

يجلب Seedance 1.5 Pro على Novita AI الذكاء الاصطناعي المتقدم للصوت والصورة من ByteDance للمطورين على نطاق واسع. يقدم هذا النموذج الذي يحتوي على 4.5 مليار معلمة دقة مزامنة الشفاه على مستوى الصوتيات عبر 8 لغات، وتحكمات سينمائية أصلية، وصوت مكاني متزامن—وهي إمكانيات كانت تتطلب سابقًا فرق إنتاج خلفية باهظة التكلفة.
بالنسبة للمطورين الذين يبنون تطبيقات فيديو تعتمد على الحوار، فإن النشر بدون خادم من Novita AI مع دقة قابلة للتكوين (480p/720p) ونسب أبعاد. أدناه نوضح لماذا هذا مهم لسير عمل الإنتاج.
ما الذي يجعل Seedance 1.5 Pro مختلفًا
التوليد المشترك الأصلي للصوت والصورة
على عكس خطوط أنابيب الفيديو ثم الصوت المتسلسلة، يستخدم Seedance 1.5 Pro محول انتشار مزدوج الفرع يقوم بتوليد إطارات الفيديو والموجات الصوتية المتزامنة في وقت واحد. تحافظ الوحدة المشتركة بين الوسائط على محاذاة على مستوى الميلي ثانية بين المرئيات والصوت، مما يحل مشكلات انحراف مزامنة الشفاه التي كانت تعاني منها النماذج السابقة.
توفر هذه البنية ثلاث مزايا حاسمة: حركات شفاه دقيقة صوتيًا (ربط أصوات الكلام الفردية بأشكال الفم الصحيحة)، وضع الصوت المكاني (تتردد أصداء الخطوات بشكل صحيح بناءً على صوتيات الغرفة)، والتماسك العاطفي (تتناسب شدة الموسيقى مع الإيقاع البصري). بالنسبة للتطبيقات كثيفة الحوار، يلغي هذا الحاجة إلى تنظيف الصوت اليدوي.
https://www.youtube.com/watch?v=yaB3LJElhZA
دعم اللهجات متعددة اللغات
يتعامل النموذج مع 8 لغات بما في ذلك اللهجات الصينية الإقليمية—السيتشوانية، الماندرين التايوانية، الكانتونية، الشنغهاينية—بالإضافة إلى الإنجليزية واليابانية والكورية والإسبانية والبرتغالية والإندونيسية والهندية. تحتفظ كل لهجة بأنماط النطق الأصيلة مع الحفاظ على دقة مزامنة الشفاه، وهو أمر بالغ الأهمية لحملات المحتوى المحلي.
مفردات التحكم السينمائي
يمكن للمطورين تحديد حركات الكاميرا بلغة طبيعية: “تكبير دوللي على ذروة المشاعر للموضوع”، “لقطة تتبع تطارد سيارة”، “انتقال سريع بين المتحدثين”. يترجم النموذج هذه التوجيهات إلى حركة كاميرا سلسة مع فيزياء صحيحة—لا حاجة لتحريك الإطارات الرئيسية يدويًا.
