

Seedance 1.5 Pro auf Novita AI bringt ByteDances fortschrittliche audiovisuelle KI für Entwickler in großem Maßstab. Dieses 4,5-Milliarden-Parameter-Modell liefert Phonem-genaue Lippen-Synchronisation über 8 Sprachen, native Filmsteuerung und synchronisierten räumlichen Audio – Fähigkeiten, die zuvor teure Postproduktionsteams erforderten.
Für Entwickler, die dialoggesteuerte Videoanwendungen erstellen, bietet Novita AIs serverlose Bereitstellung konfigurierbare Auflösung (480p/720p) und Seitenverhältnisse. Nachfolgend erläutern wir, warum dies für Produktionsworkflows wichtig ist.
Jetzt Seedance 1.5 Pro ausprobieren!
Was Seedance 1.5 Pro anders macht
Native gemeinsame audiovisuelle Generierung
Im Gegensatz zu sequenziellen Video-dann-Audio-Pipelines verwendet Seedance 1.5 Pro einen Dual-Branch-Diffusion-Transformer, der synchronisierte Videoframes und Audiowellenformen gleichzeitig generiert. Das modalübergreifende Joint-Modul gewährleistet eine millisekundengenaue Ausrichtung zwischen Bildern und Ton und löst die Lippen-Synchronisations-Drift-Probleme früherer Modelle.
Diese Architektur bietet drei entscheidende Vorteile: Phonem-genaue Lippenbewegungen (Abbildung einzelner Sprachlaute auf korrekte Mundformen), räumliche Audiopositionierung (Schritte hallen je nach Raumakustik korrekt) und emotionale Kohärenz (Musikintensität passt zum visuellen Tempo). Für dialoglastige Anwendungen entfällt damit die manuelle Audioreinigung.
https://www.youtube.com/watch?v=yaB3LJElhZA
Mehrsprachige Dialektunterstützung
Das Modell unterstützt 8 Sprachen, einschließlich regionaler chinesischer Dialekte – Sichuanesisch, Taiwanesisch-Mandarin, Kantonesisch, Shanghai-Dialekt – sowie Englisch, Japanisch, Koreanisch, Spanisch, Portugiesisch, Indonesisch und Hindi. Jeder Dialekt behält authentische Aussprachemuster bei und bewahrt gleichzeitig die Lippensynchronisation – entscheidend für lokalisierte Content-Kampagnen.
Filmische Steuerungsvokabular
Entwickler können Kamerabewegungen in natürlicher Sprache angeben: „Dolly-Zoom auf den emotionalen Höhepunkt der Person“, „Tracking-Aufnahme, die einer Verfolgungsjagd folgt“, „Whip-Pan-Übergang zwischen Sprechenden“. Das Modell setzt diese Anweisungen in sanfte Kamerabewegungen mit korrekter Physik um – ohne manuelles Keyframing.
Jetzt Seedance 1.5 Pro ausprobieren!
