

إذا كنت تقارن بين GLM-4.7 و GLM-4.7-Flash على أنهما قابلان للتبادل، فسينتهي بك الأمر إلى تحسين الشيء الخطأ.
هذان النموذجان ليسا في نفس الفئة بحسب التصميم:
- GLM-4.7 هو نموذج استدلال من الطراز الرائد—تختاره عندما تهتم بـ أقصى جودة ويمكنك تبرير تكلفة الرمز الأعلى.
- GLM-4.7-Flash هو “حصان عمل” أخف وأكثر كفاءة من حيث التكلفة—تختاره عندما تهتم بـ الإنتاجية، واقتصاديات الوحدة، وعملية السياق الطويل على نطاق واسع.
على Novita، يمكنك تشغيل كلاهما مع أسعار شفافة، واجهات برمجة تطبيقات (APIs)، ومساحة تجريبية سهلة لاتخاذ القرار بسرعة.
ما الذي تقارنه بالفعل: استدلال الطراز الرائد مقابل كفاءة قابلة للتوسع
GLM-4.7: نموذج الاستدلال من الطراز الرائد
يتم تصنيف GLM-4.7 كأحد النماذج الرائدة الأولوية للاستدلال (ذكاء عام قوي)، مع سياق طويل وتوليد سريع—لكنه أيضاً أغلى بكثير لكل رمز من Flash.
