

- Lo que realmente estás comparando: Razonamiento Insignia vs Eficiencia Escalable
- Comparativa de Benchmarks
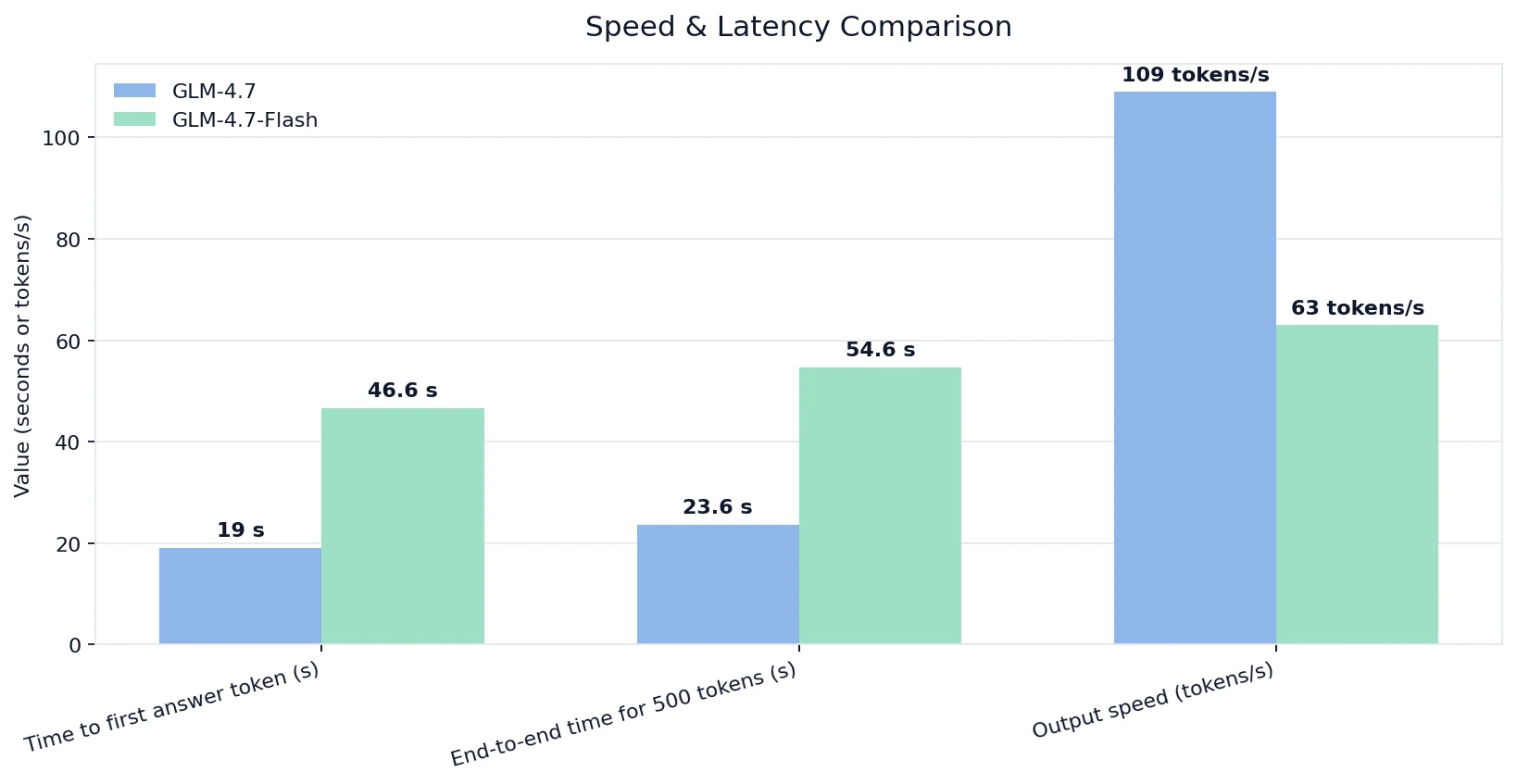
- Comparativa de Velocidad y Latencia
- Comparativa de Precios
- Cuándo Usar Cada Modelo
- Inicio Rápido: Prueba Ambos Modelos al Instante en Novita Playground
- Opciones de Despliegue: API, SDK, Integraciones de Terceros y Despliegue Local
- Conclusión
Si estás comparando GLM-4.7 y GLM-4.7-Flash como si fueran intercambiables, terminarás optimizando lo incorrecto.
