

MiniMax M2.5 is one of the fastest, most cost-effective AI coding agents available — and with Novita AI, you can access it for just $0.30/$1.20 per 1M tokens. Achieving 80.2% on SWE-Bench Verified and 51.3% on Multi-SWE-Bench, M2.5 delivers SOTA coding performance while completing tasks 37% faster than M2.1 — matching Claude Opus 4.6’s speed at a fraction of the cost.
This guide shows you exactly how to access MiniMax M2.5 through Novita AI’s OpenAI-compatible API, deploy it for production workloads, and maximize its unique strengths in agentic coding, tool use, and office automation.
Try Powerful and Affordable Minimax M2.5 Now!
What Is MiniMax M2.5?
MiniMax M2.5 is a 228.7B-parameter mixture-of-experts (MoE) model specifically trained for real-world productivity tasks. Built with 256 experts and 8 experts activated per token, it delivers frontier-level performance in coding, agentic tool use, web search, and office automation while maintaining extreme inference efficiency.
Architecture of Minimax M2.5
| Specification | MiniMax M2.5 |
|---|---|
| Total Parameters | 229B |
| Architecture | Mixture-of-Experts (MoE) |
| Number of Experts | 256 total, 8 active per token |
| Context Length | 196,608 tokens (~196K) |
| Hidden Size | 3072 |
| Layers | 62 |
| Vocabulary Size | 200,064 |
Benchmark of Minimax M2.5
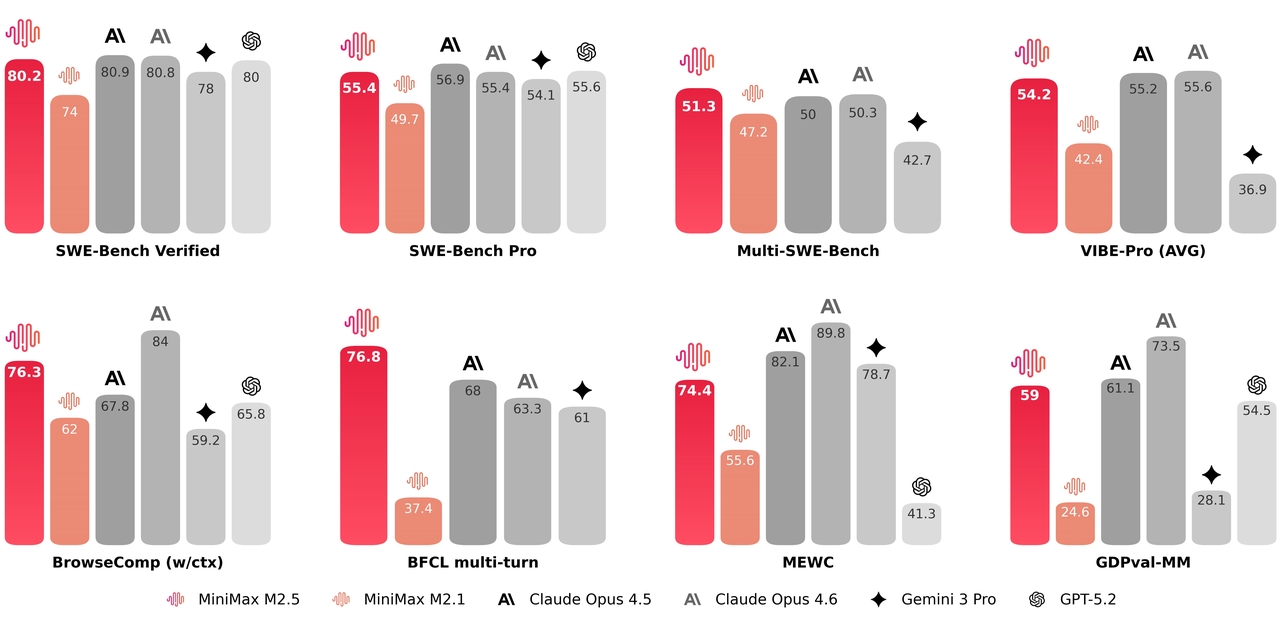
MiniMax M2.5 achieves state-of-the-art results across coding, agentic tasks, and office automation benchmarks — matching or exceeding models 3-5x more expensive. The model was trained with reinforcement learning in 200,000+ real-world environments, giving it unmatched generalization on practical tasks.
Coding and Agentic & Tool Use
From HuggingFace
From HuggingFace
MiniMax M2.5 does not dominate every benchmark, but it maintains consistently strong results across simulation, retrieval, and multi-turn reasoning tasks. Its profile suggests:
- Strong agent-style task coordination
- Robust retrieval and search integration
- Stable multi-turn reasoning
- Competitive structured environment simulation
Overall, MiniMax M2.5 appears optimized for applied agentic workflows and complex multi-step execution rather than purely academic reasoning benchmarks.