Technische Spezifikationen von Seedance 1.5 Pro
| Spezifikation | Details | Auswirkungen für Entwickler |
|---|---|---|
| Modellarchitektur | 4,5-Milliarden-Parameter Dual-Branch-Diffusion-Transformer | Niedriger VRAM für Inferenz (~16 GB), schnelle Generierung |
| Native Auflösung | 720p (480p optional) | Erfordert externes Upscaling für 4K-Workflows |
| Dauerbereich | 4–12 Sekunden pro Clip | Am besten für kurze Inhalte, nicht für lange Erzählungen geeignet |
| Audiofunktionen | Räumliche Positionierung, Umgebungseffekte, emotionssynchronisierte Musik | Reduziert die Audio-Postproduktion erheblich |
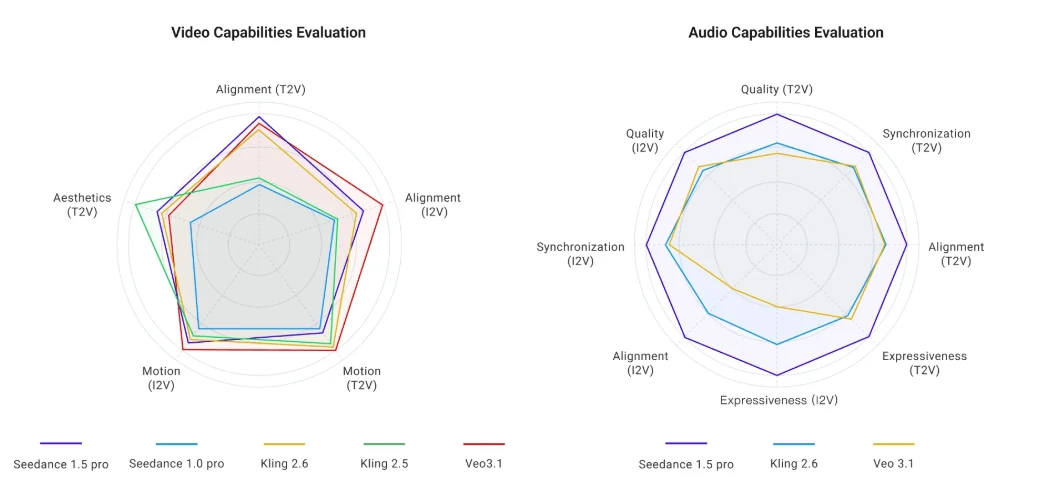
Bewertung der visuellen Qualität
Von ByteDance
Unabhängige Tester bewerten Seedance 1.5 Pro mit 7–8/10 im Vergleich zu Live-Action und stellen verbesserte Hauttexturen sowie reduzierte Banding-Effekte im Vergleich zu Kling 1.6 oder Runway Gen-3 fest. Allerdings schränkt die native 720p-Ausgabe feine Details ein – zu erwarten sind weiche Kanten bei Texteinblendungen und leichte Belichtungsinkonsistenzen zwischen Schnitten.
Das Modell verarbeitet komplexe Physik gut: Schneepartikel, High-Speed-Bewegungsunschärfe, Wassersimulationen werden überzeugend dargestellt. Gelegentlich treten Hypersharpening-Artefakte in Haaren und Laub auf, die mit dem Prompt „natürliche Beleuchtung“ behoben werden können.
Jetzt Seedance 1.5 Pro ausprobieren!
Verwendung von Seedance 1.5 Pro auf Novita AI
API-Integrations-Setup
Novita AI stellt Seedance 1.5 Pro (ihre Bezeichnung für 1.5 Pro) über zwei REST-Endpunkte bereit: Text-zu-Video (T2V) und Bild-zu-Video (I2V). Beide folgen OpenAI-kompatiblen Request/Response-Mustern mit asynchronem Task-Polling. Eine ausführliche Aufschlüsselung, wann T2V vs. I2V, Audio vs. stumm sowie Online- vs. Flex-Batch-Verarbeitung verwendet werden sollte, findest du unter Seedance V1.5 Pro API: Text-zu-Video vs. Bild-zu-Video, Audio und Stummmodi.
Jetzt Seedance 1.5 Pro ausprobieren!
Text-zu-Video-Beispiel
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-t2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"ratio": "16:9",
"prompt": "A colossal sci-fi mecha stands in the rain-soaked city nightscape, neon lights reflecting off its metallic armor. Slow motion captures every raindrop bouncing off the mecha's shoulder as it raises its arm cannon. Cinematic depth of field blurs the glowing skyscrapers behind. Anime style, dramatic lighting, 4K quality.",
"duration": 8,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'
Bild-zu-Video für kontrollierte Ausgabe
Der I2V-Modus akzeptiert Start- und End-Keyframes, was für eine präzise Konsistenz des Figurendesigns nützlich ist:
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-i2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"image": "https://pub-32c83cde150f4d468bd19f0a5e372c23.r2.dev/multimodal-assets/2026-02/1771500580027-43159b2510134742.jpg",
"ratio": "adaptive",
"prompt": "A young woman dances energetically on a city street with graffiti walls and neon lights. The camera follows her fluid movements as she spins and grooves to the rhythm. Shot scale changes from medium to close-up, capturing her confident natural expression. Detail enhancement on her facial features and clothing textures. Smooth stabilization throughout the dance sequence with consistent neon lighting reflections.",
"duration": 4,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'
Kosten von Seedance 1.5 Pro auf Novita AI
Novita AI berechnet pro Generierungsaufgabe, nicht pro Token.