Estos dos modelos no están en el mismo nivel por diseño:
- GLM-4.7 es un modelo de razonamiento insignia: lo eliges cuando te importa la máxima calidad y puedes justificar un mayor costo por token.
- GLM-4.7-Flash es un “caballo de batalla” más ligero y eficiente en costos: lo eliges cuando te importa el rendimiento, la economía unitaria y la practicidad de contexto largo a escala.
En Novita, puedes ejecutar ambos con precios transparentes, APIs y un Playground fácil para decidir rápidamente.
Lo que realmente estás comparando: Razonamiento Insignia vs Eficiencia Escalable
GLM-4.7: el modelo de razonamiento insignia
GLM-4.7 está posicionado como un modelo líder primero en razonamiento (inteligencia general sólida), con contexto largo y generación rápida, pero también es mucho más caro por token que Flash.
GLM-4.7-Flash: el “caballo de batalla” MoE escalable para agentes/código
GLM-4.7-Flash está construido en torno a la eficiencia (clase 30B-A3B MoE), orientado a flujos de trabajo de codificación agentiva, uso de herramientas y tareas de contexto largo donde necesitas alto rendimiento y costo predecible.
Comparativa de Benchmarks
Índices de Inteligencia / Codificación / Agentividad - Artificial Analysis
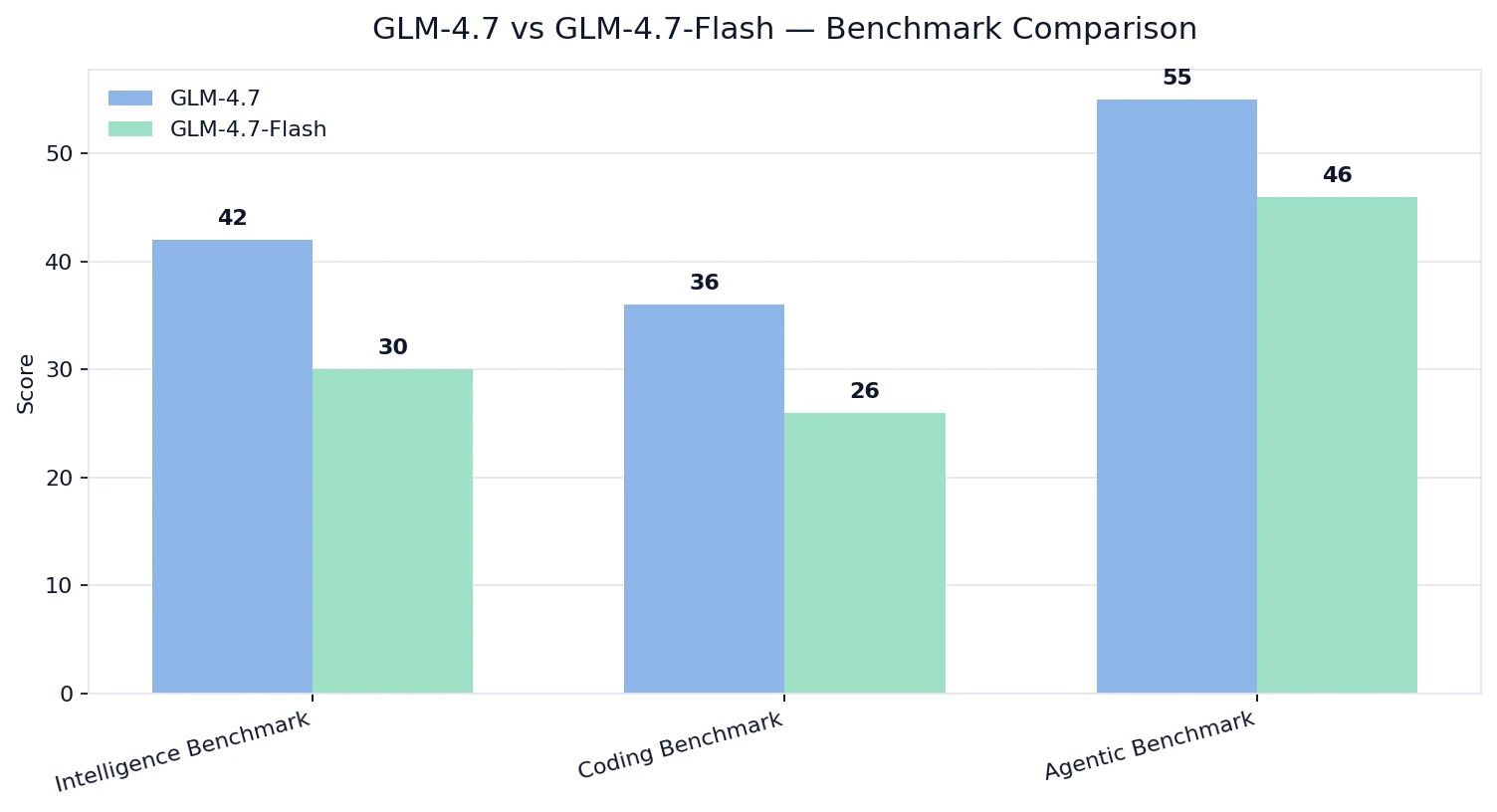
💡Interpretación:
- GLM-4.7 gana en calidad en inteligencia/codificación/capacidad agentiva.
- GLM-4.7-Flash sigue siendo sólido, pero está ajustado para un objetivo de optimización diferente: costo + facilidad de despliegue + rendimiento práctico.
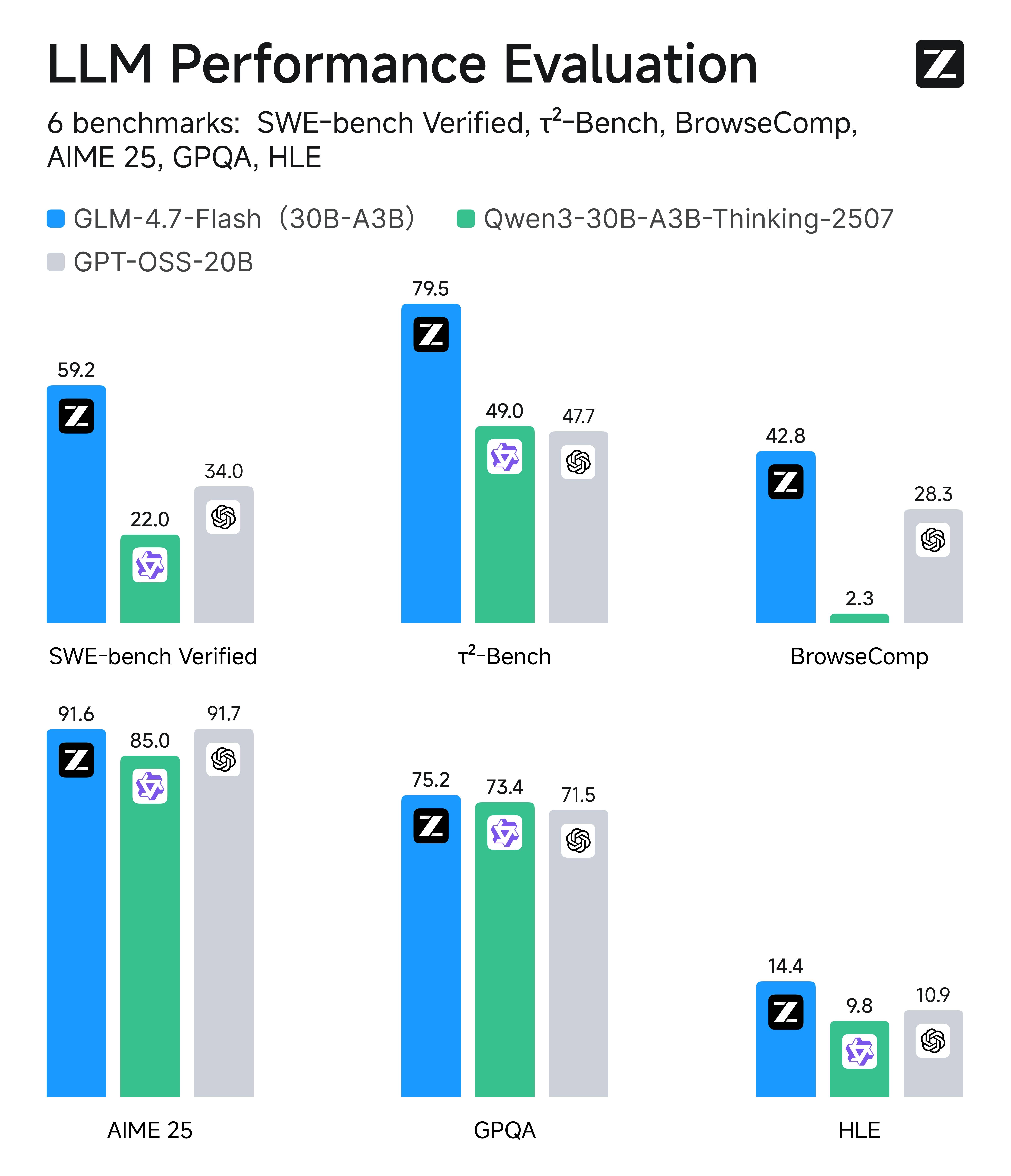
Eficiencia de Primera Clase: GLM-4.7-Flash vs Pares de Tamaño Similar
