

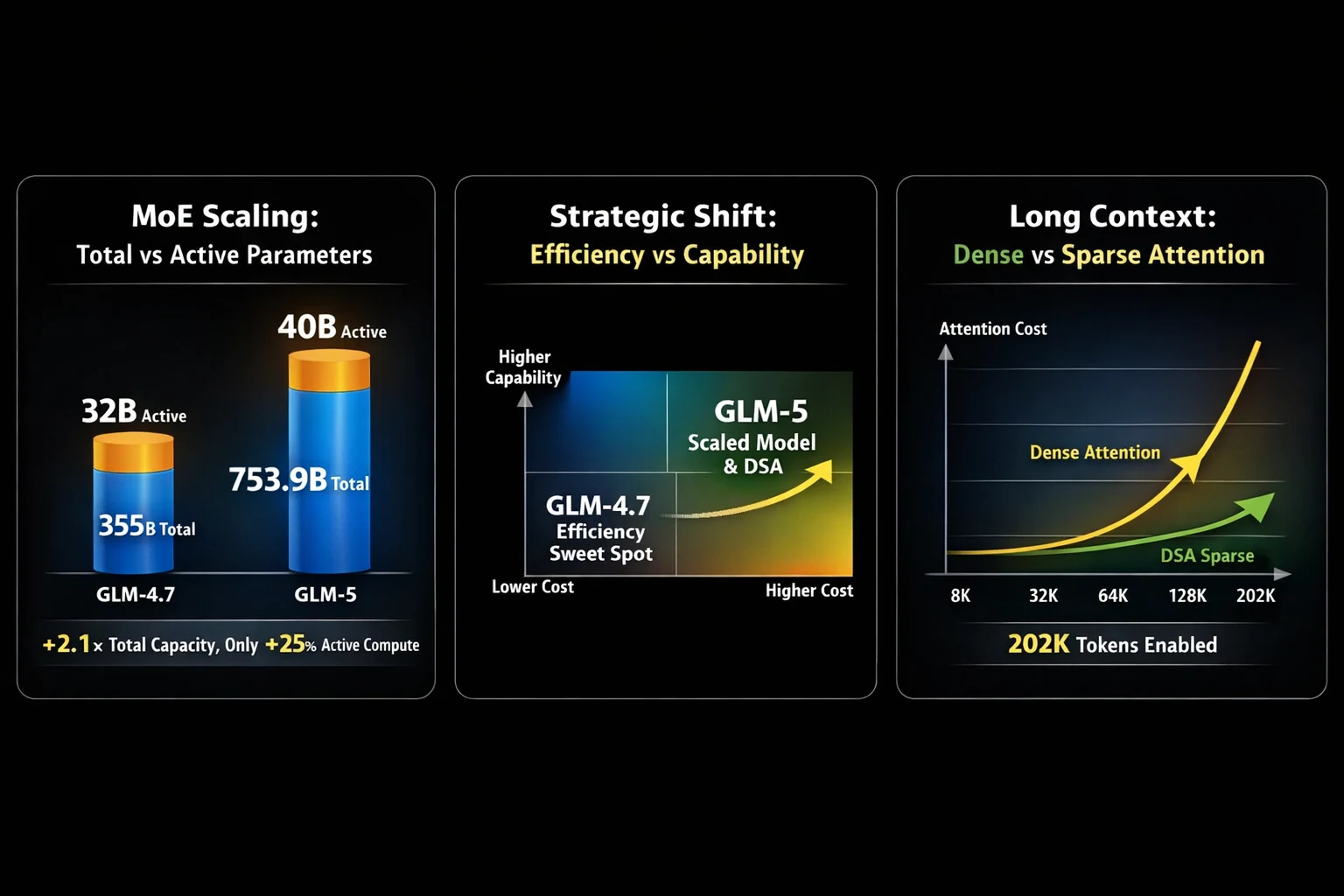
Выбор между GLM-5 и GLM-4.7 часто сводится к ключевому компромиссу: масштабная мощность агентных систем против проверенной универсальности в программировании. GLM-5, выпущенный компанией Z.ai, значительно масштабируется по сравнению с предшественником: количество параметров выросло с 355 млрд (32 млрд активных) у GLM-4.7 до 753,9 млрд (40 млрд активных). Это увеличение количества параметров в 2,1 раза приносит существенные улучшения в сложной системной инженерии и долгосрочных агентных задачах, однако GLM-4.7 остаётся лидером для многоязычного программирования, автоматизации терминала и рабочих процессов реальных разработчиков.
