

Novita AI의 Seedance 1.5 Pro는 바이트댄스의 고급 오디오-비주얼 AI를 개발자에게 확장 가능하게 제공합니다. 이 45억 개의 파라미터 모델은 8개 언어에 걸친 음소 수준의 립싱크 정확도, 네이티브 시네마틱 컨트롤, 동기화된 공간 오디오를 제공합니다. 이러한 기능은 이전에는 값비싼 후반 작업 팀이 필요했습니다.
대화 중심 비디오 애플리케이션을 구축하는 개발자에게 Novita AI의 서버리스 배포는 구성 가능한 해상도(480p/720p)와 화면 비율을 제공합니다. 아래에서는 이것이 프로덕션 워크플로우에 중요한 이유를 설명합니다.
Seedance 1.5 Pro를 차별화하는 요소
네이티브 공동 오디오-비주얼 생성
순차적인 비디오-이후-오디오 파이프라인과 달리, Seedance 1.5 Pro는 이중 분기 확산 트랜스포머를 사용 하여 동기화된 비디오 프레임과 오디오 파형을 동시에 생성합니다. 교차 모달 공동 모듈은 시각과 사운드 간의 밀리초 수준 정렬을 유지하여 이전 모델을 괴롭히던 립싱크 드리프트 문제를 해결합니다.
이 아키텍처는 세 가지 중요한 이점을 제공합니다: **음소 정확한 입술 움직임 **(개별 음성 소리를 올바른 입 모양에 매핑), ** 공간 오디오 포지셔닝 (발자국 소리가 실내 음향에 따라 올바르게 울림), ** 감정적 일관성(음악 강도가 시각적 템포와 일치). 대화가 많은 애플리케이션의 경우 수동 오디오 정리 작업이 필요 없습니다.
https://www.youtube.com/watch?v=yaB3LJElhZA
다국어 방언 지원
이 모델은 쓰촨어, 대만 만다린어, 광둥어, 상하이어 등 중국어 방언을 포함한 8개 언어와 영어, 일본어, 한국어, 스페인어, 포르투갈어, 인도네시아어, 힌디어를 처리합니다. 각 방언은 립싱크 정확도를 유지하면서 진정한 발음 패턴을 유지하므로 현지화된 콘텐츠 캠페인에 매우 중요합니다.
시네마틱 컨트롬 어휘
개발자는 자연어로 카메라 움직임을 지정할 수 있습니다: “피사체의 감정적 정점에서 돌리 줌”, “자동차 추격 장면을 따르는 트래킹 샷”, “화자 간의 휩 팬 전환”. 모델은 이러한 지시를 올바른 물리 법칙을 가진 부드러운 카메라 모션으로 변환합니다. 수동 키프레이밍이 필요 없습니다.
Seedance 1.5 Pro 기술 사양
| 사양 | 세부 사항 | 개발자 영향 |
|---|---|---|
| 모델 아키텍처 | 45억 파라미터 이중 분기 확산 트랜스포머 | 추론 시 낮은 VRAM(~16GB), 빠른 생성 |
| 네이티브 해상도 | 720p (480p 선택 가능) | 4K 워크플로우에는 외부 업스케일링 필요 |
| 지속 시간 범위 | 클립당 4~12초 | 긴 내러티브보다는 짧은 형식 콘텐츠에 적합 |
| 오디오 기능 | 공간 포지셔닝, 환경 효과, 감정 동기화 음악 | 후반 작업 오디오 작업 크게 감소 |
시각 품질 평가
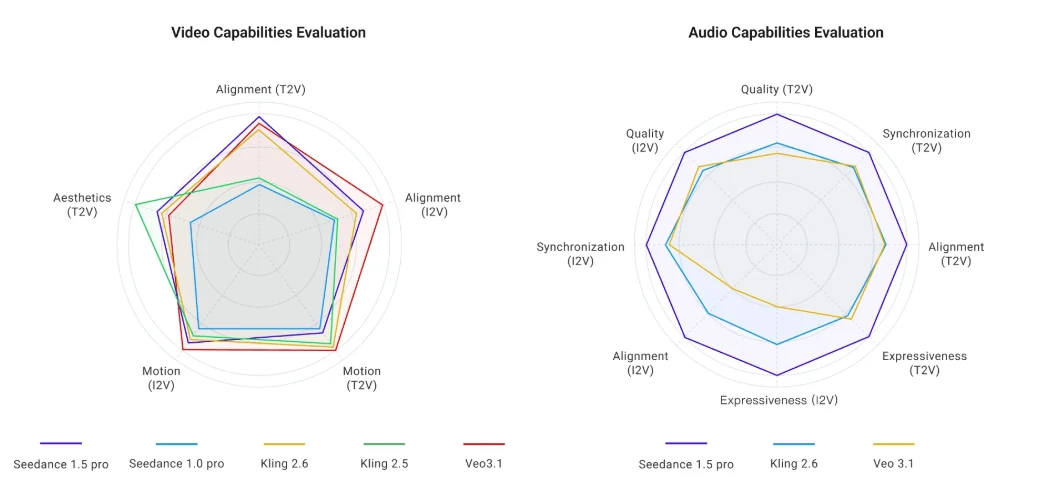
독립 리뷰어들은 Seedance 1.5 Pro를 실사 대비 7~8/10점으로 평가하며, Kling 1.6이나 Runway Gen-3에 비해 향상된 피부 질감과 줄무늬 감소를 언급합니다. 그러나 네이티브 720p 출력은 미세한 디테일을 제한합니다. 텍스트 오버레이에서 가장자리가 약간 흐릿하고 컷 간 노출 불일치가 발생할 수 있습니다.