Sin embargo, lo que es fácil pasar por alto es que GLM-4.7-Flash es uno de los mejores dentro de su propia clase de eficiencia (aproximadamente modelos MoE ligeros de 20B–30B). En comparaciones con pares en seis evaluaciones del mundo real (que abarcan codificación, uso de agentes/herramientas, tareas tipo navegación web, matemáticas y razonamiento de conocimiento), Flash se clasifica consistentemente en o cerca del top entre alternativas de tamaño similar, que es exactamente por qué tiene sentido como opción predeterminada para sistemas de producción de alto volumen.
Comparativa de Velocidad y Latencia
Comparativa de Precios
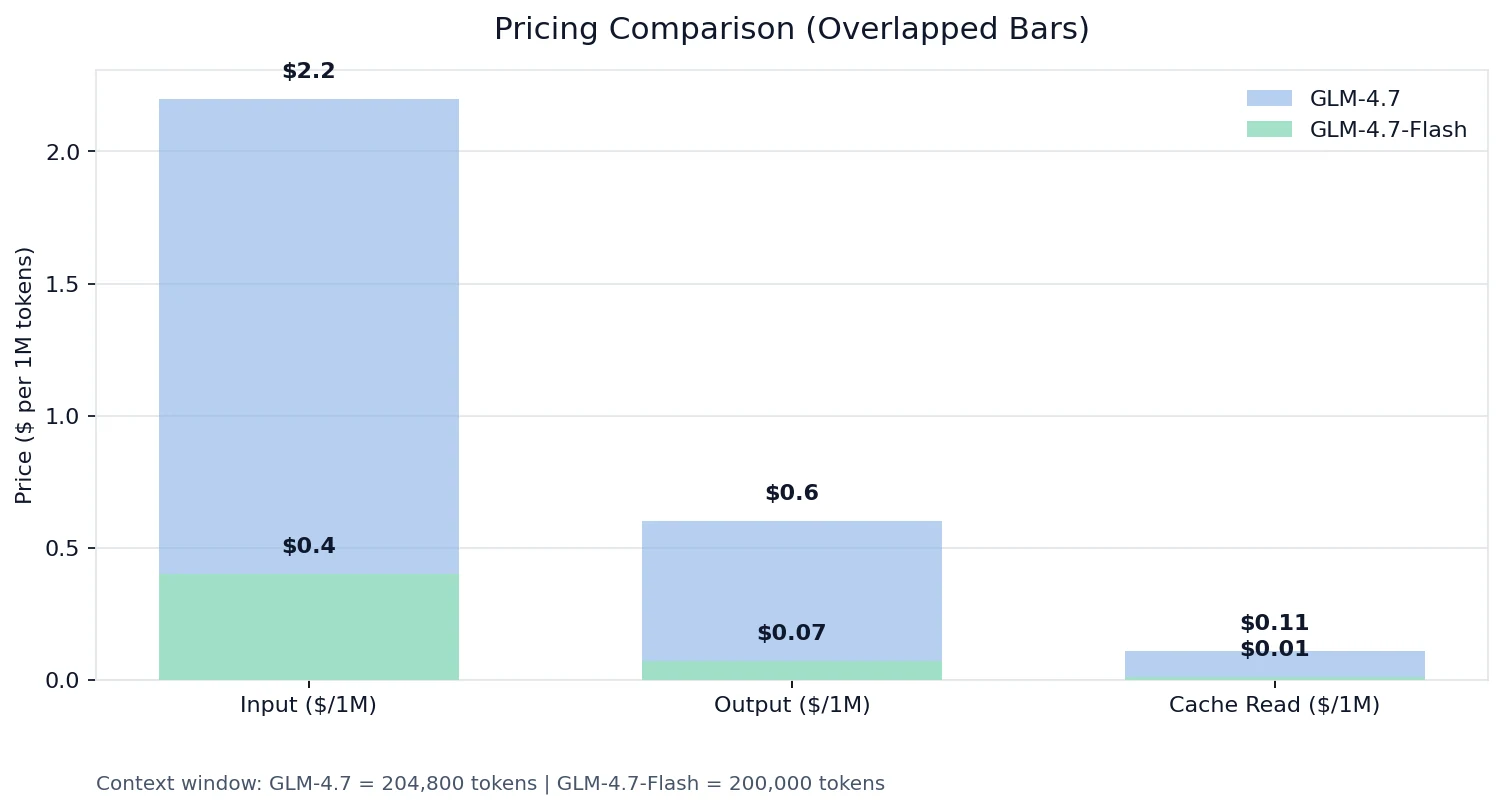
La realidad de “no están en el mismo nivel”
- Tokens de entrada: GLM-4.7 es ~8.6× Flash
- Tokens de salida: GLM-4.7 es 5.5× Flash
- Lectura de caché: GLM-4.7 es 11× Flash
Si estás construyendo algo con alto volumen de solicitudes, contexto largo o esquemas de herramientas que se repiten, la economía de Flash + el precio de lectura de caché pueden cambiar toda tu curva de costos.
Cuándo Usar Cada Modelo
GLM-4.7 y GLM-4.7-Flash no están en el mismo nivel: están diseñados para objetivos diferentes: GLM-4.7 = máxima calidad y razonamiento, Flash = rendimiento escalable y economía unitaria.
Elige GLM-4.7 cuando la calidad es el producto
Úsalo para:
- Razonamiento profundo / tareas complejas: lógica de múltiples pasos, matemáticas, planificación difícil, documentos de arquitectura y diseño
- Generación priorizando la calidad: escritura extensa, copias de marketing premium, traducción sensible al tono
- Soporte de decisiones de alto riesgo: decisiones legales/médicas/financieras/de ingeniería (aún requiere revisión humana)
Buena señal: si los errores son costosos, o si prefieres pagar más que reejecutar/reparar salidas, elige GLM-4.7.