المواصفات التقنية لـ Seedance 1.5 Pro
| المواصفات | التفاصيل | تأثير المطور |
|---|---|---|
| هندسة النموذج | محول انتشار مزدوج الفرع بـ 4.5 مليار معلمة | ذاكرة VRAM منخفضة للاستدلال (~16 جيجابايت)، توليد سريع |
| الدقة الأصلية | 720p (480p اختياري) | يتطلب رفع دقة خارجي لسير عمل 4K |
| نطاق المدة | 4-12 ثانية لكل مقطع | الأفضل للمحتوى القصير، وليس الروايات الطويلة |
| ميزات الصوت | وضع مكاني، تأثيرات بيئية، موسيقى متزامنة مع المشاعر | يقلل بشكل كبير من عمل تحرير الصوت بعد الإنتاج |
تقييم الجودة البصرية
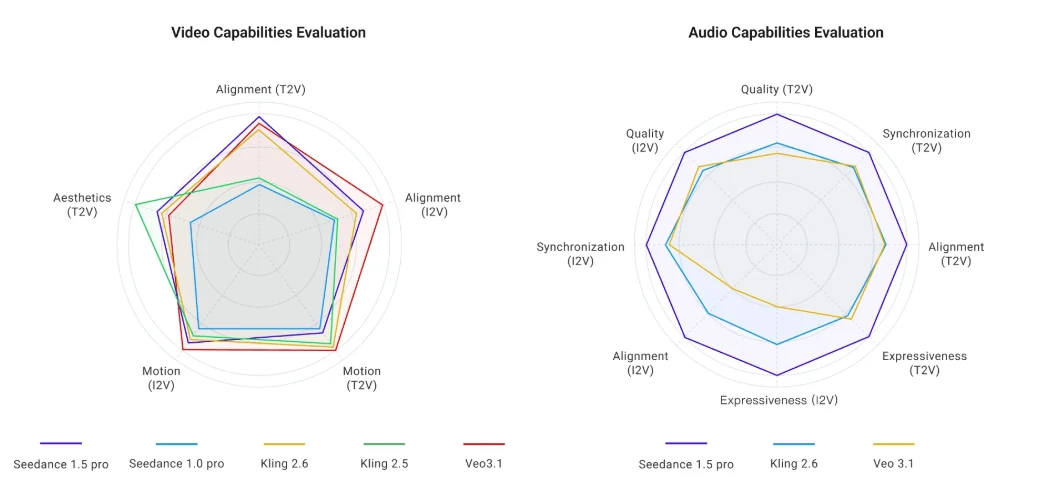
من ByteDance
يسجل المراجعون المستقلون Seedance 1.5 Pro بدرجة 7-8/10 مقارنة بالتصوير الحي، مشيرين إلى تحسن نسيج الجلد وتقليل التدرجات مقارنة بـ Kling 1.6 أو Runway Gen-3. ومع ذلك، فإن الإخراج الأصلي بدقة 720p يحد من التفاصيل الدقيقة—توقع حواف ناعمة على التراكبات النصية وتناقضات طفيفة في التعريض عبر المشاهد.
يتعامل النموذج مع الفيزياء المعقدة بشكل جيد: جزيئات الثلج، ضبابية الحركة عالية السرعة، محاكاة المياه تبدو مقنعة. تظهر أحيانًا تشوهات حادة مفرطة في الشعر وأوراق الشجر، يمكن معالجتها باستخدام أوامر “إضاءة طبيعية”.
استخدام Seedance 1.5 Pro على Novita AI
إعداد تكامل API
يقدم Novita AI Seedance 1.5 Pro (تسميتهم للإصدار 1.5 Pro) عبر نقطتي نهاية REST: نص إلى فيديو (T2V) وصورة إلى فيديو (I2V). كلاهما يتبع أنماط طلب/استجابة متوافقة مع OpenAI مع استقصاء المهام غير المتزامنة. للحصول على تفصيل دقيق حول متى تستخدم T2V مقابل I2V، والإخراج الصوتي مقابل الصامت، والمعالجة عبر الإنترنت مقابل المعالجة المجمعة المرنة، راجع Seedance V1.5 Pro API: Text-to-Video vs Image-to-Video, Audio, and Silent Modes.