이 모델은 복잡한 물리 현상을 잘 처리합니다. 눈 입자, 고속 모션 블러, 물 시뮬레이션이 설득력 있게 렌더링됩니다. 머리카락과 나뭇잎에서 가끔 과도한 샤프닝 아티팩트가 나타날 수 있으며, “자연 조명” 프롬프트로 해결할 수 있습니다.
Novita AI에서 Seedance 1.5 Pro 사용하기
API 통합 설정
Novita AI는 Seedance 1.5 Pro(1.5 Pro에 대한 명명)를 두 개의 REST 엔드포인트(Text-to-Video T2V 및 Image-to-Video I2V)로 제공합니다. 둘 다 비동기 작업 폴링이 포함된 OpenAI 호환 요청/응답 패턴을 따릅니다. T2V 대 I2V를 사용해야 하는 시기, 오디오 대 무음 출력, 온라인 대 플렉스 배치 처리에 대한 자세한 설명은 Seedance V1.5 Pro API: Text-to-Video vs Image-to-Video, Audio, and Silent Modes를 참조하세요.
텍스트-비디오 예시
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-t2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"ratio": "16:9",
"prompt": "A colossal sci-fi mecha stands in the rain-soaked city nightscape, neon lights reflecting off its metallic armor. Slow motion captures every raindrop bouncing off the mecha's shoulder as it raises its arm cannon. Cinematic depth of field blurs the glowing skyscrapers behind. Anime style, dramatic lighting, 4K quality.",
"duration": 8,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'
제어된 출력을 위한 이미지-비디오
I2V 모드는 시작 및 종료 키프레임을 허용하므로 정확한 캐릭터 디자인 일관성에 유용합니다.
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-i2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"image": "https://pub-32c83cde150f4d468bd19f0a5e372c23.r2.dev/multimodal-assets/2026-02/1771500580027-43159b2510134742.jpg",
"ratio": "adaptive",
"prompt": "A young woman dances energetically on a city street with graffiti walls and neon lights. The camera follows her fluid movements as she spins and grooves to the rhythm. Shot scale changes from medium to close-up, capturing her confident natural expression. Detail enhancement on her facial features and clothing textures. Smooth stabilization throughout the dance sequence with consistent neon lighting reflections.",
"duration": 4,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'
Novita AI에서 Seedance 1.5 Pro 사용 비용
Novita AI는 토큰당이 아닌 생성 작업당 요금을 부과합니다.
Seedance 1.5 Pro · 텍스트-비디오 (T2V)
| 해상도 | 오디오 | 온라인 ($/초) | 배치 ($/초) |
|---|---|---|---|
| 480P | 무음 | $0.012 | $0.006 |
| 480P | 오디오 | $0.024 | $0.012 |
| 720P | 무음 | $0.026 | $0.013 |
| 720P | 오디오 | $0.052 | $0.026 |
Seedance 1.5 Pro · 이미지-비디오 (I2V)
| 해상도 | 오디오 | 온라인 ($/초) | 배치 ($/초) |
|---|---|---|---|
| 480P | 무음 | $0.012 | $0.006 |
| 480P | 오디오 | $0.024 | $0.012 |
| 720P | 무음 | $0.026 | $0.013 |
| 720P | 오디오 | $0.052 | $0.026 |
비용 절감 팁:
- 프로토타이핑에는 480p로 시작(가장 빠른 생성), 최종 버전은 720p로 다시 생성하세요.
- 고정 카메라(true)를 사용하면 정적 샷이 허용될 때 처리 시간이 약 30% 감소합니다.
- 온라인 작업은 실시간으로 처리되어 즉시 결과를 반환하는 반면, 배치 작업은 대규모 생성을 위해 비동기적으로 실행되어 비용이 낮습니다.
Seedance 1.5 Pro를 위한 프롬프트 엔지니어링 모범 사례
최적 결과를 위한 구조
Seedance 1.5 Pro는 시각적 동작, 오디오 큐, 카메라 지시를 분리하는 명시적이고 계층적인 프롬프트 에서 가장 잘 작동합니다.
[캐릭터 동작] + [대화 (언어 포함)] + [오디오 환경] + [카메라 움직임] + [조명/스타일]
예시:
"시골 주방에서 반죽을 치대며 마음껏 웃는 노부인.
따뜻한 미소를 지으며 쓰촨어 방언으로 '이건 할머니 레시피야!'라고 말합니다.
