

もし GLM-4.7 と GLM-4.7-Flash を互換性があるかのように比較しているなら、間違ったものを最適化することになります。
これら2つのモデルは、設計上 同じ階層ではありません。
- GLM-4.7 は フラッグシップ推論モデル です。最高品質 を重視し、トークンコストが高くても許容できる場合に選択します。
- GLM-4.7-Flash は 軽量でコスト効率の高い「ワークホース」 です。スループット、単価経済性、大規模な長文脈の実用性 を重視する場合に選択します。
Novita では、透明な価格設定、API、そして簡単な Playground を使用して、両方をすぐに試すことができます。
実際に比較しているもの:フラッグシップ推論とスケーラブルな効率性
GLM-4.7: フラッグシップ推論モデル
GLM-4.7 は、主要な 推論ファースト モデル(全体的な知能が高い)として位置づけられており、長い文脈と高速生成を備えていますが、トークンあたりのコストは Flash よりも はるかに高くなります。
GLM-4.7-Flash: スケーラブルなMoE「エージェント/コーディングワークホース」
GLM-4.7-Flash は 効率性(30B-A3B MoE クラス)を中心に構築されており、エージェンティックコーディングやツールワークフロー、高いスループットと予測可能なコスト が求められる長文脈タスクを対象としています。
ベンチマーク比較
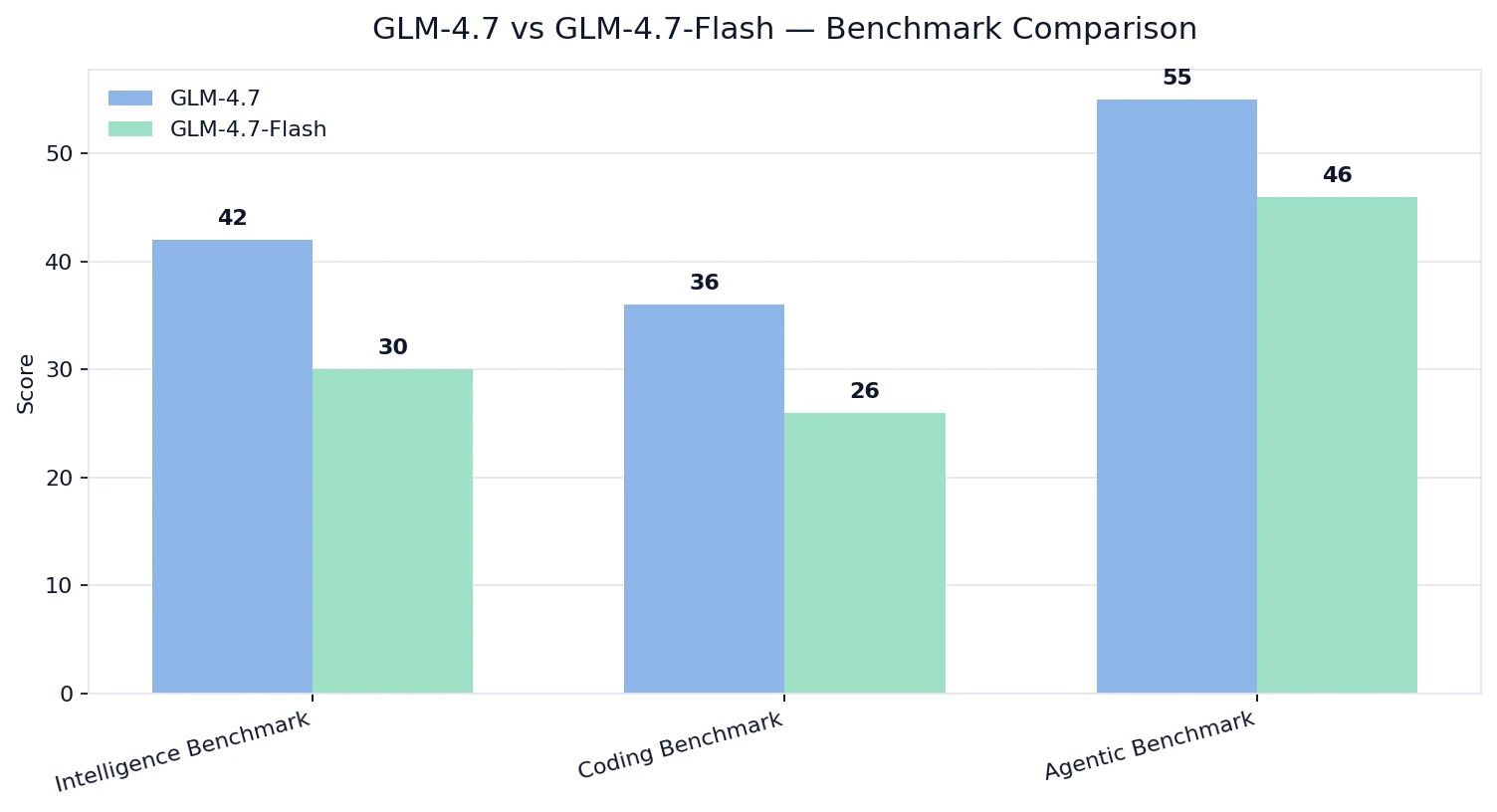
💡解釈:
- GLM-4.7 は品質で勝利:インテリジェンス、コーディング、エージェント能力すべてにおいて優れています。
- GLM-4.7-Flash も強力ですが、最適化ターゲットが異なります:コスト+デプロイ容易性+実用的スループット。
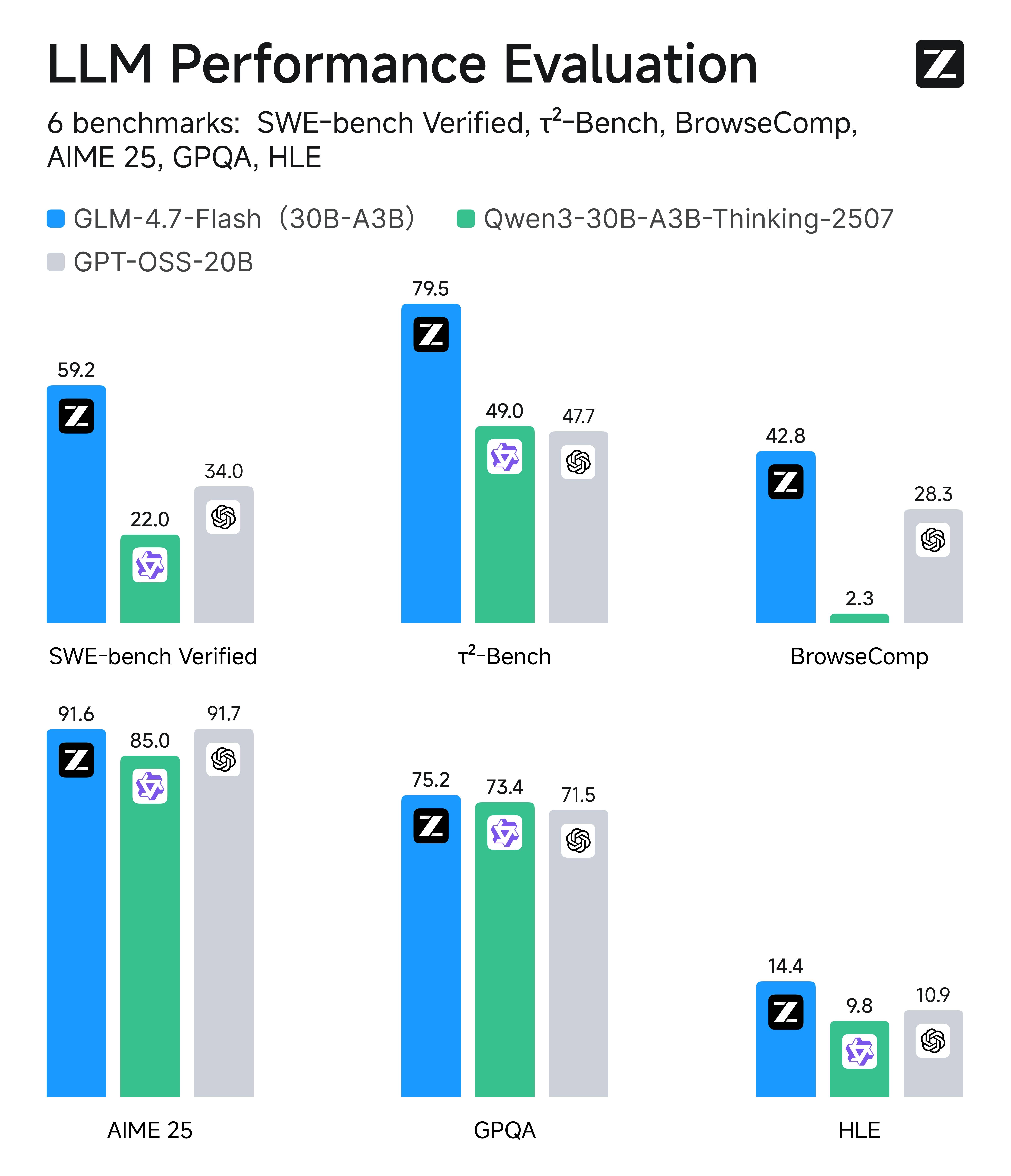
クラス最高の効率性:GLM-4.7-Flash と同サイズの競合との比較
