

만약 GLM-4.7과 GLM-4.7-Flash를 서로 교체 가능한 모델처럼 비교하고 있다면, 잘못된 부분을 최적화하고 있는 것입니다.
이 두 모델은 설계상 같은 등급이 아닙니다:
- GLM-4.7은 플래그십 추론 모델입니다. 최대 품질이 중요하고 더 높은 토큰 비용을 감당할 수 있을 때 선택합니다.
- GLM-4.7-Flash는 더 가볍고 비용 효율적인 “워크호스” 모델입니다. 대규모로 처리량, 단위 경제성, 긴 컨텍스트 실용성을 고려할 때 선택합니다.
Novita에서는 투명한 가격, API, 그리고 빠르게 결정을 내릴 수 있는 쉬운 Playground를 통해 두 모델을 모두 실행할 수 있습니다.
실제로 비교하는 대상: 플래그십 추론 vs 확장 가능한 효율성
GLM-4.7: 플래그십 추론 모델
GLM-4.7은 선도적인 추론 우선 모델(강력한 전반적 지능)로 자리 잡고 있으며, 긴 컨텍스트와 빠른 생성을 제공하지만 Flash보다 토큰당 훨씬 비쌉니다.
GLM-4.7-Flash: 확장 가능한 MoE “에이전트/코딩 워크호스”
GLM-4.7-Flash는 효율성(30B-A3B MoE 클래스)을 중심으로 구축되었으며, 높은 처리량과 예측 가능한 비용이 필요한 에이전트 코딩 + 도구 워크플로우 및 긴 컨텍스트 작업을 대상으로 합니다.
벤치마크 비교
Artificial Analysis 지능 / 코딩 / 에이전트 지수
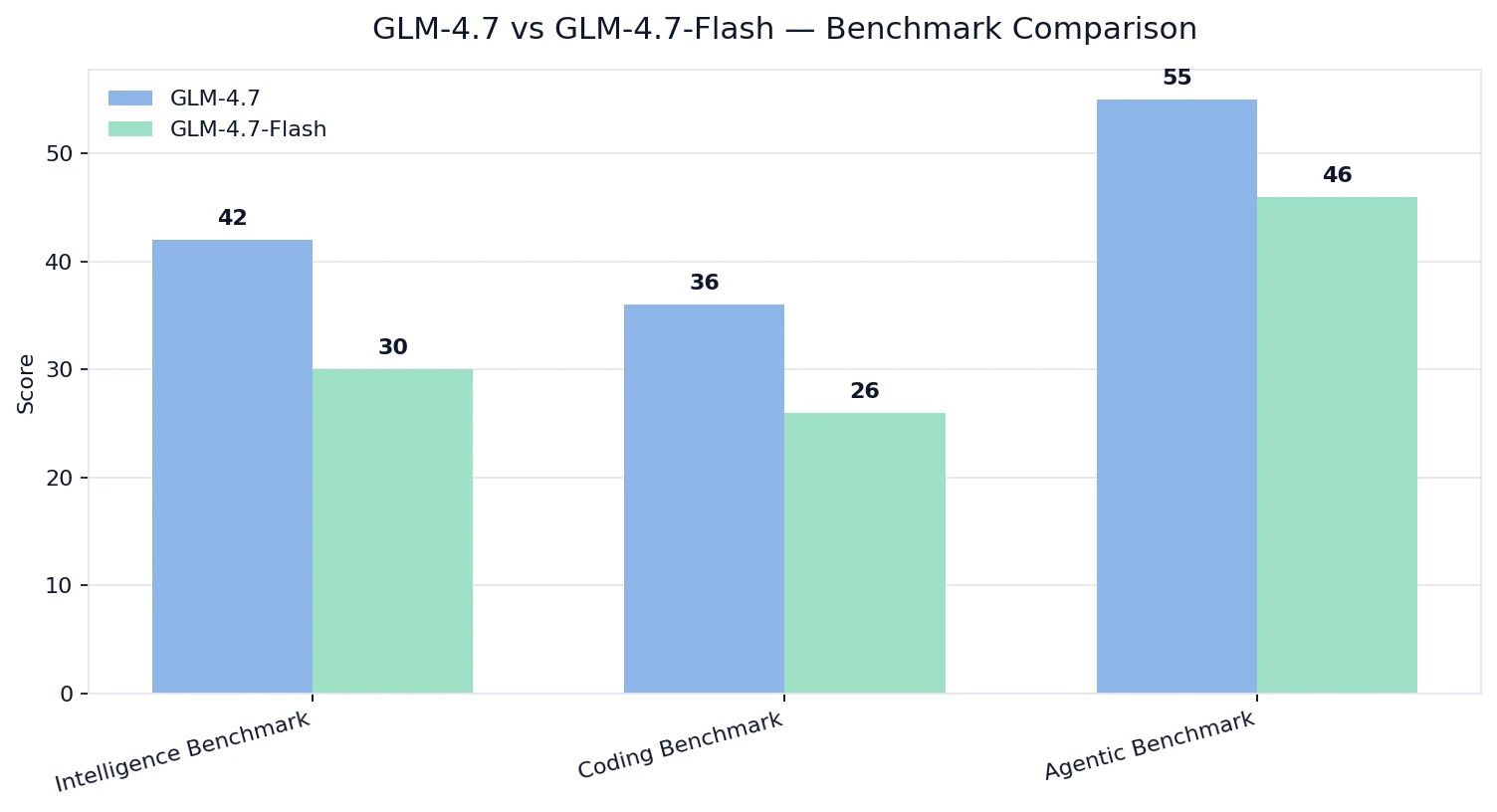
💡해석:
- GLM-4.7은 품질에서 우위를 점합니다 (지능/코딩/에이전트 능력).
- GLM-4.7-Flash도 여전히 강력하지만, 비용 + 배포 가능성 + 실용적 처리량이라는 다른 최적화 목표에 맞춰 조정되었습니다.
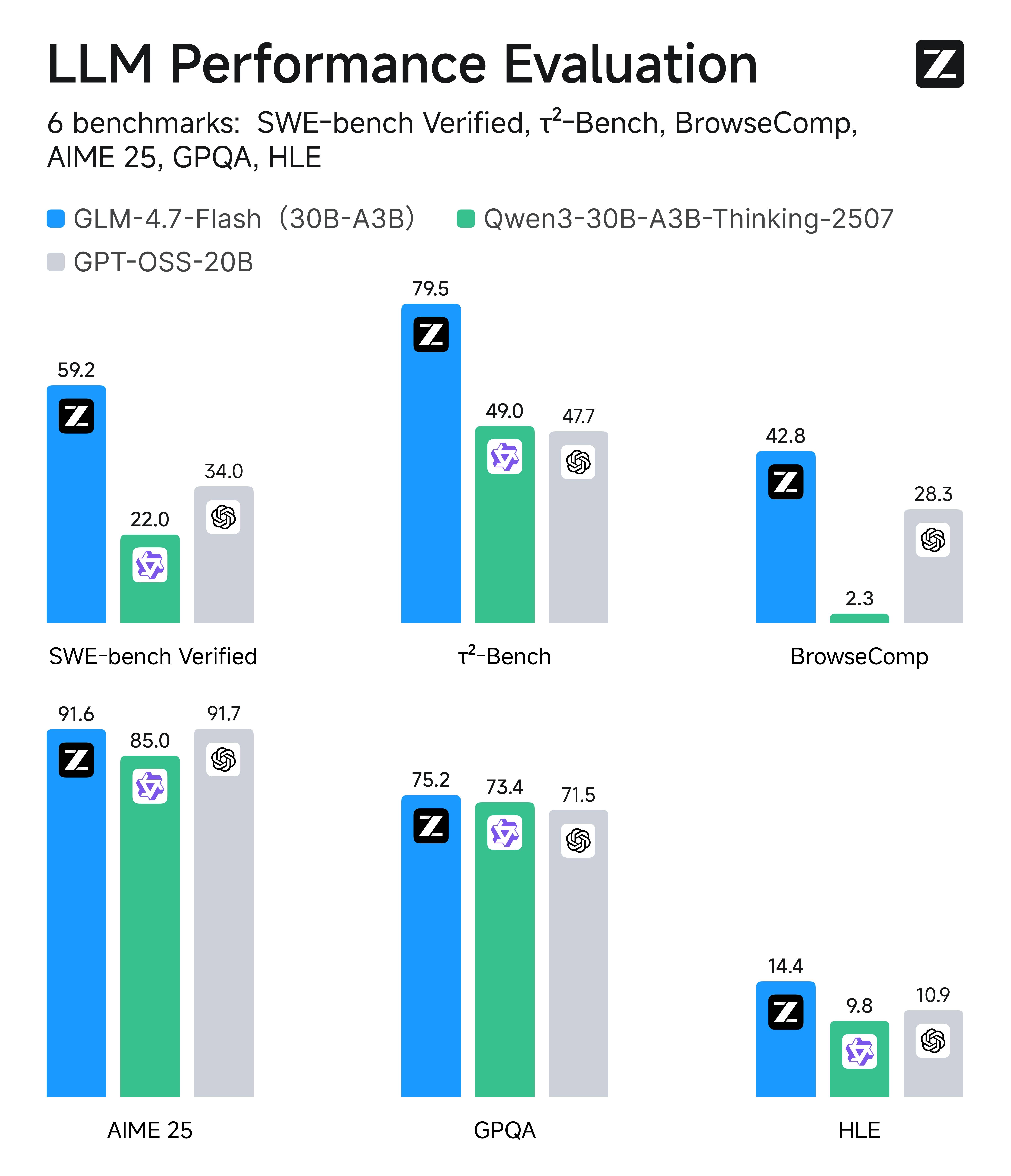
최고 수준의 효율성: GLM-4.7-Flash vs 유사 규모 경쟁사
하지만 간과하기 쉬운 점은 GLM-4.7-Flash가 자체 효율성 클래스(약 20B~30B MoE/경량 모델) 내에서 최고 성능을 발휘한다는 것입니다. 코딩, 에이전트/도구 사용, 브라우징 스타일 작업, 수학, 지식 추론을 아우르는 6가지 실제 평가에서 경쟁사와 비교했을 때, Flash는 유사한 규모의 대안 중에서 지속적으로 최상위권에 랭크됩니다. 이것이 바로 고볼륨 프로덕션 시스템에서 기본 선택으로 적합한 이유입니다.