Сравнение архитектуры GLM-5 и GLM-4.7
| Характеристика | GLM-5 | GLM-4.7 |
|---|---|---|
| Общее количество параметров | 753,9 млрд | 355 млрд |
| Активные параметры | 40 млрд | 32 млрд |
| Длина контекста | 202 752 токена | 202 752 токена |
| Данные для предобучения | 28,5 трлн токенов | 23 трлн токенов |
| Точность | BF16 (доступен FP8) | BF16 (доступен FP8) |
| Поддержка мультимодальности | Только текст | Только текст |
| Дата выпуска | Январь 2026 | Декабрь 2025 |
Одним из самых практичных обновлений GLM-5 является интеграция DeepSeek Sparse Attention (DSA), которая значительно снижает стоимость внимания для длинного контекста, сохраняя при этом большие окна контекста до 202K токенов. Это делает GLM-5 гораздо более удобным для развёртывания в реальных задачах: рассуждений на основе длинных документов, многоходовых ассистентов и агентных рабочих процессов. Со стороны постобучения GLM-5 использует slime — новую инфраструктуру асинхронного обучения с подкреплением, которая повышает пропускную способность обучения RL и позволяет проводить более частые и тонкие итерации выравнивания.
Попробуйте GLM-5 прямо сейчас!
Сравнение результатов тестов GLM-5 и GLM-4.7
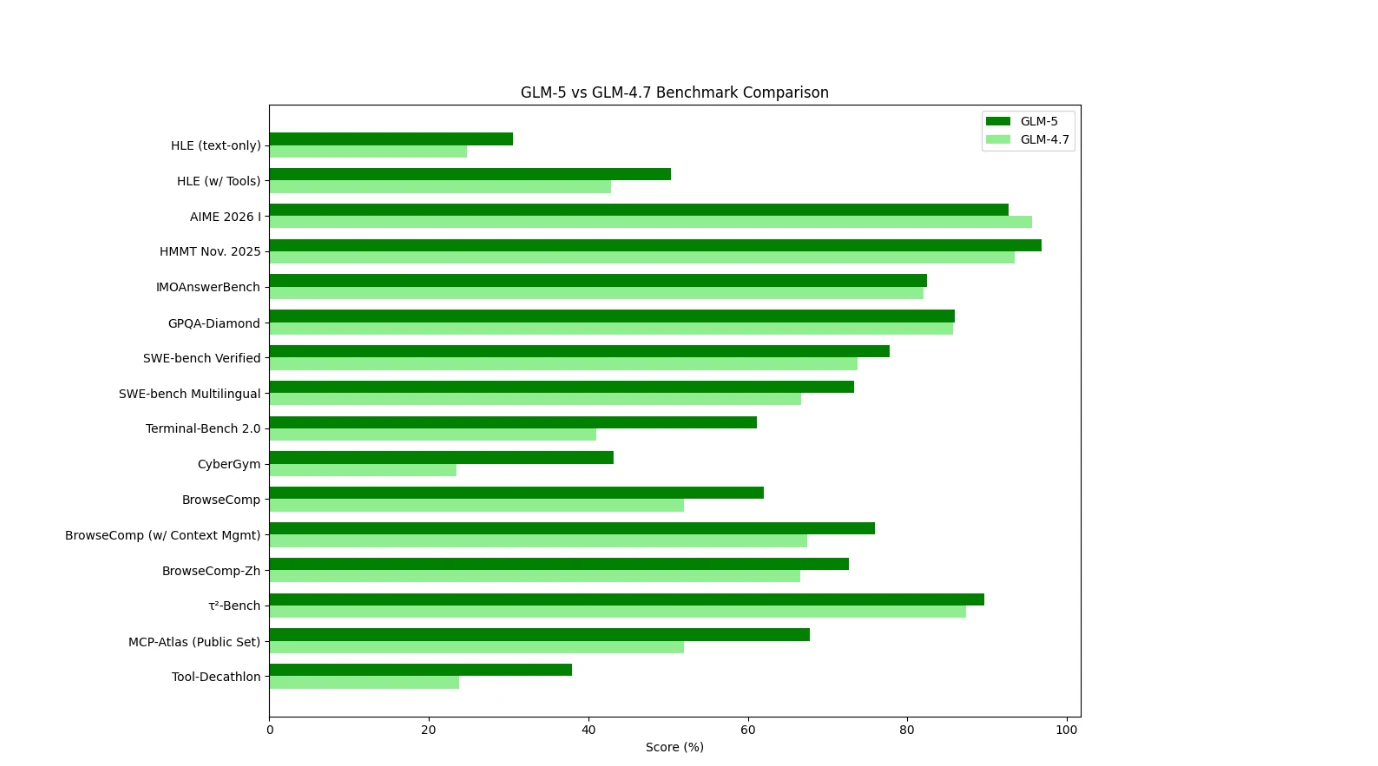
С точки зрения результатов тестов GLM-5 показывает широкие и стабильные улучшения по сравнению с GLM-4.7, особенно в задачах использования инструментов, браузинга и агентных сценариях. Наибольший прирост заметен в средах, требующих многошагового планирования, управления контекстом и выполнения в реальных условиях, что говорит о том, что GLM-5 оптимизирован для агентных рабочих процессов, а не для изолированных задач рассуждения.