ただし、見落としがちなのは、GLM-4.7-Flash は自身の効率クラス内でトップパフォーマー(おおよそ20B~30B MoE / 軽量モデル)であることです。コーディング、エージェント/ツール使用、ブラウジング形式のタスク、数学、知識推論にわたる6つの実世界評価での比較において、Flash は 同サイズの代替モデルの中で一貫してトップまたはそれに近い位置 にランクインしており、まさに大量生産システムのデフォルト選択として理にかなっている理由です。
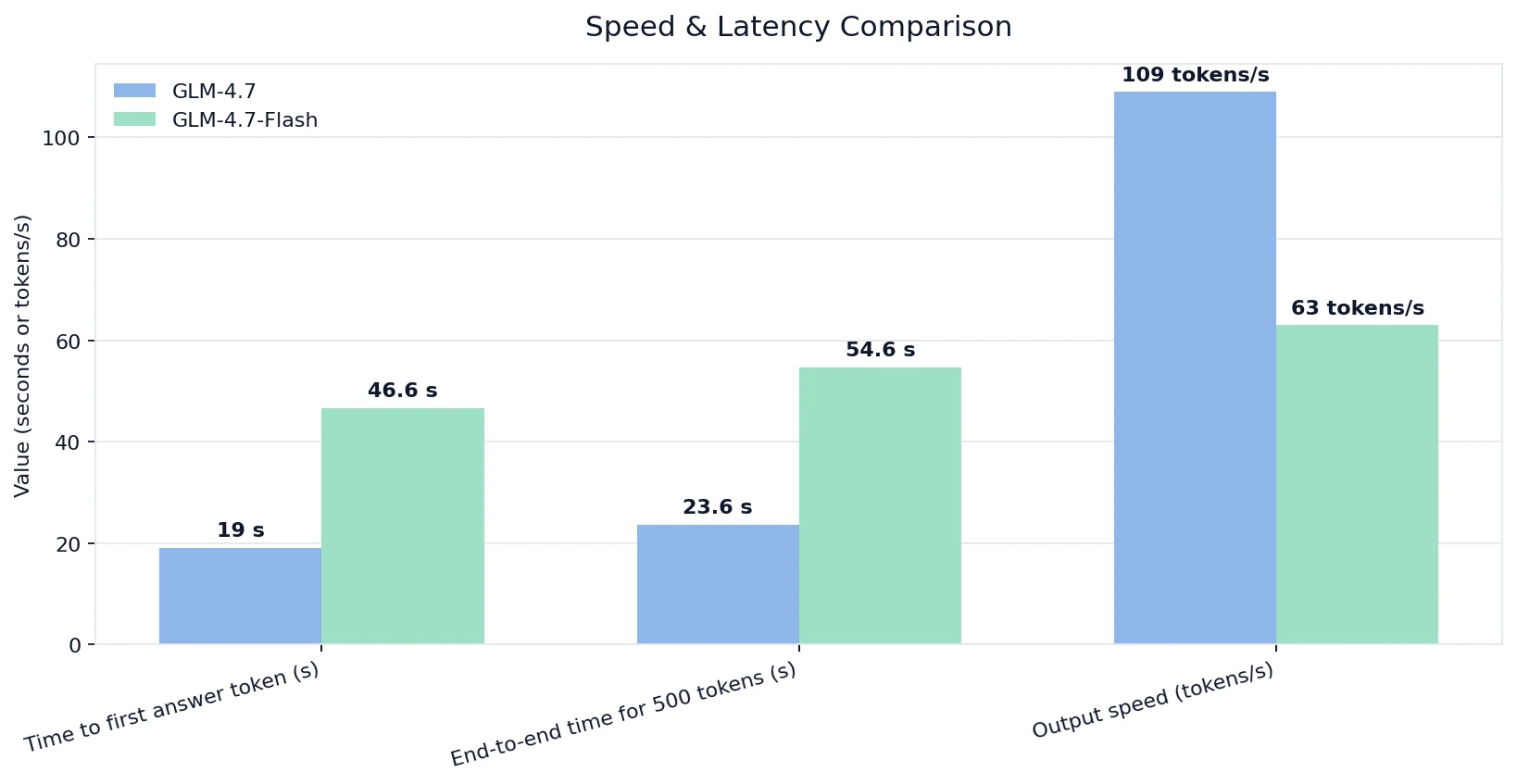
速度とレイテンシの比較
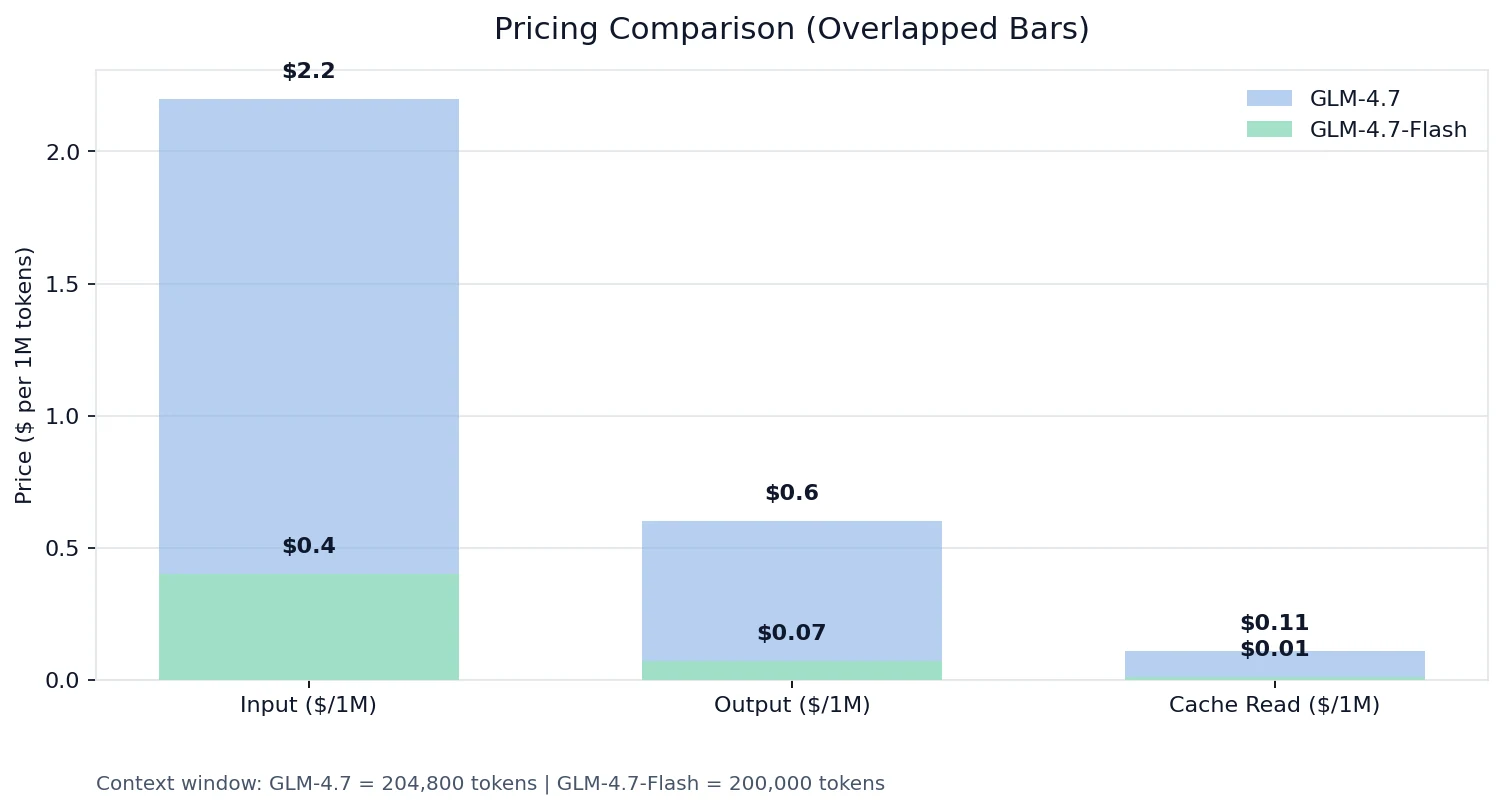
価格比較
Novita の価格設定 では:
「同じ階層ではない」という現実
- 入力トークン:GLM-4.7 は Flash の約 8.6倍
- 出力トークン:GLM-4.7 は 5.5倍
- キャッシュ読み取り:GLM-4.7 は 11倍
リクエスト数が多い、長い文脈、または繰り返されるツールスキーマを使用する構築を行っている場合、Flash の経済性とキャッシュ読み取り価格設定により、コスト曲線全体が変わります。
どのモデルをいつ使用すべきか
GLM-4.7 と GLM-4.7-Flash は同じ階層ではありません。異なるターゲット向けに構築されています:GLM-4.7 = 最大品質と推論、Flash = スケーラブルなスループットと単価経済性。
品質が製品である場合、GLM-4.7 を選択
以下の用途に使用します:
- 深い推論/複雑なタスク: 多段階論理、数学、難しい計画、アーキテクチャおよび設計文書
- 品質優先の生成: 長文作成、プレミアムマーケティングコピー、トーンに敏感な翻訳
- 高いステークスの意思決定支援: 法律/医療/金融/工学の意思決定(依然として人間のレビューが必要)
良い指標:間違いが高くつく場合、または出力を再実行/修正するよりもコストをかけるほうがよい場合は、GLM-4.7 を選びましょう。
スケールが製品である場合、GLM-4.7-Flash を選択
以下の用途に使用します:
- 日常的なタスク: チャット、基本的なQ&A、リライト、フォーマット、タグ付け/分類、情報抽出