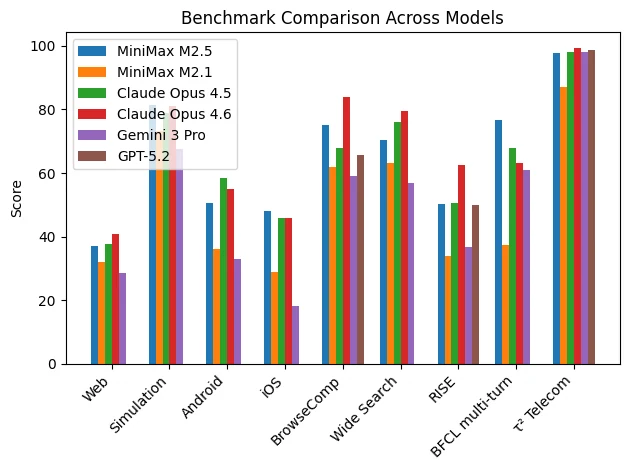
Office Automation
MiniMax M2.5 is not designed to dominate abstract academic reasoning benchmarks or pure mathematical competitions. Its strength lies in professional office execution tasks, especially those requiring structured, deliverable outputs.
| Benchmark | MiniMax M2.5 | MiniMax M2.1 | Claude Opus 4.5 | Claude Opus 4.6 | Gemini 3 Pro | GPT-5.2 |
|---|---|---|---|---|---|---|
| GDPval-MM | 59.0 | 24.6 | 61.1 | 73.5 | 28.1 | 54.5 |
| MEWC | 74.4 | 55.6 | 82.1 | 89.8 | 78.7 | 41.3 |
| Finance Modeling | 21.6 | 17.3 | 30.1 | 33.2 | 15.0 | 20.0 |
Try Powerful and Affordable Minimax M2.5 Now!
Speed of Minimax M2.5
Why M2.5’s Speed Matters: Completing SWE-Bench 37% faster than M2.1 means lower API costs AND faster iteration cycles. For a typical multi-file refactoring task, M2.5 finishes in 45 seconds vs M2.1’s 70 seconds — saving both time and money at scale.
Why MiniMax M2.5 on Novita AI?
Novita AI offers the best cost-performance trade-off for running MiniMax M2.5 in production. While self-hosting requires 4-8 H100 GPUs (minimum $5.80/hr), Novita’s serverless API costs just $0.30 input / $1.20 output per 1M tokens — with zero infrastructure overhead, instant scaling, and 99.5% uptime SLA.
Key advantages of Novita AI for MiniMax M2.5:
| Feature | Novita AI | Self-Hosted |
|---|---|---|
| Setup Time | 2 minutes (API key) | 2-5 days (GPU provisioning + setup) |
| Cost Model | Pay-per-token ($0.30/$1.20 per 1M) | Fixed GPU rental ($5.80/hr+ for 4×H100) |
| Scaling | Instant auto-scaling | Manual GPU provisioning |
| Maintenance | Zero (managed service) | High (vLLM, drivers, updates) |
| Availability | 99.5% SLA | Depends on your infrastructure |
| Best For | Variable workloads, rapid prototyping, production APIs | 24/7 high-volume inference with predictable load |
How to Access MiniMax M2.5 on Novita AI
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Try Powerful and Affordable Minimax M2.5 Now!
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.5",
messages=[
{"role"Method 2: MiniMax Official API Platform: "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)Integrating MiniMax M2.5 with Popular Tools
Easily connect Novita AI with partner platforms like Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify, Langflow, and Openclaw through official integrations and step-by-step guides.
Use Cases: Where MiniMax M2.5 Shines
You could also try to closely test M2.5 on software engineering tasks and see how it plans and executes on a closed scope. M2.5 would output a complete spec-first plan with UI wireframes and API endpoints. With that, it will add 1200+ lines of TypeScript/JavaScript code. The tests passed on the first run in 22 minutes, which makes it faster than Claude Opus 4.6’s average. The result is a functional application with JWT auth and MongoDB integration.
