

Seedance 1.5 Pro sur Novita AI offre aux développeurs l’IA audiovisuelle avancée de ByteDance à grande échelle. Ce modèle de 4,5 milliards de paramètres garantit une synchronisation labiale au niveau phonémique dans 8 langues, des contrôles cinématographiques natifs et un audio spatial synchronisé – des capacités qui nécessitaient auparavant des équipes de post-production coûteuses.
Pour les développeurs d’applications vidéo centrées sur le dialogue, le déploiement serverless de Novita AI avec résolution configurable (480p/720p) et rapports d’aspect variés est idéal. Découvrons pourquoi cela compte pour les workflows de production.
Essayez Seedance 1.5 Pro maintenant !
Qu’est-ce qui rend Seedance 1.5 Pro différent ?
Génération audiovisuelle conjointe native
Contrairement aux pipelines séquentiels vidéo puis audio, Seedance 1.5 Pro utilise un transformateur de diffusion à double branche qui génère simultanément des trames vidéo et des formes d’onde audio synchronisées. Le module conjoint inter-modal maintient un alignement milliseconde entre visuels et son, résolvant les problèmes de dérive labiale des modèles précédents.
Cette architecture offre trois avantages critiques : des mouvements labiaux précis au niveau phonémique (mappage des sons de parole individuels aux formes de bouche correctes), un positionnement audio spatial (les pas résonnent correctement selon l’acoustique de la pièce) et une cohérence émotionnelle (l’intensité musicale correspond au rythme visuel). Pour les applications riches en dialogue, cela élimine le besoin de nettoyage audio manuel.
https://www.youtube.com/watch?v=yaB3LJElhZA
Prise en charge des dialectes multilingues
Le modèle gère 8 langues, y compris des dialectes régionaux chinois – sichuanais, mandarin taïwanais, cantonais, shanghaïen – ainsi que l’anglais, le japonais, le coréen, l’espagnol, le portugais, l’indonésien et l’hindi. Chaque dialecte conserve des modèles de prononciation authentiques tout en maintenant la précision labiale, essentiel pour les campagnes de contenu localisées.
Vocabulaire de contrôle cinématographique
Les développeurs peuvent spécifier des mouvements de caméra en langage naturel : « dolly zoom sur le pic émotionnel du sujet », « travelling avant suivant une course-poursuite », « transition whip pan entre les interlocuteurs ». Le modèle traduit ces directives en mouvements de caméra fluides avec une physique correcte – sans keyframing manuel.
Essayez Seedance 1.5 Pro maintenant !
Spécifications techniques de Seedance 1.5 Pro
| Spécification | Détails | Impact développeur |
|---|---|---|
| Architecture du modèle | Transformateur de diffusion à double branche de 4,5B paramètres | Faible VRAM pour l’inférence (~16 Go), génération rapide |
| Résolution native | 720p (480p en option) | Nécessite un upscaling externe pour les workflows 4K |
| Durée par clip | 4 à 12 secondes | Idéal pour le contenu court, pas pour les récits longs |
| Fonctionnalités audio | Positionnement spatial, effets d’environnement, musique synchronisée à l’émotion | Réduit considérablement le travail audio en post-production |
Évaluation de la qualité visuelle
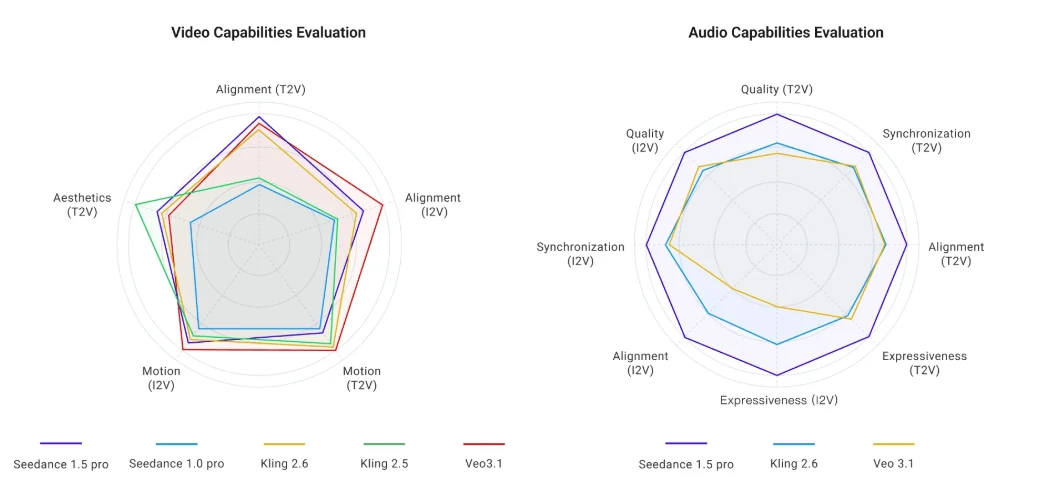
Source : ByteDance
Les évaluateurs indépendants notent Seedance 1.5 Pro à 7-8/10 par rapport à la prise de vue réelle, notant des textures de peau améliorées et une réduction des bandes par rapport à Kling 1.6 ou Runway Gen-3. Cependant, la sortie native en 720p limite les détails fins – attendez-vous à des bords flous sur les superpositions de texte et de légères incohérences d’exposition entre les plans.