- 高並行処理ワークロード: カスタマーサポートボット、リアルタイムチャット、バッチ処理、高頻度API呼び出し
- コスト重視の環境: MVP、大規模ユーザー製品、CI/テスト、開発/ステージング
良い指標:リクエストあたりのコスト、スループット、およびボリュームでの「十分な」品質を重視する場合は、Flash を選びましょう。
| 観点 | GLM-4.7を使用 | GLM-4.7-Flashを使用 |
| タスクの複雑さ | 高い | 低~中 |
| 精度許容度 | 厳格 | ある程度の誤差は許容 |
| 予算 | 余裕がある | コスト管理が重要 |
| 同時実行性 | 低~中 | 高い |
クイックスタート:Novita Playground で両モデルをすぐに試す
GLM-4.7 と GLM-4.7-Flash の違いを 実感 する最速の方法は、Novita AI Playground を使用することです。コードもセットアップも不要です。
Playground では、以下のことが可能です:
- モデルを即座に切り替え
zai-org/glm-4.7とzai-org/glm-4.7-flashの間で - 同じプロンプトを実行して、品質、推論スタイル、応答速度を比較
- API に移行する前にプロンプト形式(JSON、ツール形式の出力)を検証
推奨テストプロンプト
- 推論を多用するプロンプト(GLM-4.7 の限界を確認)
- 大量運用向けの「運用」プロンプト(要約/抽出)で Flash の実用性とコスト適合性を確認
Novita AI Playground
デプロイオプション:API、SDK、サードパーティ統合、ローカルデプロイ
オプション A: API
API キーを取得
- 手順 1: アカウントを作成またはログイン
[**https://novita.ai**](https://novita.ai) にアクセスし、サインアップ するか、既存のアカウントにログインします
- 手順 2: キー管理に移動
ログイン後、「API Keys」を見つけます

- 手順 3: 新しいキーを作成