Elige GLM-4.7-Flash cuando la escala es el producto
Úsalo para:
- Tareas diarias: chat, preguntas y respuestas básicas, reescritura, formateo, etiquetado/clasificación, extracción de información
- Cargas de trabajo de alta concurrencia: bots de atención al cliente, chat en tiempo real, procesamiento por lotes, llamadas API de alta frecuencia
- Entornos sensibles al costo: MVPs, productos con muchos usuarios, CI/testing, desarrollo/pruebas
Buena señal: si te importan el costo por solicitud, el rendimiento y la calidad “suficientemente buena” a volumen, elige Flash.
| Dimensión | Usa GLM-4.7 | Usa GLM-4.7-Flash |
| Complejidad de la tarea | Alta | Baja a media |
| Tolerancia a errores | Estricta | Algunos errores aceptables |
| Presupuesto | Cómodo | El control de costos es clave |
| Concurrencia | Baja a media | Alta |
Inicio Rápido: Prueba Ambos Modelos al Instante en Novita Playground
La forma más rápida de sentir la diferencia entre GLM-4.7 y GLM-4.7-Flash es el Novita AI Playground — sin código, sin configuración.
En Playground, puedes:
- Cambiar de modelo instantáneamente entre
zai-org/glm-4.7yzai-org/glm-4.7-flash - Ejecutar el mismo prompt para comparar calidad, estilo de razonamiento y velocidad de respuesta
- Validar el formato de tu prompt (JSON, salidas tipo herramienta) antes de pasar a la API
Prompts de prueba recomendados
- Un prompt con mucho razonamiento (para ver el techo de GLM-4.7)
- Un prompt de “operaciones” de alto volumen (resumen/extracción) para ver la practicidad y adecuación de costos de Flash
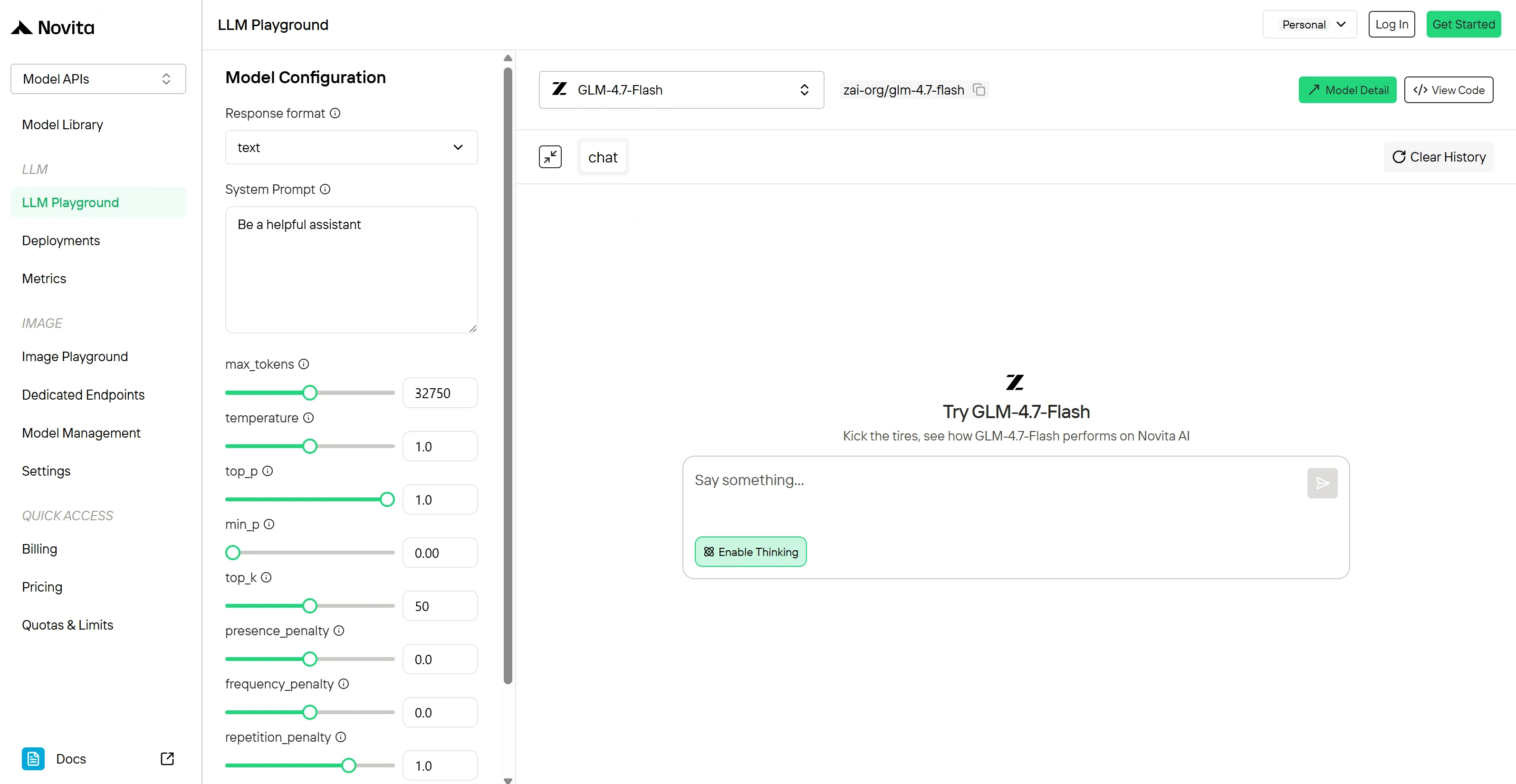
Novita AI Playground
Opciones de Despliegue: API, SDK, Integraciones de Terceros y Despliegue Local
Opción A: API
Obtén una Clave de API
- Paso 1: Crea o Inicia Sesión en tu Cuenta