배경 소리: 보글보글 끓는 냄비, 나무 숟가락이 부딪히는 소리, 부드러운 민속 음악.
손에 초점을 맞춘 후 얼굴로 천천히 돌리 줌.
창문을 통해 들어오는 따뜻한 오후 햇살, 얕은 심도."
방언 및 감정 키워드
다국어 프로젝트의 경우 방언을 명시적으로 지정 하여 올바른 음소 모델이 트리거되도록 합니다.
- 중국어 방언: “광둥어 방언으로”, “대만 만다린 사용”, “상하이 억양으로”
- 감정 강도: “화내며 외치기”, “긴장하며 속삭이기”, “자신있게 말하기”
- 비언어적 오디오: “대리석에 울리는 발자국 소리”, “화면 밖에서 유리 깨지는 소리”, “먼 교통 소음”
피해야 할 사항
리뷰어들은 매우 복잡한 액션 시퀀스에서 어려움을 겪는다고 언급합니다. 캐릭터는 1~2명으로 유지하고 동시 움직임을 제한하세요. 다음과 같은 프롬프트는 피하십시오:
- “다섯 명의 캐릭터가 그룹 토론을 하는 장면” (모델은 2~3명의 화자를 잘 처리함)
- “캐릭터가 달리고, 점프하고, 싸우는 장면” (10초에 너무 많은 순차적 동작)
- “폭발이 있는 장대한 전투 장면” (액션에 최적화되지 않음, 대화/드라마에 더 적합)
Seedance 1.5 Pro의 일반적인 문제 및 해결 방법
문제: 컷 사이의 노출 변화
원인: 네이티브 720p 생성 시 장면 전환에서 밝기 불일치가 발생할 수 있습니다.
해결 방법: 프롬프트에 "장면 전체에서 일관된 조명"을 추가하거나 후반 작업에서 Lumetri Color/Color Wheels를 사용하여 노출을 정규화합니다.
문제: 부드러운 텍스트 오버레이
원인: 720p 네이티브 해상도에서는 선명한 텍스트 가장자리를 유지하지 못합니다.
해결 방법: 화면 텍스트 없이 비디오를 생성한 다음 후반 작업에서 After Effects 또는 Motion을 사용하여 더 높은 해상도로 제목/그래픽을 추가합니다.
문제: 다중 화자 장면에서 오디오 드리프트
원인: 복잡한 중첩 대화가 때때로 100~200ms 정도 동기화되지 않을 수 있습니다.
해결 방법: 클립당 2명의 화자로 제한합니다. 그룹 대화의 경우 별도의 샷/역샷 클립을 생성하여 함께 편집합니다.
문제: 제한된 카메라 사용자 지정
원인: 모델이 카메라 지시를 해석하지만 정확한 초점 거리/f-값을 허용하지 않습니다.
해결 방법: 기술 사양 대신 “얕은 심도” 또는 "광각 원근감"과 같은 설명적 용어를 사용합니다.
Novita AI의 Seedance 1.5 Pro는 대화 중심의 짧은 형식 콘텐츠를 위한 프로덕션 준비 완료된 오디오-비주얼 생성을 제공합니다. 음소 수준의 립싱크 정확도와 OpenAI 호환 REST API는 현지화된 광고, 마이크로 드라마, 뮤직 비디오 프로토타입을 구축하는 개발자에게 스크립트에서 렌더링된 비디오로의 빠른 경로를 제공합니다.
자주 묻는 질문
Seedance 1.5 Pro는 프롬프트에서 저작권이 있는 음악을 어떻게 처리합니까? 이 모델은 감정 설명(“경쾌한 재즈”, “우울한 피아노”)과 일치하는 독창적인 음악을 생성합니다. 저작권이 있는 노래를 재생산하지 않습니다. 기존 트랙을 프롬프트하면 일반적인 해석이 생성됩니다.
전문 마스터링을 위해 오디오 및 비디오 트랙을 별도로 내보낼 수 있습니까?
예. 출력 MP4에는 FFmpeg를 통해 추출할 수 있는 표준 오디오 트랙이 포함되어 있습니다. ffmpeg -i output.mp4 -vn -acodec pcm_s16le audio.wav 명령으로 무손실 오디오를 내보낼 수 있습니다.
Seedance 1.5 Pro는 라이브 애플리케이션을 위한 실시간 생성을 지원합니까? 아니요. 생성에는 클립당 약 30~60초가 소요됩니다. 지연 시간에 민감한 워크플로우의 경우 웹후크 콜백이 있는 배치 엔드포인트를 사용하여 비동기적으로 결과를 수신하거나, 클립 라이브러리를 미리 생성하여 실시간 생성 대신 주문형으로 제공하십시오.
Novita AI는 개발자와 스타트업이 높은 성능, 신뢰성, 비용 효율성으로 모델 및 에이전트 애플리케이션을 구축, 배포, 확장할 수 있도록 지원하는 AI 및 에이전트 클라우드 플랫폼입니다.