「Add New Key」ボタンをクリックします。

- 手順 4: キーをすぐに保存
キーが生成されたらすぐにコピーして保存します。通常は一度だけ表示され、後で取得することはできません。パスワードマネージャーや暗号化メモなどの安全な場所にキーを保管してください。
OpenAI 互換 API (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # or "zai-org/glm-4.7"
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
オプション B: SDK
エージェンティックワークフロー(ルーティング、ハンドオフ、ツール/関数呼び出し)を構築している場合、Novita は最小限の変更で OpenAI 互換 SDK と連携します:
- ドロップイン互換: 既存のクライアントロジックを維持し、base_url と model を変更するだけ
- オーケストレーション対応: ルーティングの実装が容易(Flash デフォルト → GLM-4.7 エスカレーション)
- セットアップ:
https://api.novita.ai/openaiを指定し、NOVITA_API_KEYを設定し、zai-org/glm-4.7またはzai-org/glm-4.7-flashを選択
オプション C: サードパーティプラットフォーム
人気のエコシステムを通じて Novita ホストの GLM モデルを実行することもできます:
- エージェントフレームワーク&アプリビルダー: Novita のステップバイステップの統合ガイドに従って、Continue、AnythingLLM、LangChain、Langflow などの人気ツールと接続します。
- Hugging Face Hub: Novita は Hugging Face で Inference Provider としてリストされているため、Hugging Face のプロバイダーワークフローとエコシステムを通じてサポートされているモデルを実行できます。