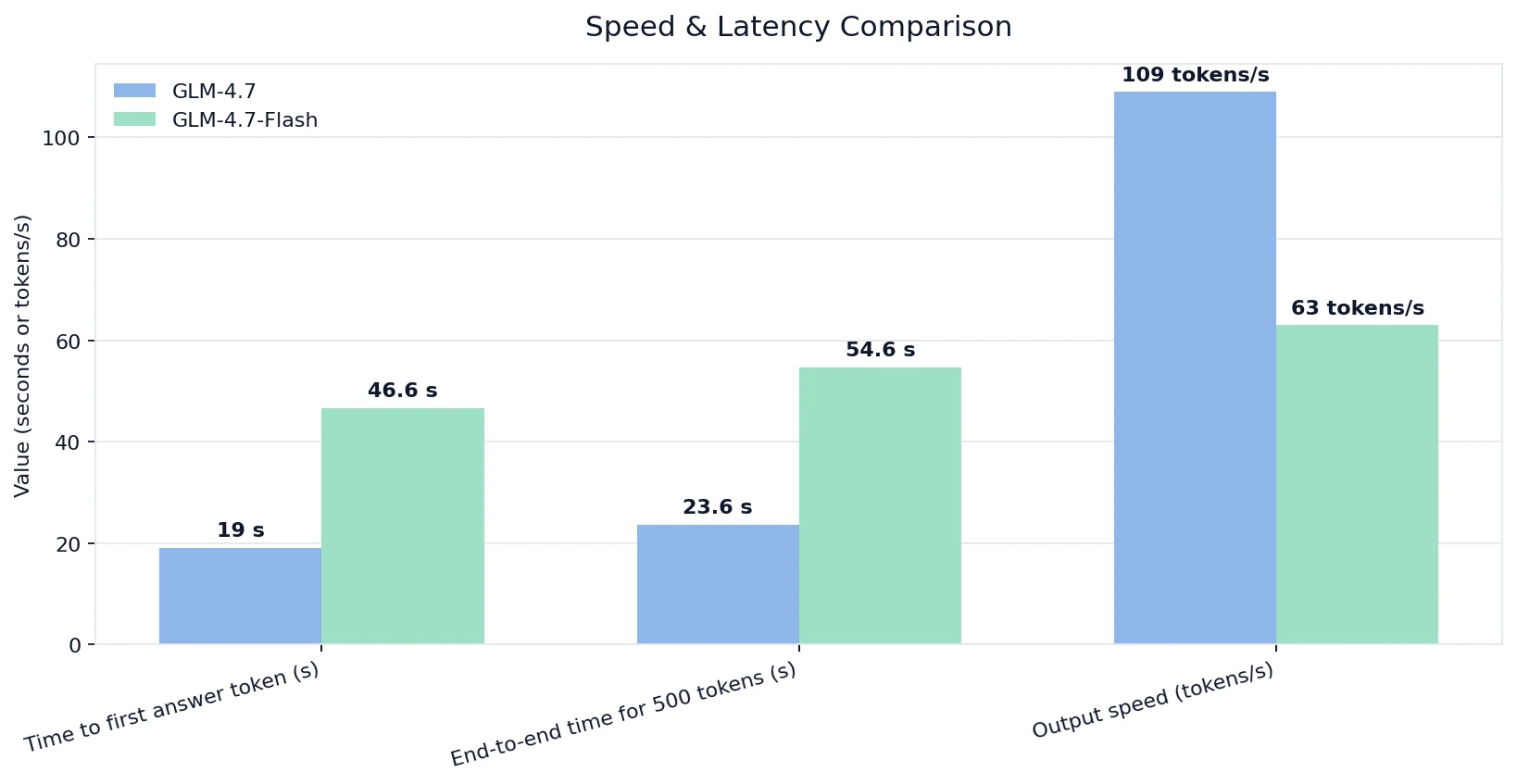
속도 및 지연 시간 비교
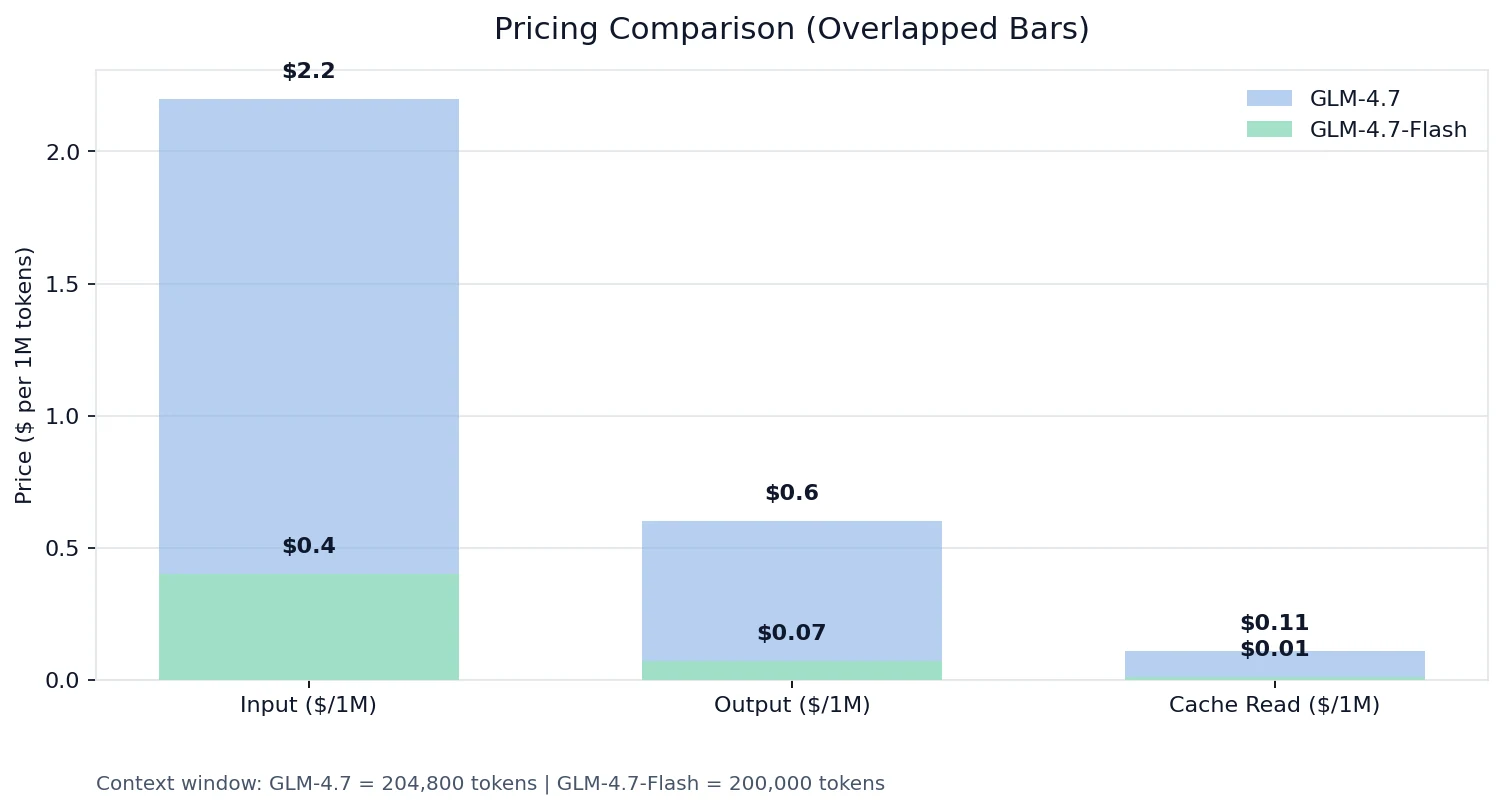
가격 비교
Novita 가격 기준:
"같은 등급이 아님"의 현실
- 입력 토큰: GLM-4.7은 Flash의 약 8.6배
- 출력 토큰: GLM-4.7은 Flash의 5.5배
- 캐시 읽기: GLM-4.7은 Flash의 11배
높은 요청 볼륨, 긴 컨텍스트, 또는 반복되는 도구 스키마가 있는 시스템을 구축하는 경우, Flash의 경제성과 캐시 읽기 가격 책정은 전체 비용 곡선을 바꿀 수 있습니다.
어떤 모델을 언제 사용해야 할까
GLM-4.7과 GLM-4.7-Flash는 같은 등급이 아닙니다 — 서로 다른 목표를 위해 설계되었습니다: GLM-4.7 = 최대 품질과 추론, Flash = 확장 가능한 처리량과 단위 경제성.
GLM-4.7을 선택해야 할 때: 품질이 제품인 경우
다음과 같은 경우에 사용합니다:
- 심층 추론 / 복잡한 작업: 다단계 논리, 수학, 어려운 계획, 아키텍처 및 설계 문서
- 품질 우선 생성: 장문 작성, 프리미엄 마케팅 카피, 어조에 민감한 번역
- 중요 의사결정 지원: 법률/의료/금융/엔지니어링 결정 (여전히 사람의 검토 필요)
좋은 신호: 실수 비용이 크거나, 결과물을 재실행/수리하는 것보다 더 많은 비용을 지불하더라도 품질을 원한다면 GLM-4.7을 선택하세요.
