

Seedance 1.5 Pro en Novita AI lleva la avanzada IA audiovisual de ByteDance a los desarrolladores a gran escala. Este modelo de 4.5 mil millones de parámetros ofrece precisión de sincronización labial a nivel de fonemas en 8 idiomas, controles cinematográficos nativos y audio espacial sincronizado, capacidades que antes requerían costosos equipos de postproducción.
Para desarrolladores que crean aplicaciones de video basadas en diálogos, Novita AI ofrece un despliegue serverless con resolución configurable (480p/720p) y relaciones de aspecto. A continuación, desglosamos por qué esto es importante para los flujos de trabajo de producción.
¡Prueba Seedance 1.5 Pro ahora!
Qué hace diferente a Seedance 1.5 Pro
Generación audiovisual conjunta nativa
A diferencia de los pipelines secuenciales de video y luego audio, Seedance 1.5 Pro utiliza un transformer de difusión de doble rama que genera fotogramas de video sincronizados y ondas de audio simultáneamente. El módulo conjunto cross-modal mantiene una alineación a nivel de milisegundos entre lo visual y el sonido, resolviendo los problemas de desviación de sincronización labial que afectaban a modelos anteriores.
Esta arquitectura ofrece tres ventajas críticas: movimientos labiales precisos a nivel de fonemas (mapeando sonidos individuales del habla a las formas bucales correctas), posicionamiento de audio espacial (los pasos resuenan correctamente según la acústica de la habitación) y coherencia emocional (la intensidad de la música coincide con el ritmo visual). Para aplicaciones con mucho diálogo, esto elimina la necesidad de limpieza manual de audio.
https://www.youtube.com/watch?v=yaB3LJElhZA
Soporte de dialectos multilingües
El modelo maneja 8 idiomas, incluidos dialectos regionales chinos: sichuanés, mandarín taiwanés, cantonés, shanghainés, además de inglés, japonés, coreano, español, portugués, indonesio e hindi. Cada dialecto conserva patrones de pronunciación auténticos mientras mantiene la precisión de sincronización labial, algo crítico para campañas de contenido localizado.
Vocabulario de control cinematográfico
Los desarrolladores pueden especificar movimientos de cámara en lenguaje natural: “zoom dolly en el pico emocional del sujeto”, “travelling siguiendo una persecución de coches”, “transición de corte rápido entre hablantes”. El modelo traduce estas directivas en movimientos de cámara suaves con física correcta, sin necesidad de animación manual.
¡Prueba Seedance 1.5 Pro ahora!
Especificaciones técnicas de Seedance 1.5 Pro
| Especificación | Detalles | Impacto para el desarrollador |
|---|---|---|
| Arquitectura del modelo | Transformer de difusión de doble rama de 4.5B parámetros | Bajo VRAM para inferencia (~16GB), generación rápida |
| Resolución nativa | 720p (480p opcional) | Requiere escalado externo para flujos de trabajo 4K |
| Rango de duración | 4-12 segundos por clip | Ideal para contenido de formato corto, no para narrativas largas |
| Características de audio | Posicionamiento espacial, efectos ambientales, música sincronizada con emociones | Reduce significativamente el trabajo de audio en postproducción |
Evaluación de calidad visual
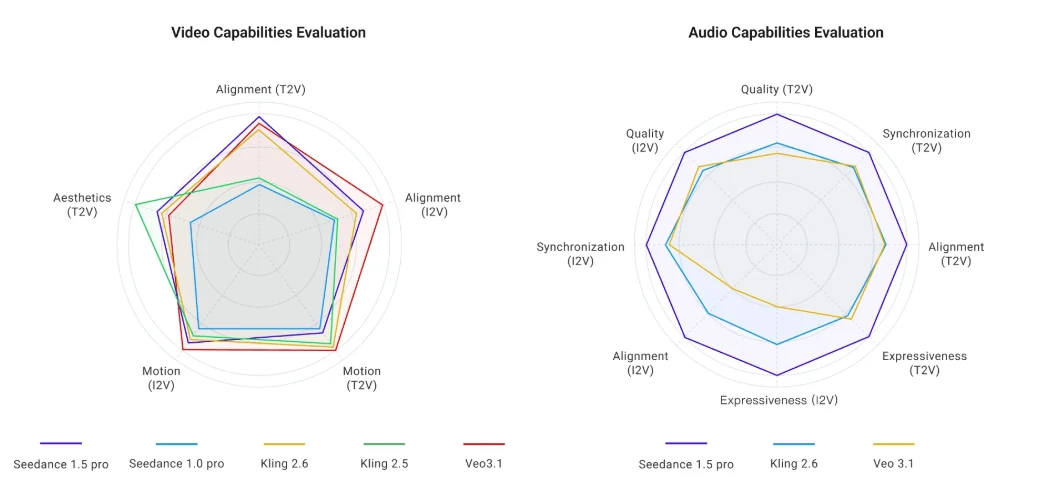
Fuente: ByteDance
Los revisores independientes puntúan Seedance 1.5 Pro con un 7-8/10 frente a acción real, destacando texturas de piel mejoradas y menor banding en comparación con Kling 1.6 o Runway Gen-3. Sin embargo, la salida nativa de 720p limita el detalle fino: espere bordes suaves en superposiciones de texto y ligeras inconsistencias de exposición entre cortes.
