

- Ce que vous comparez réellement : Raisonnement flagship contre efficacité scalable
- Comparaison des benchmarks
- Comparaison de la vitesse et de la latence
- Comparaison des prix
- Quand utiliser quel modèle
- Démarrage rapide : Essayez les deux modèles instantanément dans le Playground Novita
- Options de déploiement : API, SDK, intégrations tierces et déploiement local
- Conclusion
Si vous comparez GLM-4.7 et GLM-4.7-Flash comme s’ils étaient interchangeables, vous allez optimiser la mauvaise chose.
Ces deux modèles ne sont pas de la même gamme par conception :
- GLM-4.7 est un modèle de raisonnement flagship : vous le choisissez lorsque vous vous souciez de qualité maximale et pouvez justifier un coût par token plus élevé.
- GLM-4.7-Flash est un « cheval de trait » plus léger et rentable : vous le choisissez lorsque vous vous souciez de débit, d’économie unitaire et de praticité du long contexte à grande échelle.
Sur Novita, vous pouvez exécuter les deux avec des tarifs transparents, des API et un Playground simple pour décider rapidement.
Ce que vous comparez réellement : Raisonnement flagship contre efficacité scalable
GLM-4.7 : le modèle de raisonnement flagship
GLM-4.7 est positionné comme un modèle axé sur le raisonnement de premier plan (intelligence générale forte), avec un long contexte et une génération rapide – mais il est également beaucoup plus cher par token que Flash.
GLM-4.7-Flash : le « cheval de trait » MoE scalable pour les agents et le codage
GLM-4.7-Flash est construit autour de l’efficacité (classe MoE 30B-A3B), ciblant les workflows de codage agentique + outils et les tâches de long contexte pour lesquelles vous avez besoin de débit élevé et de coûts prévisibles.
Comparaison des benchmarks
Indices Intelligence / Codage / Agentique d’Artificial Analysis
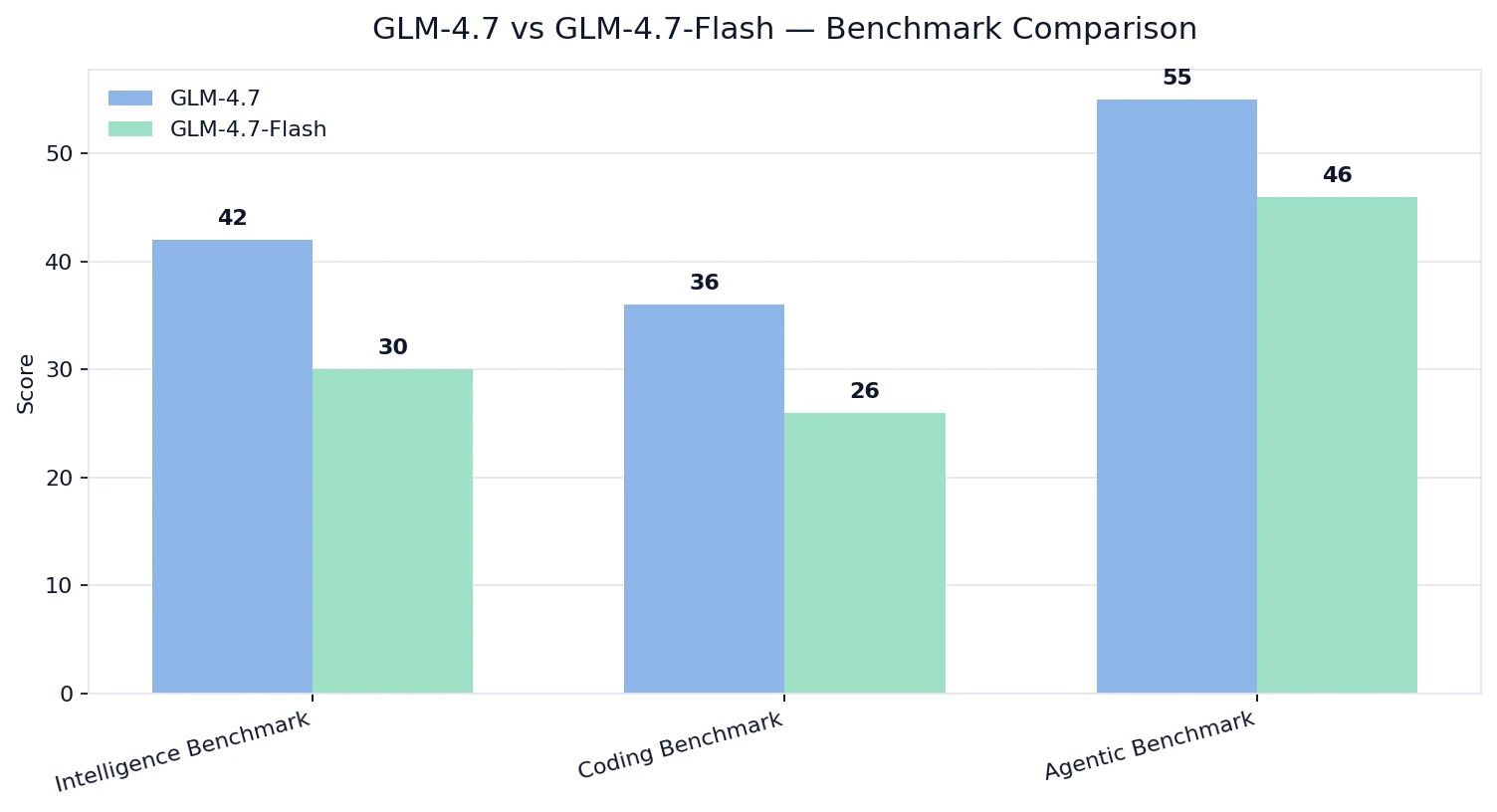
Depuis Artificial Analysis
💡Interprétation :