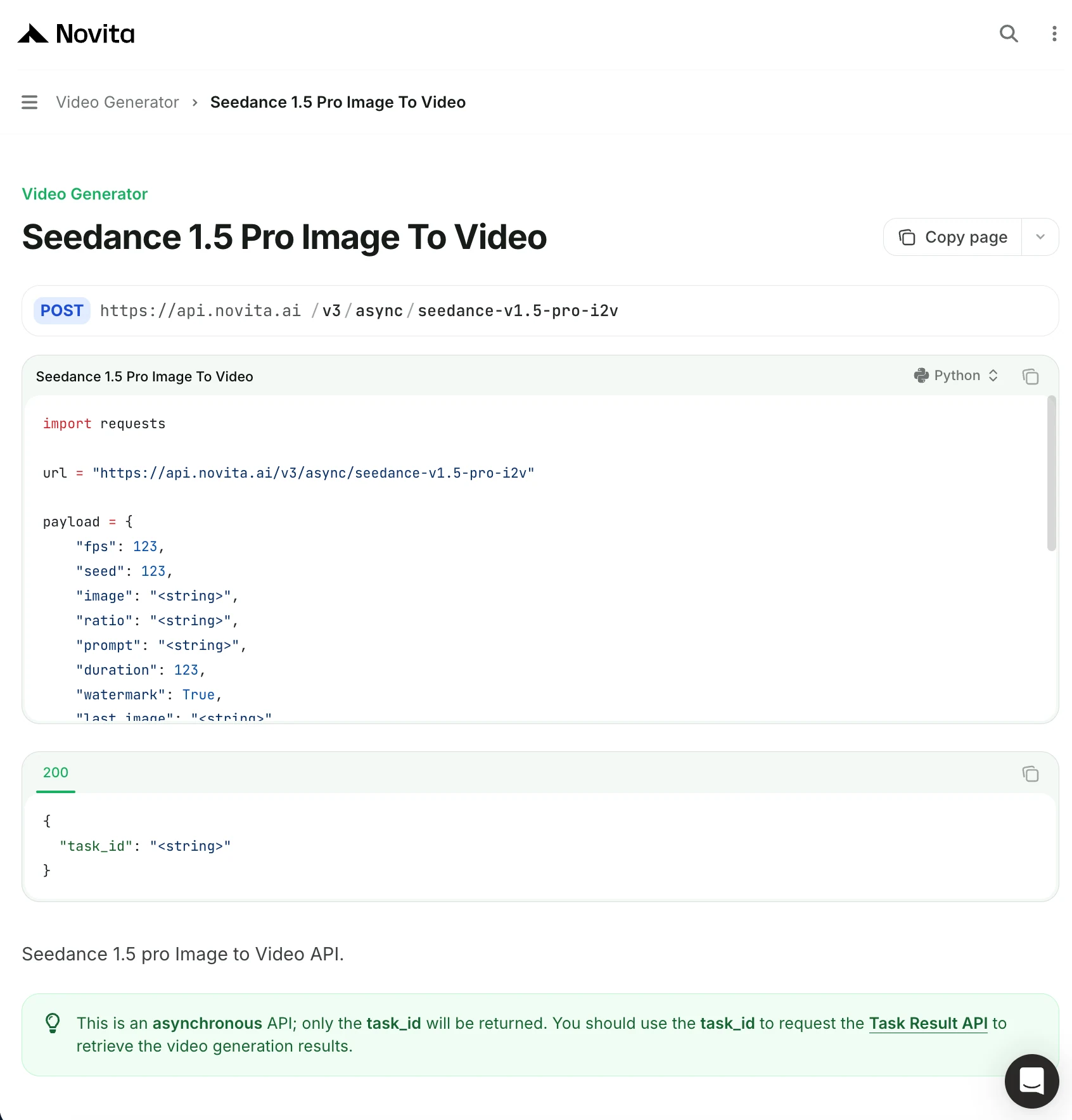
مثال: نص إلى فيديو
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-t2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"ratio": "16:9",
"prompt": "A colossal sci-fi mecha stands in the rain-soaked city nightscape, neon lights reflecting off its metallic armor. Slow motion captures every raindrop bouncing off the mecha's shoulder as it raises its arm cannon. Cinematic depth of field blurs the glowing skyscrapers behind. Anime style, dramatic lighting, 4K quality.",
"duration": 8,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'
صورة إلى فيديو لإخراج محكوم
وضع I2V يقبل إطارات مفتاحية للبداية والنهاية، مفيدًا لاتساق تصميم الشخصيات بدقة:
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-i2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"image": "https://pub-32c83cde150f4d468bd19f0a5e372c23.r2.dev/multimodal-assets/2026-02/1771500580027-43159b2510134742.jpg",
"ratio": "adaptive",
"prompt": "A young woman dances energetically on a city street with graffiti walls and neon lights. The camera follows her fluid movements as she spins and grooves to the rhythm. Shot scale changes from medium to close-up, capturing her confident natural expression. Detail enhancement on her facial features and clothing textures. Smooth stabilization throughout the dance sequence with consistent neon lighting reflections.",
"duration": 4,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'
تكلفة Seedance 1.5 Pro على Novita AI
يتقاضى Novita AI لكل مهمة توليد، وليس لكل رمز مميز.