GLM-4.7-Flash를 선택해야 할 때: 규모가 제품인 경우
다음과 같은 경우에 사용합니다:
- 일상적인 작업: 채팅, 기본 Q&A, 재작성, 포맷팅, 태깅/분류, 정보 추출
- 높은 동시성 워크로드: 고객 지원 봇, 실시간 채팅, 배치 처리, 고주파 API 호출
- 비용에 민감한 환경: MVP, 대규모 사용자 제품, CI/테스트, 개발/스테이징
좋은 신호: 요청당 비용, 처리량, 그리고 볼륨에서 “충분히 좋은” 품질이 중요하다면 Flash를 선택하세요.
| 차원 | GLM-4.7 사용 | GLM-4.7-Flash 사용 |
| 작업 복잡성 | 높음 | 낮음~중간 |
| 정확도 허용 범위 | 엄격함 | 일부 오류 허용 가능 |
| 예산 | 여유 있음 | 비용 통제가 핵심 |
| 동시성 | 낮음~중간 | 높음 |
빠른 시작: Novita Playground에서 두 모델 즉시 체험하기
GLM-4.7과 GLM-4.7-Flash의 차이를 느끼는 가장 빠른 방법은 Novita AI Playground입니다 — 코드도 설정도 필요 없습니다.
Playground에서 다음을 할 수 있습니다:
- 모델을 즉시 전환:
zai-org/glm-4.7과zai-org/glm-4.7-flash사이를 자유롭게 전환 - 동일한 프롬프트를 실행하여 품질, 추론 스타일, 응답 속도 비교
- API로 이동하기 전에 프롬프트 형식(JSON, 도구 스타일 출력) 검증
권장 테스트 프롬프트
- 추론 중심 프롬프트 (GLM-4.7의 최대 성능 확인)
- 고볼륨 “운영” 프롬프트 (요약/추출)로 Flash의 실용성과 비용 적합성 확인
Novita AI Playground
배포 옵션: API, SDK, 타사 통합 및 로컬 배포
옵션 A: API
API 키 얻기
- 1단계: 계정 생성 또는 로그인
[**https://novita.ai**](https://novita.ai) 방문하여 가입하거나 기존 계정으로 로그인합니다.
- 2단계: 키 관리로 이동
로그인 후 "API Keys"를 찾습니다.

- 3단계: 새 키 생성
“Add New Key” 버튼을 클릭합니다.

- 4단계: 키 즉시 저장
키가 생성되면 즉시 복사하여 저장합니다. 일반적으로 한 번만 표시되며 나중에 다시 확인할 수 없습니다. 비밀번호 관리자나 암호화된 메모와 같은 안전한 장소에 보관하세요.
OpenAI 호환 API (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # 또는 "zai-org/glm-4.7"
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
옵션 B: SDK
에이전트 워크플로우(라우팅, 핸드오프, 도구/함수 호출)를 구축하는 경우, Novita는 최소한의 변경으로 OpenAI 호환 SDK와 함께 작동합니다:
- 드롭인 호환: 기존 클라이언트 로직 유지, base_url + model만 변경
- 오케스트레이션 준비: 라우팅 구현 용이 (Flash 기본 → GLM-4.7 에스컬레이션)
- 설정:
https://api.novita.ai/openai로 연결,NOVITA_API_KEY설정,zai-org/glm-4.7/zai-org/glm-4.7-flash선택
옵션 C: 타사 플랫폼
Novita에서 호스팅하는 GLM 모델을 인기 있는 에코시스템을 통해 실행할 수도 있습니다:
- 에이전트 프레임워크 및 앱 빌더: Novita의 단계별 통합 가이드를 따라 Continue, AnythingLLM, LangChain, Langflow 와 같은 인기 도구에 연결하세요.
- Hugging Face Hub: Novita는 Hugging Face에서 추론 제공자(Inference Provider) 로 등록되어 있으므로 Hugging Face의 제공자 워크플로우 및 에코시스템을 통해 지원되는 모델을 실행할 수 있습니다.
- OpenAI 호환 API: Novita의 LLM 엔드포인트는 OpenAI API 표준과 호환되므로 기존 OpenAI 스타일 앱을 쉽게 마이그레이션하고 많은 OpenAI 호환 도구( Cline, Cursor, Trae 및 Qwen Code )를 연결할 수 있습니다.