- GLM-4.7 l’emporte sur la qualité sur l’ensemble des capacités d’intelligence, de codage et agentiques.
- GLM-4.7-Flash reste performant, mais il est optimisé pour une cible d’optimisation différente : coût + déployabilité + débit pratique.
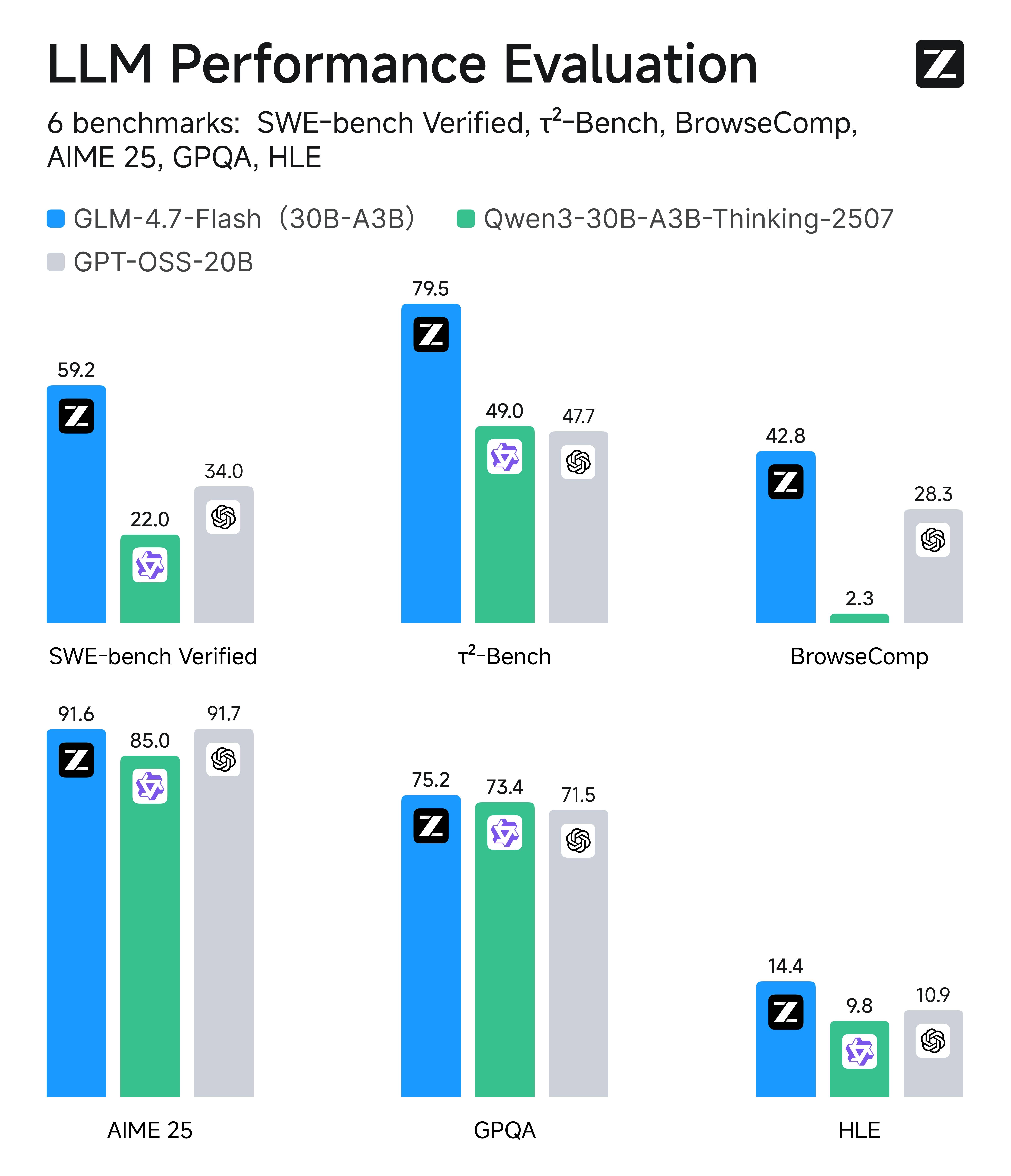
Efficacité de premier ordre : GLM-4.7-Flash contre des pairs de taille similaire
Ce qui est facile à manquer, cependant, c’est que GLM-4.7-Flash est un performer de premier ordre dans sa propre classe d’efficacité (environ modèles MoE 20B–30B / légers). Lors de comparaisons avec des pairs sur six évaluations du monde réel – couvrant le codage, l’utilisation d’agents/outils, les tâches de type navigation, les mathématiques et le raisonnement sur des connaissances – Flash se classe systématiquement parmi les premiers ou près du sommet parmi les alternatives de taille similaire, ce qui explique exactement pourquoi il est un choix par défaut logique pour les systèmes de production à haut volume.