Le modèle gère bien les simulations physiques complexes : particules de neige, flou de mouvement à haute vitesse, simulations d’eau convaincantes. Des artefacts de sur-accentuation apparaissent parfois dans les cheveux et le feuillage, corrigibles avec des prompts de type « éclairage naturel ».
Essayez Seedance 1.5 Pro maintenant !
Utiliser Seedance 1.5 Pro sur Novita AI
Configuration d’intégration API
Novita AI expose Seedance 1.5 Pro (leur nom pour la version 1.5 Pro) via deux endpoints REST : Text-to-Video (T2V) et Image-to-Video (I2V). Les deux suivent des modèles de requête/réponse compatibles avec OpenAI avec un polling asynchrone des tâches. Pour une analyse détaillée des cas d’utilisation de T2V ou I2V, des modes audio ou silencieux, et du traitement en ligne ou par lots flexibles, consultez Seedance V1.5 Pro API : Text-to-Video vs Image-to-Video, Audio et modes silencieux.
Essayez Seedance 1.5 Pro maintenant !
Exemple Text-to-Video
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-t2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"ratio": "16:9",
"prompt": "A colossal sci-fi mecha stands in the rain-soaked city nightscape, neon lights reflecting off its metallic armor. Slow motion captures every raindrop bouncing off the mecha's shoulder as it raises its arm cannon. Cinematic depth of field blurs the glowing skyscrapers behind. Anime style, dramatic lighting, 4K quality.",
"duration": 8,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'
Image-to-Video pour un rendu contrôlé
Le mode I2V accepte des keyframes de début et de fin, utile pour une cohérence précise du design des personnages :
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-i2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"image": "https://pub-32c83cde150f4d468bd19f0a5e372c23.r2.dev/multimodal-assets/2026-02/1771500580027-43159b2510134742.jpg",
"ratio": "adaptive",
"prompt": "A young woman dances energetically on a city street with graffiti walls and neon lights. The camera follows her fluid movements as she spins and grooves to the rhythm. Shot scale changes from medium to close-up, capturing her confident natural expression. Detail enhancement on her facial features and clothing textures. Smooth stabilization throughout the dance sequence with consistent neon lighting reflections.",
"duration": 4,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'
Coût de Seedance 1.5 Pro sur Novita AI
Novita AI facture par tâche de génération, pas par jeton.
Seedance 1.5 Pro · Text to Video (T2V)
| Résolution | Audio | En ligne ($/s) | Par lots ($/s) |
|---|---|---|---|
| 480P | Silencieux | $0,012 | $0,006 |
| 480P | Audio | $0,024 | $0,012 |
| 720P | Silencieux | $0,026 | $0,013 |
| 720P | Audio | $0,052 | $0,026 |
Seedance 1.5 Pro · Image to Video (I2V)
| Résolution | Audio | En ligne ($/s) | Par lots ($/s) |
|---|---|---|---|
| 480P | Silencieux | $0,012 | $0,006 |
| 480P | Audio | $0,024 | $0,012 |
| 720P | Silencieux | $0,026 | $0,013 |
| 720P | Audio | $0,052 | $0,026 |
Astuce pour réduire les coûts :
- Commencez par le 480p pour le prototypage (génération la plus rapide), puis régénérez les versions finales en 720p.
- Utilisez une caméra fixe (
camera_fixed: true) pour réduire le temps de traitement d’environ 30 % lorsque des plans statiques sont acceptables.- Les tâches en ligne sont traitées en temps réel et retournent les résultats immédiatement, tandis que les tâches par lots sont exécutées de manière asynchrone pour une génération à grande échelle à moindre coût.
Essayez Seedance 1.5 Pro maintenant !
