

If you’re comparing GLM-4.7 and GLM-4.7-Flash as if they’re interchangeable, you’ll end up optimizing the wrong thing.
These two models are not in the same tier by design:
- GLM-4.7 is a flagship reasoning model—you pick it when you care about maximum quality and can justify higher token cost.
- GLM-4.7-Flash is a lighter, cost-efficient “workhorse”—you pick it when you care about throughput, unit economics, and long-context practicality at scale.
On Novita, you can run both with transparent pricing, APIs, and an easy Playground to decide quickly.
What You’re Actually Comparing: Flagship Reasoning vs Scalable Efficiency
GLM-4.7: the flagship reasoning model
GLM-4.7 is positioned as a leading reasoning-first model (strong overall intelligence), with long context and fast generation—but it’s also much more expensive per token than Flash.
GLM-4.7-Flash: the scalable MoE “agent/coding workhorse”
GLM-4.7-Flash is built around efficiency (30B-A3B MoE class), targeting agentic coding + tool workflows and long-context tasks where you need high throughput and predictable cost.
Benchmarks Comparison
Artificial Analysis Intelligence / Coding / Agentic indices
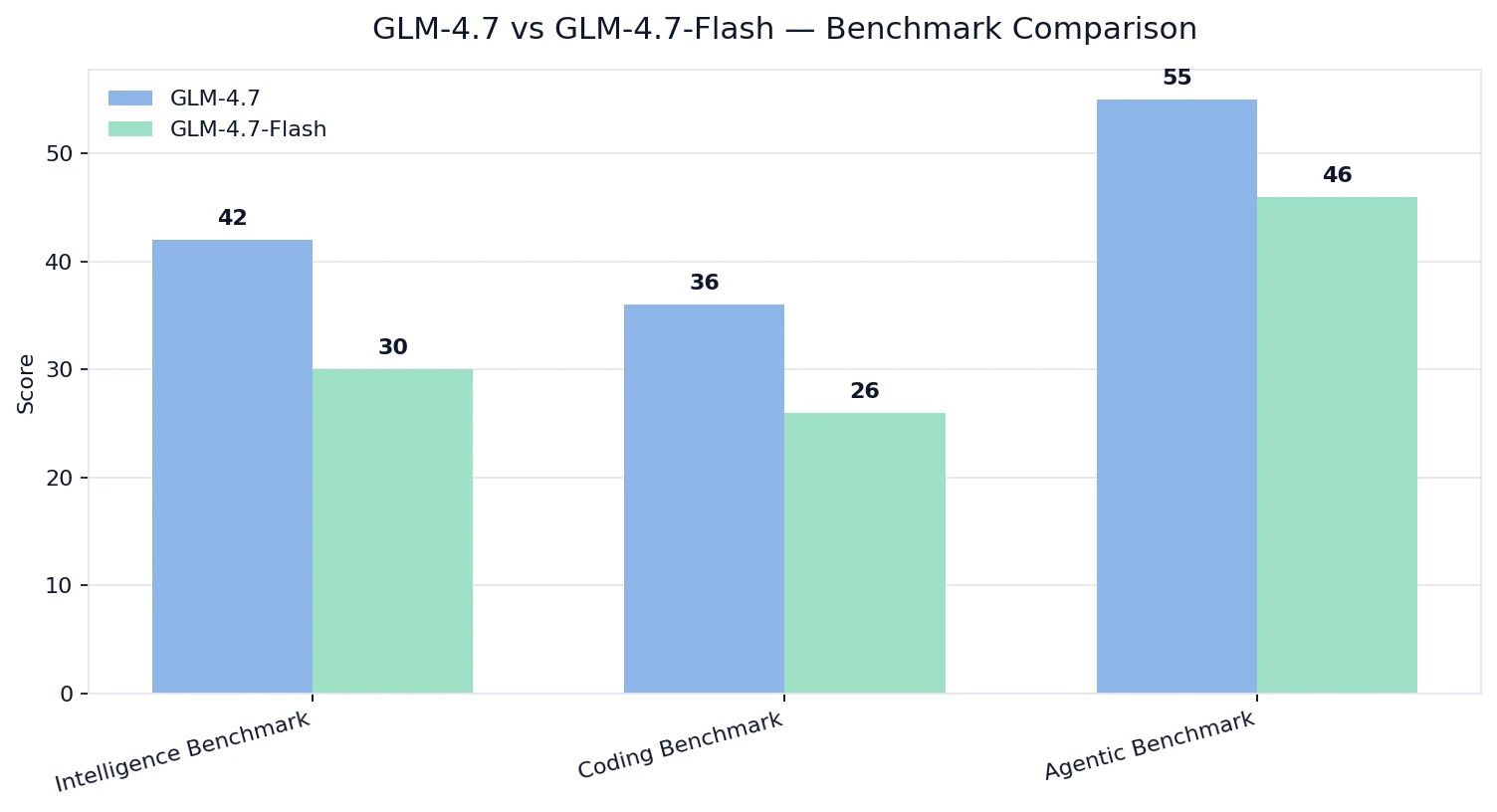
From Artificial Analysis
💡Interpretation:
- GLM-4.7 wins on quality across intelligence/coding/agentic capability.