El modelo maneja bien la física compleja: partículas de nieve, desenfoque de movimiento a alta velocidad, simulaciones de agua se renderizan de manera convincente. Ocasionalmente aparecen artefactos de hiperenfoque en cabello y follaje, que se pueden solucionar con indicaciones de “iluminación natural”.
¡Prueba Seedance 1.5 Pro ahora!
Cómo usar Seedance 1.5 Pro en Novita AI
Configuración de integración API
Novita AI expone Seedance 1.5 Pro (su denominación para 1.5 Pro) a través de dos endpoints REST: Texto a Video (T2V) e Imagen a Video (I2V). Ambos siguen patrones de solicitud/respuesta compatibles con OpenAI con sondeo asíncrono de tareas. Para un desglose detallado de cuándo usar T2V vs I2V, salida con audio vs silenciosa, y procesamiento online vs batch flexible, consulta Seedance V1.5 Pro API: Texto a Video vs Imagen a Video, Audio y Modos Silenciosos.
¡Prueba Seedance 1.5 Pro ahora!
Ejemplo de Texto a Video
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-t2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"ratio": "16:9",
"prompt": "Un colosal mecha de ciencia ficción se alza en el paisaje urbano nocturno empapado por la lluvia, luces de neón reflejándose en su armadura metálica. Cámara lenta captura cada gota de lluvia rebotando en el hombro del mecha mientras levanta su cañón de brazo. Profundidad de campo cinematográfica que desenfoca los rascacielos brillantes detrás. Estilo anime, iluminación dramática, calidad 4K.",
"duration": 8,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'
Imagen a Video para salida controlada
El modo I2V acepta fotogramas clave inicial y final, útil para consistencia precisa en el diseño de personajes:
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-i2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"image": "https://pub-32c83cde150f4d468bd19f0a5e372c23.r2.dev/multimodal-assets/2026-02/1771500580027-43159b2510134742.jpg",
"ratio": "adaptive",
"prompt": "Una joven baila enérgicamente en una calle urbana con paredes de graffiti y luces de neón. La cámara sigue sus movimientos fluidos mientras gira y se mueve al ritmo. La escala del plano cambia de medio a primer plano, capturando su expresión natural y segura. Mejora de detalle en sus rasgos faciales y texturas de ropa. Estabilización suave durante toda la secuencia de baile con reflejos consistentes de luz neón.",
"duration": 4,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'
Costo de Seedance 1.5 Pro en Novita AI
Novita AI cobra por tarea de generación, no por token.
Seedance 1.5 Pro · Texto a Video (T2V)
| Resolución | Audio | Online ($/s) | Batch ($/s) |
|---|---|---|---|
| 480P | Silencioso | $0.012 | $0.006 |
| 480P | Con audio | $0.024 | $0.012 |
| 720P | Silencioso | $0.026 | $0.013 |
| 720P | Con audio | $0.052 | $0.026 |
Seedance 1.5 Pro · Imagen a Video (I2V)
| Resolución | Audio | Online ($/s) | Batch ($/s) |
|---|---|---|---|
| 480P | Silencioso | $0.012 | $0.006 |
| 480P | Con audio | $0.024 | $0.012 |
| 720P | Silencioso | $0.026 | $0.013 |
| 720P | Con audio | $0.052 | $0.026 |
Consejo para ahorrar costos:
- Comience con 480p para prototipado (generación más rápida) y luego regenere las versiones finales a 720p.
- Use cámara fija (`camera_fixed: true`) para reducir el tiempo de procesamiento ~30% cuando sean aceptables planos estáticos.
- Los trabajos online se procesan en tiempo real y devuelven resultados inmediatamente, mientras que los trabajos batch se ejecutan de forma asíncrona para generación a gran escala a un costo menor.
¡Prueba Seedance 1.5 Pro ahora!