GLM-4.7-Flash: “حصان عمل” MoE القابل للتوسع للوكلاء/البرمجة
يتم بناء GLM-4.7-Flash حول الكفاءة (فئة MoE 30B-A3B)، ويستهدف سير عمل البرمجة للوكلاء + الأدوات والمهام ذات السياق الطويل التي تحتاج فيها إلى إنتاجية عالية وتكلفة يمكن التنبؤ بها.
مقارنة معايير الأداء
مؤشرات الذكاء/البرمجة/الاستدلال للوكلاء من Artificial Analysis
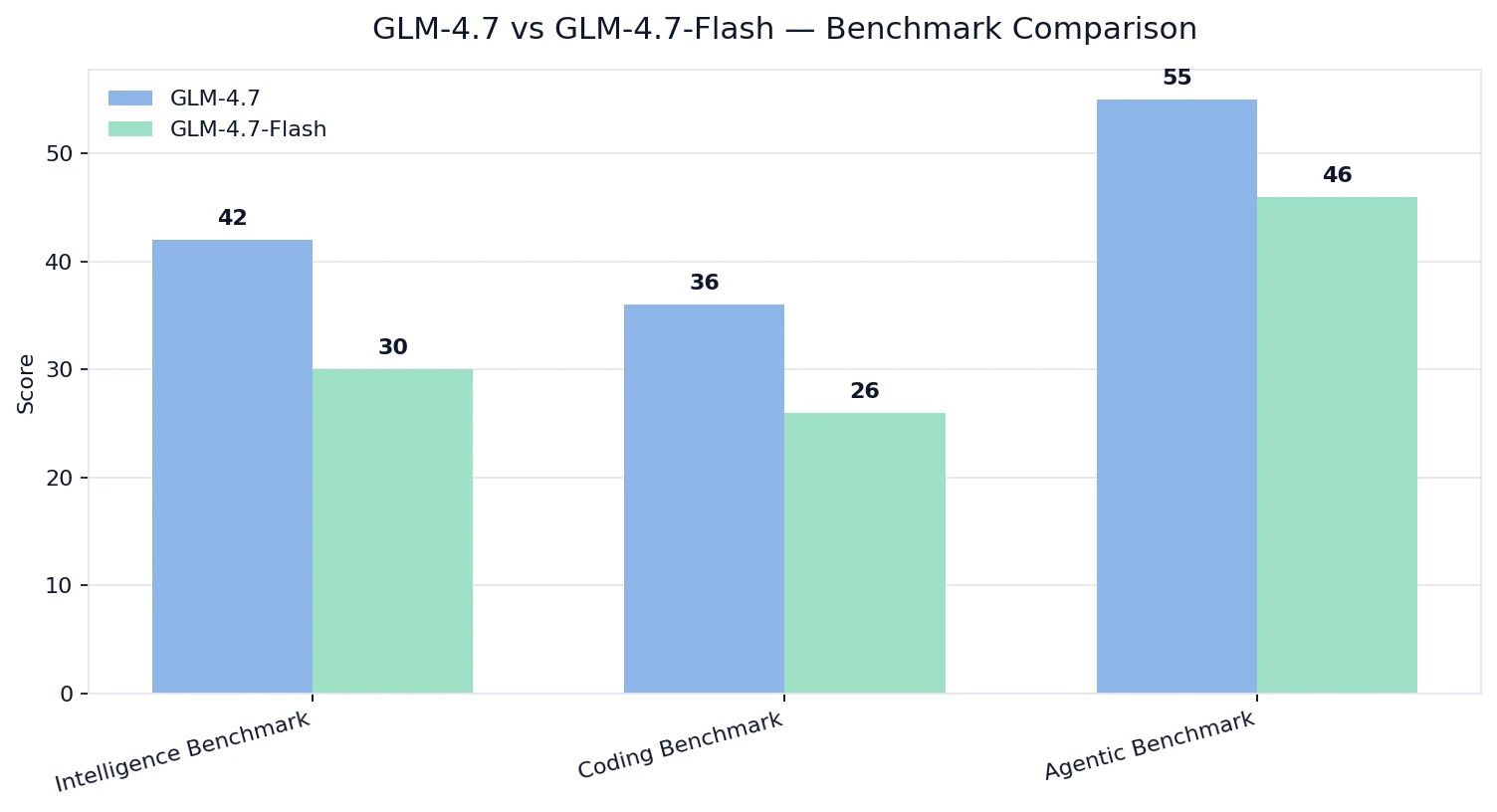
💡التفسير:
- GLM-4.7 يفوز بالجودة عبر قدرات الذكاء/البرمجة/الاستدلال للوكلاء.
- GLM-4.7-Flash لا يزال قوياً، لكنه مضبوط لهدف تحسين مختلف: التكلفة + إمكانية النشر + الإنتاجية العملية.
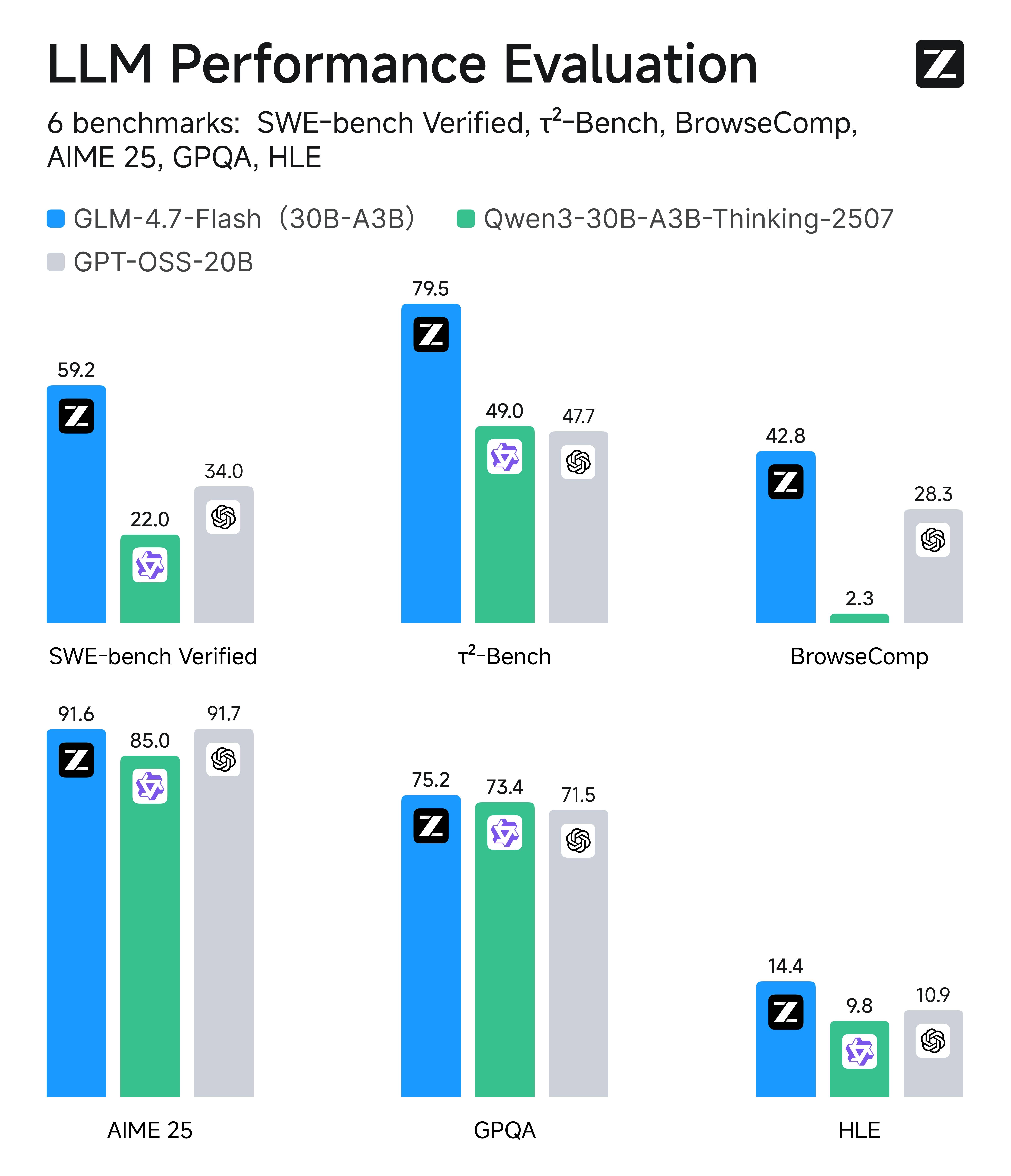
كفاءة من الطراز الأول: GLM-4.7-Flash مقابل بدائل ذات حجم مماثل