- GLM-4.7-Flash is still strong, but it’s tuned for a different optimization target: cost + deployability + practical throughput.
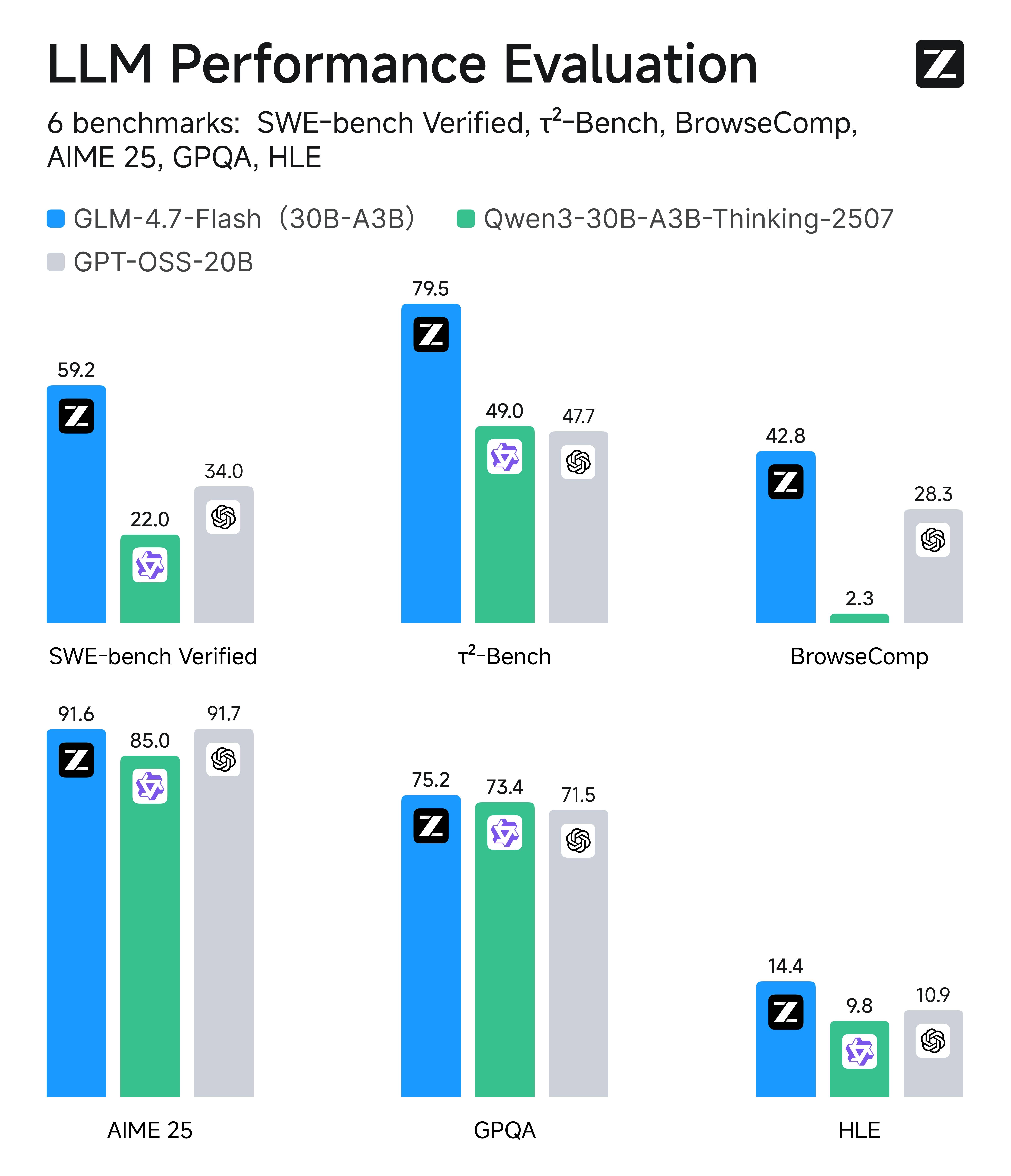
Top-in-Class Efficiency: GLM-4.7-Flash vs Similar-Size Peers
What’s easy to miss, though, is that GLM-4.7-Flash is a top performer within its own efficiency class (roughly 20B–30B MoE / lightweight models). In peer comparisons across six real-world evaluations—spanning coding, agent/tool use, browsing-style tasks, math, and knowledge reasoning—Flash consistently ranks at or near the top among similarly sized alternatives, which is exactly why it makes sense as the default choice for high-volume production systems.
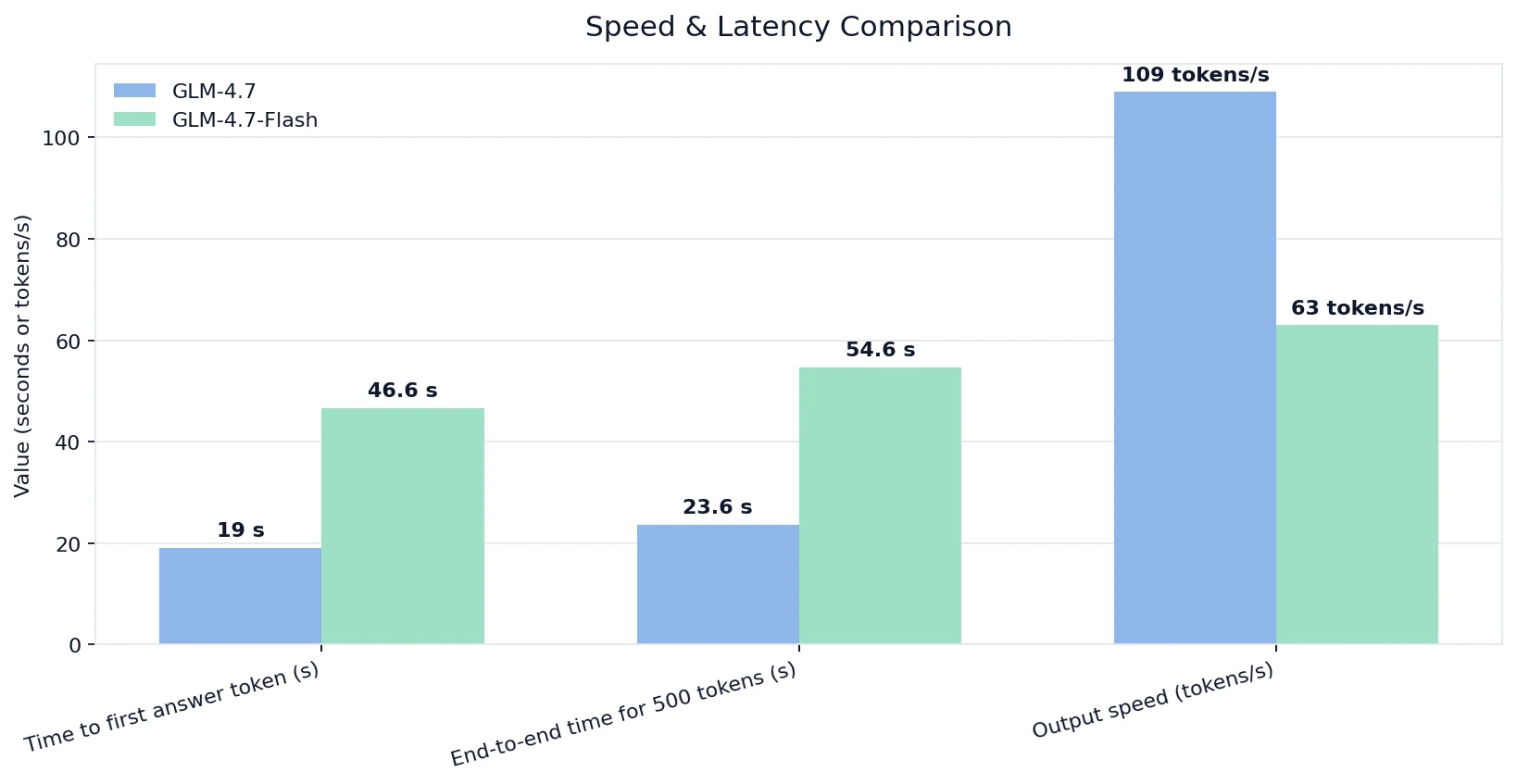
Speed & Latency Comparison
From Artificial Analysis
Price Comparison
On Novita pricing:
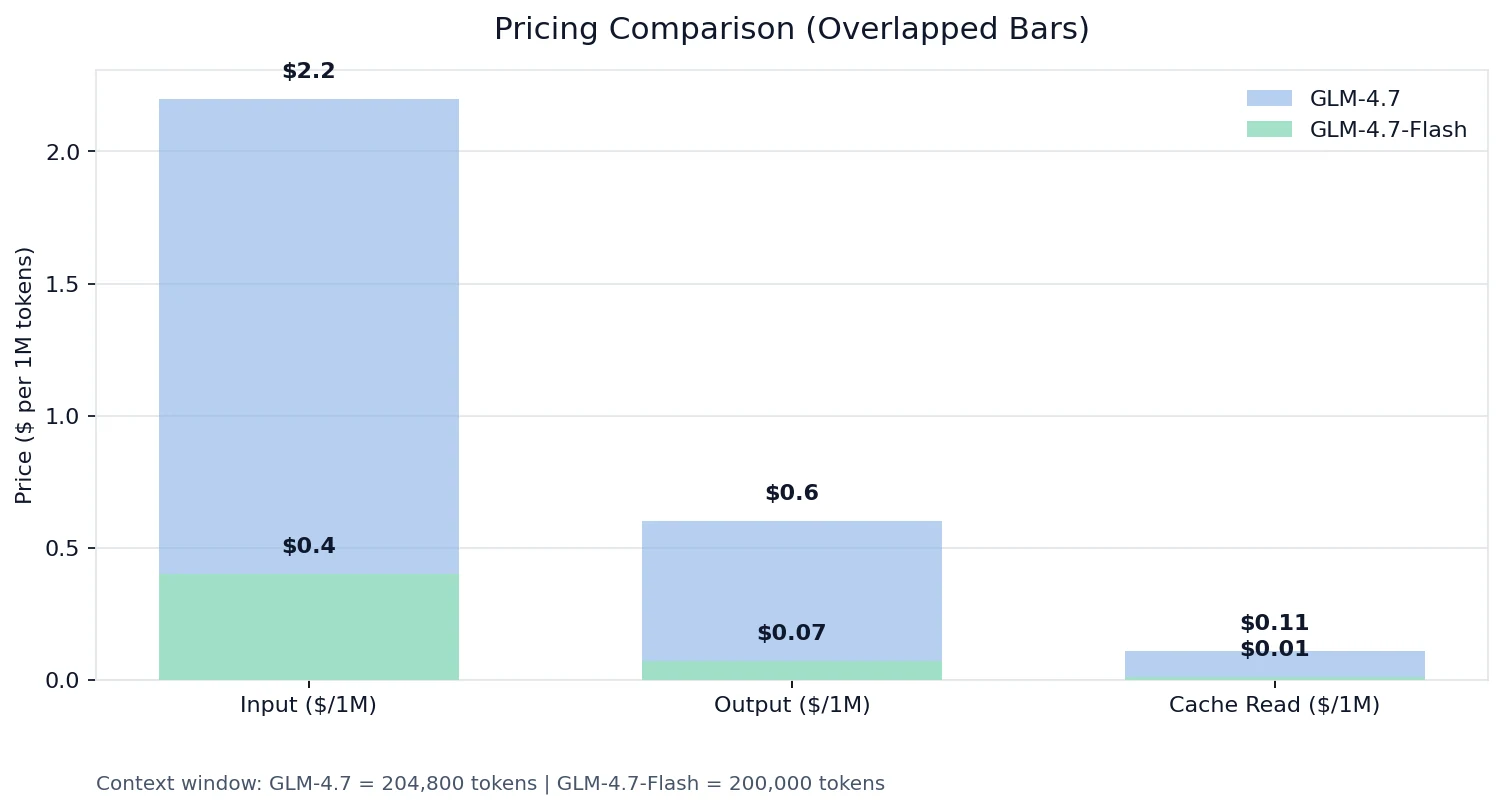
The “not the same tier” reality
