

Seedance 1.5 Pro on Novita AI brings ByteDance’s advanced audio-visual AI to developers at scale. This 4.5-billion-parameter model delivers phoneme-level lip-sync accuracy across 8 languages, native cinematic controls, and synchronized spatial audio—capabilities that previously required expensive post-production teams.
For developers building dialogue-driven video applications, Novita AI’s serverless deployment with configurable resolution (480p/720p) and aspect ratios. Below we break down why this matters for production workflows.
What Makes Seedance 1.5 Pro Different
Native Joint Audio-Visual Generation
Unlike sequential video-then-audio pipelines, Seedance 1.5 Pro uses a dual-branch diffusion transformer that generates synchronized video frames and audio waveforms simultaneously. The cross-modal joint module maintains millisecond-level alignment between visuals and sound, solving the lip-sync drift issues plaguing earlier models.
This architecture delivers three critical advantages: phoneme-accurate lip movements (mapping individual speech sounds to correct mouth shapes), spatial audio positioning (footsteps echo correctly based on room acoustics), and emotional coherence (music intensity matches visual pacing). For dialogue-heavy applications, this eliminates the need for manual audio cleanup.
https://www.youtube.com/watch?v=yaB3LJElhZA
Multilingual Dialect Support
The model handles 8 languages including regional Chinese dialects—Sichuanese, Taiwanese Mandarin, Cantonese, Shanghainese—plus English, Japanese, Korean, Spanish, Portuguese, Indonesian, and Hindi. Each dialect retains authentic pronunciation patterns while maintaining lip-sync accuracy, critical for localized content campaigns.
Cinematic Control Vocabulary
Developers can specify camera movements in natural language: “dolly zoom on subject’s emotional peak,” “tracking shot following car chase,” “whip pan transition between speakers.” The model translates these directives into smooth camera motion with correct physics—no manual keyframing required.
Technical Specifications of Seedance 1.5 Pro
| Specification | Details | Developer Impact |
|---|---|---|
| Model Architecture | 4.5B parameter dual-branch diffusion transformer | Low VRAM for inference (~16GB), fast generation |
| Native Resolution | 720p (480p optional) | Requires external upscaling for 4K workflows |
| Duration Range | 4-12 seconds per clip | Best for short-form content, not long narratives |
| Audio Features | Spatial positioning, environmental effects, emotion-synced music | Significantly reduces post-production audio work |
Visual Quality Assessment
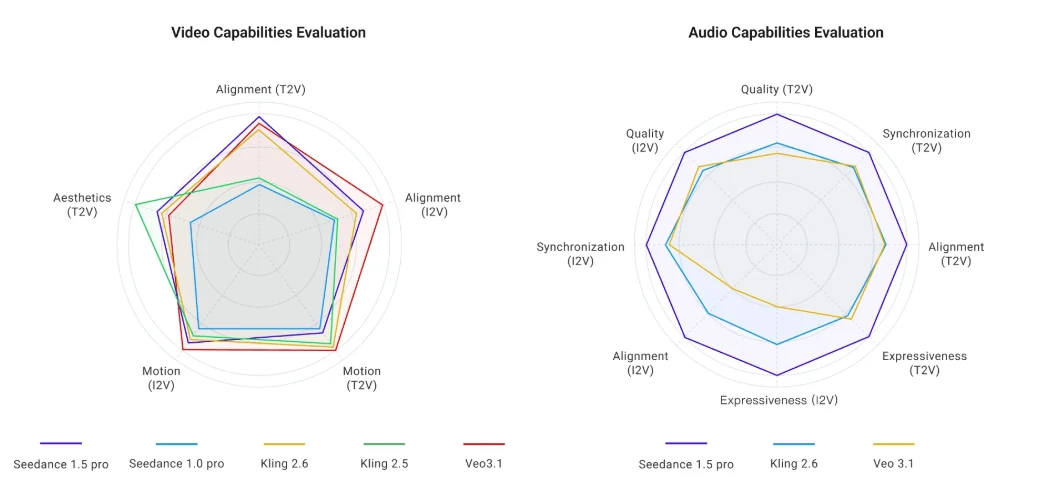
From ByteDance
Independent reviewers score Seedance 1.5 Pro at 7-8/10 vs live-action, noting improved skin textures and reduced banding compared to Kling 1.6 or Runway Gen-3. However, native 720p output limits fine detail—expect soft edges on text overlays and slight exposure inconsistencies across cuts.
The model handles complex physics well: snow particles, high-speed motion blur, water simulations render convincingly. Occasional hypersharpening artifacts appear in hair and foliage, addressable with “natural lighting” prompts.
Using Seedance 1.5 Pro on Novita AI
API Integration Setup
Novita AI exposes Seedance 1.5 Pro (their naming for 1.5 Pro) via two REST endpoints: Text-to-Video (T2V) and Image-to-Video (I2V). Both follow OpenAI-compatible request/response patterns with asynchronous task polling. For a detailed breakdown of when to use T2V vs I2V, audio vs silent output, and online vs flex batch processing, see Seedance V1.5 Pro API: Text-to-Video vs Image-to-Video, Audio, and Silent Modes.