Visita [**https://novita.ai**](https://novita.ai) y regístrate o inicia sesión en tu cuenta existente.
- Paso 2: Navega a la Gestión de Claves
Después de iniciar sesión, busca “API Keys”.

- Paso 3: Crea una Nueva Clave
Haz clic en el botón “Add New Key”.

- Paso 4: Guarda tu Clave Inmediatamente
Copia y almacena la clave tan pronto como se genere; normalmente se muestra solo una vez y no se puede recuperar después. Mantén la clave en un lugar seguro, como un gestor de contraseñas o notas cifradas.
API compatible con OpenAI (Python)
from openai import OpenAI
client = OpenAI(
api_key="<TU_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # o "zai-org/glm-4.7"
messages=[
{"role": "system", "content": "Eres un asistente de ingeniería preciso. Genera JSON válido cuando se te pida."},
{"role": "user", "content": "Resume los riesgos clave de implementar feature flags en 20 servicios."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
Opción B: SDK
Si estás construyendo flujos de trabajo agentivos (enrutamiento, traspasos, llamadas a herramientas/funciones), Novita funciona con SDKs compatibles con OpenAI con cambios mínimos:
- Compatible sin cambios: mantén tu lógica de cliente existente; solo cambia base_url + model
- Listo para orquestación: fácil de implementar enrutamiento (Flash por defecto → escalada a GLM-4.7)
- Configuración: apunta a
https://api.novita.ai/openai, estableceNOVITA_API_KEY, seleccionazai-org/glm-4.7/zai-org/glm-4.7-flash
Opción C: Plataformas de Terceros
También puedes ejecutar los modelos GLM alojados en Novita a través de ecosistemas populares:
- Frameworks de agentes y creadores de aplicaciones: Sigue las guías de integración paso a paso de Novita para conectar con herramientas populares como Continue, AnythingLLM, LangChain y Langflow.