- Input tokens: GLM-4.7 is ~8.6× Flash
- Output tokens: GLM-4.7 is 5.5× Flash
- Cache read: GLM-4.7 is 11× Flash
If you’re building anything with high request volume, long context, or tool schemas that repeat, Flash’s economics + cache read pricing can change your entire cost curve.
When to Use Which Model
GLM-4.7 and GLM-4.7-Flash are not the same tier—they’re built for different targets: GLM-4.7 = maximum quality and reasoning, Flash = scalable throughput and unit economics.
Choose GLM-4.7 when quality is the product
Use it for:
- Deep reasoning / complex tasks: multi-step logic, math, hard planning, architecture & design docs
- Quality-first generation: long-form writing, premium marketing copy, tone-sensitive translation
- High-stakes decision support: legal/medical/finance/engineering decisions (still requires human review)
Good signal: if mistakes are expensive, or you’d rather pay more than rerun/repair outputs, pick GLM-4.7.
Choose GLM-4.7-Flash when scale is the product
Use it for:
- Everyday tasks: chat, basic Q&A, rewriting, formatting, tagging/classification, info extraction
- High concurrency workloads: customer support bots, real-time chat, batch processing, high-frequency API calls
- Cost-sensitive environments: MVPs, large user products, CI/testing, dev/staging
Good signal: if you care about cost per request, throughput, and “good enough” quality at volume, pick Flash.
| Dimension | Use GLM-4.7 | Use GLM-4.7-Flash |
| Task complexity | High | Low to medium |
| Accuracy tolerance | Strict | Some errors acceptable |
| Budget | Comfortable | Cost control is key |
| Concurrency | Low to medium | High |
Quickstart: Try Both Models Instantly in Novita Playground
The fastest way to feel the difference between GLM-4.7 and GLM-4.7-Flash is the Novita AI Playground—no code, no setup.
In Playground, you can:
- Switch models instantly between
zai-org/glm-4.7andzai-org/glm-4.7-flash - Run the same prompt to compare quality, reasoning style, and response speed
- Validate your prompt format (JSON, tool-style outputs) before moving to API
Recommended test prompts
- A reasoning-heavy prompt (to see GLM-4.7’s ceiling)
- A high-volume “ops” prompt (summarization / extraction) to see Flash’s practicality and cost-fit
Novita AI Playground
Deploy Options: API, SDK, Third-Party Integrations and Local Deployment
Option A: API
Get an API Key
- Step 1: Create or Login to Your Account
Visit [**https://novita.ai**](https://novita.ai) and sign up or log in to your existing account
- Step 2: Navigate to Key Management
After logging in, find “API Keys”

- Step 3: Create a New Key
Click the “Add New Key” button.