- OpenAI 互換 API: Novita の LLM エンドポイントは OpenAI API 標準と互換性があり、既存の OpenAI スタイルのアプリを移行し、多くの OpenAI 互換ツール(Cline、Cursor、Trae、Qwen Code)と接続するのが容易です。
- Anthropic 互換 API: Novita は Anthropic SDK 互換アクセスも提供しており、Novita 対応モデルを Claude Code スタイルのエージェンティックコーディングワークフローに統合できます。
- OpenCode: Novita AI は現在、サポートされているプロバイダーとして OpenCode に直接統合されており、ユーザーは手動設定なしで OpenCode で Novita を選択できます。
オプション D: ローカル&プライベートデプロイ
GLM-4.7-Flash は通常、ローカル/プライベートデプロイにとってより実用的な選択肢です。軽量で、オンプレミスクラスター、VPC/プライベートクラウド、ハイブリッド環境で実行しやすいためです。特に、コンプライアンス/データ居住要件、レイテンシに敏感な内部アプリケーション、および固定 GPU 予算下での長文脈/エージェントワークロードに適しています。
一般的なセットアップは次のとおりです:
- Flash をローカルで実行して大量トラフィックを処理
- 複雑またはハイステークスなリクエストは、GLM-4.7(ホスト)にエスカレーション
GLM-4.7 もローカルにデプロイ可能ですが、通常は 強力な GPU 容量と運用成熟度 を持つチーム向けであり、主に 品質重視でスループットが低い 内部システムに使用されます。広範な内部使用には、Flash がデフォルトのままです。
💡GLM-4.7 をオンプレミスで実行するコストが高すぎる場合でも、Novita のホスト API を介して本番環境で使用するか、Novita GPU インフラストラクチャ で実行して、初期のハードウェアと運用の負担を回避できます。
まとめ