Build a React app with Node.js backend for user authentication, including database schema.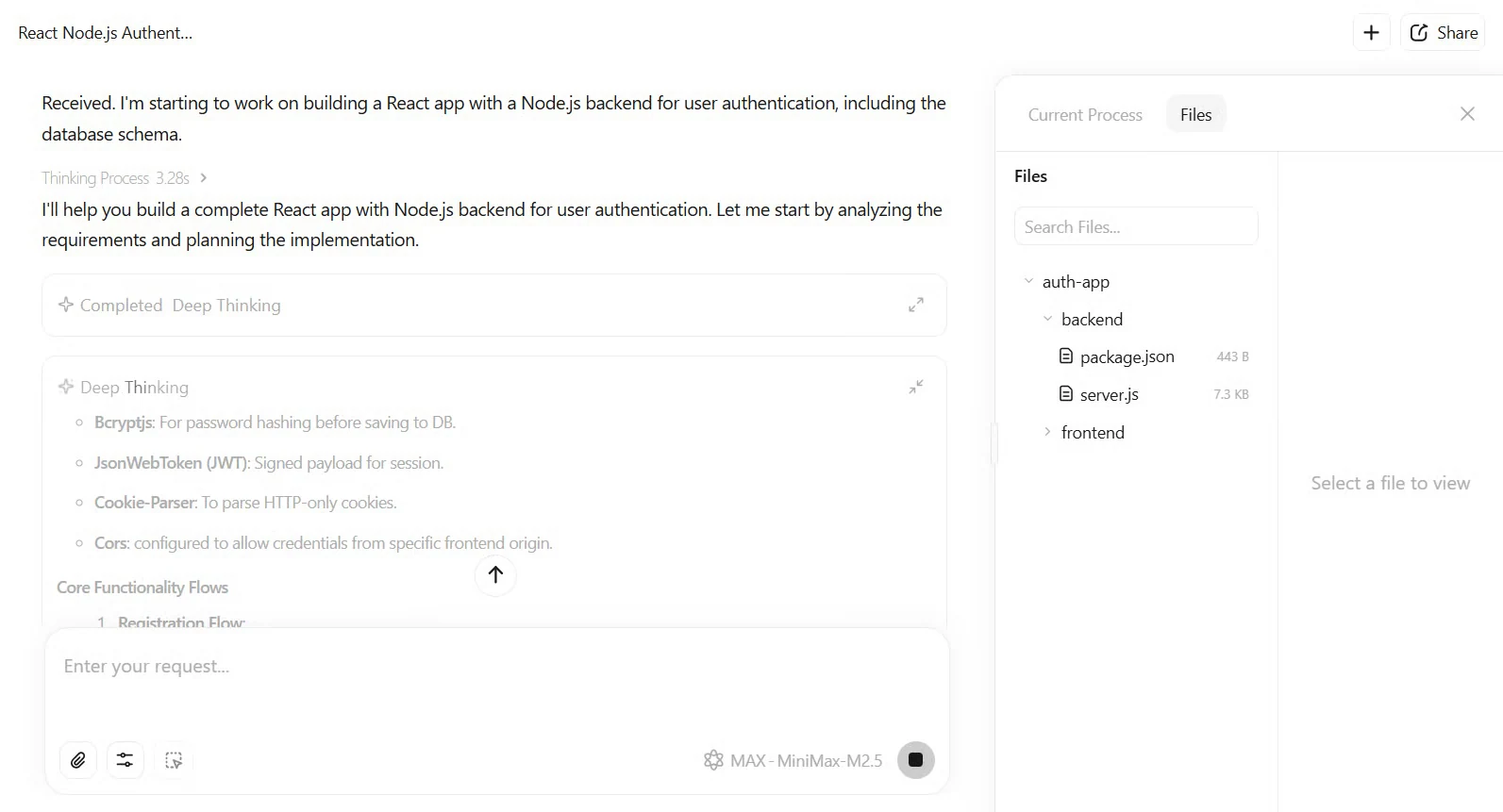
From website
Try Powerful and Affordable Minimax M2.5 Now!
MiniMax M2.5 on Novita AI delivers frontier-level agentic coding performance at 1/10th the cost of premium alternatives. With 80.2% SWE-Bench Verified, 37% faster task completion than M2.1, and $0.30/$1.20 per 1M tokens, it’s the optimal choice for production AI coding agents, office automation, and tool orchestration workflows.
Frequently Asked Questions
How does MiniMax M2.5 compare to M2.1?
M2.5 is 37% faster on SWE-Bench tasks and achieves 80.2% vs ~70% on SWE-Bench Verified. Both cost the same ($0.30/$1.20 per 1M tokens on Novita), making M2.5 the clear upgrade.
Can I self-host MiniMax M2.5 instead of using Novita API?
Yes, but it requires 4-8 H100 GPUs (minimum $5.80/hr on Novita GPU instances). Self-hosting only makes economic sense above 500M tokens/month — for most developers, the API is far more cost-effective.
Does MiniMax M2.5 support function calling?
Yes. M2.5 was extensively trained on tool use and function calling across 200,000+ real-world environments, achieving u003cstrongu003eindustry-leading performance on BrowseComp (76.3%)u003c/strongu003e and Wide Search benchmarks.
Novita AI is an AI & agent cloud platform helping developers and startups build, deploy, and scale models and agentic applications with high performance, reliability, and cost efficiency.
Recommend Reading