Comparaison de la vitesse et de la latence
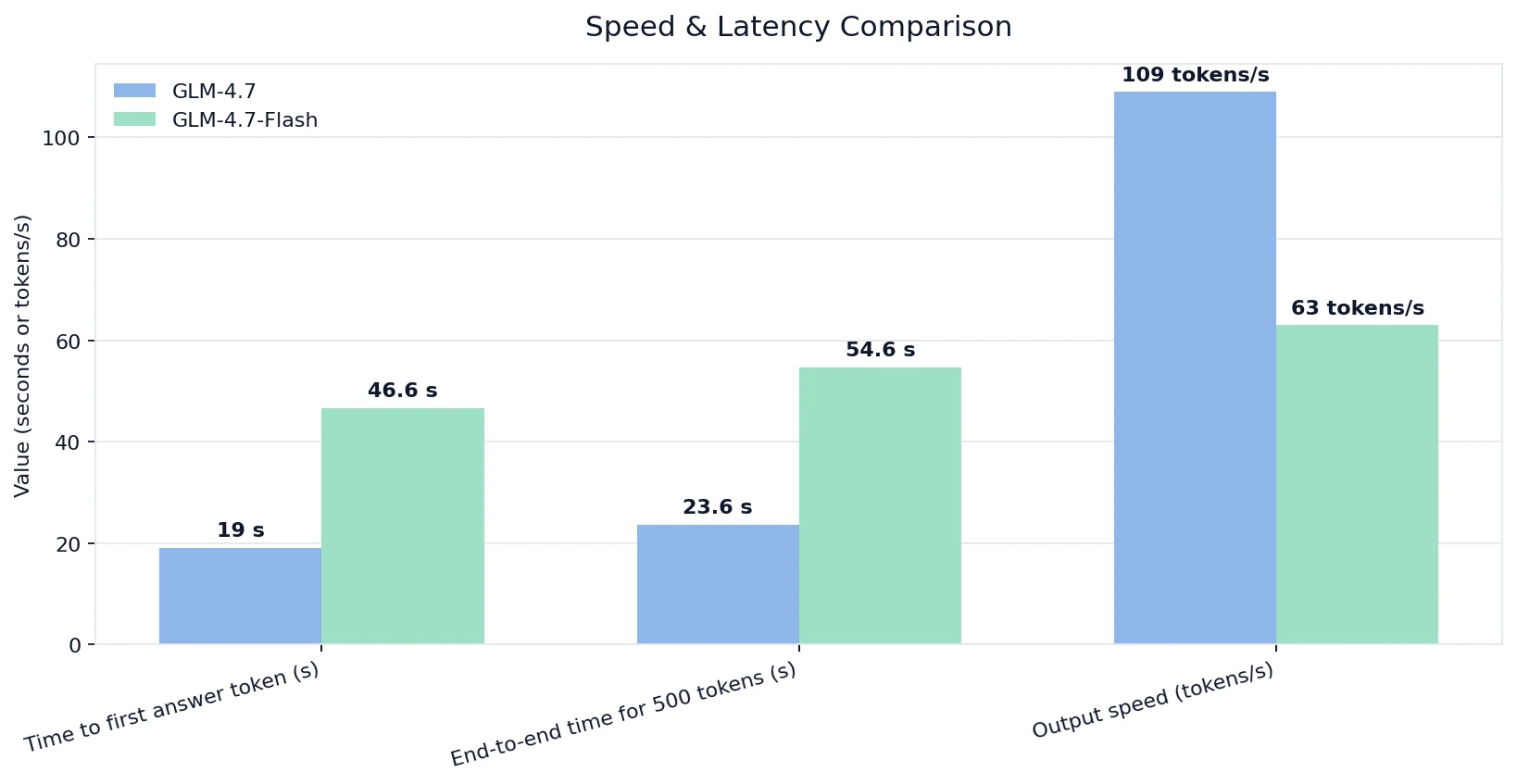
Depuis Artificial Analysis
Comparaison des prix
Sur les tarifs Novita :
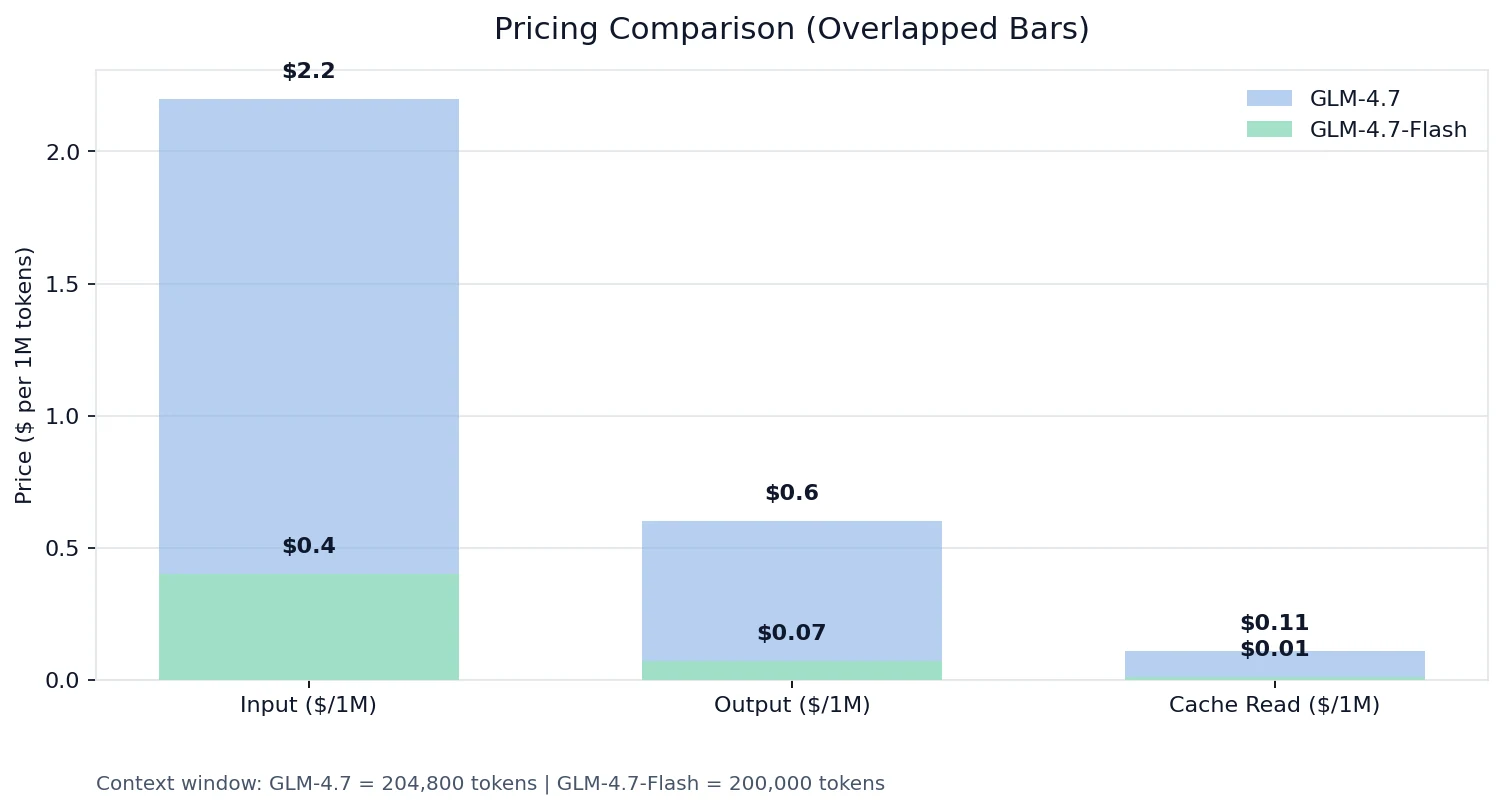
La réalité des « gammes différentes »
- Tokens d’entrée : GLM-4.7 est ~8,6× Flash
- Tokens de sortie : GLM-4.7 est 5,5× Flash
- Lecture de cache : GLM-4.7 est 11× Flash
Si vous développez quoi que ce soit avec un volume de demandes élevé, un long contexte ou des schémas d’outils qui se répètent, l’économie de Flash + les tarifs de lecture de cache peuvent changer toute votre courbe de coûts.
Quand utiliser quel modèle
GLM-4.7 et GLM-4.7-Flash ne sont pas de la même gamme – ils sont conçus pour des cibles différentes : GLM-4.7 = qualité et raisonnement maximaux, Flash = débit scalable et économie unitaire.
Choisissez GLM-4.7 lorsque la qualité est le produit
Utilisez-le pour :
- Raisonnement approfondi / tâches complexes : logique multi-étapes, mathématiques, planification difficile, documents d’architecture et de conception
- Génération priorisant la qualité : rédaction longue, copies marketing premium, traduction sensible au ton
- Aide à la décision à haut risque : décisions juridiques/médicales/financières/ingénierie (nécessite toujours une revue humaine)
Bon indicateur : si les erreurs sont coûteuses, ou si vous préférez payer plus plutôt que de réexécuter/réparer les sorties, choisissez GLM-4.7.