GLM-4.7 vs GLM-4.7-Flash は「どちらが優れているか」という公平な比較ではありません。異なる仕事のために構築されているからです。 推論、コーディング、エージェントの信頼性において最高の上限が必要な場合は GLM-4.7 を使用します。実際にスケール可能な強力なモデルが必要な場合(コスト効率が高く、デプロイ可能で、効率クラス内で非常に競争力がある)は GLM-4.7-Flash を使用します。
最良の本番パターンは通常ハイブリッドです:大量トラフィックはデフォルトで Flash に、複雑またはハイステークスなリクエストは GLM-4.7 にルーティングします。Novita の Playground と OpenAI 互換 API を使用すれば、両方を数分でテストし、スタックを変更せずにルーティング戦略を出荷できます。
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、同時に構築とスケーリングのための手頃で信頼性の高い GPU クラウドを提供します。
よくある質問
GLM-4.7-Flash とは何ですか?
GLM-4.7-Flash は、Zhipu AI によって開発された30Bクラスの Mixture-of-Experts (MoE) 大規模言語モデルであり、高い効率性と低レイテンシで強力な推論、コーディング、エージェント性能を提供するように設計されています。
GLM-4.7-Flash のコストはいくらですか?
Novita AI(サーバーレス)では、GLM-4.7-Flash の料金は 入力トークン $0.07/M、キャッシュ読み取りトークン $0.01/M、出力トークン $0.40/M であり、大規模なコンテキストと高スループットのワークロードにコスト効率が高くなっています。
GLM-4.7-Flash と GLM-4.7 の関係は?
GLM-4.7-Flash と GLM-4.7 は同じモデルファミリーに属しますが、異なる階層を対象としています:GLM-4.7 は最大の推論品質向けに最適化されたフラッグシップモデルであり、GLM-4.7-Flash はスケーラブルで大量デプロイ向けに設計された軽量でコスト効率の高いバリアントです。