لكن ما من السهل تجاهله هو أن GLM-4.7-Flash هو أداء رائد ضمن فئة الكفاءة الخاصة به (تقريباً نماذج MoE / خفيفة الوزن من 20B إلى 30B). في مقارنات مع البدائل عبر ست تقييمات في العالم الواقعي—تغطي البرمجة، استخدام الوكلاء/الأدوات، مهام التصفح، الرياضيات، والاستدلال المعرفي—يحتل Flash مرتبة متسقة في القمة أو بالقرب منها بين البدائل ذات الحجم المماثل، وهذا هو السبب بالضبط في أنه يعد خياراً افتراضياً منطقياً لأنظمة الإنتاج عالية الحجم.
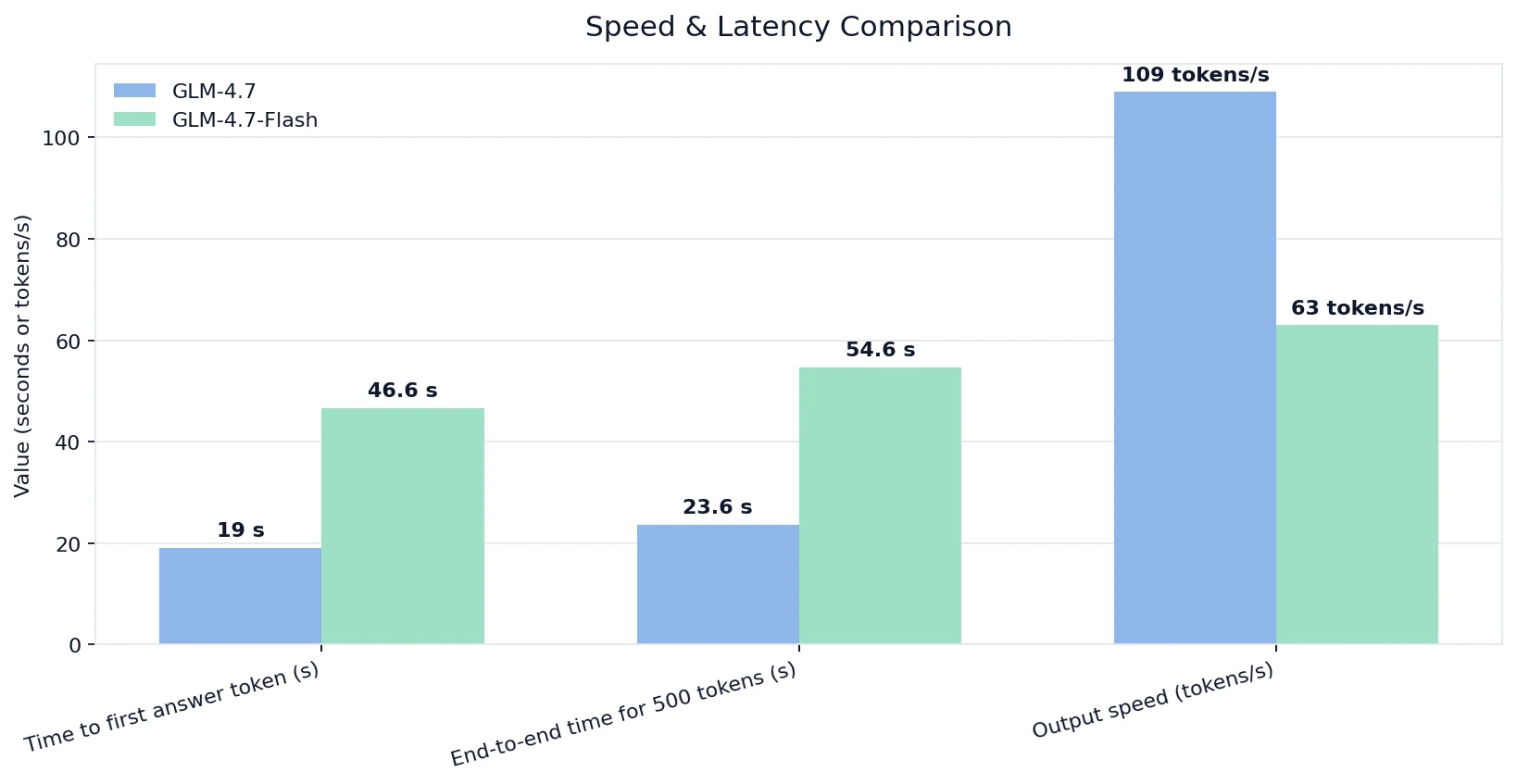
مقارنة السرعة والكمون
مقارنة الأسعار
على أسعار Novita:
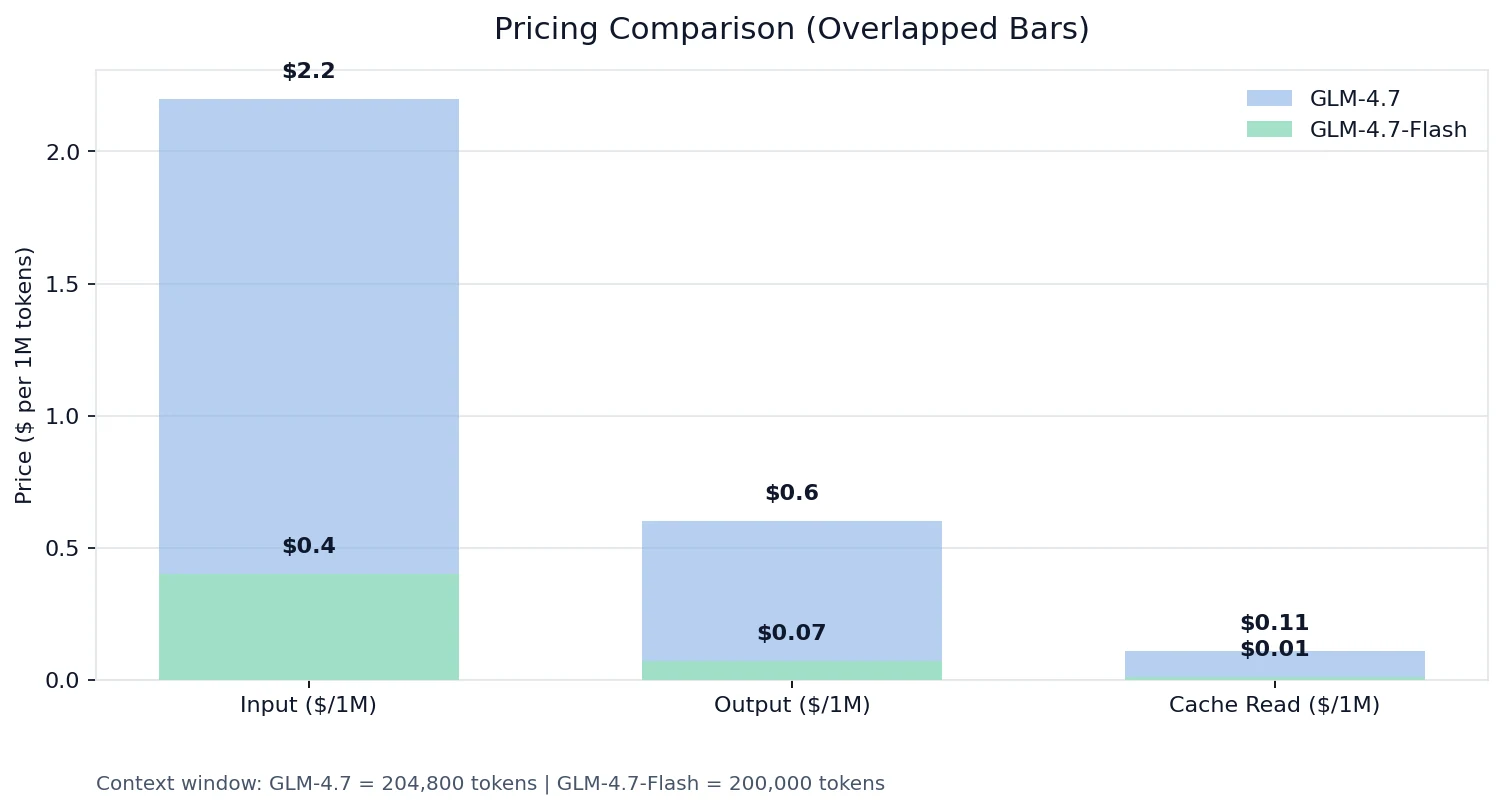
حقيقة “ليسا في نفس الفئة”
- رموز الإدخال: GLM-4.7 هو ~8.6× Flash
- رموز الإخراج: GLM-4.7 هو 5.5× Flash
- قراءة ذاكرة التخزين المؤقت: GLM-4.7 هو 11× Flash
إذا كنت تبني أي شيء بحجم طلبات مرتفع، أو سياق طويل، أو مخططات أدوات تتكرر، فإن اقتصاديات Flash + أسعار قراءة ذاكرة التخزين المؤقت يمكن أن تغير منحنى التكلفة بالكامل.