GLM-4.7 показывает результаты тестов как модель рассуждения/программирования, оптимизированная на эффективность, она всё ещё очень сильна в классических математических оценках, но уступает в интерактивных задачах, управляемых инструментами.
Попробуйте GLM-5 прямо сейчас!
Требования к VRAM для GLM-5 и GLM-4.7
Увеличение количества параметров в 2,1 раза при переходе от GLM-4.7 к GLM-5 влечёт существенные требования к оборудованию. Вот разбивка по объёму VRAM:
Рекомендуемая конфигурация GPU для GLM-5
| Точность | Требуемый объём VRAM | Рекомендуемая конфигурация | Сценарий использования |
|---|---|---|---|
| BF16 | 1508 ГБ | 19x NVIDIA H100 (80 ГБ) | Исследования с максимальным качеством |
| FP8 | Около 800 ГБ | 10x NVIDIA H100 (80 ГБ) | Развёртывание в продакшене |
| INT4 | Около 400 ГБ | 5x H100 (80 ГБ) | Эффективный по стоимости вывод |
Рекомендуемая конфигурация GPU для GLM-4.7
| Точность | Требуемый объём VRAM | Рекомендуемая конфигурация | Сценарий использования |
|---|---|---|---|
| BF16 | 717 ГБ | 9x NVIDIA H100 (80 ГБ) | Максимальное качество |
| FP8 | 390 ГБ | 5x H100 (80 ГБ) | Развёртывание в продакшене |
| INT4 | 200 ГБ | 3x H100 (80 ГБ) | Эффективный по стоимости вывод |
Попробуйте экономичные GPU прямо сейчас!
При развёртывании в режиме FP8 GLM-5 обычно требует вдвое больше GPU по сравнению с GLM-4.7.
Для разработчиков с ограниченным бюджетом GLM-4.7 предлагает лучшую производительность на доллар в рабочих нагрузках, связанных с программированием, достигая 73,8% на SWE-bench Verified и 84,9% на LiveCodeBench-v6.
Для передовых исследований и разработки агентных систем более мощные возможности использования инструментов и выполнения долгосрочных задач GLM-5 могут оправдать дополнительные затраты на оборудование.