- Step 4: Save Your Key Immediately
Copy and store the key as soon as it is generated; it is usually shown only once and cannot be retrieved later. Keep the key in a secure location such as a password manager or encrypted notes
OpenAI-Compatible API (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # or "zai-org/glm-4.7"
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)Option B: SDK
If you’re building agentic workflows (routing, handoffs, tool/function calls), Novita works with OpenAI-compatible SDKs with minimal changes:
- Drop-in compatib le: keep your existing client logic; just change base_url + model
- Orchestration-ready: easy to implement routing (Flash default → GLM-4.7 escalation)
- Setup: point to
https://api.novita.ai/openai, setNOVITA_API_KEY, selectzai-org/glm-4.7/zai-org/glm-4.7-flash
Option C: Third-Party Platforms
You can also run Novita-hosted GLM models through popular ecosystems:
- Agent frameworks & app builders: Follow Novita’s step-by-step integration guides to connect with popular tooling such as Continue, AnythingLLM, LangChain, and Langflow.
- Hugging Face Hub: Novita is listed as an Inference Provider on Hugging Face, so you can run supported models through Hugging Face’s provider workflow and ecosystem.
- OpenAI-compatible API: Novita’s LLM endpoints are compatible with the OpenAI API standard, making it easy to migrate existing OpenAI-style apps and connect many OpenAI-compatible tools ( Cline, Cursor , Trae and Qwen Code) .
- Anthropic-compatible API: Novita also provides Anthropic SDK–compatible access so you can integrate Novita-backed models into Claude Code style agentic coding workflows.
- OpenCode: Novita AI is now integrated directly into OpenCode as a supported provider, so users can select Novita in OpenCode without manual configuration.
Option D: Local & Private Deployment
GLM-4.7-Flash is usually the more practical choice for local/private deployment because it’s lighter and easier to run across on-prem clusters, VPC /private clouds, and hybrid environments. It works especially well for compliance/data-residency needs, latency-sensitive internal apps, and long-context/agentic workloads under fixed GPU budgets.
A common setup is:
- Run Flash locally for high-volume traffic
- Escalate to GLM-4.7 (hosted) for complex or high-stakes requests
GLM-4.7 can also be deployed locally, but it’s typically reserved for teams with strong GPU capacity and ops maturity, mainly for quality-critical, lower-throughput internal systems. For broad internal usage, Flash remains the default.
💡Even if running GLM-4.7 on-prem is too costly, you can still use it in production via Novita’s hosted API, or run it on Novita GPU infrastructure to avoid the upfront hardware and ops burden.
Conclusion
GLM-4.7 vs GLM-4.7-Flash isn’t a fair “which is better” contest—because they’re built for different jobs. Use GLM-4.7 when you need the highest ceiling for reasoning, coding, and agentic reliability. Use GLM-4.7-Flash when you need a strong model you can actually scale—cost-efficient, deployable, and highly competitive within its efficiency tier.
The best production pattern is usually hybrid: default to Flash for volume, and route complex or high-stakes requests to GLM-4.7. With Novita’s Playground and OpenAI-compatible APIs, you can test both in minutes and ship the routing strategy without changing your stack.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Frequently Asked Questions
What is GLM-4.7-Flash?
GLM-4.7-Flash is a 30B-class Mixture-of-Experts (MoE) large language model developed by Zhipu AI, designed to deliver strong reasoning, coding, and agentic performance with high efficiency and low latency.
How much does GLM-4.7-Flash cost?
On Novita AI (serverless), GLM-4.7-Flash is priced at $0.07/M input tokens, $0.01/M cached read tokens, and $0.40/M output tokens, making it cost-effective for large-context and high-throughput workloads.
What is the relationship between GLM-4.7-Flash and GLM-4.7?
GLM-4.7-Flash and GLM-4.7 belong to the same model family but target different tiers: GLM-4.7 is the flagship model optimized for maximum reasoning quality, while GLM-4.7-Flash is a lighter, cost-efficient variant designed for scalable, high-volume deployment.