Choisissez GLM-4.7-Flash lorsque l’échelle est le produit
Utilisez-le pour :
- Tâches quotidiennes : chat, Q&R basiques, réécriture, formatage, étiquetage/classification, extraction d’informations
- Charges de travail à haute concurrence : bots de support client, chat en temps réel, traitement par lots, appels API haute fréquence
- Environnements sensibles aux coûts : MVPs, produits à grand nombre d’utilisateurs, CI/tests, dev/staging
Bon indicateur : si vous vous souciez du coût par demande, du débit et d’une qualité « suffisamment bonne » à grande échelle, choisissez Flash.
| Dimension | Utiliser GLM-4.7 | Utiliser GLM-4.7-Flash |
| Complexité des tâches | Élevée | Faible à moyenne |
| Tolérance à l’exactitude | Stricte | Certaines erreurs acceptables |
| Budget | Confortable | Le contrôle des coûts est essentiel |
| Concurrence | Faible à moyenne | Élevée |
Démarrage rapide : Essayez les deux modèles instantanément dans le Playground Novita
Le moyen le plus rapide de sentir la différence entre GLM-4.7 et GLM-4.7-Flash est le Playground Novita AI – pas de code, pas de configuration.
Dans le Playground, vous pouvez :
- Changez de modèle instantanément entre
zai-org/glm-4.7etzai-org/glm-4.7-flash - Exécutez le même prompt pour comparer la qualité, le style de raisonnement et la vitesse de réponse
- Validez le format de votre prompt (sorties JSON, style outil) avant de passer à l’API
Prompts de test recommandés
- Un prompt axé sur le raisonnement (pour voir le plafond de GLM-4.7)
- Un prompt « ops » à haut volume (résumé / extraction) pour voir la praticité et l’adéquation coûts de Flash
Playground Novita AI
Options de déploiement : API, SDK, intégrations tierces et déploiement local
Option A : API
Obtenir une clé API
- Étape 1 : Créez ou connectez-vous à votre compte
Visitez [**https://novita.ai**](https://novita.ai) et inscrivez-vous ou connectez-vous à votre compte existant
- Étape 2 : Accédez à la gestion des clés
Après vous être connecté, trouvez « API Keys »

- Étape 3 : Créez une nouvelle clé
Cliquez sur le bouton « Add New Key ».

- Étape 4 : Enregistrez votre clé immédiatement
Copiez et stockez la clé dès qu’elle est générée ; elle n’est généralement affichée qu’une seule fois et ne peut pas être récupérée ultérieurement. Conservez la clé dans un emplacement sécurisé tel qu’un gestionnaire de mots de passe ou des notes chiffrées.
API compatible OpenAI (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # or "zai-org/glm-4.7"
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
Option B : SDK
Si vous développez des workflows agentiques (routage, transferts, appels d’outils/fonctions), Novita fonctionne avec des SDK compatibles OpenAI avec des modifications minimales :
- Compatible drop-in : conservez votre logique client existante ; changez simplement base_url + model
- Prêt pour l’orchestration : facile à mettre en place le routage (par défaut Flash → escalade vers GLM-4.7)
- Configuration : pointez vers
https://api.novita.ai/openai, définissezNOVITA_API_KEY, sélectionnezzai-org/glm-4.7/zai-org/glm-4.7-flash
Option C : Plateformes tierces
Vous pouvez également exécuter les modèles GLM hébergés par Novita via des écosystèmes populaires :
- Frameworks d’agents et constructeurs d’applications : Suivez les guides d’intégration pas à pas de Novita pour vous connecter à des outils populaires tels que Continue, AnythingLLM, LangChain et Langflow.