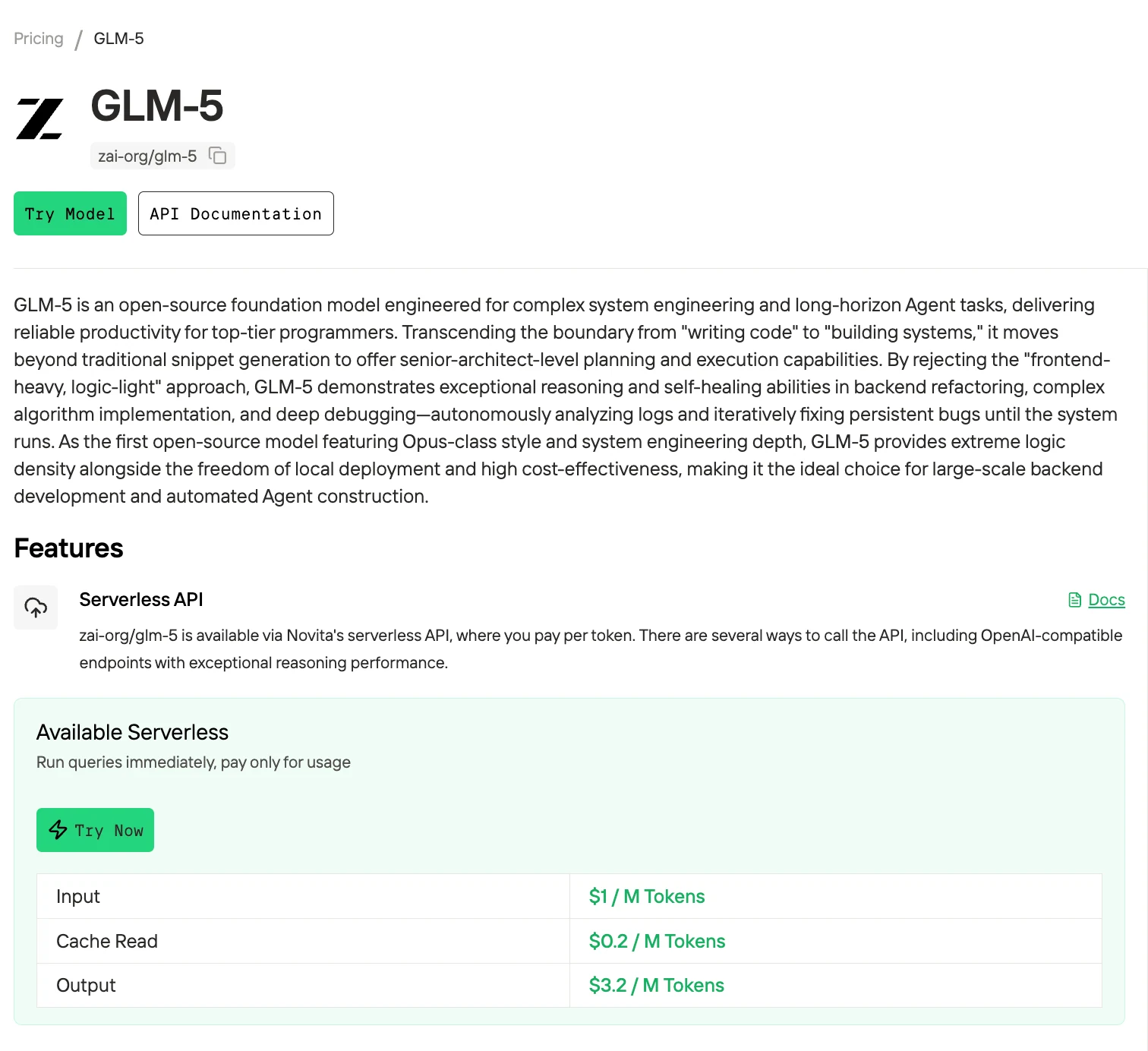
Цены и доступ к API для GLM-5 и GLM-4.7
| Модель | Ввод ($ / M токенов) | Чтение из кэша ($ / M токенов) | Вывод ($ / M токенов) |
|---|---|---|---|
| GLM-4.7 | $0.60 | $0.11 | $2.20 |
| GLM-5 | $1.00 | $0.20 | $3.20 |
Чтение из кэша — это стоимость чтения токенов, которые ранее были сохранены в кэше промптов. Когда одинаковое содержимое промпта повторно используется в нескольких запросах, модель получает эти токены напрямую из кэша, вместо того чтобы обрабатывать их заново. Это снижает как задержку вывода, так и стоимость.