متى تستخدم أي من النموذجين
GLM-4.7 و GLM-4.7-Flash ليسا في نفس الفئة—فهما مبنيان لأهداف مختلفة: GLM-4.7 = أقصى جودة واستدلال، Flash = إنتاجية قابلة للتوسع واقتصاديات الوحدة.
اختر GLM-4.7 عندما تكون الجودة هي المنتج
استخدمه لـ:
- استدلال عميق / مهام معقدة: منطق متعدد الخطوات، رياضيات، تخطيط صعب، وثائق البنية والتصميم
- توليد الأولوية للجودة: كتابة طويلة، نصوص تسويقية متميزة، ترجمة حساسة للنبرة
- دعم القرارات عالية المخاطر: قرارات قانونية/طبية/مالية/هندسية (لا تزال تتطلب مراجعة بشرية)
إشارة جيدة: إذا كانت الأخطاء مكلفة، أو تفضل دفع المزيد بدلاً من إعادة تشغيل/إصلاح المخرجات، اختر GLM-4.7.
اختر GLM-4.7-Flash عندما يكون النطاق هو المنتج
استخدمه لـ:
- مهام يومية: محادثات، أسئلة وأجوبة أساسية، إعادة صياغة، تنسيق، وسم/تصنيف، استخراج معلومات
- أحمال عمل ذات تزامن عالي: روبوتات دعم العملاء، محادثات في الوقت الفعلي، معالجة دفعات، استدعاءات API عالية التردد
- بيئات حساسة للتكلفة: نماذج MVP الأولى، منتجات مستخدمين كبيرة، تكامل مستمر/اختبار، بيئات التطوير/التجهيز
إشارة جيدة: إذا كنت تهتم بـ التكلفة لكل طلب، الإنتاجية، وجودة “جيدة بما فيه الكفاية” على نطاق واسع، اختر Flash.
| البعد | استخدم GLM-4.7 | استخدم GLM-4.7-Flash |
| تعقيد المهمة | مرتفع | منخفض إلى متوسط |
| تحمل الدقة | صارم | بعض الأخطاء مقبولة |
| الميزانية | مريحة | التحكم في التكلفة هو الأساس |
| التزامن | منخفض إلى متوسط | مرتفع |
بداية سريعة: جرّب كلا النموذجين فوراً في مساحة Novita التجريبية
أسرع طريقة لـ الشعور بالفرق بين GLM-4.7 و GLM-4.7-Flash هي مساحة Novita AI التجريبية—بدون كود، بدون إعداد.