Seedance 1.5 Pro · نص إلى فيديو (T2V)
| الدقة | صوت | عبر الإنترنت ($/ثانية) | دفعة ($/ثانية) |
|---|---|---|---|
| 480P | صامت | $0.012 | $0.006 |
| 480P | صوت | $0.024 | $0.012 |
| 720P | صامت | $0.026 | $0.013 |
| 720P | صوت | $0.052 | $0.026 |
Seedance 1.5 Pro · صورة إلى فيديو (I2V)
| الدقة | صوت | عبر الإنترنت ($/ثانية) | دفعة ($/ثانية) |
|---|---|---|---|
| 480P | صامت | $0.012 | $0.006 |
| 480P | صوت | $0.024 | $0.012 |
| 720P | صامت | $0.026 | $0.013 |
| 720P | صوت | $0.052 | $0.026 |
نصيحة لتوفير التكاليف:
- ابدأ بـ 480p للنماذج الأولية (أسرع توليد)، ثم أعد توليد الإصدارات النهائية بدقة 720p.
- استخدم كاميرا ثابتة (
camera_fixed: true) لتقليل وقت المعالجة بنحو 30% عندما تكون اللقطات الثابتة مقبولة.- تتم معالجة المهام عبر الإنترنت في الوقت الفعلي وتعود بالنتائج فورًا، بينما يتم تنفيذ مهام الدفعة بشكل غير متزامن للتوليد على نطاق واسع بتكلفة أقل.
أفضل ممارسات هندسة الأوامر لـ Seedance 1.5 Pro
البنية للحصول على نتائج مثلى
يعمل Seedance 1.5 Pro بشكل أفضل مع أوامر صريحة ومتعددة الطبقات تفصل الإجراء البصري والإشارات الصوتية وتوجيهات الكاميرا:
[إجراء الشخصية] + [حوار مع لغة] + [بيئة صوتية] + [حركة الكاميرا] + [إضاءة/أسلوب]
مثال:
"امرأة مسنة تضحك بحرارة وهي تعجن العجين في مطبخ ريفي.
تقول 'هذه وصفة جدتي!' بلهجة سيتشوانية مع ابتسامة دافئة.
أصوات الخلفية: قدر يغلي، ملعقة خشبية تصطدم، موسيقى شعبية هادئة.
تكبير دوللي بطيء يركز على اليدين، ثم الوجه.
ضوء شمس بعد الظهيرة دافئ عبر النافذة، عمق ميدان ضحل."
كلمات اللهجة والعواطف
للمشاريع متعددة اللغات، حدد اللهجة بوضوح لتفعيل نماذج الصوتيات الصحيحة:
- اللهجات الصينية: “باللهجة الكانتونية”، “باستخدام الماندرين التايوانية”، “بلكنة شنغهاينية”
- الشدة العاطفية: “يصرخ بغضب”، “يهمس بعصبية”، “يتحدث بثقة”
- صوت غير لفظي: “أصداء خطوات على الرخام”، “صوت زجاج يتكسر خارج الإطار”، “ضجيج مرور بعيد”
ما يجب تجنبه
يلاحظ المراجعون صعوبات في تسلسلات الحركة المعقدة جدًا—التزم بشخصية أو اثنتين وحد الحركات المتزامنة. تجنب أوامر مثل:
- “خمس شخصيات يناقشون في مجموعة” (يتعامل النموذج جيدًا مع 2-3 متحدثين كحد أقصى)
- “شخصية تجري، ثم تقفز، ثم تقاتل” (إجراءات متسلسلة كثيرة جدًا لمدة 10 ثوانٍ)
- “مشهد معركة ملحمي مع انفجارات” (غير محسّن للحركة، أفضل للحوار/الدراما)
المشكلات الشائعة وحلولها لـ Seedance 1.5 Pro
المشكلة: تغيرات التعريض بين المشاهد
السبب: التوليد الأصلي بدقة 720p ينتج أحيانًا تناقضات في السطوع عبر انتقالات المشاهد.