- Anthropic 호환 API: Novita는 또한 Anthropic SDK 호환 액세스를 제공하므로 Novita 지원 모델을 Claude Code 스타일의 에이전트 코딩 워크플로우에 통합할 수 있습니다.
- OpenCode: Novita AI는 이제 OpenCode 에 지원되는 제공자로 직접 통합되어 사용자가 수동 구성 없이 OpenCode에서 Novita를 선택할 수 있습니다.
옵션 D: 로컬 및 프라이빗 배포
GLM-4.7-Flash는 일반적으로 로컬/프라이빗 배포에 더 실용적인 선택입니다. 더 가볍고 온프레미스 클러스터, VPC/프라이빗 클라우드, 하이브리드 환경에서 실행하기 더 쉽기 때문입니다. 특히 규정 준수/데이터 레지던시 요구 사항, 지연 시간에 민감한 내부 앱, 고정 GPU 예산 하의 긴 컨텍스트/에이전트 워크로드에 잘 맞습니다.
일반적인 설정은 다음과 같습니다:
- Flash를 로컬에서 실행하여 높은 볼륨 트래픽 처리
- 복잡하거나 중요한 요청은 GLM-4.7 (호스팅) 로 에스컬레이션
GLM-4.7도 로컬에 배포할 수 있지만, 일반적으로 강력한 GPU 용량과 운영成熟度를 갖춘 팀이 주로 품질에 중요한, 낮은 처리량의 내부 시스템을 위해 사용합니다. 광범위한 내부 사용을 위해서는 Flash가 기본값으로 남아 있습니다.
💡GLM-4.7을 온프레미스에서 실행하는 것이 너무 비싸더라도 Novita의 호스팅 API를 통해 프로덕션에서 사용하거나 Novita GPU 인프라에서 실행하여 초기 하드웨어 및 운영 부담을 피할 수 있습니다.
결론
GLM-4.7 vs GLM-4.7-Flash는 "어느 것이 더 나은가"라는 공정한 대결이 아닙니다 — 서로 다른 작업을 위해 만들어졌기 때문입니다. 추론, 코딩, 에이전트 신뢰성에서 최고 수준의 성능이 필요할 때 GLM-4.7을 사용하세요. 실제로 확장할 수 있는 강력한 모델이 필요할 때 — 비용 효율적이고, 배포 가능하며, 효율성 계층 내에서 매우 경쟁력 있는 — GLM-4.7-Flash를 사용하세요.
가장 좋은 프로덕션 패턴은 일반적으로 하이브리드입니다: 볼륨에는 기본적으로 Flash, 복잡하거나 중요한 요청은 GLM-4.7로 라우팅합니다. Novita의 Playground와 OpenAI 호환 API를 사용하면 몇 분 안에 두 모델을 테스트하고 스택을 변경하지 않고 라우팅 전략을 출시할 수 있습니다.
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있는 AI 클라우드 플랫폼이며, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공합니다.
자주 묻는 질문
GLM-4.7-Flash란 무엇인가요?
GLM-4.7-Flash는 Zhipu AI가 개발한 30B급 Mixture-of-Experts (MoE) 대규모 언어 모델로, 높은 효율성과 낮은 지연 시간으로 강력한 추론, 코딩 및 에이전트 성능을 제공하도록 설계되었습니다.
GLM-4.7-Flash의 비용은 얼마인가요?
Novita AI(서버리스)에서 GLM-4.7-Flash의 가격은 입력 토큰 $0.07/M, 캐시 읽기 토큰 $0.01/M, 출력 토큰 $0.40/M으로, 대규모 컨텍스트 및 높은 처리량 워크로드에 비용 효율적입니다.
GLM-4.7-Flash와 GLM-4.7의 관계는 무엇인가요?
GLM-4.7-Flash와 GLM-4.7은 동일한 모델 제품군에 속하지만 서로 다른 계층을 대상으로 합니다: GLM-4.7은 최대 추론 품질에 최적화된 플래그십 모델인 반면, GLM-4.7-Flash는 확장 가능한 대규모 배포를 위해 설계된 더 가볍고 비용 효율적인 변형입니다.