في المساحة التجريبية، يمكنك:
- تبديل النماذج فوراً بين
zai-org/glm-4.7وzai-org/glm-4.7-flash - تشغيل نفس الأمر لمقارنة الجودة، أسلوب الاستدلال، و سرعة الاستجابة
- التحقق من صيغة الأمر الخاص بك (مخرجات JSON، بأسلوب الأدوات) قبل الانتقال إلى واجهة برمجة التطبيقات
أوامر اختبار موصى بها
- أمر غني بالاستدلال (لرؤية الحد الأقصى لأداء GLM-4.7)
- أمر “عمليات” عالي الحجم (تلخيص / استخراج) لرؤية عملية Flash وملاءمة التكلفة
مساحة Novita AI التجريبية
خيارات النشر: API، SDK، تكاملات طرف ثالث ونشر محلي
الخيار أ: واجهة برمجة التطبيقات (API)
احصل على مفتاح API
-
الخطوة 1: إنشاء حساب أو تسجيل الدخول إلى حسابك الحالي زر
[**https://novita.ai**](https://novita.ai)و سجل حساباً جديداً أو سجل الدخول إلى حسابك الحالي -
الخطوة 2: انتقل إلى إدارة المفاتيح بعد تسجيل الدخول، ابحث عن “مفاتيح API”

-
الخطوة 3: إنشاء مفتاح جديد انقر على زر “إضافة مفتاح جديد”.

-
الخطوة 4: احفظ مفتاحك فوراً انسخ المفتاح واحفظه فور توليده؛ عادة ما يظهر مرة واحدة فقط ولا يمكن استرداده لاحقاً. احتفظ بالمفتاح في مكان آمن مثل مدير كلمات المرور أو ملاحظات مشفرة.
واجهة برمجة تطبيقات متوافقة مع OpenAI (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # or "zai-org/glm-4.7"
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
الخيار ب: حزمة تطوير البرمجيات (SDK)
إذا كنت تبني سير عمل للوكلاء (توجيه، تسليم، استدعاءات أدوات/دوال)، تعمل Novita مع حزم SDK متوافقة مع OpenAI مع تغييرات ضئيلة:
- متوافقة تماماً: احتفظ بمنطق العميل الحالي الخاص بك؛ فقط قم بتغيير base_url + model
- جاهز للتنسيق: من السهل تنفيذ التوجيه (الافتراضي هو Flash → تصعيد إلى GLM-4.7)
- الإعداد: وجه إلى
https://api.novita.ai/openai، عيّنNOVITA_API_KEY، اخترzai-org/glm-4.7/zai-org/glm-4.7-flash
الخيار ج: منصات طرف ثالث
يمكنك أيضاً تشغيل نماذج GLM المستضافة على Novita عبر الأنظمة البيئية الشائعة:
- أطر عمل الوكلاء وبناة التطبيقات: اتبع أدلة التكامل خطوة بخطوة من Novita للاتصال بالأدوات الشائعة مثل Continue، AnythingLLM، LangChain، و Langflow.
- مركز Hugging Face: تم إدراج Novita كـ مزود استدلال على Hugging Face، لذا يمكنك تشغيل النماذج المدعومة عبر سير عمل ومجموعة أدوات مزود Hugging Face.
- واجهة برمجة تطبيقات متوافقة مع OpenAI: نقاط نهاية LLM الخاصة بـ Novita متوافقة مع معيار واجهة برمجة تطبيقات OpenAI، مما يسهل ترحيل تطبيقات OpenAI الحالية والاتصال بالعديد من الأدوات المتوافقة مع OpenAI ( Cline، Cursor، Trae و Qwen Code).
- واجهة برمجة تطبيقات متوافقة مع Anthropic: توفر Novita أيضاً وصولاً متوافقاً مع حزمة SDK لـ Anthropic حتى تتمكن من دمج النماذج المدعومة من Novita في سير عمل البرمجة للوكلاء بأسلوب Claude Code.