الحل: أضف “إضاءة متناسقة طوال المشهد” إلى الأمر، أو قم بتعديل التعريض بعد الإنتاج باستخدام Lumetri Color/Color Wheels.
المشكلة: تراكبات نصية ناعمة
السبب: الدقة الأصلية 720p لا تحافظ على حواف النص الحادة.
الحل: قم بتوليد الفيديو بدون نص على الشاشة، ثم أضف العناوين/الرسومات بعد الإنتاج بدقة أعلى باستخدام After Effects أو Motion.
المشكلة: انحراف الصوت في مشاهد متعددة المتحدثين
السبب: الحوار المتداخل المعقد يمكن أن يسبب أحيانًا فقدان التزامن بمقدار 100-200 مللي ثانية.
الحل: اقتصر على متحدثين لكل مقطع. للمحادثات الجماعية، قم بتوليد مقاطع منفصلة لكل لقطة/لقطة معكوسة ودمجها معًا.
المشكلة: تخصيص محدود للكاميرا
السبب: يفسر النموذج توجيهات الكاميرا لكنه لا يقبل قيم دقيقة للبعد البؤري/فتحة العدسة.
الحل: استخدم مصطلحات وصفية مثل “عمق ميدان ضحل” أو “منظور واسع الزاوية” بدلاً من المواصفات الفنية.
يقدم Seedance 1.5 Pro على Novita AI توليدًا صوتيًا بصريًا جاهزًا للإنتاج للمحتوى القصير الذي يركز على الحوار. إن دقة مزامنة الشفاه على مستوى الصوتيات وواجهة REST المتوافقة مع OpenAI تجعله مسارًا سريعًا من النص إلى الفيديو المقدم للمطورين الذين يبنون إعلانات محلية، ودراما مصغرة، ونماذج أولية لفيديوهات موسيقية.
الأسئلة الشائعة
كيف يتعامل Seedance 1.5 Pro مع الموسيقى المحمية بحقوق النشر في الأوامر؟
يقوم النموذج بتوليد موسيقى أصلية تطابق الأوصاف العاطفية (“جاز مبهج”، “بيانو حزين”). لا يعيد إنتاج الأغاني المحمية بحقوق النشر—محاولة الأمر بأغاني موجودة ستؤدي إلى تفسيرات عامة.
هل يمكنني تصدير المسارات الصوتية والفيديو بشكل منفصل للتحرير الاحترافي؟
نعم. يحتوي ملف MP4 الناتج على مسارات صوتية قياسية يمكن استخراجها باستخدام FFmpeg: ffmpeg -i output.mp4 -vn -acodec pcm_s16le audio.wav للتصدير الصوتي دون فقدان.
هل يدعم Seedance 1.5 Pro التوليد في الوقت الفعلي للتطبيقات المباشرة؟
لا. يستغرق التوليد حوالي 30–60 ثانية لكل مقطع. بالنسبة لسير العمل الحساس لوقت الاستجابة، استخدم نقطة نهاية الدفعة مع استدعاءات webhook لتلقي النتائج بشكل غير متزامن، أو قم بتوليد مكتبة من المقاطع مسبقًا وخدمتها عند الطلب بدلاً من التوليد في الوقت الفعلي.
Novita AI هي منصة سحابية للذكاء الاصطناعي والعوامل تساعد المطورين والشركات الناشئة على بناء ونشر وتوسيع نطاق النماذج والتطبيقات العاملة بالعوامل بأداء عالٍ وموثوقية وكفاءة من حيث التكلفة.