Mejores prácticas de ingeniería de prompts para Seedance 1.5 Pro
Estructura para resultados óptimos
Seedance 1.5 Pro funciona mejor con prompts explícitos y en capas que separen la acción visual, las señales de audio y las directivas de cámara:
[ACCIÓN DEL PERSONAJE] + [DIÁLOGO CON IDIOMA] + [AMBIENTE DE AUDIO] + [MOVIMIENTO DE CÁMARA] + [ILUMINACIÓN/ESTILO]
Ejemplo:
"Anciana ríe a carcajadas mientras amasa masa en cocina rústica.
Dice '¡Esta es la receta de mi abuela!' en dialecto sichuanés con sonrisa cálida.
Sonidos de fondo: olla burbujeante, cuchara de madera tintineando, música folk suave.
Dolly zoom lento enfocando en manos, luego rostro.
Cálida luz de la tarde a través de la ventana, poca profundidad de campo."
Palabras clave de dialecto y emoción
Para proyectos multilingües, especifique el dialecto explícitamente para activar los modelos de fonemas correctos:
- Dialectos chinos: “en dialecto cantonés”, “usando mandarín taiwanés”, “con acento shanghainés”
- Intensidad emocional: “gritando enfadado”, “susurrando nerviosamente”, “hablando con confianza”
- Audio no verbal: “pasos resonando en mármol”, “vidrio rompiéndose fuera de pantalla”, “ruido de tráfico lejano”
Qué evitar
Los revisores señalan dificultades con secuencias de acción muy complejas: mantenga 1-2 personajes y limite los movimientos simultáneos. Evite prompts como:
- “Cinco personajes teniendo una discusión grupal” (el modelo maneja bien máximo 2-3 hablantes)
- “Personaje corre, salta, luego pelea” (demasiadas acciones secuenciales para 10s)
- “Escena de batalla épica con explosiones” (no optimizado para acción, mejor para diálogo/drama)
¡Prueba Seedance 1.5 Pro ahora!
Problemas comunes y soluciones de Seedance 1.5 Pro
Problema: Cambios de exposición entre cortes
Causa: La generación nativa a 720p a veces produce inconsistencias de brillo entre transiciones de escena.
Solución: Añada “iluminación consistente en toda la escena” al prompt, o normalice la exposición en postproducción usando Lumetri Color/Ruedas de color.
Problema: Superposiciones de texto suaves
Causa: La resolución nativa de 720p no retiene bordes de texto nítidos.
Solución: Genere video sin texto en pantalla, luego añada títulos/gráficos en postproducción a mayor resolución usando After Effects o Motion.
Problema: Desviación de audio en escenas con múltiples hablantes
Causa: El diálogo superpuesto complejo puede ocasionalmente desincronizarse entre 100-200ms.
Solución: Limite a 2 hablantes por clip. Para conversaciones grupales, genere clips separados de plano/contraplano y edítelos juntos.
Problema: Personalización limitada de cámara
Causa: El modelo interpreta directivas de cámara pero no acepta valores precisos de distancia focal/número f.
Solución: Use términos descriptivos como “poca profundidad de campo” o “perspectiva gran angular” en lugar de especificaciones técnicas.
Seedance 1.5 Pro en Novita AI ofrece generación audiovisual lista para producción para contenido de formato corto centrado en diálogos. Su precisión de sincronización labial a nivel de fonemas y su API REST compatible con OpenAI lo convierten en un camino rápido desde el guion hasta el video renderizado para desarrolladores que crean anuncios localizados, micro-dramas y prototipos de videos musicales.
Preguntas frecuentes
¿Cómo maneja Seedance 1.5 Pro la música con derechos de autor en los prompts?
El modelo genera música original que coincide con las descripciones emocionales (“jazz animado”, “piano melancólico”). No reproduce canciones con derechos de autor: intentar pedir canciones existentes dará lugar a interpretaciones genéricas.
¿Puedo exportar pistas de audio y video por separado para masterización profesional?
Sí. El archivo MP4 de salida contiene pistas de audio estándar extraíbles mediante FFmpeg: `ffmpeg -i output.mp4 -vn -acodec pcm_s16le audio.wav` para exportación de audio sin pérdida.
¿Seedance 1.5 Pro admite generación en tiempo real para aplicaciones en vivo?
No. La generación toma aproximadamente 30–60 segundos por clip. Para flujos de trabajo sensibles a la latencia, use el endpoint Batch con callbacks de webhook para recibir resultados de forma asíncrona, o genere previamente una biblioteca de clips y sírvalos bajo demanda en lugar de generarlos en tiempo real.
Novita AI es una plataforma de nube de IA y agentes que ayuda a desarrolladores y startups a construir, desplegar y escalar modelos y aplicaciones de agentes con alto rendimiento, fiabilidad y eficiencia de costos.