- Hub Hugging Face : Novita est répertorié comme Fournisseur d’inférence sur Hugging Face, vous pouvez donc exécuter les modèles pris en charge via le workflow et l’écosystème de fournisseur de Hugging Face.
- API compatible OpenAI : Les endpoints LLM de Novita sont compatibles avec la norme d’API OpenAI, ce qui facilite la migration d’applications existantes de style OpenAI et la connexion à de nombreux outils compatibles OpenAI ( Cline, Cursor , Trae et Qwen Code) .
- API compatible Anthropic : Novita propose également un accès compatible avec le SDK Anthropic pour que vous puissiez intégrer des modèles supportés par Novita dans des workflows de codage agentique de style Claude Code.
- OpenCode : Novita AI est désormais intégré directement à OpenCode en tant que fournisseur pris en charge, donc les utilisateurs peuvent sélectionner Novita dans OpenCode sans configuration manuelle.
Option D : Déploiement local et privé
GLM-4.7-Flash est généralement le choix le plus pratique pour le déploiement local/privé car il est plus léger et plus facile à exécuter sur des clusters sur site, des VPC / clouds privés et des environnements hybrides. Il fonctionne particulièrement bien pour les besoins de conformité/résidence des données, les applications internes sensibles à la latence et les charges de travail de long contexte/agentiques avec des budgets GPU fixes.
Une configuration courante est :
- Exécuter Flash localement pour le trafic à haut volume
- Escalader vers GLM-4.7 (hébergé) pour les demandes complexes ou à haut risque
GLM-4.7 peut également être déployé localement, mais il est généralement réservé aux équipes disposant d’une capacité GPU importante et d’une maturité opérationnelle, principalement pour les systèmes internes critiques pour la qualité et à débit faible. Pour une utilisation interne large, Flash reste le choix par défaut.
💡Même si l’exécution de GLM-4.7 sur site est trop coûteuse, vous pouvez toujours l’utiliser en production via l’API hébergée de Novita, ou l’exécuter sur l’infrastructure GPU Novita pour éviter la charge matérielle et opérationnelle initiale.
Conclusion
La comparaison GLM-4.7 vs GLM-4.7-Flash n’est pas un concours équitable de « quel est le meilleur » – car ils sont conçus pour des tâches différentes. Utilisez GLM-4.7 lorsque vous avez besoin du plafond le plus élevé pour le raisonnement, le codage et la fiabilité agentique. Utilisez GLM-4.7-Flash lorsque vous avez besoin d’un modèle performant que vous pouvez réellement mettre à l’échelle – rentable, déployable et très compétitif dans sa gamme d’efficacité.
Le meilleur modèle de production est généralement hybride : utilisez Flash par défaut pour le volume, et routez les demandes complexes ou à haut risque vers GLM-4.7. Avec le Playground de Novita et les API compatibles OpenAI, vous pouvez tester les deux en quelques minutes et déployer la stratégie de routage sans modifier votre stack.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle.
Foire aux questions
Qu’est-ce que GLM-4.7-Flash ?
GLM-4.7-Flash est un modèle de langage large de classe 30B de type Mixture-of-Experts (MoE) développé par Zhipu AI, conçu pour offrir des performances élevées en raisonnement, codage et agentique avec une grande efficacité et une faible latence.
Combien coûte GLM-4.7-Flash ?
Sur Novita AI (sans serveur), GLM-4.7-Flash est tarifé à 0,07 $ par million de tokens d’entrée, 0,01 $ par million de tokens de lecture en cache et 0,40 $ par million de tokens de sortie, ce qui le rend rentable pour les charges de travail à long contexte et haut débit.
Quelle est la relation entre GLM-4.7-Flash et GLM-4.7 ?
GLM-4.7-Flash et GLM-4.7 appartiennent à la même famille de modèles mais ciblent des gammes différentes : GLM-4.7 est le modèle flagship optimisé pour une qualité de raisonnement maximale, tandis que GLM-4.7-Flash est une variante plus légère et rentable conçue pour un déploiement scalable et à haut volume.