Bonnes pratiques d’ingénierie de prompts pour Seedance 1.5 Pro
Structure pour des résultats optimaux
Seedance 1.5 Pro fonctionne mieux avec des prompts explicites et en couches qui séparent l’action visuelle, les indices audio et les directives de caméra :
[ACTION DU PERSONNAGE] + [DIALOGUE AVEC LANGUE] + [ENVIRONNEMENT AUDIO] + [MOUVEMENT DE CAMÉRA] + [ÉCLAIRAGE/STYLE]
Exemple :
"Elderly woman laughs heartily while kneading dough in rustic kitchen.
Says 'This is my grandmother's recipe!' in Sichuanese dialect with warm smile.
Background sounds: bubbling pot, wooden spoon clinking, soft folk music.
Slow dolly zoom focusing on hands, then face.
Warm afternoon sunlight through window, shallow depth of field."
Mots-clés de dialecte et d’émotion
Pour les projets multilingues, spécifiez explicitement le dialecte pour déclencher les modèles phonémiques corrects :
- Dialectes chinois : « in Cantonese dialect », « using Taiwan Mandarin », « with Shanghainese accent »
- Intensité émotionnelle : « yelling angrily », « whispering nervously », « speaking confidently »
- Audio non verbal : « footsteps echoing on marble », « glass shattering off-screen », « distant traffic noise »
Ce qu’il faut éviter
Les évaluateurs notent des difficultés avec les séquences d’action très complexes – limitez-vous à 1-2 personnages et restreignez les mouvements simultanés. Évitez les prompts comme :
- « Five characters having a group discussion » (le modèle gère bien 2-3 interlocuteurs max)
- « Character runs, jumps, then fights » (trop d’actions séquentielles pour 10s)
- « Epic battle scene with explosions » (non optimisé pour l’action, mieux adapté au dialogue/drame)
Essayez Seedance 1.5 Pro maintenant !
Problèmes courants et solutions pour Seedance 1.5 Pro
Problème : Variations d’exposition entre les plans
Cause : La génération native en 720p produit parfois des incohérences de luminosité entre les transitions de scène.
Solution : Ajoutez « consistent lighting throughout scene » au prompt, ou normalisez l’exposition en post-production avec Lumetri Color / les roues chromatiques.
Problème : Superpositions de texte floues
Cause : La résolution native 720p ne conserve pas des bords de texte nets.
Solution : Générez la vidéo sans texte à l’écran, puis ajoutez titres et graphismes en post-production à une résolution plus élevée dans After Effects ou Motion.
Problème : Dérive audio dans les scènes multi-intervenants
Cause : Les dialogues complexes qui se chevauchent peuvent parfois se désynchroniser de 100 à 200 ms.
Solution : Limitez-vous à 2 intervenants par clip. Pour les conversations de groupe, générez des plans séparés (champ/contre-champ) et montez-les ensemble.
Problème : Personnalisation limitée de la caméra
Cause : Le modèle interprète les directives de caméra mais n’accepte pas de valeurs précises de focale/d’ouverture.
Solution : Utilisez des termes descriptifs comme « shallow depth of field » ou « wide-angle perspective » au lieu de spécifications techniques.
Seedance 1.5 Pro sur Novita AI offre une génération audiovisuelle prête pour la production pour les contenus courts orientés dialogue. Sa précision labiale au niveau phonémique et son API REST compatible OpenAI en font un chemin rapide du script à la vidéo rendue pour les développeurs créant des publicités localisées, des micro-dramas et des prototypes de clips musicaux.
Questions fréquentes
Comment Seedance 1.5 Pro gère-t-il les musiques protégées par le droit d’auteur dans les prompts ?
Le modèle génère une musique originale correspondant aux descriptions émotionnelles (« upbeat jazz », « melancholic piano »). Il ne reproduit pas de chansons protégées – tenter de demander des morceaux existants donnera des interprétations génériques.
Puis-je exporter les pistes audio et vidéo séparément pour un mastering professionnel ?
Oui. Le fichier MP4 de sortie contient des pistes audio standard extractibles avec FFmpeg : ffmpeg -i output.mp4 -vn -acodec pcm_s16le audio.wav pour un export audio sans perte.
Seedance 1.5 Pro prend-il en charge la génération en temps réel pour des applications live ?
Non. La génération prend environ 30 à 60 secondes par clip. Pour les workflows sensibles à la latence, utilisez l’endpoint Batch avec des webhooks pour recevoir les résultats de manière asynchrone, ou pré-générez une bibliothèque de clips et servez-les à la demande plutôt que de générer en temps réel.
Novita AI est une plateforme cloud d’IA et d’agents qui aide les développeurs et startups à construire, déployer et mettre à l’échelle des modèles et des applications agentiques avec hautes performances, fiabilité et rentabilité.