- OpenCode: تم دمج Novita AI الآن مباشرة في OpenCode كـ مزود مدعوم، لذا يمكن للمستخدمين اختيار Novita في OpenCode دون تكوين يدوي.
الخيار د: النشر المحلي والخاص
GLM-4.7-Flash هو عادة الخيار العملي الأكثر لـ النشر المحلي/الخاص لأنه أخف وأسهل في التشغيل عبر مجموعات الخوادم المحلية، شبكات VPC خاصة / سحابات خاصة، و بيئات هجينة. يعمل بشكل جيد بشكل خاص لـ احتياجات الامتثال/إقامة البيانات، تطبيقات داخلية حساسة للكمون، و أحمال عمل ذات سياق طويل/للوكلاء ضمن ميزانيات GPU ثابتة.
إعداد شائع هو:
- تشغيل Flash محلياً لحركة المرور عالية الحجم
- التصعيد إلى GLM-4.7 (مستضاف) للطلبات المعقدة أو عالية المخاطر
GLM-4.7 يمكن أيضاً نشره محلياً، لكنه عادة محجوز للفرق ذات قدرة GPU قوية ونضج عمليات، بشكل أساسي لأنظمة داخلية حرجة من حيث الجودة، ذات إنتاجية منخفضة. للاستخدام الداخلي الواسع، يبقى Flash هو الافتراضي.
💡حتى لو كان تشغيل GLM-4.7 محلياً مكلفاً للغاية، لا يزال بإمكانك استخدامه في الإنتاج عبر واجهة برمجة تطبيقات Novita المستضافة، أو تشغيله على بنية GPU الخاصة بـ Novita لتجنب عبء الأجهزة الأولي والعمليات.
الخلاصة
مقارنة GLM-4.7 مقابل GLM-4.7-Flash ليست مسابقة عادلة “أيهما أفضل”—لأنهما مبنيان لمهام مختلفة. استخدم GLM-4.7 عندما تحتاج إلى أعلى حد للاستدلال والبرمجة وموثوقية الوكلاء. استخدم GLM-4.7-Flash عندما تحتاج إلى نموذج قوي يمكنك فعلاً توسيع نطاقه—كفء من حيث التكلفة، قابل للنشر، وذو قدرة تنافسية عالية ضمن فئة الكفاءة الخاصة به.
أفضل نمط إنتاج عادة ما يكون هجين: الافتراضي هو Flash للحجم العالي، و توجيه الطلبات المعقدة أو عالية المخاطر إلى GLM-4.7. مع مساحة Novita التجريبية وواجهات برمجة التطبيقات المتوافقة مع OpenAI، يمكنك اختبار كلاهما في دقائق وإطلاق استراتيجية التوجيه دون تغيير مكدس التقنية الخاص بك.
Novita AI هي منصة سحابية للذكاء الاصطناعي توفر للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، مع توفير سحابة GPU بأسعار معقولة وموثوقة للبناء والتوسع.
الأسئلة الشائعة
ما هو GLM-4.7-Flash؟ GLM-4.7-Flash هو نموذج لغة كبير من فئة 30B من نوع Mixture-of-Experts (MoE) تم تطويره بواسطة Zhipu AI، مصمم لتقديم أداء قوي في الاستدلال والبرمجة والوكلاء مع كفاءة عالية وكمون منخفض.
كم تكلفة GLM-4.7-Flash؟ على Novita AI (بدون خوادم)، يتم تسعير GLM-4.7-Flash بـ $0.07/M رموز إدخال، $0.01/M رموز قراءة ذاكرة تخزين مؤقت، و $0.40/M رموز إخراج، مما يجعله فعالاً من حيث التكلفة لأحمال العمل ذات السياق الكبير والإنتاجية العالية.
ما هي العلاقة بين GLM-4.7-Flash و GLM-4.7؟ ينتمي GLM-4.7-Flash و GLM-4.7 إلى نفس عائلة النماذج لكنهما يستهدفان فئات مختلفة: GLM-4.7 هو النموذج الرائد المحسّن لأقصى جودة استدلال، بينما GLM-4.7-Flash هو نسخة أخف وأكثر كفاءة من حيث التكلفة مصمم للنشر القابل للتوسع عالي الحجم.