Шаг 1. Войдите в аккаунт и перейдите в библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.

Шаг 2. Выберите нужную модель
Просмотрите доступные варианты и выберите модель, которая подходит для ваших задач.

Шаг 3. Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Попробуйте GLM-5 прямо сейчас!
Шаг 4. Получите API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.

Шаг 5. Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Это пример использования API завершения чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5 or zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Сводка по критериям выбора для GLM-5 и GLm-4.7
| Сценарий | Рекомендуемая модель | Ключевая причина |
|---|---|---|
| Многоагентные системы с оркестрацией инструментов | GLM-5 | +15,8pp на MCP-Atlas, +14,2pp на Tool-Decathlon |
| Рабочие процессы SWE-bench в продакшене | GLM-4.7 | 73,8% при половине затрат на оборудование |
| Кибербезопасность и пентестинг | GLM-5 | 43,2% на CyberGym |
| Программирование в IDE (Claude Code, Cline) | GLM-4.7 | Сохранение режима мышления + меньшая задержка |
| Передовые исследования рассуждений (HLE) | GLM-5 | 50,4% с использованием инструментов (лучший среди открытых моделей) |
| Разработка UI/фронтенда «vibe coding» | GLM-4.7 | Специализированное обучение для современного веб-интерфейса |
| Автоматизация терминала (долгосрочные задачи) | GLM-5 | +28,3pp на Terminal-Bench 2.0 |
| Математические соревнования (AIME, HMMT) | GLM-4.7 | Сопоставим/превосходит GLM-5 при меньшей стоимости |
| Стартапы с ограниченным бюджетом | GLM-4.7 | Высокое качество программирования на 4x H100 против 8x H100 у GLM-5 |
| Исследовательские лаборатории, продвигающие границы AGI | GLM-5 | Предобучение на 28,5 трлн токенов, инфраструктура RL slime |
Попробуйте GLM-5 прямо сейчас!
GLM-5 не делает GLM-4.7 устаревшим — он решает другие задачи. Если ваша работа связана с долгосрочными агентными задачами, требующими активного использования инструментов и многошагового рассуждения, двукратные инвестиции в оборудование для GLM-5 окупаются более высоким процентом выполнения задач. Если вы поставляете ассистенты по программированию тысячам разработчиков или нуждаетесь в быстрых циклах итерации в средах IDE, более лёгкая архитектура и специализированное обучение GLM-4.7 делают его более подходящим выбором. Обе модели представляют собой значительные достижения в области языкового моделирования с открытым исходным кодом, сокращая разрыв с передовыми проприетарными моделями при сохранении полной прозрачности и гибкости локального развёртывания.
Часто задаваемые вопросы
В чём основное архитектурное отличие GLM-5 от GLM-4.7?
Общее количество параметров GLM-5 выросло с 355 млрд до 753,9 млрд (активные параметры с 32 млрд до 40 млрд), а также интегрирована технология DeepSeek Sparse Attention (DSA) для снижения затрат на развёртывание при сохранении длины контекста 202K токенов.
Можно ли запустить GLM-5 на потребительском оборудовании?
Нет. GLM-5 требует как минимум 10 графических процессоров H100 80GB в режиме FP8 (800 ГБ VRAM), что значительно превышает возможности потребительских GPU.
Какая модель лучше подходит для задач программирования в SWE-bench?
GLM-5 немного опережает GLM-4.7 с результатом 77,8% на SWE-bench Verified (+4 п.п.), но результат GLM-4.7 в 73,8% при половине затрат на оборудование делает его более практичным для продакшена.
Novita AI — это облачная платформа ИИ, которая предлагает разработчикам простой способ развёртывания моделей ИИ с помощью нашего простого API, а также доступное и надёжное облако GPU для построения и масштабирования решений.
Рекомендуемые материалы