Seedance 1.5 Pro · Text-zu-Video (T2V)
| Auflösung | Audio | Online ($/s) | Batch ($/s) |
|---|---|---|---|
| 480P | Stumm | $0,012 | $0,006 |
| 480P | Audio | $0,024 | $0,012 |
| 720P | Stumm | $0,026 | $0,013 |
| 720P | Audio | $0,052 | $0,026 |
Seedance 1.5 Pro · Bild-zu-Video (I2V)
| Auflösung | Audio | Online ($/s) | Batch ($/s) |
|---|---|---|---|
| 480P | Stumm | $0,012 | $0,006 |
| 480P | Audio | $0,024 | $0,012 |
| 720P | Stumm | $0,026 | $0,013 |
| 720P | Audio | $0,052 | $0,026 |
Tipp zum Kosten sparen:
- Beginne mit 480p zum Prototyping (schnellste Generierung) und erstelle dann die finalen Versionen in 720p neu.
- Verwende eine feste Kamera (
camera_fixed: true), um die Verarbeitungszeit um ~30 % zu reduzieren, wenn statische Aufnahmen akzeptabel sind.- Online-Jobs werden in Echtzeit verarbeitet und liefern sofort Ergebnisse, während Batch-Jobs asynchron für die Massengenerierung zu geringeren Kosten ausgeführt werden.
Jetzt Seedance 1.5 Pro ausprobieren!
Best Practices für Prompt-Engineering mit Seedance 1.5 Pro
Struktur für optimale Ergebnisse
Seedance 1.5 Pro funktioniert am besten mit expliziten, geschichteten Prompts, die visuelle Aktionen, Audiohinweise und Kameradirektiven trennen:
[CHARAKTER-AKTION] + [DIALOG MIT SPRACHE] + [AUDIO-UMGEBUNG] + [KAMERABEWEGUNG] + [BELEUCHTUNG/STIL]
Beispiel:
"Ältere Frau lacht herzlich, während sie in einer rustikalen Küche Teig knetet.
Sagt 'Das ist das Rezept meiner Großmutter!' im Sichuan-Dialekt mit warmem Lächeln.
Hintergrundgeräusche: brodelnder Topf, Klappern von Holzlöffeln, sanfte Volksmusik.
Langsamer Dolly-Zoom, fokussiert auf Hände, dann Gesicht.
Warmes Nachmittagslicht durch das Fenster, geringe Tiefenschärfe."
Dialekt- und Emotions-Keywords
Für mehrsprachige Projekte den Dialekt explizit angeben, um die korrekten Phonem-Modelle auszulösen:
- Chinesische Dialekte: „im kantonesischen Dialekt“, „unter Verwendung von Taiwan-Mandarin“, „mit Shanghai-Akzent“
- Emotionale Intensität: „wütend schreiend“, „nervös flüsternd“, „selbstbewusst sprechend“
- Non-verbales Audio: „Schritte hallen auf Marmor wider“, „Glas zersplittert außerhalb des Bildes“, „entfernter Verkehrslärm“
Was zu vermeiden ist
Tester berichten von Schwierigkeiten mit sehr komplexen Actionszenen – beschränke dich auf 1–2 Charaktere und begrenze gleichzeitige Bewegungen. Vermeide Prompts wie:
- „Fünf Charaktere führen eine Gruppendiskussion“ (das Modell handhabt maximal 2–3 Sprecher gut)
- „Charakter rennt, springt und kämpft dann“ (zu viele aufeinanderfolgende Aktionen für 10 s)
- „Epische Kampfszene mit Explosionen“ (nicht für Action optimiert, besser geeignet für Dialog/Drama)
Jetzt Seedance 1.5 Pro ausprobieren!