- Hugging Face Hub: Novita aparece como un Proveedor de Inferencia en Hugging Face, por lo que puedes ejecutar modelos compatibles a través del flujo de trabajo y ecosistema de Hugging Face.
- API compatible con OpenAI: Los endpoints LLM de Novita son compatibles con el estándar de la API de OpenAI, lo que facilita migrar aplicaciones existentes al estilo OpenAI y conectar muchas herramientas compatibles con OpenAI ( Cline, Cursor , Trae y Qwen Code) .
- API compatible con Anthropic: Novita también proporciona acceso compatible con el SDK de Anthropic para que puedas integrar modelos respaldados por Novita en flujos de trabajo de codificación agentiva al estilo Claude Code .
- OpenCode: Novita AI ahora está integrado directamente en OpenCode como un proveedor compatible, por lo que los usuarios pueden seleccionar Novita en OpenCode sin configuración manual.
Opción D: Despliegue Local y Privado
GLM-4.7-Flash suele ser la opción más práctica para despliegue local/privado porque es más ligero y fácil de ejecutar en clusters on-prem, VPC/nubes privadas y entornos híbridos. Funciona especialmente bien para necesidades de cumplimiento/residencia de datos, aplicaciones internas sensibles a la latencia y cargas de trabajo agentivas/de contexto largo bajo presupuestos fijos de GPU.
Una configuración común es:
- Ejecutar Flash localmente para tráfico de alto volumen
- Escalar a GLM-4.7 (alojado) para solicitudes complejas o de alto riesgo
GLM-4.7 también se puede desplegar localmente, pero normalmente está reservado para equipos con fuerte capacidad de GPU y madurez operativa, principalmente para sistemas internos críticos en calidad y de menor rendimiento. Para uso interno general, Flash sigue siendo la opción predeterminada.
💡Incluso si ejecutar GLM-4.7 on-prem es demasiado costoso, aún puedes usarlo en producción a través de la API alojada de Novita, o ejecutarlo en la infraestructura de GPU de Novita para evitar la carga inicial de hardware y operaciones.
Conclusión
GLM-4.7 vs GLM-4.7-Flash no es un concurso justo de “cuál es mejor” — porque están diseñados para trabajos diferentes. Usa GLM-4.7 cuando necesites el techo más alto en razonamiento, codificación y fiabilidad agentiva. Usa GLM-4.7-Flash cuando necesites un modelo sólido que puedas escalar realmente: eficiente en costos, desplegable y altamente competitivo dentro de su nivel de eficiencia.
El mejor patrón de producción suele ser híbrido: Flash por defecto para volumen, y enrutar solicitudes complejas o de alto riesgo a GLM-4.7. Con el Playground de Novita y las APIs compatibles con OpenAI, puedes probar ambos en minutos y enviar la estrategia de enrutamiento sin cambiar tu stack.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.
Preguntas Frecuentes
¿Qué es GLM-4.7-Flash?
GLM-4.7-Flash es un modelo de lenguaje grande (LLM) de clase 30B de Mixture-of-Experts (MoE) desarrollado por Zhipu AI, diseñado para ofrecer un rendimiento sólido en razonamiento, codificación y tareas agentivas con alta eficiencia y baja latencia.
¿Cuánto cuesta GLM-4.7-Flash?
En Novita AI (serverless), GLM-4.7-Flash tiene un precio de $0.07/M tokens de entrada, $0.01/M tokens de lectura de caché y $0.40/M tokens de salida, lo que lo hace rentable para cargas de trabajo de contexto largo y alto rendimiento.
¿Cuál es la relación entre GLM-4.7-Flash y GLM-4.7?
GLM-4.7-Flash y GLM-4.7 pertenecen a la misma familia de modelos pero se dirigen a niveles diferentes: GLM-4.7 es el modelo insignia optimizado para la máxima calidad de razonamiento, mientras que GLM-4.7-Flash es una variante más ligera y eficiente en costos diseñada para un despliegue escalable y de alto volumen.