Text-to-Video Example
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-t2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"ratio": "16:9",
"prompt": "A colossal sci-fi mecha stands in the rain-soaked city nightscape, neon lights reflecting off its metallic armor. Slow motion captures every raindrop bouncing off the mecha's shoulder as it raises its arm cannon. Cinematic depth of field blurs the glowing skyscrapers behind. Anime style, dramatic lighting, 4K quality.",
"duration": 8,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'Image-to-Video for Controlled Output
I2V mode accepts starting and ending keyframes, useful for precise character design consistency:
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-i2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"image": "https://pub-32c83cde150f4d468bd19f0a5e372c23.r2.dev/multimodal-assets/2026-02/1771500580027-43159b2510134742.jpg",
"ratio": "adaptive",
"prompt": "A young woman dances energetically on a city street with graffiti walls and neon lights. The camera follows her fluid movements as she spins and grooves to the rhythm. Shot scale changes from medium to close-up, capturing her confident natural expression. Detail enhancement on her facial features and clothing textures. Smooth stabilization throughout the dance sequence with consistent neon lighting reflections.",
"duration": 4,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'Cost of Seedance 1.5 Pro on Novita AI
Novita AI charges per generation task, not per token.
Seedance 1.5 Pro · Text to Video (T2V)
| Resolution | Audio | Online ($/s) | Batch ($/s) |
|---|---|---|---|
| 480P | Silent | $0.012 | $0.006 |
| 480P | Audio | $0.024 | $0.012 |
| 720P | Silent | $0.026 | $0.013 |
| 720P | Audio | $0.052 | $0.026 |
Seedance 1.5 Pro · Image to Video (I2V)
| Resolution | Audio | Online ($/s) | Batch ($/s) |
|---|---|---|---|
| 480P | Silent | $0.012 | $0.006 |
| 480P | Audio | $0.024 | $0.012 |
| 720P | Silent | $0.026 | $0.013 |
| 720P | Audio | $0.052 | $0.026 |
Cost-Saving Tip:
- Start with 480p for prototyping (fastest generation), then regenerate final versions at 720p.
- Use fixed camera (`camera_fixed: true`) to reduce processing time by ~30% when static shots are acceptable.
- Online jobs are processed in real time and return results immediately, while Batch jobs are executed asynchronously for large-scale generation at a lower cost.
Prompt Engineering Best Practices of Seedance 1.5 Pro
Structure for Optimal Results
Seedance 1.5 Pro performs best with explicit, layered prompts that separate visual action, audio cues, and camera directives:
[CHARACTER ACTION] + [DIALOGUE WITH LANGUAGE] + [AUDIO ENVIRONMENT] + [CAMERA MOVEMENT] + [LIGHTING/STYLE]
Example:
"Elderly woman laughs heartily while kneading dough in rustic kitchen.
Says 'This is my grandmother's recipe!' in Sichuanese dialect with warm smile.
Background sounds: bubbling pot, wooden spoon clinking, soft folk music.
Slow dolly zoom focusing on hands, then face.
Warm afternoon sunlight through window, shallow depth of field."Dialect and Emotion Keywords
For multilingual projects, specify dialect explicitly to trigger correct phoneme models:
- Chinese dialects: “in Cantonese dialect,” “using Taiwan Mandarin,” “with Shanghainese accent”
- Emotional intensity: “yelling angrily,” “whispering nervously,” “speaking confidently”
- Non-verbal audio: “footsteps echoing on marble,” “glass shattering off-screen,” “distant traffic noise”
What to Avoid
Reviewers note struggles with very complex action sequences—keep to 1-2 characters and limit simultaneous movements. Avoid prompts like:
- “Five characters having a group discussion” (model handles max 2-3 speakers well)
- “Character runs, jumps, then fights” (too many sequential actions for 10s)
- “Epic battle scene with explosions” (not optimized for action, better suited for dialogue/drama)
Common Gotchas and Solutions of Seedance 1.5 Pro
Issue: Exposure Shifts Between Cuts
Cause: Native 720p generation sometimes produces brightness inconsistencies across scene transitions.
Fix: Add “consistent lighting throughout scene” to prompt, or normalize exposure in post using Lumetri Color/Color Wheels.
Issue: Soft Text Overlays
Cause: 720p native resolution doesn’t retain sharp text edges.
Fix: Generate video without on-screen text, then add titles/graphics in post at higher resolution using After Effects or Motion.
Issue: Audio Drift in Multi-Speaker Scenes
Cause: Complex overlapping dialogue can occasionally desync by 100-200ms.
Fix: Limit to 2 speakers per clip. For group conversations, generate separate shot/reverse-shot clips and edit together.
Issue: Limited Camera Customization
Cause: Model interprets camera directives but doesn’t accept precise focal length/f-stop values.
Fix: Use descriptive terms like “shallow depth of field” or “wide-angle perspective” instead of technical specs.
Seedance 1.5 Pro on Novita AI delivers production-ready audio-visual generation for dialogue-focused short-form content. Its phoneme-level lip-sync accuracy and OpenAI-compatible REST API make it a fast path from script to rendered video for developers building localized ads, micro-dramas, and music video prototypes.
Frequently Asked Questions
How does Seedance 1.5 Pro handle copyrighted music in prompts?
The model generates original music matching emotional descriptions (“upbeat jazz,” “melancholic piano”). It does not reproduce copyrighted songs—attempting to prompt existing tracks will yield generic interpretations.
Can I export audio and video tracks separately for professional mastering?
Yes. The output MP4 contains standard audio tracks extractable via FFmpeg: `ffmpeg -i output.mp4 -vn -acodec pcm_s16le audio.wav` for lossless audio export.
Does Seedance 1.5 Pro support real-time generation for live applications?
No. Generation takes approximately 30–60 seconds per clip. For latency-sensitive workflows, use the Batch endpoint with webhook
callbacks to receive results asynchronously, or pre-generate a library of clips and serve them on demand rather than generating in
real time.
Novita AI is an AI & agent cloud platform helping developers and startups build, deploy, and scale models and agentic applications with high performance, reliability, and cost efficiency.



