отображается только один раз и не может быть восстановлен позже. Храните ключ в безопасном месте, например в менеджере паролей или зашифрованных заметках
Совместимый с OpenAI API (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # or "zai-org/glm-4.7"
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
Вариант Б: SDK
Если вы создаёте агентные рабочие процессы (маршрутизация, передача управления, вызовы инструментов/функций), Novita поддерживает SDK, совместимые с OpenAI, с минимальными изменениями:
- Готовая совместимость: сохраните существующую логику клиента; достаточно изменить только base_url и model
- Готово к оркестрации: легко реализовать маршрутизацию (по умолчанию Flash → эскалация до GLM-4.7)
- Настройка: укажите адрес
https://api.novita.ai/openai, задайте переменнуюNOVITA_API_KEY, выберитеzai-org/glm-4.7/zai-org/glm-4.7-flash
Вариант В: Сторонние платформы
Вы также можете запускать модели GLM, размещённые на Novita, через популярные экосистемы:
- Фреймворки для агентов и конструкторы приложений: Следуйте пошаговым руководствам по интеграции от Novita, чтобы подключиться к популярным инструментам, таким как Continue, AnythingLLM, LangChain и Langflow.
- Hugging Face Hub: Novita указана как провайдер инференса на Hugging Face, поэтому вы можете запускать поддерживаемые модели через рабочий процесс и экосистему провайдера Hugging Face.
- Совместимый с OpenAI API: Эндпоинты LLM от Novita совместимы со стандартом API OpenAI, что упрощает миграцию существующих приложений, работающих с OpenAI, и подключение множества инструментов, совместимых с OpenAI ( Cline, Cursor, Trae и Qwen Code).
- Совместимый с Anthropic API: Novita также предоставляет доступ, совместимый с SDK Anthropic, поэтому вы можете интегрировать модели на базе Novita в агентные рабочие процессы кодирования в стиле Claude Code.
- OpenCode: Novita AI теперь напрямую интегрирована в OpenCode как поддерживаемый провайдер, поэтому пользователи могут выбрать Novita в OpenCode без ручной настройки.
Вариант Г: Локальное и частное развертывание
GLM-4.7-Flash обычно является более практичным выбором для локального/частного развертывания, так как он легче и проще запускать на on-prem кластерах, в VPC / частных облаках и гибридных средах. Он особенно хорошо подходит для задач, связанных с соответствием нормам / требованием к размещению данных, внутренних приложений с чувствительными к задержкам требованиями и нагрузок с длинным контекстом / агентных рабочих процессов при фиксированном бюджете на GPU.
Распространённая конфигурация:
- Запускайте Flash локально для высоконагруженного трафика
- Эскалируйте до GLM-4.7 (размещённого на Novita) для сложных или критически важных запросов
GLM-4.7 также можно развернуть локально, но обычно он зарезервирован для команд с высокой производительностью GPU и зрелостью операционных процессов, в основном для внутренних систем с критически важным качеством и низкой пропускной способностью. Для широкого внутреннего использования Flash остаётся выбором по умолчанию.
💡Даже если запуск GLM-4.7 на локальных мощностях слишком дорог, вы всё равно можете использовать его в production через хостинговый API Novita, или запустить его на GPU-инфраструктуре Novita, чтобы избежать первоначальных затрат на оборудование и операционные расходы.
Заключение
Сравнение GLM-4.7 и GLM-4.7-Flash — это нечестное состязание «какая модель лучше», потому что они созданы для разных задач. Используйте GLM-4.7, когда вам нужен максимальный потенциал в рассуждениях, кодировании и надёжности агентных сценариев. Используйте GLM-4.7-Flash, когда вам нужна мощная модель, которую можно реально масштабировать — экономичная, простая в развертывании и высококонкурентная в своём классе эффективности.
Лучший паттерн для production обычно гибридный: используйте Flash по умолчанию для большого объёма запросов, и направляйте сложные или критически важные запросы на GLM-4.7. С Playground от Novita и совместимыми с OpenAI API вы можете протестировать обе модели за несколько минут и внедрить стратегию маршрутизации без изменения вашего стека.
Novita AI — это облачная ИИ-платформа, которая предлагает разработчикам простой способ развертывать ИИ-модели через наш удобный API, а также предоставляет доступное и надёжное облако GPU для разработки и масштабирования решений.
Часто задаваемые вопросы
Что такое GLM-4.7-Flash?
GLM-4.7-Flash — это большая языковая модель класса 30B с архитектурой Mixture-of-Experts (MoE), разработанная компанией Zhipu AI. Она создана для обеспечения высокой производительности в рассуждениях, кодировании и агентных сценариях с высокой эффективностью и низкой задержкой.
Сколько стоит GLM-4.7-Flash?
На Novita AI (бессерверный режим) тарифы на GLM-4.7-Flash составляют $0.07 за миллион входных токенов, $0.01 за миллион токенов чтения из кэша и $0.40 за миллион выходных токенов, что делает её экономически выгодной для нагрузок с длинным контекстом и высокой пропускной способностью.
Какова связь между GLM-4.7-Flash и GLM-4.7?
GLM-4.7-Flash и GLM-4.7 относятся к одному семейству моделей, но ориентированы на разные сегменты: GLM-4.7 является флагманской моделью, оптимизированной для максимального качества рассуждений, а GLM-4.7-Flash — это более лёгкая, экономичная версия, предназначенная для масштабируемого развертывания при больших объёмах запросов.