Häufige Stolperfallen und Lösungen bei Seedance 1.5 Pro
Problem: Belichtungswechsel zwischen Schnitten
Ursache: Die native 720p-Generierung erzeugt manchmal Helligkeitsinkonsistenzen über Szenenübergänge hinweg.
Lösung: Füge „konsistente Beleuchtung in der gesamten Szene“ zum Prompt hinzu oder normalisiere die Belichtung in der Nachbearbeitung mit Lumetri Color/Color Wheels.
Problem: Weiche Texteinblendungen
Ursache: Die native Auflösung von 720p behält keine scharfen Textkanten.
Lösung: Erzeuge das Video ohne eingeblendeten Text und füge Titel/Grafiken in der Nachbearbeitung in höherer Auflösung mit After Effects oder Motion hinzu.
Problem: Audio-Drift bei Szenen mit mehreren Sprechern
Ursache: Komplexe überlappende Dialoge können gelegentlich um 100–200 ms desynchronisieren.
Lösung: Beschränke dich auf 2 Sprecher pro Clip. Für Gruppengespräche generiere separate Schuss-/Gegenschuss-Clips und bearbeite sie zusammen.
Problem: Eingeschränkte Kamerakontrolle
Ursache: Das Modell interpretiert Kameradirektiven, akzeptiert aber keine präzisen Brennweiten-/Blendenzahlen.
Lösung: Verwende beschreibende Begriffe wie „geringe Tiefenschärfe“ oder „Weitwinkelperspektive“ anstelle technischer Spezifikationen.
Seedance 1.5 Pro auf Novita AI liefert produktionsreife audiovisuelle Generierung für dialogfokussierte Kurzform-Inhalte. Die Phonem-genaue Lippensynchronisation und die OpenAI-kompatible REST-API bieten einen schnellen Weg vom Skript zum gerenderten Video für Entwickler, die lokalisierte Anzeigen, Mikrodramen und Musikvideoprototypen erstellen.
Häufig gestellte Fragen
Wie geht Seedance 1.5 Pro mit urheberrechtlich geschützter Musik in Prompts um?
Das Modell generiert Originalmusik, die emotionalen Beschreibungen entspricht („lebhafter Jazz“, „melancholisches Klavier“). Es reproduziert keine urheberrechtlich geschützten Songs – der Versuch, vorhandene Titel zu prompten, führt zu generischen Interpretationen.
Kann ich Audio- und Videospuren für professionelles Mastering separat exportieren?
Ja. Das ausgegebene MP4 enthält Standard-Audiospuren, die mit FFmpeg extrahiert werden können: ffmpeg -i output.mp4 -vn -acodec pcm_s16le audio.wav für verlustfreien Audioexport.
Unterstützt Seedance 1.5 Pro Echtzeitgenerierung für Live-Anwendungen?
Nein. Die Generierung dauert etwa 30–60 Sekunden pro Clip. Für latenzempfindliche Workflows verwende den Batch-Endpunkt mit Webhook-Callbacks, um Ergebnisse asynchron zu erhalten, oder generiere vorab eine Bibliothek von Clips und serviere sie bei Bedarf, anstatt sie in Echtzeit zu generieren.
Novita AI ist eine KI- und Agent-Cloud-Plattform, die Entwickler und Startups dabei unterstützt, Modelle und agentische Anwendungen mit hoher Leistung, Zuverlässigkeit und Kosteneffizienz zu erstellen, bereitzustellen und zu skalieren.



